Mutex Locks
- hardware수준에서 구현하는 것 -> application 개발자들에게 너무 어려움. -> operating-system designers build higher-level software tools to solve the critical-section problem for application programmers. -> mutex lock
- mutex lock?
- critical section 진입 전에 lock을 acquire() 해야 함.
- critical section 실행 후에 lock을 release() 해야 함.
- mutex lock은 boolean variable인 available을 통해 lock을 얻을 수 있는지 아닌지 판별한다. -> available이면 바로 lock 획득. unavailable이면 available이 될 때까지 blocked 된다.
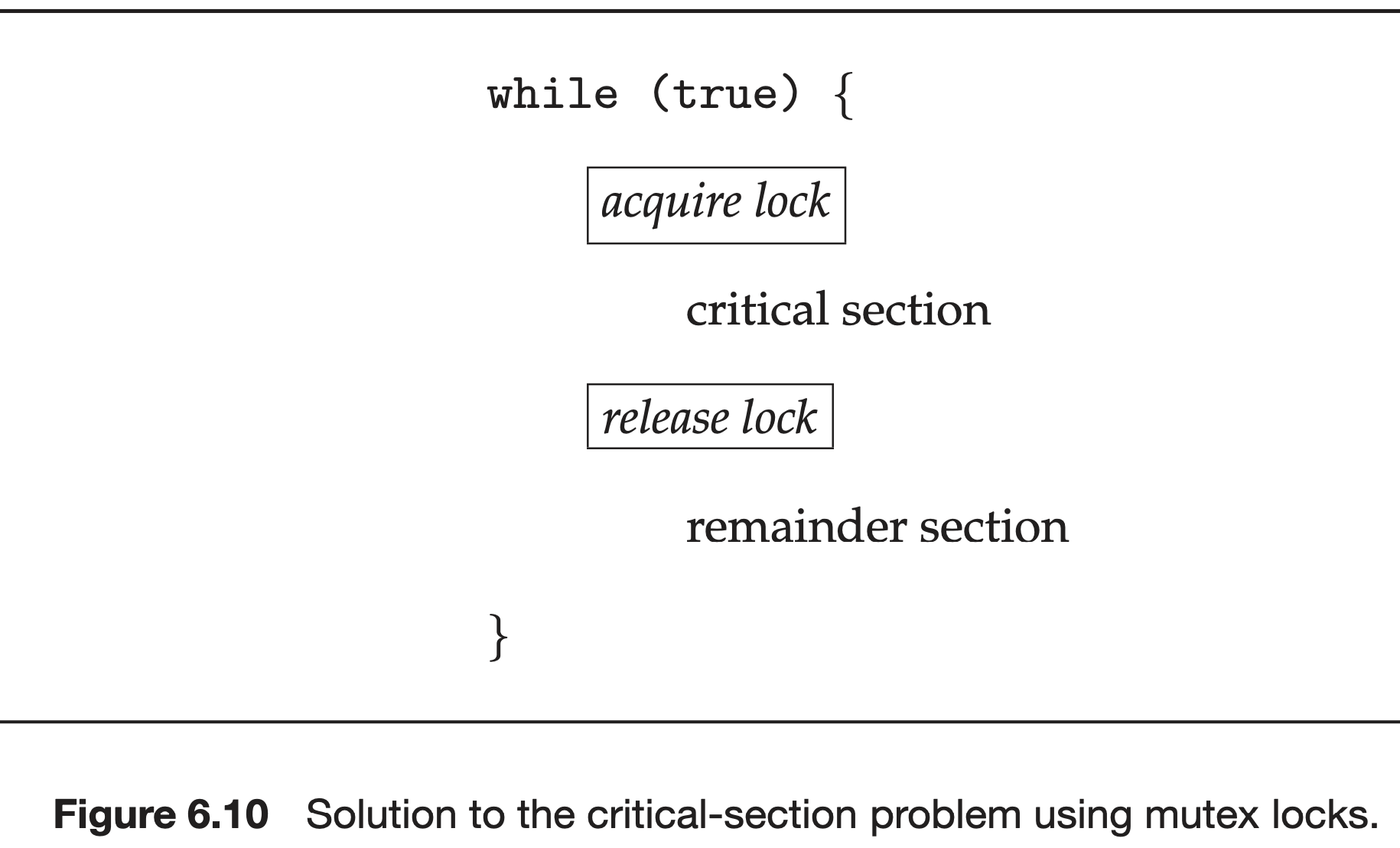
- acquire(), release()의 정의
acquire() { while (!available) ; /* busy wait */ available = false; } release() { available = true; } - 당연히 두 함수는 atomically 실행되어야 한다. -> CAS operation으로 구현될 수 있다.
- CAS로 구현하기
얘만 하면 될듯. 어차피 release()의 경우 acquire()이 일어난 이후에만 동작할 것이므로 동시에 동작하는 경우를 고려하지 않아도 된다.acquire() { while (!compare_and_swap(&available, true, false)) ; }
- CAS로 구현하기
- 지금까지의 방법의 단점 : busy waiting을 해야 함. 즉, critical section에 한 프로세스가 들어가 있는 동안, 나머지 기다리는 프로세스들은 while문을 계속 돌고 있어야 한다 -> CPU 낭비
- 이러한 방법을 spinlock(기다리는 동안 계속 while문을 spin하고 있어서)이라고 부른다.
- 당연히 장점도 존재하는데, context switching하는 데에 필요한 시간이 lock을 사용하는 시간과 비슷할 때, spinlock이 더 효율적이다.
- 추가 내용


Semaphores
- semaphore 'S'
- integer variable
- atomic operation인 wait()과 signal()에 의해서만 접근이 가능.
- wait() -> 'P'
- signal() -> 'V'
- definition of wait()
wait(S) { while (S <= 0) ; // busy wait S--; } - definition of signal()
signal(S) { S++; } - wait()과 signal()에서 정수값을 바꾸는 모든 행위는 atomically 실행되어야 한다.
Semaphore Usage
- counting semaphore : 범위가 정해져 있지 않다.
- binary semaphore : 범위가 0, 1로만 정해져 있다. -> mutex lock과 비슷함.
- Semaphore??
- 유한한 수의 자원에의 접근을 제어하기 위해 쓰인다.
- 사용가능한 자원의 수로 초기화됨.
- resource를 사용하고 싶어하는 각 프로세스는 wait() operation을 수행한다.
- resource를 다 사용하고 나면 signal() operation을 수행한다.
- semaphore count가 0이 되면 모든 자원을 사용중인 것이고, resource를 갖고 싶어하는 프로세스들은 count가 0보다 커질 때 까지 block된다.
- synchronization에 사용되는 예시
- with a statement , with a statement 가 있다고 하자.
- 가 이 끝난 이후에 바로 시작되기를 원한다면, 과 가 common semaphore synch를 공유하게 만들고, 0으로 초기화 시킨다.
- 에서는 다음을 실행시킨다.
;
signal(synch); - 에서는 다음을 실행시킨다.
wait(synch);
;
Semaphore Implementation
-
기존 방법은 busy waiting으로 인한 문제점이 있었다.
-
극복 방법
- wait()
- 똑같이 semaphore value가 양수가 아니면 기다리긴 하는데, 프로세스 자신을 suspend 한다.
- suspend 하는 방법 : semaphore를 위한 waiting queue에다가 프로세스를 집어넣고, 그 프로세스를 waiting 상태로 만든다.
- 그 후 control은 CPU scheduler에게 넘어가서 다음 프로세스가 실행되게 된다.
- signal()
- 어떤 프로세스가 signal() operation을 실행하게 된다면, waiting 상태이던 프로세스는 wakeup() operation에 의해 다시 ready state로 바뀐다. 즉, CPU의 ready queue에 들어가게 된다.
- wait()
-
바뀐 semaphore definition
typedef struct { int value; struct process *list; } semaphore;- process가 semaphore 에서 기다려야 한다면, semaphore의 list에서 기다리게 된다. -> signal() operation이 list에서 한 프로세스를 깨워서 실행되게 한다.
-
바뀐 wait(), signal() definition
wait(semaphore *S) { S->value--; if (S->value < 0) { add this process to S->list; sleep(); } } signal(semaphore *S) { S->value++; if (S->value <= 0) { remove a process P from S->list; wakeup(P); } }- sleep() operation은 호출한 프로세스를 중지시킨다.
- wakeup(P) operation은 그 중지되었던 프로세스 P를 다시 시작시킨다. -> basic system call에 의해 제공된다.
-
waiting process들의 list는 PCB로 구성할 수 있다.
-
bounded waiting을 위해서 list를 FIFO queue로 구성할 수 있다. -> 이 외에도 다른 여러 알고리즘들을 사용 가능.
-
당연히, semaphore operation은 모두 atomically 실행되어야 한다. -> wait(), signal() 모두 동시에 실행될 수 없어야 한다.
- 동시에 실행되면 안 되는 이유 : 만약 semaphore count가 1이고, 두 프로세스가 동시에 wait()을 실행했다고 해 보자. 그러면 count값이 -1이 되고, 두 프로세스 모두 wait queue에 담기는 일이 생기게 되어버린다. -> 절대로 wakeup()이 실행되지 않음.
- single-processor의 경우, 이지하게 위의 operation이 실행하는 동안 interrupt를 모두 차단하면 된다. -> 그러면 그동안 CPU scheduler에게 control이 돌아가지 않게 되어 wait()이나 signal()은 오직 하나만 실행되게 된다.
- multicore의 경우, 모든 processor에서 interrupt를 무시해야 한다. 이유 : 각각의 processor에서 CPU scheduling이 일어날 수 있기 때문. -> 성능 저하로 이어지게 된다. -> SMP system에서는 compare_and_swap()이나 spinlock을 지원해주어야 한다.
-
마지막 정리
- It is important to admit that we have not completely eliminated busy waiting with this definition of the wait() and signal() operations. Rather, we have moved busy waiting from the entry section to the critical sections of application programs. Furthermore, we have limited busy waiting to the critical sections of the wait() and signal() operations, and these sections are short (if properly coded, they should be no more than about ten instructions). Thus, the critical section is almost never occupied, and busy waiting occurs rarely, and then for only a short time. An entirely different situation exists with application programs whose critical sections may be long (minutes or even hours) or may almost always be occupied. In such cases, busy waiting is extremely inefficient. - 본문 발췌
- 여기서 말하는 'we have moved busy waiting from the entry section to the critical sections of application programs'란, naive definition의 경우 프로세스가 완전히 종료하기 전까지 계속 busy waiting을 했었는데, 바뀐 definition에 의해 busy waiting을 하지 않고 semaphore count에 접근하는 데에만 busy waiting이 쓰이게 된다는 것을 의미한다. (예를 들어, S->value의 값을 바꿀 때, mutex를 사용해서 바꾸게 되면, 기존 mutex의 정의에 의해 busy waiting을 통해서 mutex가 동작하게 된다. 하지만 이 busy waiting은 semaphore의 동작 중의 S->value값을 바꾸는 아주 잠깐에 해당할 뿐 이 후에는 바로 process를 block시키기 때문에 이 외에 상황에서는 busy waiting이 발생하지 않게 된다.)
- 결론적으로, 기존에는 프로세스의 critical section이 종료될 때 까지 busy waiting을 했었는데, 바꾼 정의에 의해서 wait()이나 signal()의 critical section(mutex 등으로 구현되는, semaphore count를 변경시키는 영역만을 의미)에서만 busy waiting이 이루어져서 굉장한 효율 증진이 이루어짐을 뜻하는 것 같다.
참고 자료
- Abraham Silberschatz, Operating System Concepts, 10th edition
- https://softwareengineering.stackexchange.com/questions/418789/is-there-still-busy-waiting-in-the-process-blocking-implementation-of-a-semaphor

공부 내용 저장소