1. 회귀 알고리즘 평가
어떤 모델이 좋은 모델인지 어떻게 평가?
목표를 얼마나 잘 달성했는지 정도를 평가해야 함
실제 값과 모델이 예측하는 값의 차이에 기반한 평가 방법 사용 => Loss함수처럼
예시) RSS, MSE, MAE, MAPE, R^2
2. RSS - 단순 오차
-
실제 값과 예측 값의 단순 오차 제곱 합
Loss와 거의 비슷한 형태 -
값이 작을수록 모델의 성능이 높음
-
전체 데이터에 대한 실제 값과 예측하는 값의 오차 제곱의 총합
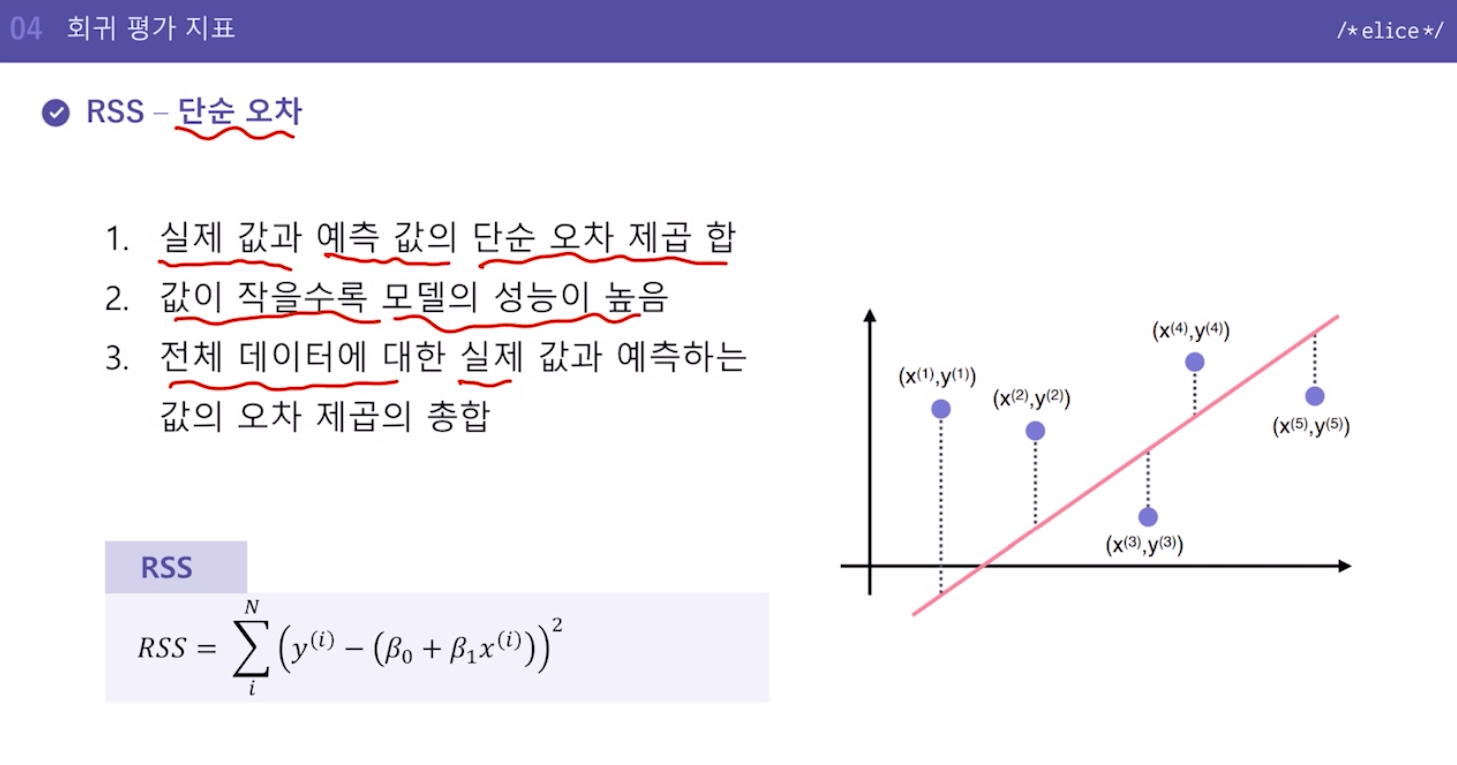
특징
- 가장 간단한 평가 방법으로 직관적인 해석이 가능함
- 그러나 오차를 그대로 이용하기 때문에 입력 값의 크기에 의존적임
- 절대적인 값과 비교가 불가능함
2번과 3번 특징이 이어짐. -> 비슷한 정도로 잘 예측한 데이터여도 데이터의 Raw값 자체가 크면 RSS값이 크게 나타남. 어떤 모델이 더 좋은지에 대해 비교하기가 애매하다.
3. MSE, MAE - 절대적인 크기에 의존한 지표
Mean Squared Error
평균 제곱 오차, RSS에서 데이터 수 만큼 나눈 값
작을수록 모델의 성능이 높다고 평가할 수 있음.
배웠던 Loss함수랑 똑같은 수식..
=> Loss라는 것은 그 모델에서 줄여야하는 값(이라는 의미만 있을 뿐), 형태가 꼭 이러란 법은 없음. 계산을 위한 것이지, 특정한 지표를 말하는 것이 아니다!
MSE는 지표이고, Loss 그 모델에서 줄여야하는 값, 대상.
우리가 배운 모델, 회귀 모델에서는 보통 MSE를 Loss로 사용하지만, 다른 곳에서는 다른 것을 Loss로 이용할 수도 있다.(분류에서는 Entropy라든지)
MAE Mean Absolute Error
평균 절대값 오차, 실제 값과 예측 값의 오차의 절대값의 평균
작을수록 모델의 성능이 높다고 평가할 수 있음
특징
- MSE: 이상치(outlier) 즉, 데이터들 중 크게 떨어진 값에 민감함(하나의 잘못 예측한 값 하나가 제곱되어서 들어가므로 매우 크게 반영)
- MAE: 변동성이 큰 지표와 낮은 지표를 같이 예측할 시 유용
- 가장 간단한 평가 방법들로 직관적인 해석이 가능함
- 그러나 평균을 그대로 이용하기 때문에 입력 값의 크기에 의존적임
- 절대적인 값과 비교가 불가능함
4. R^2 R square (결정 계수)
회귀 모델의 설명력을 표현하는 지표
1에 가까울수록 높은 성능의 모델이라고 해석할 수 있음
!절대적인 값으로 비교가 가능하다!
1 - 예측값과의 차이 제곱의 합(RSS) / 평균값과의 차이 제곱의 합(TSS)
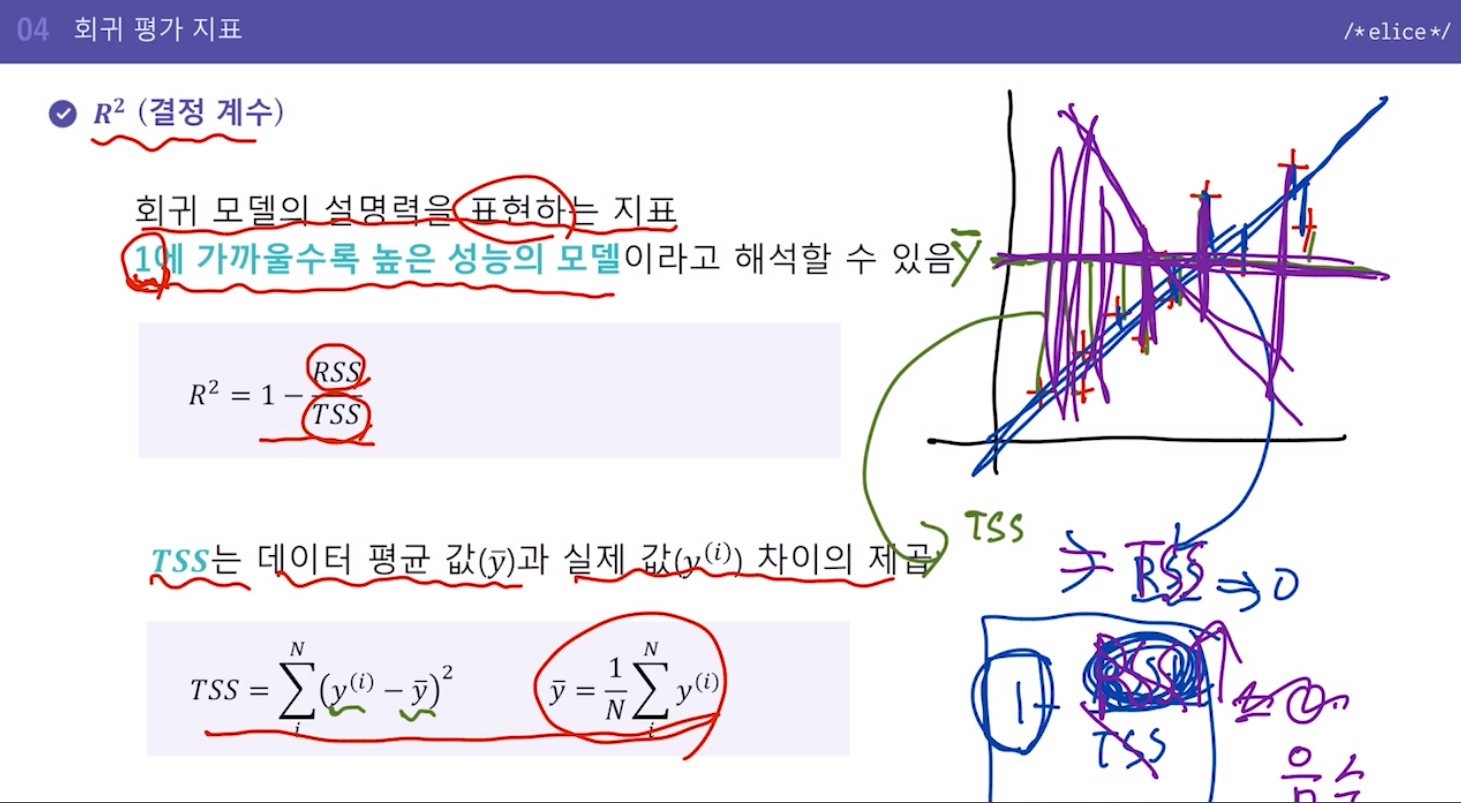
잘 예측할수록 RSS값의 작아지므로 1에 가까워지고, 단순 평균 낸 것과 비슷한 수준의 예측이면 0에 가까워짐, 단순 평균 낸 것보다도 못한 예측이면 RSS가 TSS보다 커져서 결정계수값은 마이너스값이 될 수 있음.
특징
- 오차가 없을수록 1에 가까운 값
- 값이 0인 경우, 데이터의 평균 값을 출력하는 직선 모델을 의미
- 음수 값이 나온 경우, 평균 값 예측보다 성능이 좋지 않음
5. 실습
[실습6] 에 이어서 Sales 예측 모델의 성능을 평가하기 위해서 다양한 회귀 알고리즘 평가 지표를 사용하여 비교해보겠습니다.
이번 실습에서는 학습용 및 평가용 데이터에 대해서 MSE와 MAE을 계산해보겠습니다.
MSE와 MAE는 sklearn 라이브러리 함수를 통하여 쉽게 구할 수 있습니다.
MSE, MAE 평가 지표를 계산하기 위한 사이킷런 함수/라이브러리
mean_squared_error(y_true, y_pred): MSE 값 계산하기
mean_absolute_error(y_true, y_pred): MAE 값 계산하기
지시사항
train_X 데이터에 대한 MSE, MAE 값을 계산하여 MSE_train, MAE_train에 저장합니다.
test_X 데이터에 대한 MSE, MAE 값을 계산하여 MSE_test, MAE_test에 저장합니다.
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
# 데이터를 읽고 전 처리합니다
df = pd.read_csv("data/Advertising.csv")
df = df.drop(columns=['Unnamed: 0'])
X = df.drop(columns=['Sales'])
Y = df['Sales']
train_X, test_X, train_Y, test_Y = train_test_split(X, Y, test_size=0.2, random_state=42)
# 다중 선형 회귀 모델을 초기화 하고 학습합니다
lrmodel = LinearRegression()
lrmodel.fit(train_X, train_Y)
# train_X 의 예측값을 계산합니다
pred_train = lrmodel.predict(train_X)
"""
1. train_X 의 MSE, MAE 값을 계산합니다
"""
MSE_train = mean_squared_error(train_Y, pred_train)
MAE_train = mean_absolute_error(train_Y, pred_train)
print('MSE_train : %f' % MSE_train)
print('MAE_train : %f' % MAE_train)
# test_X 의 예측값을 계산합니다
pred_test = lrmodel.predict(test_X)
"""
2. test_X 의 MSE, MAE 값을 계산합니다
"""
MSE_test = mean_squared_error(test_Y,pred_test)
MAE_test = mean_absolute_error(test_Y,pred_test)
print('MSE_test : %f' % MSE_test)
print('MAE_test : %f' % MAE_test)
[실습7] 에 이어서 Sales 예측 모델의 성능을 평가하기 위해서 다양한 회귀 알고리즘 평가 지표를 사용하여 비교해보겠습니다.
이번 실습에서는 학습용 및 평가용 데이터에 대해서 R2 score를 계산해보겠습니다.
R2 score 는 아래와 같이 정의할 수 있고 sklearn 라이브러리 함수를 통하여 쉽게 구할 수 있습니다.
R2 평가 지표를 계산하기 위한 사이킷런 함수/라이브러리
r2_score(y_true, y_pred): R2 score 값 계산하기
지시사항
train_X 데이터에 대한 R2 값을 계산하여 R2_train에 저장합니다.
test_X 데이터에 대한 R2 값을 계산하여 R2_test에 저장합니다.
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
# 데이터를 읽고 전 처리합니다
df = pd.read_csv("data/Advertising.csv")
df = df.drop(columns=['Unnamed: 0'])
X = df.drop(columns=['Sales'])
Y = df['Sales']
train_X, test_X, train_Y, test_Y = train_test_split(X, Y, test_size=0.2, random_state=42)
# 다중 선형 회귀 모델을 초기화 하고 학습합니다
lrmodel = LinearRegression()
lrmodel.fit(train_X, train_Y)
# train_X 의 예측값을 계산합니다
pred_train = lrmodel.predict(train_X)
"""
1. train_X 의 R2 값을 계산합니다
"""
R2_train = r2_score(train_Y,pred_train)
print('R2_train : %f' % R2_train)
# test_X 의 예측값을 계산합니다
pred_test = lrmodel.predict(test_X)
"""
2. test_X 의 R2 값을 계산합니다
"""
R2_test = r2_score(test_Y,pred_test)
print('R2_test : %f' % R2_test)
