Thread Scheduling
Contention Scope
- process-contention scope(PCS)
- user-level thread가 scheduled될 때, 한 process 내부에서 CPU 점유를 위한 경쟁이 일어나기 때문에, process-contention scope라고 부른다.
- 특히나 user-level thread의 경우 실제 CPU에 할당되는 것이 아니라 LWP에 우선적으로 할당된다.
- system-contention scope(SCS)
- kernel-level thread가 scheduled될 때의 경우를 말한다.
- 리눅스나 윈도우의 경우 one-to-one system이므로 PCS는 사용 불가, SCS만 사용 가능하다.
Pthread Scheduling
- 사용 방법
- pthread_attr_setscope(pthread_attr_t *attr, int scope)
- pthread_attr_getscope(pthread_attr_t *attr, int *scope)
- scope의 값으로는 다음이 올 수 있다.
- PTHREAD_SCOPE_PROCESS : PCS scheduling을 통해 스레드를 scheduling 하겠다는 뜻.
- PTHREAD_SCOPE_SYSTEM : SCS scheduling을 통해 스레드를 scheduling 하겠다는 뜻.
Multi-Processor Scheduling
Approaches to Multiple-Processor Scheduling
-
asymmetric multiprocessing
- 하나의 processor만 모든 스케줄링을 비롯한 시스템에 직접 접근하는 권한을 가지고 있고, 나머지 processors는 user code를 실행하는 데에만 쓰임.
- 하나의 processor만 관리하는 만큼 자원 공유나 이런 복잡한 로직이 필요하지 않지만 한 processor가 모두를 담당하기 때문에 병목현상 발생 가능.
-
symmetric multiprocessing(SMP)
-
각 processor가 따로 self-scheduling을 시행한다.
-
scheduling을 실시하는 2가지 방법이 존재.
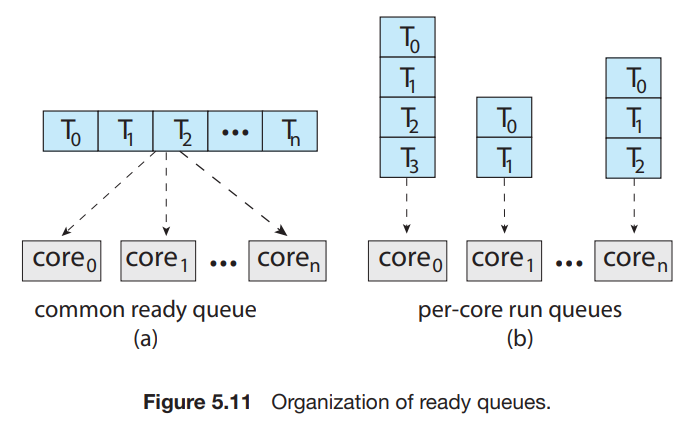
- 모든 스레드들이 공통된 ready queue에 존재
- 여러 프로세스가 하나의 스레드에 동시에 접근할 수 있다 -> race condition 발생!
- locking을 사용해서 해결할 수는 있지만, 모든 queue로의 접근은 lock을 원할 것이고, 결국 병목현상을 발생시킨다.
- 각 processor가 각자의 queue를 가짐
- 1번의 단점이 발생하지 않는다.
- cache memory를 더 효율적으로 사용 가능.
- 추가적인 알고리즘을 통해 일을 균등하게 분배해야 한다.
- 대부분의 현대 운영체제가 SMP를 지원한다.
- 모든 스레드들이 공통된 ready queue에 존재
-
Multicore Processors
-
singlecore processor 여러 chip을 꽂는 것 보다 multicore processor 하나를 꽂는 것이 power를 덜 쓴다.
-
processor의 속도가 점점 빨라지면서, memory의 data가 사용가능해질 때 까지 걸리는 시간(memory stall)이 상대적으로 굉장히 길어지게 되었다. -> 줄여야 할 필요성이 생김.
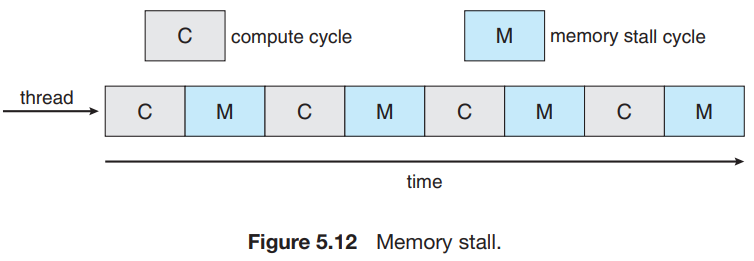
-
해결 방법 : 둘 이상의 hardware thread(?)를 각 코어에 할당시킴 -> memory stall 시간동안 다른 스레드로 switch한다. -> CPU를 항상 작동상태로 만들 수 있다. (이 때에는 context-switch가 무시할 만한 수준인듯. -> X, 뒤에서 이 부분에 대해 다룬다.)

-> 운영체제 입장에서는 logical CPU가 2배로 존재한다고 인식한다. -> chip multithreading (CMT)
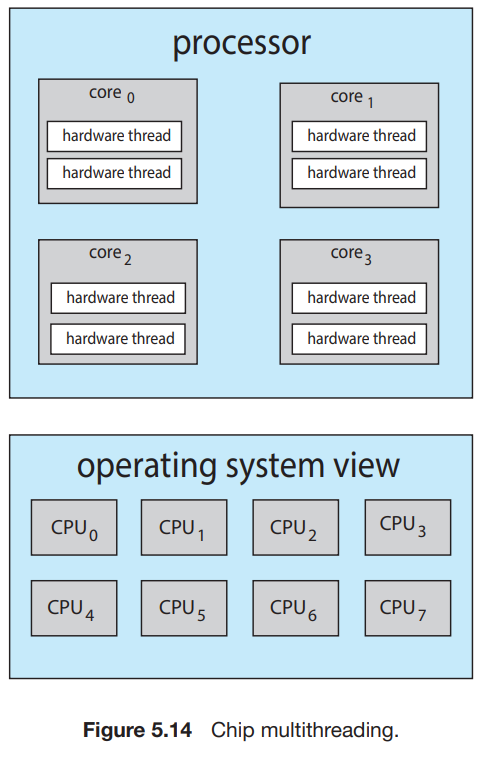
-
intel processor : hyper-threading(simultaneous multithreading or SMT)이라고 부름.
-
processing core를 multithread하는 방법
- coarse-grained(굵은 곡식? -> context switch 시간이 촘촘하지 않다는 뜻인듯)
- memory stall과 같은 long-latency event가 생길 때 까지 core에서 실행된다.
- context-switching이 상대적으로 적게 발생함.
- pipeline을 flush하고(컴구에서 배울듯) 다시 채워야 하므로 context-switch 비용이 상당하다.
- fine-grained(고운 곡식? -> context switch 시간이 촘촘하다는 뜻인듯)
- cycle 단위로 context switching이 발생함.
- 당연히 cycle 단위이기 때문에 context switching이 상대적으로 많이 발생한다. -> switching overhead가 커짐
- hardware적으로 이를 보완하는데, processor 내부에 추가적인 레지스터를 달아서 context switch가 수행될 때, 기존에 써져 있던 데이터를 지우고 다시 추가하는 작업을 하지 않고 그냥 데이터가 존재하는 위치만 바꾸어 주어서 context switch 시의 비용을 대폭 줄여준다.
- coarse-grained(굵은 곡식? -> context switch 시간이 촘촘하지 않다는 뜻인듯)
-
그럼에도 불구하고 physical core의 자원들은 (cache나 pipeline같은) hardware threads 간에 공유되어야 하므로, 한 번에 하나의 스레드만 실행될 수 있다. -> multithread, multicore processor는 2 level의 scheduling이 필요함.
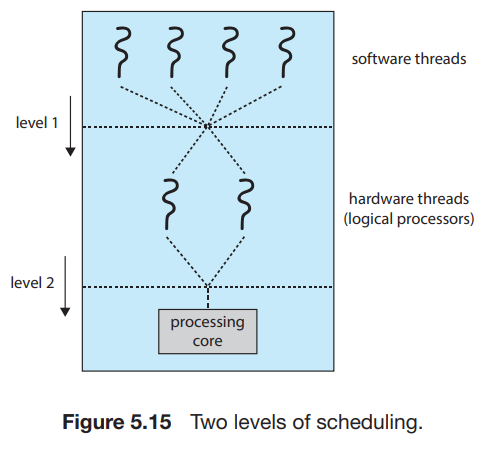
-
level 1 : operating system에 의해 각 hardware thread(logical CPU)에 어떤 software thread가 할당되어야 하는지 선택해야 함.
-
level 2 : core가 어떤 hardware thread를 선택해야 하는지 결정해야 함.
-
위 그림의 두 가지 levels는 mutually exclusive할 필요는 없다. 예를 들어, 2 코어 2 hardware thread, 2 software thread가 존재할 때, 운영체제는 실제 코어의 상태를 판단해서(단순 4개의 logical processors로 보지 않고) 서로 다른 core에 존재하는 hardware thread에 각각 software thread를 할당할 수도 있다.
Load Balancing
- workload는 processor 간에 balanced되어 있어야 하는데, 그렇지 않다면 특정 processor는 놀고 다른애들은 계속 일하는 상황이 벌어질 수 있다 -> 효율성이 떨어짐.
- 하지만 load balancing은 asymetric multiprocessing에서는 큰 의미가 없는게, 만약 한 processor가 놀고 있다면, 단순히 공유되는 ready queue에서 하나를 갖고 오면 그만이다. 반면에 SMP의 경우에는, 각 processor마다 ready queue가 존재하며, 이 ready queue에 존재하는 thread들의 work load에 차이가 발생하면 위에 말한 문제가 생길 수 있다.
- load balancing의 2가지 방법
- push migration : 주기적으로 각 processor의 load를 확인하다가 불균형을 발견하면 overloaded -> idle or less-busy 로 thread를 push한다.
- pull migration : idle processor가 busy processor로 부터 waiting task를 pull하는 것을 의미한다.
- 이 두 가지 방법은 mutual exclusive할 필요가 없고, 보통 같이 구현된다.
- balanced load라는 것은 각 queue에 비슷한 수의 thread가 존재하는 상태일 수도 있지만, 각 queue마다 비슷한 priority를 가지는 경우 또한 포함한다. -> 이 경우에는 또 다른 방법이 필요함.
Processor Affinity
- 한 thread가 특정한 processor에서 실행중일 때, 최근에 접근한 메모리의 내용이 cache에 담겨서 동일한 데이터 영역에 반복해서 접근할 때 이 cache를 사용하게 된다.(warm cache) 하지만 thread가 다른 processor로 migrate한다면, 1번 프로세서의 cache memory 내부의 내용은 지워져야 하고, 2번 프로세서의 cache memory에 내용이 채워져야 한다.(여기와 관련해서 chatGPT에게 물어보았더니, cache memory에는 다양한 스레드들의 데이터가 동시에 담겨있을 수 있다고 한다. 왜냐하면 다 같은 프로세스에서 생성된 스레드들이므로 서로 다른 스레드가 가리키는 메모리에 접근이 가능하기 때문. 하지만 서로 다른 프로세스의 경우 각자의 메모리 공간에 접근을 할 수 없으므로 동시에 담기지 못한다. -> 결국 프로세스 간의 문맥 교환 시 캐시 메모리를 비워주어야 하고, 스레드의 경우는 그렇지 않고, 캐시 메모리를 비워주는 행위는 high-cost 이므로 스레드의 문맥 교환 속도가 프로세스의 문맥교환속도보다 훨씬 빠르다.) -> high cost 발생. -> 그래서 웬만하면 processor간의 migrating은 피하려고 한다 -->> "processor affinity"
- 프로세스는 현재 실행되고 있는 프로세서에 대해 affinity를 가지고 있다 라고 표현함.
- common ready queue를 사용하는 경우, 스레드는 어떠한 프로세서에도 할당될 수 있다. 그러므로 매 순간순간마다 cache 메모리가 비워지고 써지고를 반복하게 된다.
- 프로세서별로 ready queue가 존재하는 경우, thread는 항상 같은 프로세서에서 schedule될 것이고 결국 warm cache의 이득을 볼 수 있다. -> 이미 per-processor queue는 processor affinity를 제공해주고 있던 셈.
- soft affinity : 보장하지는 않지만 같은 프로세서에서 프로세스가 실행되도록 하는 규정을 운영체제가 가지고 있을 때, 이를 soft affinity라고 한다. -> 예시) 운영체제는 엥간하면 하나의 프로세서에 프로세스를 놓고 싶어하지만, load balancing에 의해서 이는 바뀔 수 있다.
- hard affinity : 프로세스가 실행될 수 있는 프로세서들의 부분집합을 정할 수 있다. (system call)
- sched_setaffinity() system call을 통해서 thread가 실행될 수 있는 CPU의 set을 정해서 hard affinity를 구현하였다.
- Linux에서는 soft/hard affinity 둘 다 구현되어 있다.
- 시스템의 main-memory architecture가 processor affinity에 영향을 끼칠 수도 있는데, NUMA(non-uniform memory access)의 경우가 그렇다.

- 이러한 processor affinity를 통해 얻을 수 있는 이점과 load balancing은 서로 상충된다. -> 잘 조절하는 알고리즘 필요.
Heterogeneous Multiprocessing
- 코어들 자체가 성능이 각각 다른 경우를 말한다. 이러한 시스템을 heterogeneous multiprocessing(HMP)이라고 한다.
- 각 코어마다 성능이 다 다르므로, 각자에게 맡겨진 역할이 다르다.
- big.LITTLE architecture : big core는 higher-performance를, LITTLE cores는 energy efficient하게 동작하게끔 하는 architecture이다.
- asymmetric multiprocessing과 헷갈려서는 안 되는 점
- 코어마다 다른 역할이 부여될 수 있다는 점에서 asymmetric multiprocessing이 Heterogeneous multiprocessing의 부분집합이라고 생각할 수 있지만, asymmetric multiprocessing의 경우 main process의 역할을 아무 core나 할 수 있지만, Heterogeneous multiprocessing의 경우 코어마다 성능이 다 다르므로 특정한 일을 하는 코어는 정해져 있다는 점에서 다르다.
- 장점 : 적은 퍼포먼스를 요구하는 작업의 경우 little core에 배정되어 작업을 수행하게 하면 배터리를 아낄 수 있음. 물론 많은 퍼포먼스를 요구할 경우에는 big core에 배정되어 수행할 것이다. Battery-saving mode를 켜게 되면 많은 퍼포먼스를 요구하는 경우에도 little core에 배정하게 되어 배터리를 극한으로 아낄 수 있다. -> Windows 10이 HMP를 제공한다.
참고 자료
- Abraham Silberschatz, Operating System Concepts, 10th edition
- https://stackoverflow.com/questions/33189536/relation-between-cpus-hyperthreading-and-oss-context-switch
- http://navigatorkernel.blogspot.com/2017/04/coarse-grained-vs-fine-grained.html
참고 자료는 아니지만 읽으면 좋을 것 같은거
