1. 텐서플로우TensorFlow
유연하고, 효율적이며, 확장성 있는 딥러닝 프레임워크
대형 클러스터 컴퓨터부터 스마트폰까지 다양한 디바이스에서 동작 가능
가장 많이 쓰이는 딥러닝프레임워크
텐서플로우, 파이토치
2. 딥러닝 모델 구현 순서
- 데이터 전처리하기
- 딥러닝 모델 구축하기
- 모델 학습시키기
- 평가 및 예측하기
3. 데이터 전처리하기
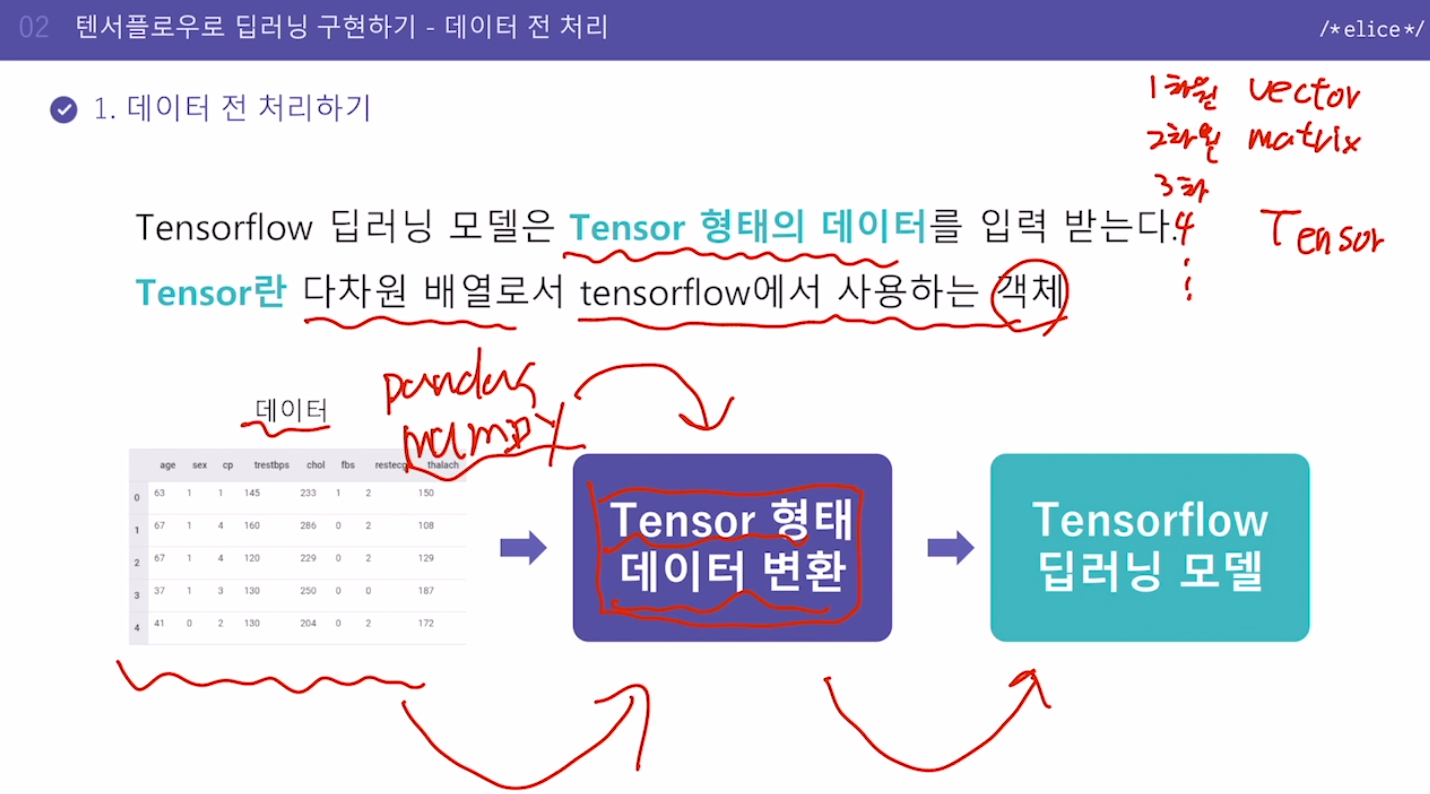
Tensorflow 딥러닝 모델은 Tensor 형태의 데이터를 입력 받는다.
Tensor란 다차원 배열로서 tensorflow에서 사용하는 개체
Tensor의 일반적 의미 : 다차원 배열
1차원 배열 : vector
2차원 배열 : matrix
3차원 이상 : Tensor
TensorFlow 에서의 Tensor : Tensorflow에서 사용하는 객체
pandas나 numpy로 정리한 데이터를 다시 한번 Tensor 형태로 변환
하지만 요새 함수들이 잘 나와서 바로 넣을 수 있기도 한데, 그 내부에서 텐서전환을 알아서 해주는 것
# pandas를 사용하여 데이터 불러오기
# 우리는 지도학습을 이용하므로 feature데이터와 label 데이터로 분리
df = pd.read_csv('data.csv')
feature = df.drop(columns=['label'])
label = df['label']
# tensor 형태로 데이터 변환
dataset = tf.data.Dataset.from_tensor_slices((feature.values, label.values))
# 입력값이 pandas 데이터프레임 형태로 들어가는 것이 아니라 .values를 이용하여 배열의 형태로 전달해야한다는 것! 숙지!4. 데이터 전처리: Epoch와 Batch
딥러닝에 사용하는 데이터는 추가적인 전처리 작업이 필요함 => Epoch, Batch
Epoch: 한번의 epoch는 전체 데이터 셋에 대해 한 번 학습을 완료한 상태
전체 과정이 하나의 에포크
Batch: 나눠진 데이터 셋(보통 mini-batch라고 표현) 배치 사이즈로 데이터를 나누게 됨. 하나의 에포크 안에 여러 개의 배치
iteration은 epoch를 나누어서 실행하는 횟수를 의미
딥러닝 학습하려면 가중치 w 업데이트 => 무거우면 무거울수록 w도 많아지고 굉장히 많은 계산 필요해짐.
이 계산량을 줄이기 위해 처음부터 1 Epoch만큼의 데이터를 넣는 게 아니라 쪼개서 넣어보자는 아이디어가 Batch
1개의 batch씩 가중치 업데이트를 해보자
요 하나의 계산과정이 iteration
예시: 총 데이터가 1000개, batch size = 100 으로 나눠본다고 하면 총 10개로 나눠짐
1 iteration = 100개 데이터에 대해서 학습
1 epoch = 10 iteration( = 1000 / Batch size )
# dataset의 batch사이즈를 32로 설정
dataset = dataset.batch(32)5. 실습
텐서플로우를 활용하여 신경망 구현하기 - 데이터 전 처리
이번 실습에서는 텐서플로우를 활용하여 신경망을 구현해보는 과정을 수행해보겠습니다.
여러분은 마케터로서 광고 비용에 따른 수익률을 신경망을 통해서 예측하고자 합니다.
아래와 같이 FB, TV, Newspaper 광고에 대한 비용 대비 Sales 데이터가 주어진다면 우선 데이터 전 처리를 수행하여 텐서플로우 딥러닝 모델에 필요한 학습용 데이터를 만들어 봅시다.

텐서플로우 신경망 모델의 학습 데이터를 만드는 함수/메서드
텐서플로우 신경망 모델의 학습 데이터는 기존 데이터를 tf.data.Dataset 형식으로 변환하여 사용합니다.
pandas의 DataFrame 형태 데이터를 Dataset으로 변환하기 위해서는 아래의 from_tensor_slices() 메서드를 사용하여 ds에 저장할 수 있습니다.
ds = tf.data.Dataset.from_tensor_slices((X.values, Y.values))
X는 feature 데이터가 저장된 DataFrame이고, Y는 label 데이터가 저장된 Series 입니다. 여기서 X, Y 데이터는 X.values, Y.values를 사용하여 리스트 형태로 입력합니다.
이후 변환된 Dataset인 ds에서 batch를 적용하고 싶다면 아래와 같이 batch() 메서드를 사용합니다.
ds = ds.shuffle(len(X)).batch(batch_size=5)
- shuffle 메서드를 사용하여 데이터를 셔플합니다. 인자로는 데이터의 크기를 입력합니다.
- batch 메서드를 사용하여 batch_size에 batch 크기를 넣게 되면 해당 크기로 batch를 수행하게 됩니다.
이렇게 처리한 ds에서 take()메서드를 사용하면 batch로 분리된 데이터를 확인할 수 있습니다.
지시사항
pandas DataFrame df에서 Sales 변수는 label 데이터로 Y에 저장하고 나머진 X에 저장합니다.
학습용 데이터 train_X, train_Y를 tf.data.Dataset 형태로 변환합니다.
from_tensor_slices 함수를 사용하여 변환합니다.
import tensorflow as tf
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
np.random.seed(100)
tf.random.set_seed(100)
# 데이터를 DataFrame 형태로 불러 옵니다.
df = pd.read_csv("data/Advertising.csv")
# DataFrame 데이터 샘플 5개를 출력합니다.
print('원본 데이터 샘플 :')
print(df.head(),'\n')
# 의미없는 변수는 삭제합니다.
df = df.drop(columns=['Unnamed: 0'])
"""
1. Sales 변수는 label 데이터로 Y에 저장하고 나머진 X에 저장합니다.
"""
X = df.drop(columns=['Sales'])
Y = df['Sales']
train_X, test_X, train_Y, test_Y = train_test_split(X, Y, test_size=0.3)
"""
2. 학습용 데이터를 tf.data.Dataset 형태로 변환합니다.
from_tensor_slices 함수를 사용하여 변환하고 batch를 수행하게 합니다.
"""
train_ds = tf.data.Dataset.from_tensor_slices((train_X.values, train_Y.values))
train_ds = train_ds.shuffle(len(train_X)).batch(batch_size=5)
# 하나의 batch를 뽑아서 feature와 label로 분리합니다.
[(train_features_batch, label_batch)] = train_ds.take(1)
# batch 데이터를 출력합니다.
print('\nFB, TV, Newspaper batch 데이터:\n',train_features_batch)
print('Sales batch 데이터:',label_batch)
