1. 의사결정나무 분리 기준 알아보기
데이터의 불순도를 최소화하는 기준으로 나누자.
- 불순도 : 다른 데이터가 섞여 있는 정도
데이터가 많이 섞여있을수록 불순도가 높고,
적게 섞여있을수록 불순도가 낮다.
2. 불순도 측정방법
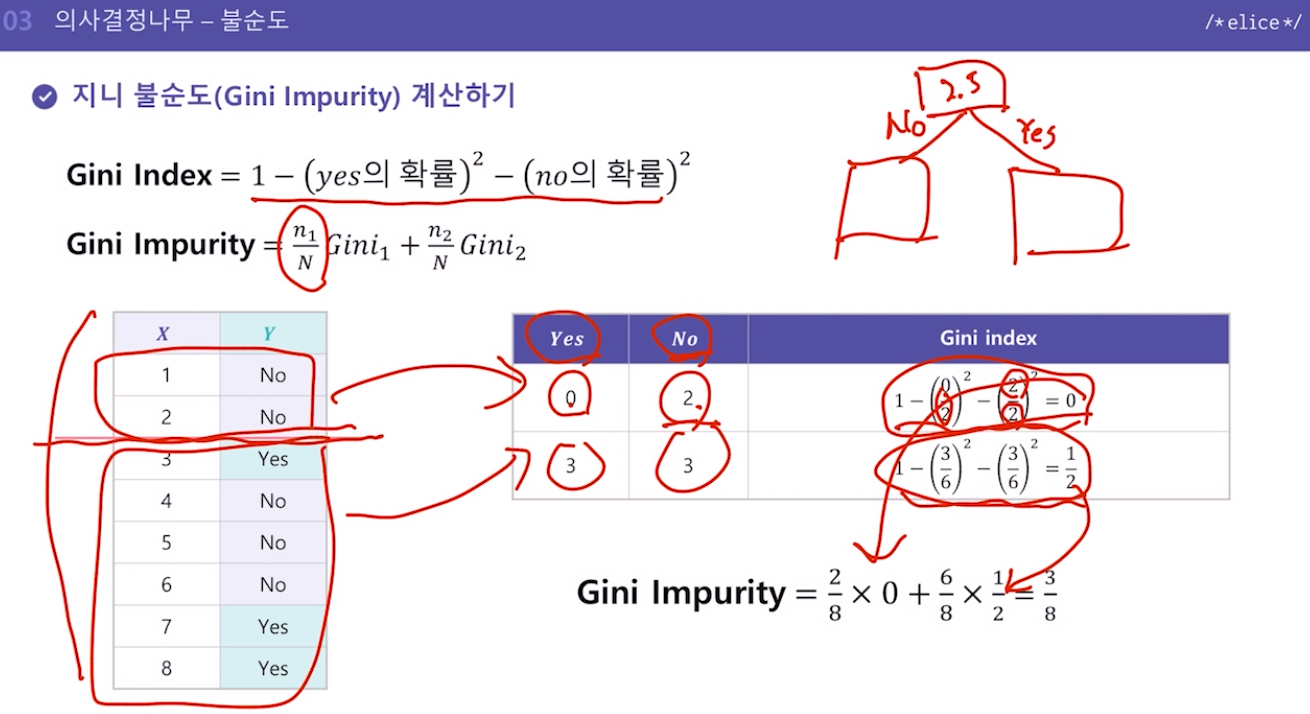
- 지니 불순도
-
지니계수
해당 구역 안에서 특정 클래스에 속하는 데이터의 비율을 모두 제외한 값
즉, 다양성을 계산하는 방법 -
지니 불순도
작을수록 좋은 것.


다양한 기준에 따라 분류했을 때의 지니불순도를 계산해보고, 가장 지니불순도가 낮게 나오는 기준을 채택 -> 여기서 6.5를 기준으로 크냐 작냐를 나누는 게 가장 좋은 기준임을 알 수 있음
이 과정을 뿌리노드에서부터 노드마다 기준을 정함
끝노드가 나올 때까지.
- 의사결정나무의 깊이의 trade-off
깊이 => 중간노드Node의 개수
중간노드가 많으면 많을수록, (의사결정나무의 깊이가 깊어질수록) 세분화해서 나눌 수 있어서 좋으나
너무 깊은 모델은 "과적합"을 야기할 수 있음
과적합 => 너무 세밀하게 예측하는 것 => 이게 단점이 될 수 있는 경우가 있음 => 한두 개의 튀는 값까지 다 하나의 분류로 나뉘어지면서 오히려 예측에 실패할 수 있음, 분류가 너무 자잘자잘하게 만들어지는 경우가 생기는 것. => 예측모델 평가할 때 오히려 안좋은 평가를 받게 되는 경우가 생길 수 있다.
=> 데이터에 따라 다를 수 있지만 너무 깊은 모델은 지양
- 의사결정나무 특징
- 결과가 직관적이며, 해석하기 쉬움
- 나무 깊이가 깊어질수록 과적합(Overfitting)문제 발생 가능성이 매우 높음
- 학습이 끝난 트리의 작업 속도가 매우 빠르다

백엔드 개발자. 공동의 목표를 함께 이해한 상태에서 솔직하게 소통하며 일하는 게 가장 즐겁고 효율적이라고 믿는 사람.