VGG16
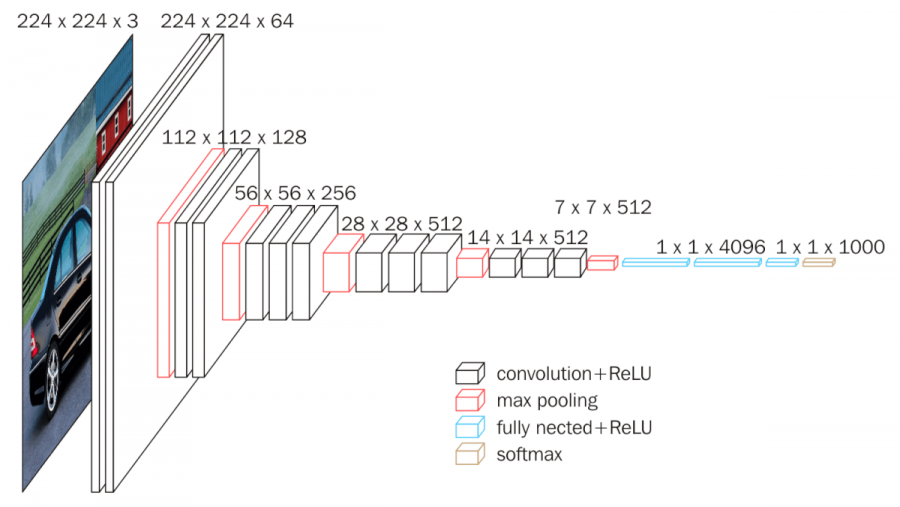
- VGGNet은 옥스포드 대학의 연구팀 VGG에 의해 개발된 모델로, 2014년
이미지넷 이미지 인식 대회에서 준우승을 한 모델이다.- 통상적으로 VGGNet 모델부터 네트워크의 깊이가 이전 모델 대비 깊어졌다고 한다.
- CNN 알고리즘들 중에서는 이미지 분류(Image Classification)용 알고리즘, 예를 들어 AlexNet, GoogleNet 등이 있다. 그 이미지 분류 CNN 모델들 중에 하나가 바로 VGGNet이다.
- VGGNet은 몇 개의 층(layer)으로 구성되어 있는지에 따라, 16개 층으로 구성되어 있으면 VGG16, 19개 층으로 구성되어 있으면 VGG19라고 불린다.
- VGG16은 Convolution의 필터의 사이즈를 3x3으로 고정시켜 사용하는데, 이를 통해 연산 시 발생하는 파라미터의 개수가 줄어드는 효과를 낼 수 있다. 즉 학습해야할 가중치가 줄어들어, network 학습 속도가 빨라지고 network를 더 깊게 만들 수 있다!
- 활성함수로는 ReLU를 사용한다.
구현
nn.Sequential 을 이용해서 VGG model을 이전에 작성했던 것보다 더 깔끔하게 작성할 수 있었다! image size는 3*32*32으로 resize해서 넣어주었다!
VGG model 코드를 확실히 이해하고 싶다면 아래 post를 참고하자!!
공부하면서 작성해놓은 것인데 도움이 될지도 ... !
import torch
import torch.nn as nn
class VGG16(nn.Module):
def __init__(self, input_channel, num_class):
super().__init__()
self.conv = nn.Sequential(
# 32 32 3 (입력)
# 32 32 64
nn.Conv2d(in_channels=input_channel, out_channels=64, kernel_size=3, stride=1, padding=1), nn.ReLU(),
nn.Conv2d(in_channels=64 , out_channels=64 , kernel_size=3 , stride=1, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
# 16 16 128
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1), nn.ReLU(),
nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
# 8 8 256
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1), nn.ReLU(),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1), nn.ReLU(),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
# 4 4 512
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1), nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1), nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=1),
# 3 3 512
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1), nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1), nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=1) # 2 2 512
)
self.fc = nn.Sequential(
nn.Linear(in_features=512*2*2, out_features=4096), nn.ReLU(),
nn.Linear(in_features=4096, out_features=4096), nn.ReLU(),
nn.Linear(in_features=4096, out_features=num_class)
)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
conv_out = self.conv(x)
conv_out = conv_out.view(conv_out.size()[0], -1) # 256, 512*2*2
fc_out = self.fc(conv_out)
output = self.softmax(fc_out)
return output
블로그 이전) https://danbibibi.tistory.com