Real-Time CPU Scheduling
- Soft real-time systems : critical real-time process는 noncritical process에 비해 더 높은 preference만 가지게 될 뿐 언제 시작할지는 보장되지 않는다.
- Hard real-time systems : task는 deadline 전에 실행되어야 한다. deadline 이후의 service는 no service나 다름없다.
Minimizing Latency
-
real-time system에서 event가 발생했을 경우를 고려해 보자. event가 발생하면 시스템은 최대한 빨리 반응해서 service해야 하는데, 이 때 event가 발생한 시점과 service되는 시점 사이의 시간간격을 'event latency'라고 한다.
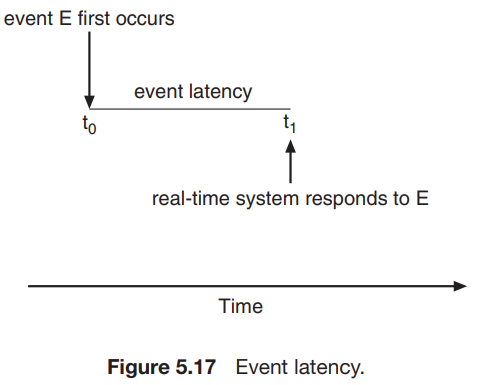
-
event별로 latency requirement가 다르다. 예를들면, 자동차의 브레이크 시스템은 3~5ms정도의 latency requirement를 가진다. 반면에, 비행기에서의 레이더는 몇 초정도의 시간을 가질 수도 있다. real-time system에서 두 종류의 latency가 존재한다.
-
Interrupt latency : 말 그대로 interrupt가 발생하고 service routine이 시작될 때 까지의 시간.
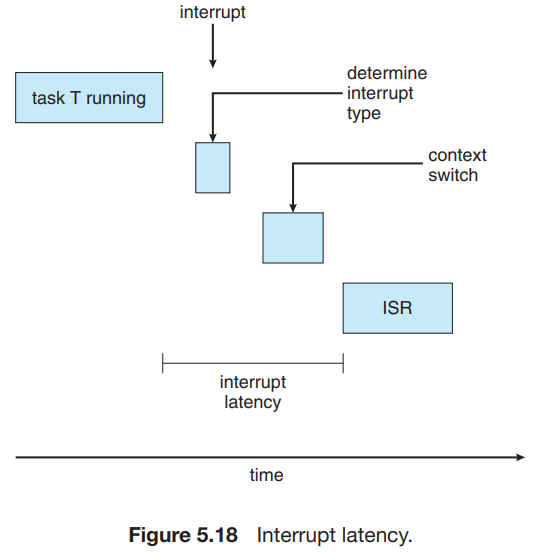
-
Dispatch latency : 실행중인 프로세스를 중지시키고 다른 프로세스를 실행시키는 데에 필요한 시간. 더 정확히는, 프로세스가 ready queue에 있을 때, 이 process를 실행 상태로 만들 때 까지 필요한 시간. 아래 그림을 통해 이해하는 것이 좋을 것 같다.
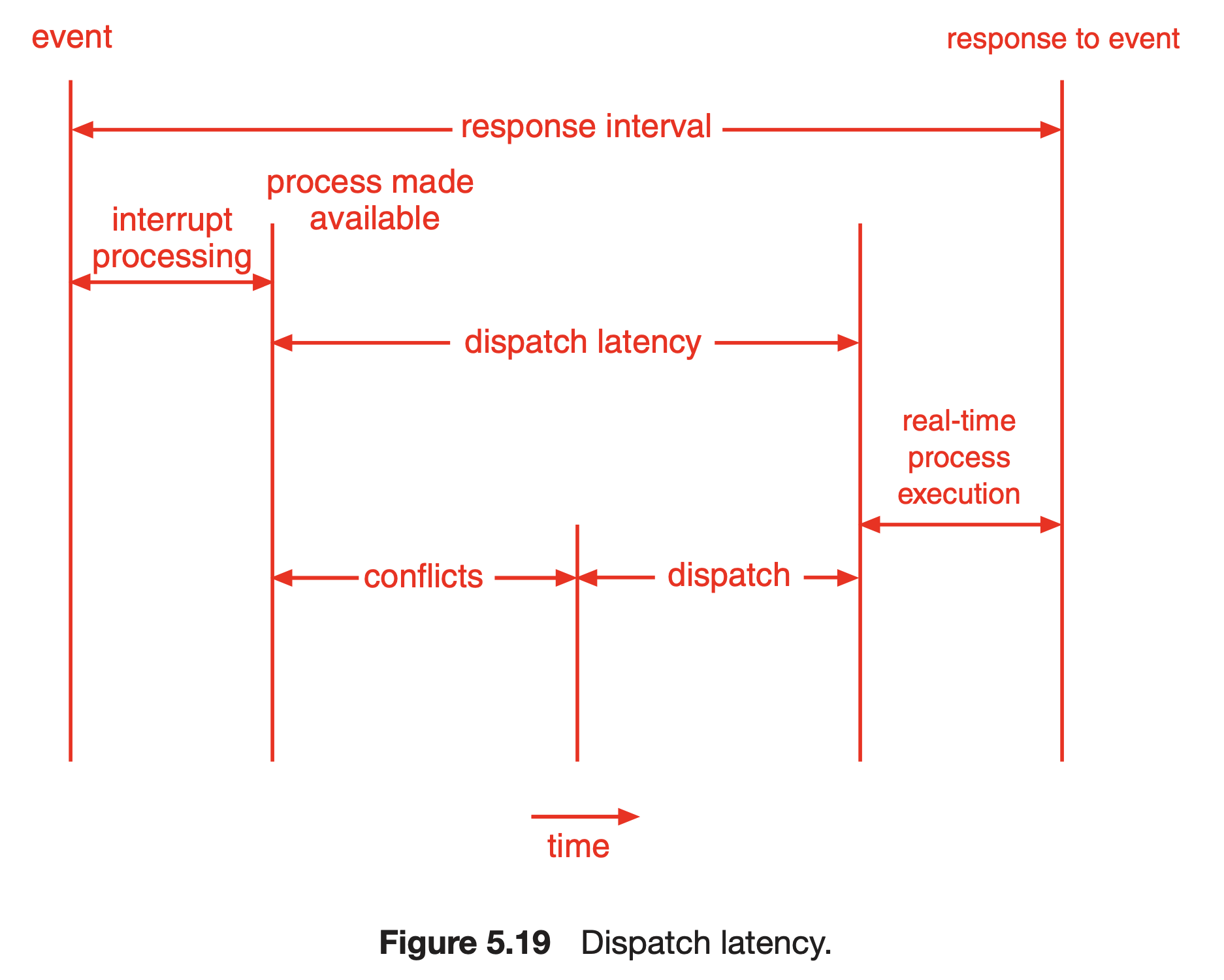
- 보면 process made available 상태가 된 이후에 dispatch latency가 시작되는데, 이 process가 ready queue에 있지 않다면 ready queue로 놓는 과정이 interrupt processing 안에 존재하는 것 같다(?) 사실 잘 모르겠음.. 정확히 interrupt processing이 뭘 하는 작업인지 다시 한 번 더 봐야될듯.
- 예를 들어, I/O에 의해 block된 process가 있다고 하자. 그런데 real-time으로 이 프로세스가 실행되었으면 하는 상황이 발생. -> interrupt occurs -> 현재 실행중이던 프로세스의 context를 PCB에 저장, interrupt service routine 실행 -> service routine 도중에 block되었던 프로세스를 ready-queue로 올리는 작업이 실행됨 -> 그 이후에 다시 실행 흐름이 원래 실행되던 프로세스로 돌아감 -> 그 다음에는 잘 모르겠음..
- conflict phase는 두 요소로 이루어져 있다.
- 커널에서 실행중인 process preempt하기
- 낮은 우선순위를 가진 프로세스가 가지고 있는 자원이 높은 우선순위를 가진 프로세스가 필요로 할 때 release 하기
-
Priority-Based Scheduling
- real-time operating system에서 최대한 반응을 빨리 하기 위해서는 priority-based algorithm과 preempt가 같이 수행되어야 한다.
- 예를 들어, 윈도우에는 32개의 priority level이 존재하고, 16 ~ 31이 real-time process를 위한 값이다.
- 이런 식으로 구성하면 잘 될 것 같지만, 사실 soft real-time system에 해당한다. 왜냐? -> 기존 priority 알고리즘을 기반으로 하면, 예를 들어 time quantum이 3ms인데 deadline이 2ms에 해당하는 경우 이 deadline을 맞추지 못하게 된다. -> 추가적인 방법 필요.
- 앞으로 real-time task의 특징을 다음과 같이 정해서 살펴볼 것이다.
- 프로세스는 주기적이다. : CPU를 특정 주기마다 요청한다.
- fixed processing time : t
- deadline : d
- period : p
- rate of a periodic task : 1/p
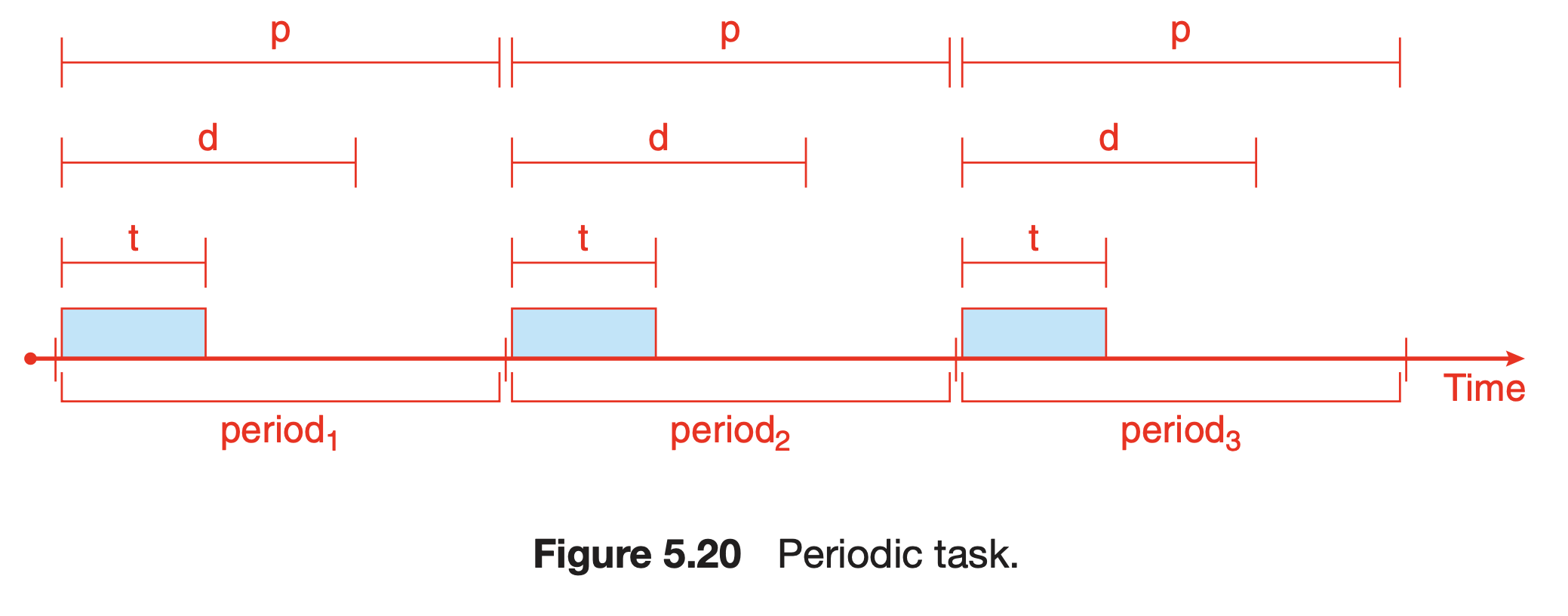
- 이러한 방식은 프로세스가 스케줄러에게 deadline requirement를 알려주어야 한다. -> 그 후 admission-control 알고리즘을 통해 스케줄러는 제 시간 안에 끝낼 수 있다고 보장하면서 그 프로세스를 허용하던가, 아니면 제 시간 안에 끝난다는 것이 보장이 안 되면 거절하던가 둘 중 하나를 선택해야 한다.
- 프로세스는 주기적이다. : CPU를 특정 주기마다 요청한다.
Rate-Monotonic Scheduling
- 기본 원리는 static(바뀌지 않는) priority policy와 preemption을 같이 사용하여 periodic task를 스케줄 하는 것이다.
- higher-priority process가 실행 가능할 때, 현재 실행중인 lower-priority process를 preempt하게 된다.
- priority = 1 / period : 애초에 periodic task를 대상으로 하므로, 주기가 짧다 -> 더 자주 요청한다 -> 우선순위가 높다 로 해석해도 될듯. (기본적으로 CPU burst는 주기에 비례한다는 정보가 없기 때문에 주기가 짧을 수록 먼저 실행되어야 그 다음 CPU 요청이 오기 이전에 deadline을 맞출 수 있다.)
- 가정 : CPU burst = processing time이 아니고, 매 CPU burst 마다 processing time은 일정하다고 가정한다... (영어 이슈..)
- 예시
- : processing time = 20, period = 50
- : processing time = 35, period = 100
- CPU utilization = / + / = 0.75 -> 75%
- 가 보다 높은 우선순위를 가질 경우
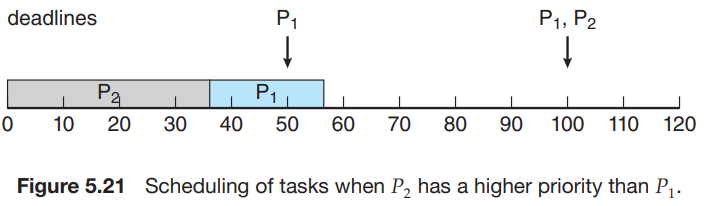
- Deadline에 맞추지 못하게 된다.
- 이 보다 높은 우선순위를 가질 경우 (rate monotonic에 의해 우선순위 = 1/주기 인 경우)

- Deadline에 맞출 수 있다.
- static priority를 가지는 알고리즘 중에 가장 효율적이다..? 라는데 정확히는 잘 모르겠음.
- 안 되는 경우도 존재 : = 50, = 25, = 80, = 35
- CPU utilization = 25/50 + 35/80 = 0.94 -> 될 것 같다.
- 하지만 안 된다.
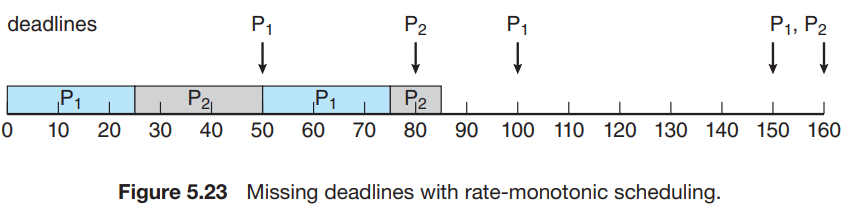
- 한계점 : CPU utilization은 bounded가 되어있다.
- worst-case CPU utilization for N processes =
- 즉, worst-case의 값을 알면 이 안에 들어가는 애들은 rate-monotonic scheduling에 의해 스케줄링 가능, 범위를 벗어나는 경우는 스케줄링 불가능하다.
Earliest-Deadline-First Scheduling(EDF)
- 앞서 봤던 방법은 static priority였지만, EDF의 경우 dynamic priority에 해당한다.
- 이름이 의미하듯, 프로세스가 queue에 들어왔을 때, deadline이 임박한 process의 경우의 우선순위를 제일 높게 선정한다.
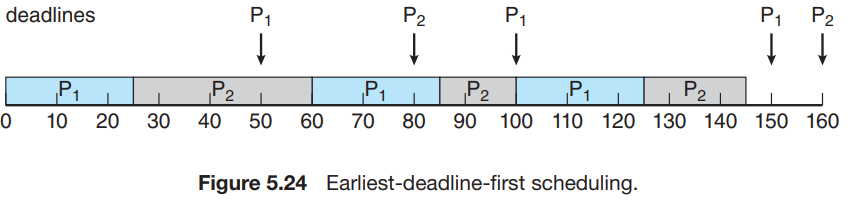
- 앞에서 안 됐던 경우인 = 50, = 25, = 80, = 35를 다시 보자.
- 결국 알고리즘을 봤을 때, 매 순간마다 우선순위와 deadline이 정해지므로, 프로세스는 굳이 주기적이지 않아도 적용된다.
- EDF scheduling은 이론상 optimal하고, 100%의 CPU utilization을 가질 수 있다.(진짜 이론상)
Proportional Share Scheduling
- 전체적으로 T shares를 할당한 후, 각 프로세스가 shares를 나눠 갖도록 한다.
- 예를 들어, T = 100 shares, process A = 50 shares, B = 15 shares, C = 20 shares를 할당받는다고 하면, 각각은 N/T의 비율로 processor time을 가질 것이다.
- 물론 addmission-control policy와 함께 동작해서 프로세스들이 나눠갖는 shares의 개수가 T보다 더 큰 경우 해당 프로세스를 거절(? 표현이 좀 이상한듯)한다.
- TMI : 이렇게 비율을 정하고 나서 할당받는 방법으로 lottery 뭐시기 방법이 있는데, 말 그대로 비율을 확률로 적용해서 매 time slice마다 확률에 따라 선택된 프로세스가 실행되도록 한다. 물론 완전히 그 확률에 해당하지는 않겠지만, 시간이 오래 될 수록 그 값에 수렴할 것이다.
POSIX Real-Time Scheduling
-
POSIX API
-
SCHED_FIFO : FCFS policy, 하지만 time slicing이 없다.
-
SCHED_RR : Round-Robin policy, SCHED_FIFO와 다른 점은 time slicing이 존재한다는 점.
-
SCHED_OTHER : undefined, system마다 다르다.
-
pthread_attr_getschedpolicy(pthread_attr_t *attr, int *policy);
-
pthread_attr_setschedpolicy(pthread_attr_t *attr, int policy);
- 말 그대로 스케줄링 정책을 get하고 set하는 함수들이다. 이 때 위에서 정의된 SCHED_*들이 쓰이게 된다.
-
참고 자료
- Abraham Silberschatz, Operating System Concepts, 10th edition
