📔설명
통계의 정의와 자료 획득 방법을 알아보고, 통계분석과 통계분석 방법을 알아보자.
확률 및 확률분포를 알고, 추정과 가절검정을 알아보자.
통계
간단한 테이블또는그래프에서아주 복잡한 분석 결과까지 형태는 다양
통계자료 획득 방법
총조사샘플링 조사
통계분석의 방법
기술통계통계적 추론
추정
표본으로부터모집단이 가지는 특성(모수)를추측하는 것
가설검정
- 자신이 가진
이론적 대안이통계적으로 의미가 있는지를 확인하는 것
🏓통계분석의 이해
통계
- 특정집단을 대상으로 수행한
조사나실험을 통해 나온결과에 대한요약된 형태
ex) 일기예보, 물가/실업률/GNP, 의식조사와 사회조사 분석 통계, 임상실험 통계 조사또는실험을 통해데이터 확보,조사 대상에 따라총조사(census)와표본조사로 구분
통계자료의 획득 방법
총 조사/전수 조사(Census)
- 대상
집단 모두를 조사하는데많은 비용과시간이 소요되므로 특별한 경우를 제외하곤 사용X
ex) 인구주택 총 조사
표본조사
- 대부분의 설문조사가 표본조사로 진행
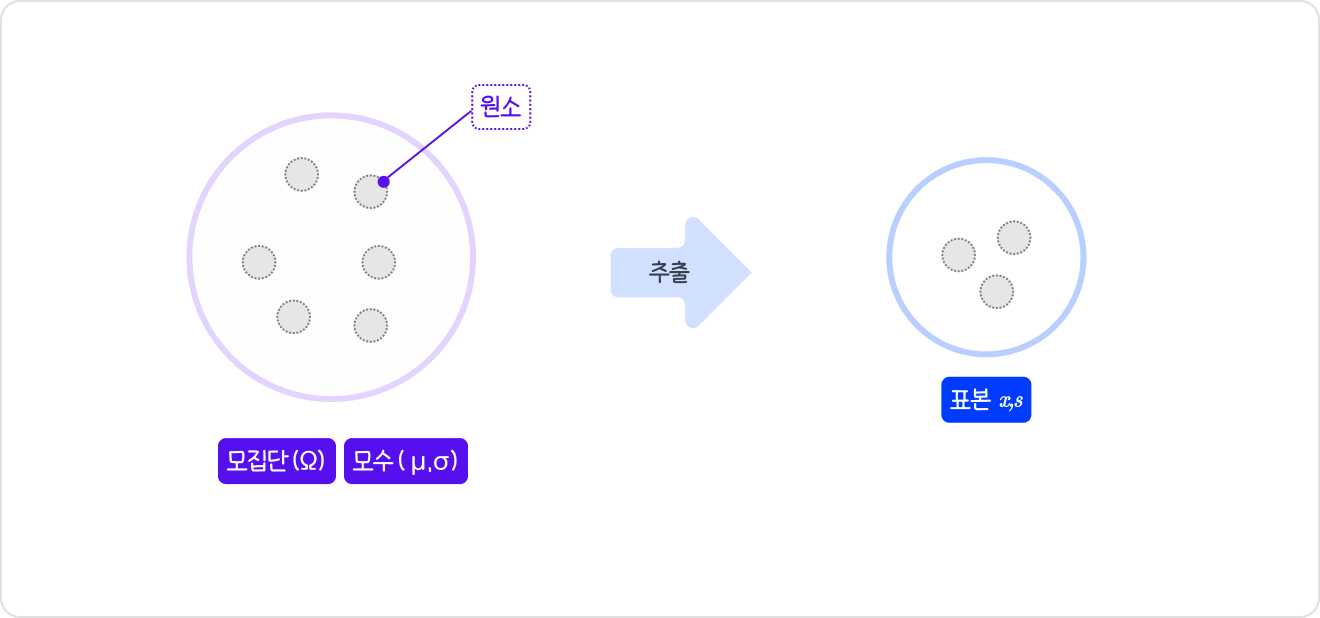
모집단에서샘플을 추출하여 진행모집단(Population): 조사하고자 하는대상 집단 전체원소(Element):모집단을 구성하는개체표본(Sample): 조사하기 위해추출한 모집단의 일부 원소모수(Parameter): 표본 관측에 의해 구하고자 하는모집단에 대한 정보(모집단의 특성)모집단의 정의,표본 크기,조사 방법,조사기간,표본추출방법을 정확히 명시해야 함
*표본오차 : 모집단의 일부인 표본에서 얻은 자료를 통해 모집단 전체의 특성을 추론함으로써 생기는 오차.
-> 모집단을 대표할 수 있는 표본단위들이 조사대상으로 추출되지 못하면 발생
*비표본오차 : 표본오차를 제외한 조사의 전체 과정에서 발생할 수 있는 모든 오차
*표본편의 : 표본추출방법에서 기인하는 오차.
-> 표본추출이 의도된 모집단의 일부 구성원이 다른 구성원보다 더 낮거나 더 높은 표본 추출 확률을 갖는 오차
표본 추출 방법
표본조사의 중요한 점은모집단을 대표할 수 있는표본추출표본 추출 방법에 따라분석결과의 해석은큰 차이 발생
(N개의 모집단에서 n개의 표본을 추출하는 경우)
단순랜덤 추출법(Simple Random Sampling)
- 각 샘플에 번호를 부여해
임의의 n개를 추출하는 방법 - 각 샘플은
선택될 확률이 동일 비복원,복원(추출한 원소를 다시 집어넣어 추출하는 경우)추출
계통추출법(Systematic Sampling)
단순랜덤추출법의 변형된 방식- 번호를 부여한 샘플을
나열하여K개씩 (K=N/n) n개의 구간으로나누고첫 구간(1, 2, ... , K)에서 하나를 임의로 선택한 후에K개씩 띄어서 n개의 표본 선택
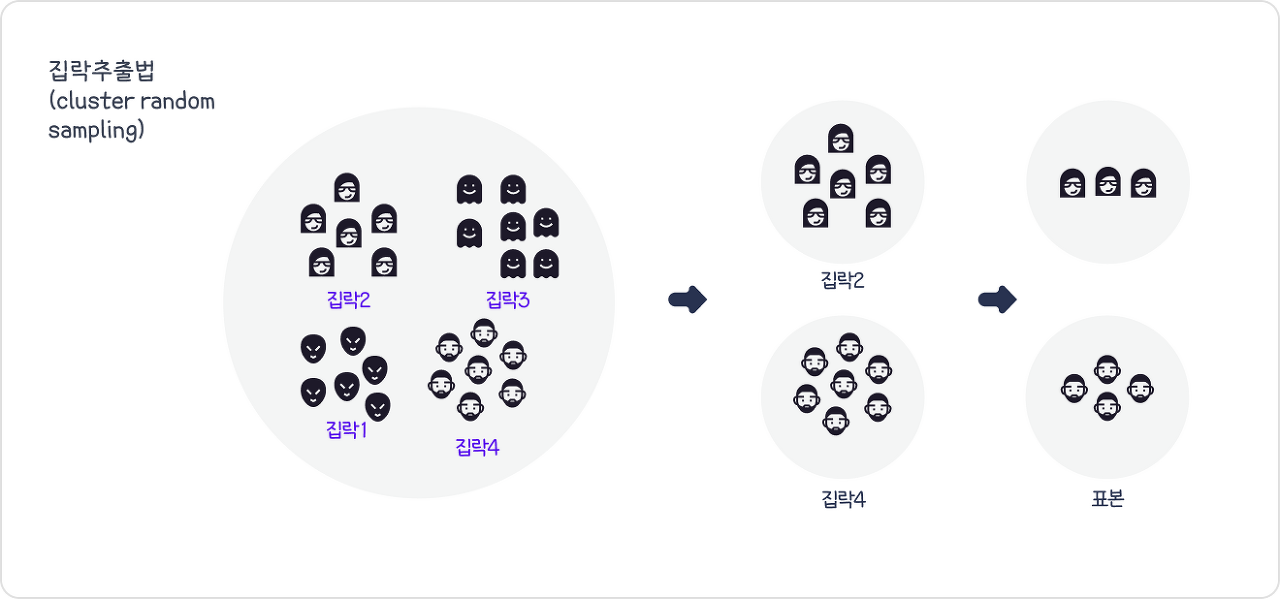
집락추출법(Cluster Random Sampling)
군집을 구분하고군집별로 단순랜덤 추출법을 수행한 후,모든 자료를 활용/샘플링하는 방법지역표본추출,다단계표본추출
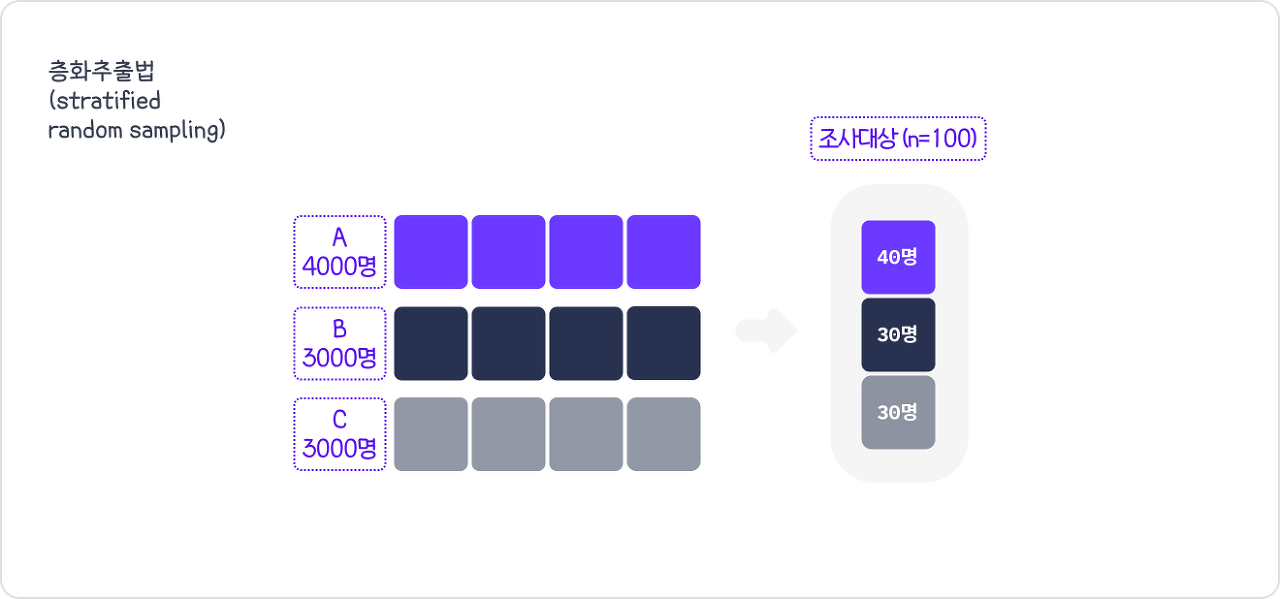
층화추출법(Stratified Random Sampling)
- 이질적인 원소들로 구성된 모집단에서
각 계층을 고루 대표할 수 있도록 표본을 추출하는 방법 유사한 원소끼리몇 개의 층(Stratum)으로 나누어 각 층에서랜덤 추출비례층화추출법,불비례층화추출법
*실험 : 특정 목적 하에서 실험 대상에게 처리를 가한 후, 그 결과를 관측해 자료를 수집하는 방법
측정(Measurement)
표본조사나실험을 실시하는 과정에서추출된 원소들이나실험 단위로부터 주어진목적에적합하도록관측해 자료를 얻는 것
측정방법

서열척도는명목척도와 달리매겨진 숫자의 크기를의미있게 활용가능
ex) 1등이 2등보다 성적이 높다구간척도는절대적 크기를 측정할 수없기때문에사칙연산중더하기/빼기는 가능하나 비율처럼곱하기/나누기는 불가능
통계분석
- 특정한
집단이나불확실한 현상을 대상으로 자료를 수집해 대상집단에 대한 정보를 구하고, 적절한 통계분석 방법을 이용해의사결정을 하는 과정
기술통계(Descriptive Statistic)
: 주어진 자료로부터 어떠한 판단이나 예측과 같은 주관이 섞일 수 있는 과정을 배제하여 통계집단들의 여러 특성을 수량화하여 객관적인 데이터로 나타내는 통계분석 방법론
Sample에 대한 특성인평균,표준편차,중위수,최빈값,그래프,왜도,첨도등을 구하는 것
통계적 추론(추측통계, Inference Statistics)
: 수집된 자료를 이용해 대상 집단(모집단)에 대한 의사결정을 하는 것
Sample을 통해모집단을 추정하는 것
-
모수추정
:표본집단으로부터모집단의 특성인모수(평균/분산 등)를분석하여 모집단 추론 -
가설검정
: 대상집단에 대해특정한 가설을 설정한 후, 그 가설이옳은지 그른지에 대한 채택여부를 결정하는 방법론 -
예측
:미래의불확실성을 해결해효율적인 의사결정을 하기 위해 활용
ex)회귀분석,시계열분석등
확률 및 확률분포
확률
표본공간 S에부분집합인 각사상에 대해 실수값을 가지는 함수의확률값이0과 1사이에 있고,전체 확률의 합이1인 것표본공간 Ω의 부분집합인사건 E의 확률은표본공간 원소의 개수에 대한사건 E의 개수 비율로확률을P(E)라고 할 때, 아래로 정의
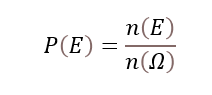
-
표본공간(Sample Space, Ω)
: 어떤 실험을 실시할 때 나타날 수 있는모든 결과들의 집합 -
사건(Event)
:관찰자가관심이 있는 사건으로표본공간의부분집합 -
원소(Element)
: 나타날 수 있는개별의 결과 -
확률변수(Random Variable)
:특정값이 나타날 가능성이확률적으로 주어지는 변수
-
정의역(Domain)이표본공간,치역(Range)이실수값(0<y<1)인함수 -
0이 아닌확률을 갖는 실수값의 형태에 따라이산형 확률변수와연속형 확률변수로 구분 -
확률변수X의 기대값(Expectation, Expected Value): 실험을 반복했을 때평균적으로 기대할 수 있는 값
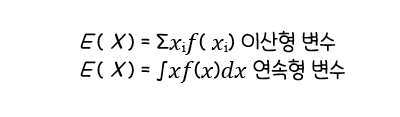
-
확률변수 X의 k차 적률(k-th Moment)
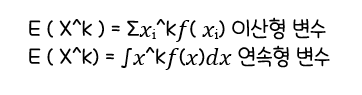
-
확률변수 X의 k차 중심적률(k-th Cental Moment)
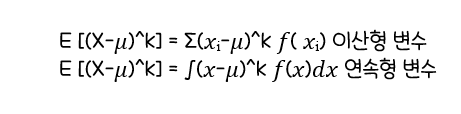
-
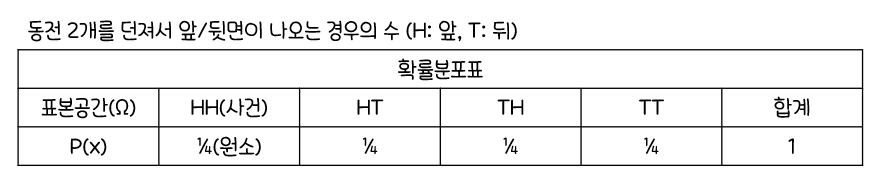
2차 중심적률 E [(X-𝜇)^2]=𝜎^2 : 모분산(Population Variance)기대값의 선형성 이용
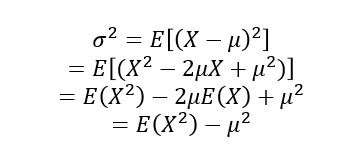
-> 즉,모분산=2차적률-1차적률^2로 해석
-
덧셈정리(배반사건X):사건A와사건B가동시에 일어날 수 있을 때(교집합이 성립할 때),
일어날 확률P(A 또는 B):P(AUB)=P(A)+P(B)-P(A∩B)
=>사건B가 주어졌을 때 사건A의 조건부 확률
:P(A|B)=P(A∩B)/P(B) -
덧셈정리(배반사건O):사건A와사건B가동시에 일어나지 않을 때,
즉사건A 또는 사건 B중어느 한 쪽만 일어날 확률:P(AUB)=P(A)+P(B) -
곱셈정리:사건A와B가서로 무관계하게 나타날 때, 즉독립사건일 때
사건A와 B가 동시에 나타날 확률 P(A와B):P(A∩B)=P(A)XP(B)
=>사건B가 주어졌을 때 사건A의 조건부 확률
:P(A|B)=P(A)
확률분포
이산형 확률변수
-0이 아닌 확률값을 갖는확률 변수를셀 수 있는 경우(확률질량함수)
ex) 동전 2개를 던져서 앞/뒷면이 나오는 경우의 수
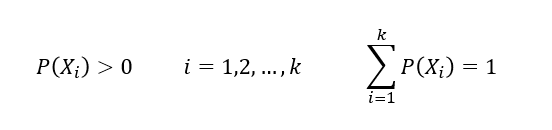
-
베르누이 확률분포(Bernoulli Distribution)
:결과가2개만 나오는 경우
ex) 동전 던지기, 시험의 합격/불합격 등
메이저리거 추신수 선수가안타를 칠 확률은베르누이 분포를 따름
(안타를 치는 사건을 x=1, 안타를 칠 확률은 타율로 적용 가능
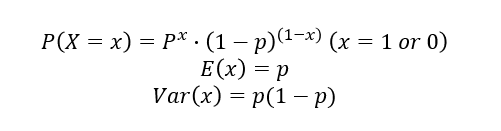
-
이항분포(Binomial Distribution)
:베르누이 시행을n번 반복했을 때k번 성공할 확률
ex) 메이저리거 추신수 선수가 오늘 경기에서5번타석에 들어와서3번안타를 칠 확률은 이항분포를 따른다.
(n=5, k=3, 안타를 칠 확률 P(x)=타율로 적용 가능)
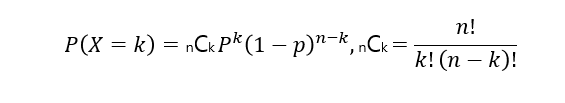
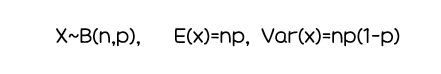
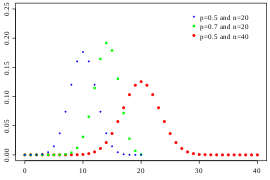
성공할 확률 p가0이나 1에가깝지 않고n이 충분히 크면이항분포는정규분포에가까워짐성공할 확률 P가1/2에 가까우면종모양
-
기하분포(Geometric Distribution)
:성공확률이p인베르누이 시행에서첫 번째 성공이 있기 까지x번 실패할 확률
ex) 메이저리거 추신수 선수가 오늘 경기에서5번 타석에 들어와서3번째타석에서 안타칠 확률은기하분포를 따름 -
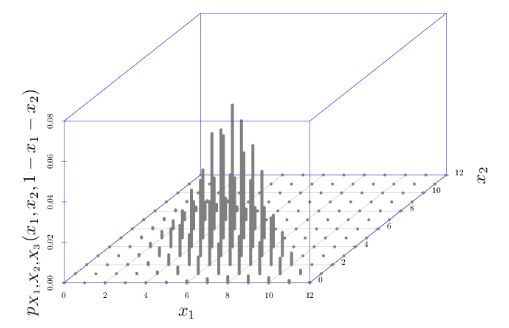
다항분포(Multinomial Distribution)
:이항분포를확장한 것으로,
세 가지 이상의 결과를 가지는반복 시행에서 발생하는 확률 분포
포아송분포(Poisson Distribution)
:시간과 공간내에서 발생하는사건의 발생 횟수에 대한 확률분포
ex) 책에 오타가5page당10개씩 나온다고 할 때,한페이지에 오타가3개나올 확률
메이저리거 추신수 선수가최근 5경기에서10개의 홈런을 쳤을 때,오늘 경기에서 홈런을 못 칠 확률은포아송분포를 따름

연속형 확률변수
-가능한 값이실수의 어느 특정구간 전체에 해당하는 확률변수(확률밀도함수)
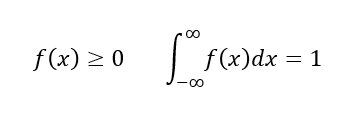
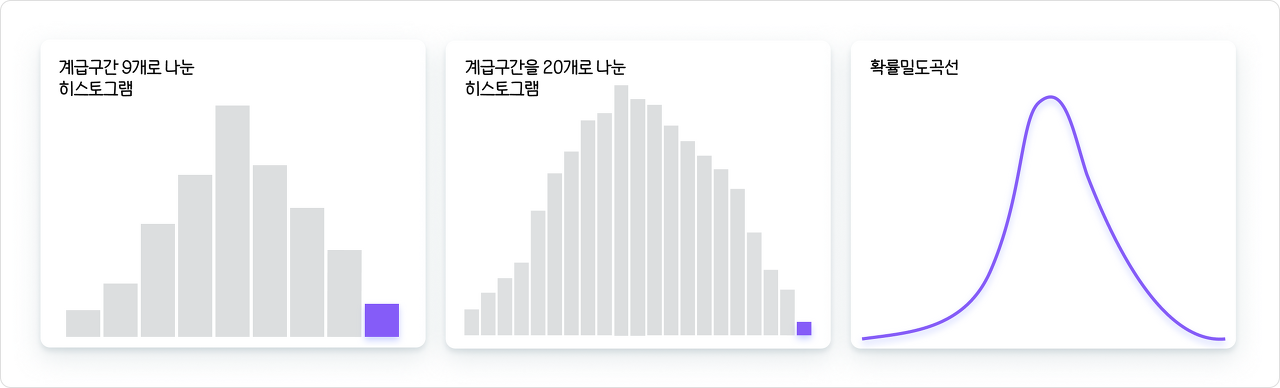
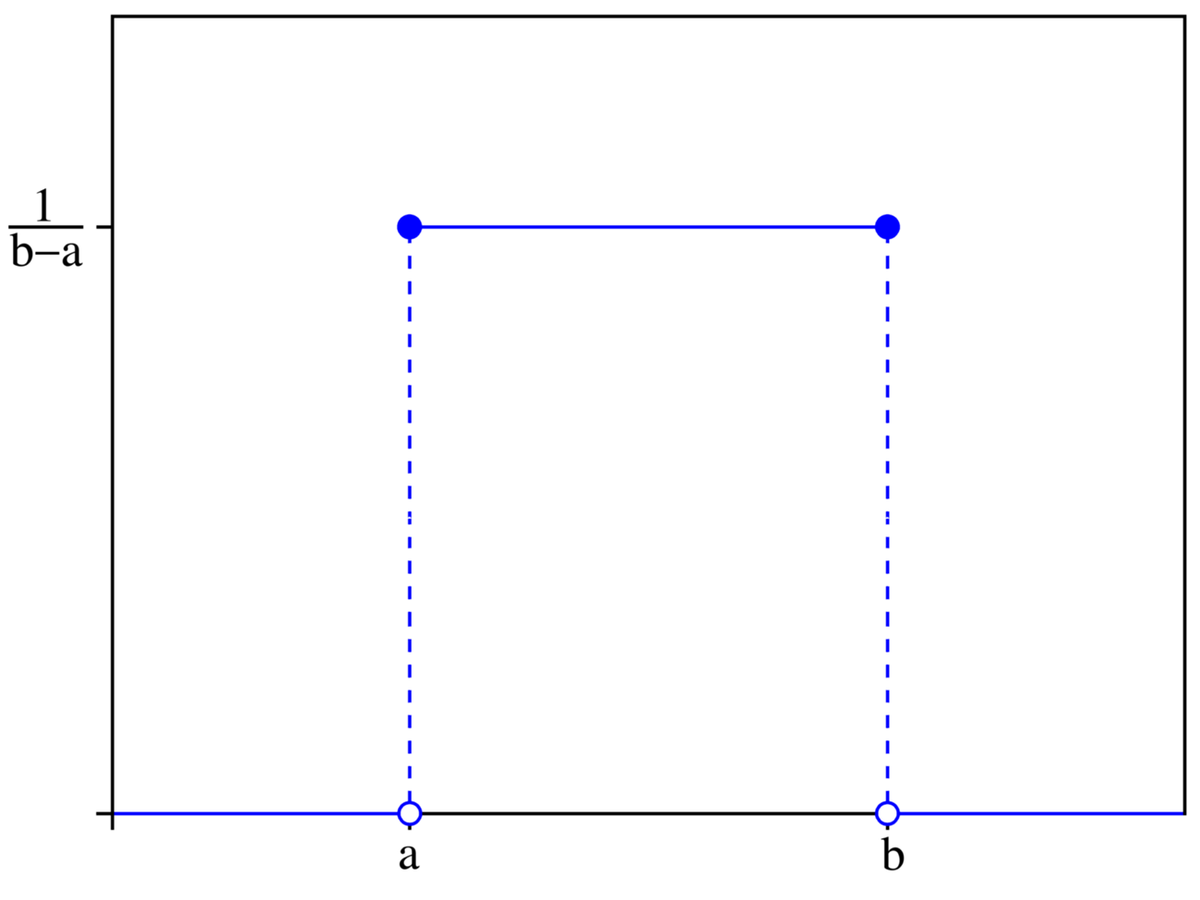
균일분포(일양분포, Uniform Distribution)
:모든 확률변수 X가균일한 확률을 가지는 확률분포
ex) 다트의 확률분포
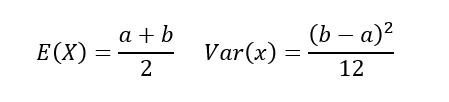
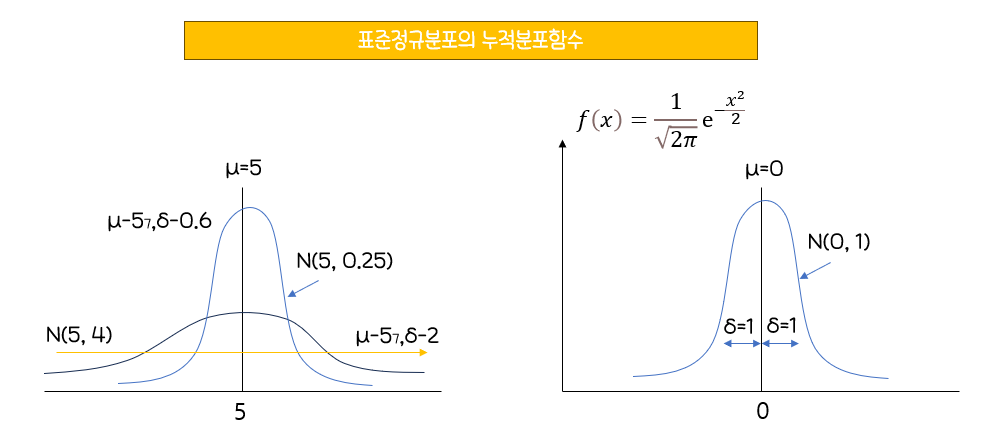
정규분포(Normal Distribution)
:평균이𝜇이고,표준편차가𝜎인x의 확률밀도함수표준편차가클경우퍼져보이는 그래프가 나타남
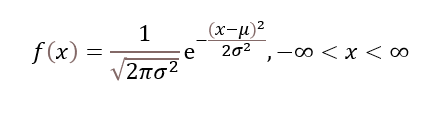
*최소-최대 정규화(Min-Max Normalization)
: (X-Min)/(Max-Min), 원 데이터의 분포를 유지하면서 0~1 사이 값이 되도록 정규화함
*Z-점수 표준화(Z-Score Standardization)
: (X-평균)/표준편차, 원 데이터를 표준정규분포에 해당되도록 표준화
*표준정규분포
: 평균이 0이고 표준편차가 1인 정규분포
-정규분포를 표준정규분포로 만들기 위해선 Z=(X-µ)/𝜎(Z-점수 표준화)식 이용
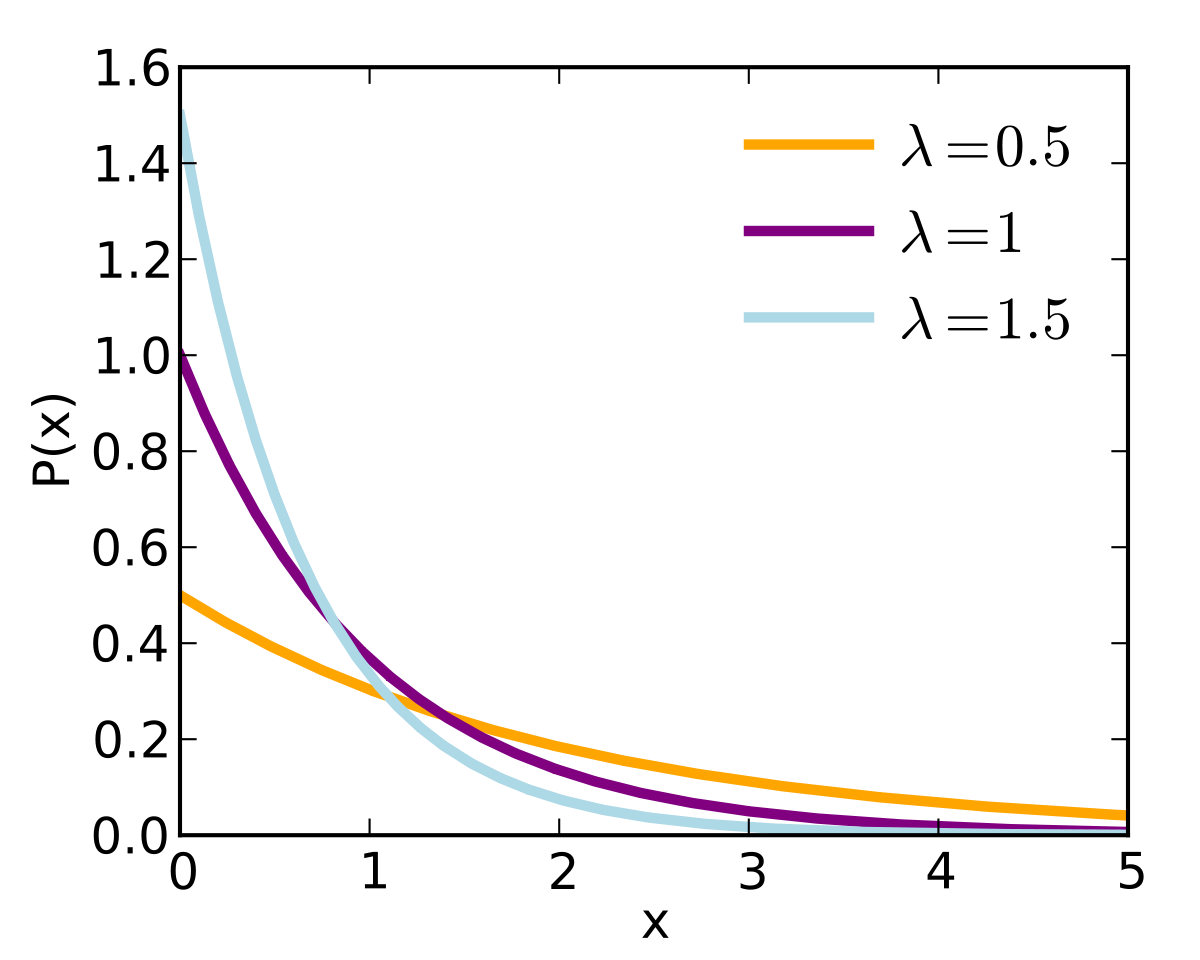
지수분포(Exponential Distribution)
:어떤 사건이발생할 때까지경과 시간에 대한연속확률분포
ex) 전자레인지의 수명시간, 콜센터에 전화가 걸려올 때까지의 시간, 은행에 고객이 내방하는데 걸리는 시간, 정류소에서 버스가 올 때까지의 시간
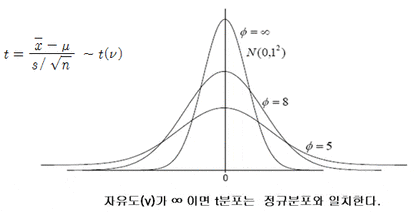
t-분포(t-Distribution)
:표준정규분포와 같이평균이 0을 중심으로좌우가 동일한 분포표본의 크기가적을 때:표준정규분포를위에서 눌러놓은 것표본이 커져서(30개 이상):자유도가 증가하면표준정규분포와거의 같은분포데이터가연속형일 경우 활용두 집단의평균이 동일한지 알고자 할 때검정통계량으로 활용
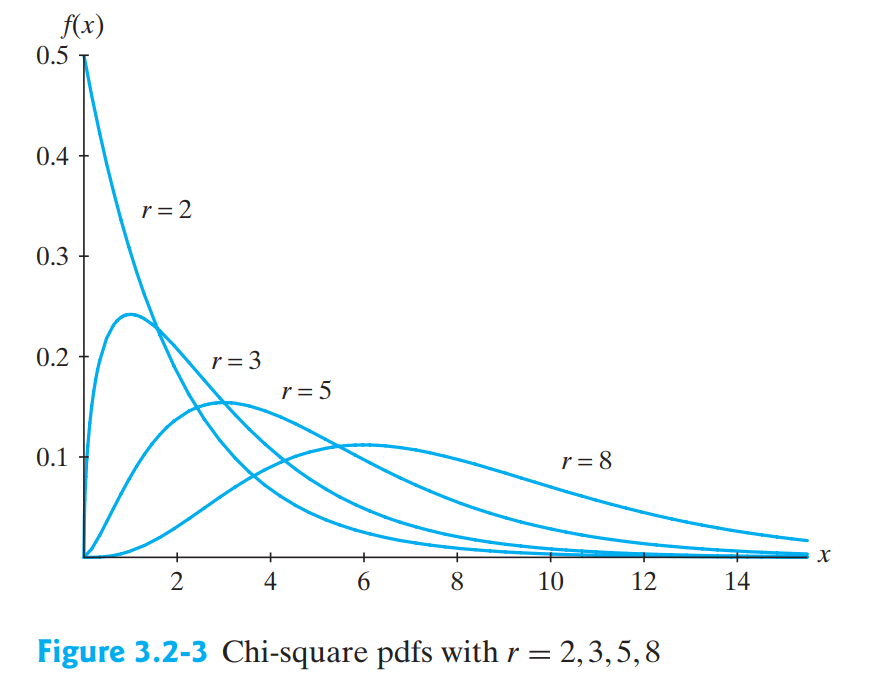
-
χ2-분포(카이제곱분포/Chi-Square Distribution)
:모평균과모분산이알려지지 않은 모집단의모분산에 대한 가설검정에 사용되는 분포두 집단 간의동질성 검정에 활용범주형 자료에 대해 얻어진관측값과기대값의 차이를 보는 적합성 검정
-
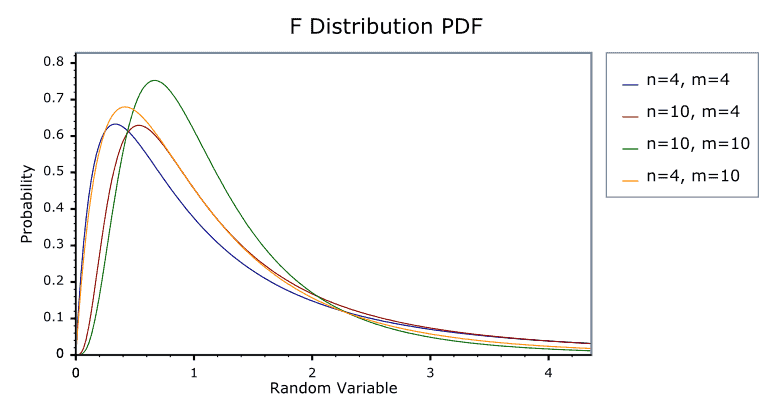
F-분포(F-Distribution)
:두 집단 간분산의 동일성 검정에 사용되는 검정 통계량 분포확률변수는항상 양의 값만을 갖고χ2분포와 달리자유도를 2개가지고 있으며자유도가 커질수록 정규분포에 가까워짐
추정과 가설검정
추정의 개요
확률표본(Random Sample)
확률분포는 분포를 결정하는평균,분산등의모수(Parameter)를 가짐특정한 확률분포로부터독립적으로 반복해표본을 추출- 각
관찰값들은서로 독립적이며동일한 분포를 갖음
추정
-
표본으로부터미지의 모수를추측하는 것 -
점추정과구간추정으로 구분-
점추정(Point Estimation)
:모수가 특정한 값일 것이라고 추정- 표본의
평균,중위수,최빈값등을 사용

- 표본의
-
구간추정(Interval Estimation)
:점추정의정확성 보완을 위해 확률로 표현된 믿음의 정도 하에서모수가 특정한 구간에 있을 것이라고 선언하는 것- 항상
추정량의 분포에 대한 전제가 주어져야 하고,구해진 구간 안에 모수가 있을 가능성의 크기(신뢰수준)이 주어져야 함 n:전체 표본수

- 항상
-
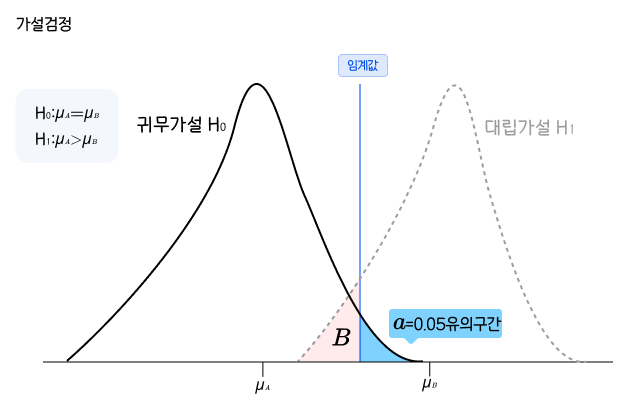
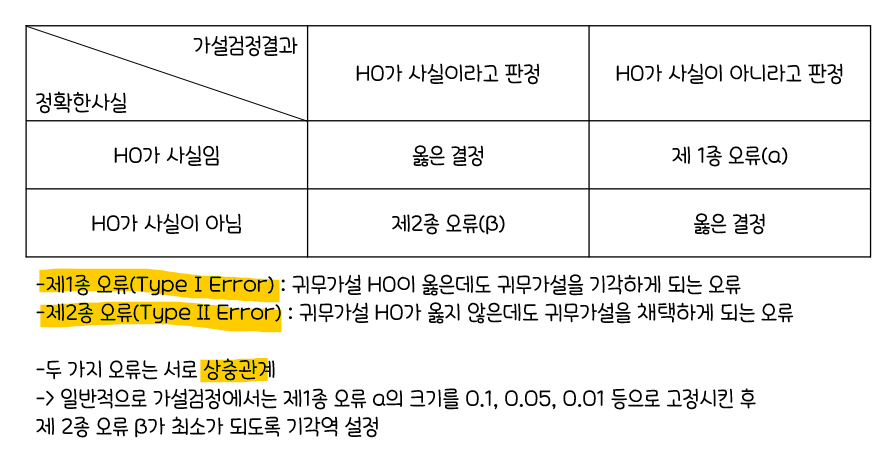
가설검정
모집단에 대한어떤 가설을 설정한 뒤에표본관찰을 통해 그 가설의채택여부를결정하는 분석방법표본관찰또는실험을 통해귀무가술과대립가설중하나를 선택하는 과정귀무가설이 옳다는 전제하에검정통계량 값을 구한 후에 이 값이 나타날가능성의 크기에 의해귀무가설 채택여부 결정
-
귀무가설(Null Hypothesis, 𝐻0)
:비교하는 값과차이가 없다, 동일하다를 기본개념으로 하는 가설
-
대립가설(Alternative Hypothesis, 𝐻1)
:뚜렷한 증거가 있을 때주장하는 가설
-
검정통계량(Test Statistic)
: 관찰된표본으로부터 구하는통계량.
검정 시가설의 진위 판단 기준
-
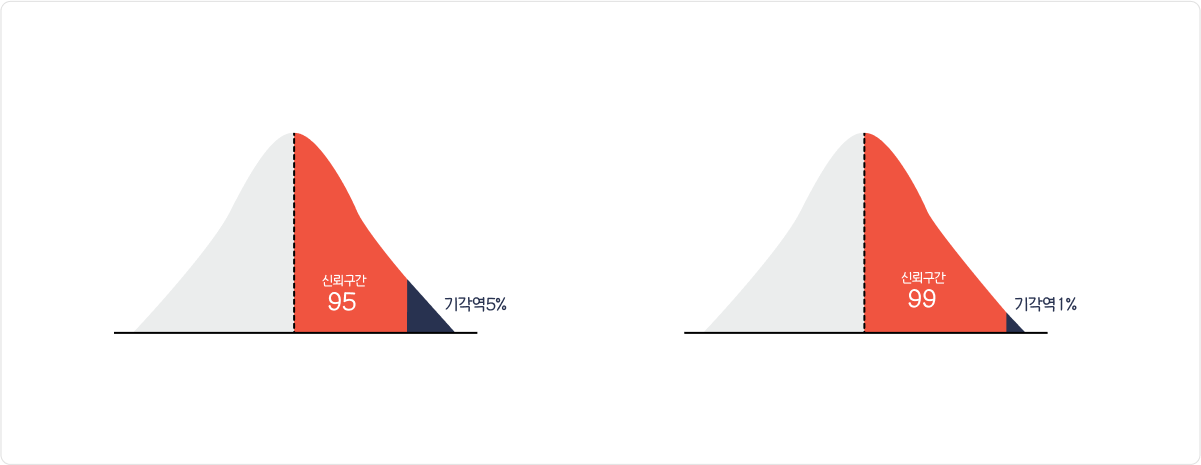
유의수준(Significance Level, 𝛼)
:귀무가설을 기각하게 되는 확률의 크기.
->귀무가설이 옳은데도 이를 기각하는 확률의 크기
-
기각역(Critical Region, C)=P-value=유의구간
:귀무가설이 옳다는 전제하에서 구한검정통계량의 분포에서확률이 유의수준 𝛼인 부분
->반대:채택역(Acceptance Region)
*유의확률(p-value)
: 귀무가설이 맞다고 가정할 때 얻을 수 있는 결과보다 실제값이 더 극단에 위치할 확률
*검정력(Statistical Power)
: 대립가설이 사실일 때, 대립가설을 채택하는 옳은 결정을 할 확률
비모수 검정
모수적 방법
: 검정하고자 하는 모집단의 분포에 대한 가정을 하고, 그 가정하에서 검정통계량과 검정통계량의 분포를 유도해 검정을 실시
비모수적 방법
: 자료가 추출된 모집단의 분포에 대한 아무 제약을 가하지 않고 검정을 실시
관측된 자료가특정분포를 따른다고 가정할 수 없는 경우에 이용- 관측된
자료의 수가 많지 않거나(30개 미만) 자료가 개체 간의서열관계를 나타내는 경우에 이용
모수적 검정과 비모수 검정의 차이점
가설의 설정
-
모수적 검정
:가정된 분포의모수에 대해 가설 설정 -
비모수 검정
:가정된 분포가 없으므로가설은 단지 '분포의 형태가 동일하다' 또는 '분포의 형태가 동일하지 않다' 와 같이분포의 형태에 대해 설정
검정 방법
-
모수적 검정
:관측된 자료를 이용해 구한표본평균,표본분산등을 이용해 검정 실시 -
비모수 검정
: 관측값의 절대적인 크기에 의존하지 않는관측값들의 순위(Rank)나두 관측값 차이의 부호등을 이용해 검정
비모수 검정 예
부호검정(Sign Test)윌콕슨의 순위합 검정(Wilcoxon's Rank Sum Test)윌콕슨의 부호 순위 검정(Wilcoxon's Signed Rank Test)맨-휘트니의 U검정(Mann-Whitney U test)런 검정(Run Test)스피어만의 순위상관계수(Spearmans's rank correlation analysis)
🧈기초 통계분석
기술통계(Descriptive Statistics)
- 자료의 특성을
표,그림,통계량등을 사용하에쉽게 파악할 수 있도록 정리/요약하는 것 자료를 요약하는기초적 통계- 데이터 분석에 앞서 데이터의 대략적인
통계적 수치를 계산함으로써 데이터에 대한대략적인 이해와 앞으로 분석에 대한통찰력을 얻기에 유리 객관적인 데이터
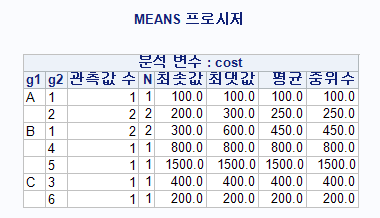
통계량에 의한 자료 정리
중심위치의측도
자료(데이터)
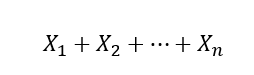
-
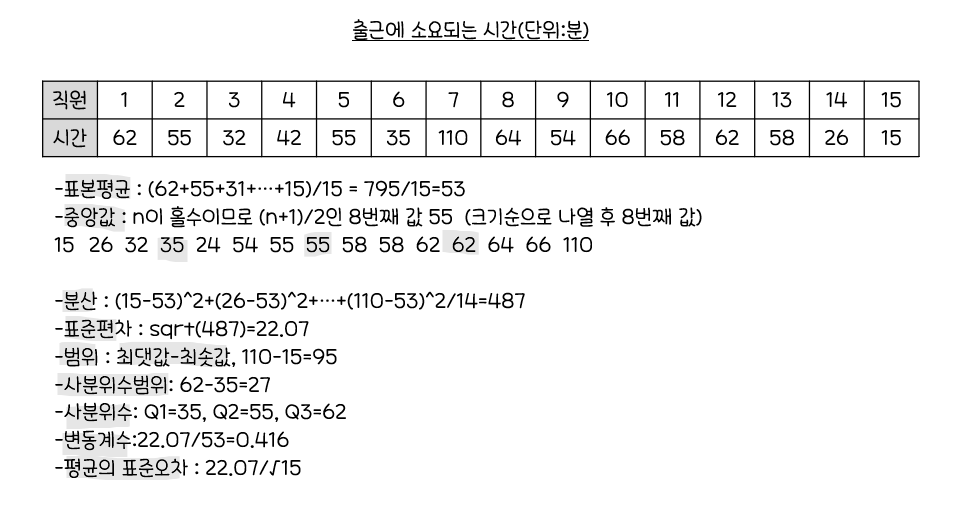
표본평균(Sample Mean)
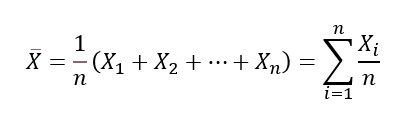
-
중앙값(Median)
: 자료를 크기순으로 나열할 때중앙에 위치하는 자료값
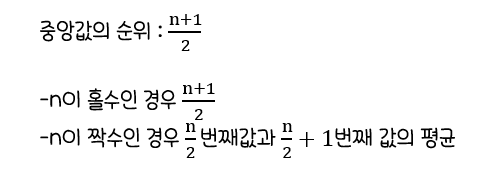
산포의 측도
-대표적인 산포도(Dispersion):분산,표준편차,범위및사분위수범위
-
분산
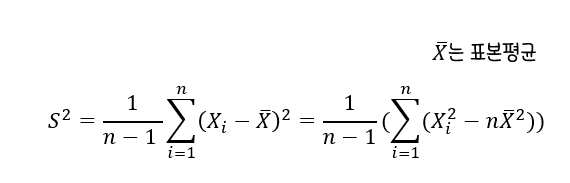
-
표준편차
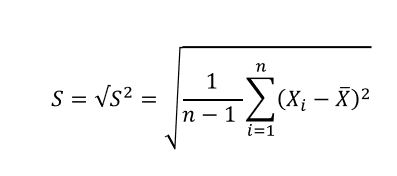
-
사분위수범위(Interquartile Range)IQR:Q3-Q1
-
사분위수- 제 1사분위수(
Q1)=25% - 제 2사분위수(
Q2)=50% - 제 3사분위수(
Q3)=75%
- 제 1사분위수(
백분위수(Percentile)

-
변동계수(Coefficient of Variation)
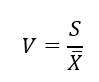
-
표본평균의 표준오차
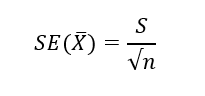
분포의 형태에 관한측도
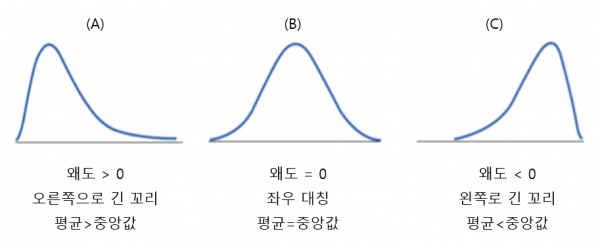
왜도
: 분포의비대칭정도를 나타내는 측도
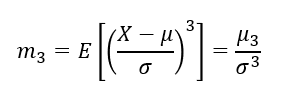
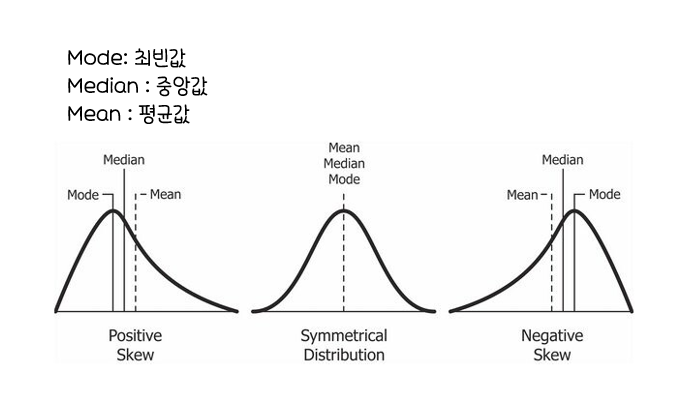
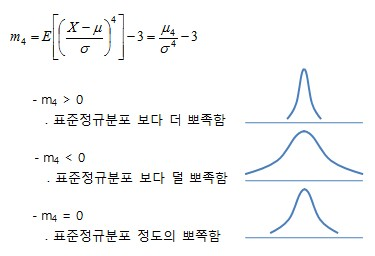
첨도
: 분포의중심에서뾰족한 정도를 나타내는 측도
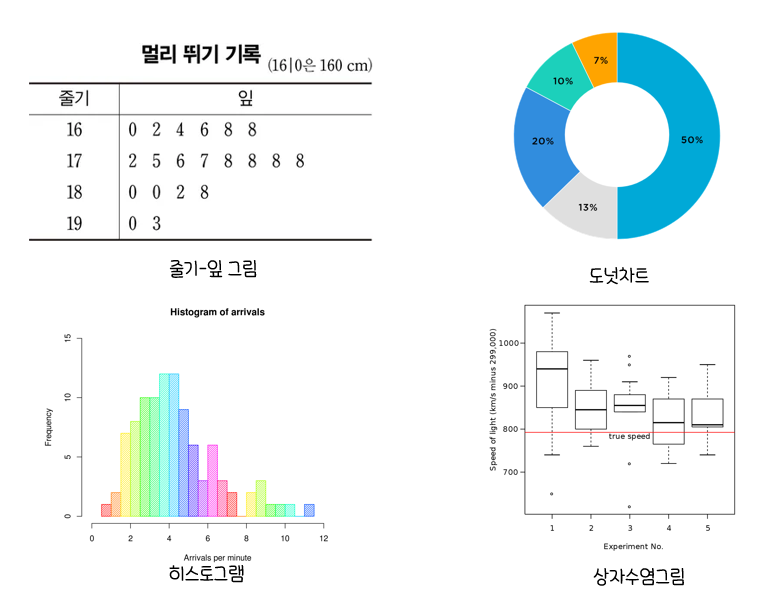
그래프를 이용한 자료 정리
-
히스토그램
:표로 되어 있는도수 분포를그림으로 나타낸 것.
-도수분포표를 그래프로 나타낸 것
-
모자이크 플롯(Mosaic Plot)
:교차표(2원, 3원)를시각화한 그래프.
-사각형들이 그래프에 나열되고사각형의 넓이는범주에 속한 데이터 수(또는 비율)
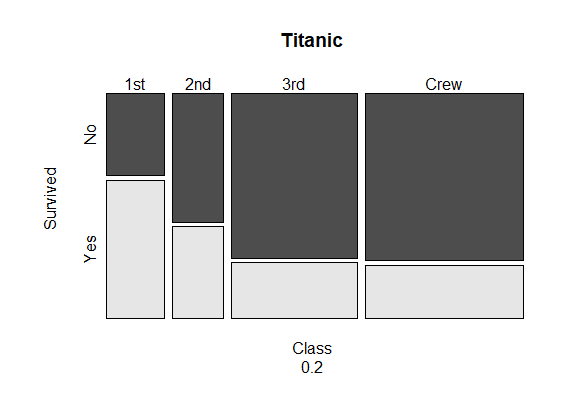
-
막대그래프와히스토그램의 비교
-
막대그래프
:범주(Category)형으로 구분된 데이터(ex. 직업, 종교, 음식 등)를 표현하며범주의 순서를 의도에 따라바꾸기 o -
히스토그램
:연속(Continuous)형으로 표시된 데이터(ex. 몸무게, 성적, 연봉 등)를 표현하며임의로 순서 바꾸기x,막대간 간격x
히스토그램의생성
: 데이터의 수를 활용해서계급의 수와계급간격을 계산하여도수분포표를 만들고 히스토그램 생성
-계급의 수:2^k>=n을 만족하는최소의 정수 log2n=k에서최소의 정수
(k는 계급 수, n은 데이터 수)
계급의 간격은(최댓값-최솟값)/계급수계급의 수와간격이 변하면히스토그램 모양이 변함

-
줄기-잎 그림(Stem-and Leaf Plot)
:데이터를줄기와잎의 모양으로 그린 그림
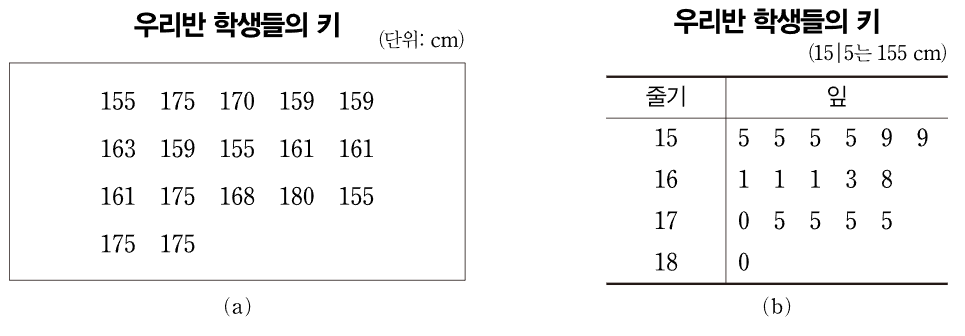
-
상자그림(Box Plot)
:다섯 숫자 요약(최솟값,Q1,Q2,Q3,최댓값)을 통해 그림으로 표현
-사분위수범위(IQR):Q3-Q1
-안울타리(Inner Fence):Q1-1.5xIQR ~ Q3+1.5xIQR
-바깥울타리(Outer Fence):Q1-3xIQR ~ Q3+3xIQR
-보통이상점(Mild Outlier):안쪽울타리와바깥 울타리사이 자료
-극단이상점(Extreme Outlier):바깥울타리밖의 자료
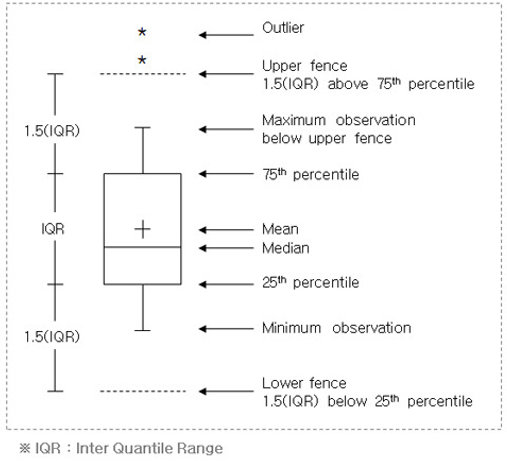
*R에서의 분위수
#특정 컬럼의 분위수를 알고 싶을 때 사용
quantile(data명$column명)인과관계의 이해
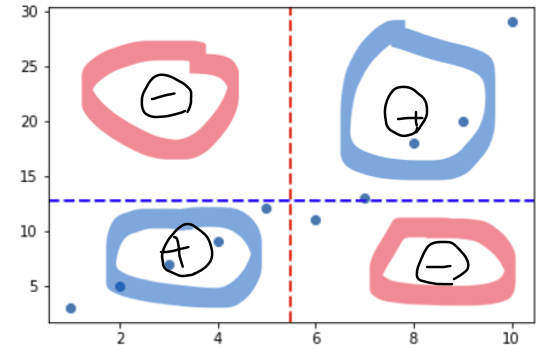
종속변수(반응변수, y) : 다른 변수의 영향을 받는 변수
독립변수(설명변수, x) : 영향을 주는 변수
산점도(Scatter Plot) : 좌표평면 위에 점들로 표현한 그래프
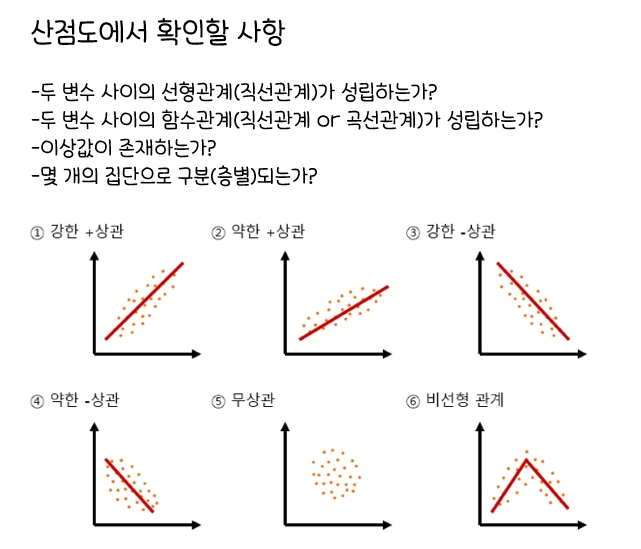
공분산(Covariance)
: 두 확률변수 X, Y의 방향의 조합(선형성)
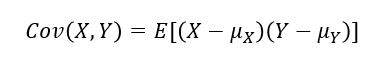
공분산의 부호만으로두 변수 간의 방향성을 확인 가능부호가+:두 변수는양의 방향성부호가-:두 변수는음의 방향성
X, Y가 서로독립:Cov(X,Y)=0
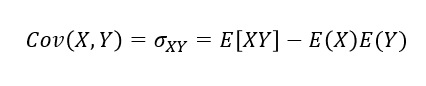
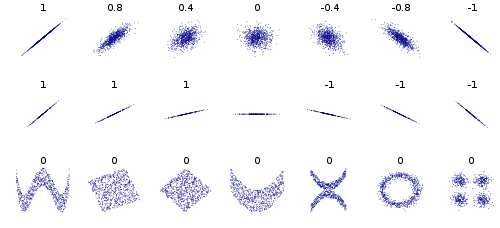
상관분석(Correlation Analysis)
두 변수간의관계의정도를 알아보기 위한 분석방법두 변수의상관관계를 알아보기 위해상관계수(Correlation Coefficient)를 이용
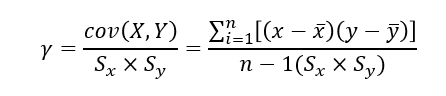
상관관계 특성
| 상관계수 범위 | 해석 |
|---|---|
| 0.7<𝛾<=1 | 강한 양(+)의 상관 |
| 0.3<𝛾<=0.7 | 약한 양(+)의 상관 |
| 0<𝛾<=0.3 | 거의 상관 없음 |
| 𝛾=0 | 상관관계(선형, 직선)가 존재X |
| -0.3<=𝛾<0 | 거의 상관 없음 |
| -0.7<=𝛾<-0.3 | 약한 음(-)의 상관 |
| -1<=𝛾<-0.7 | 강한 음(-)의 상관 |
상관분석의 유형
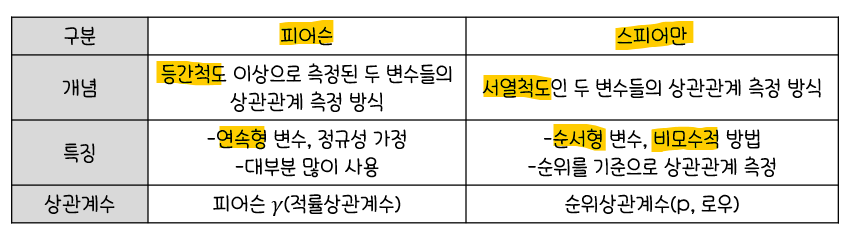
상관분석을 위한 R코드
-x: 숫자형 변수, y:NULL(default) 또는 변수, na.rm : 결측값 처리
분산(var)
var(x,y=NULL, na.rm=FALSE)공분산(cov)
cov(x,y=NULL, use="everything", method=c("pearson","kendall","spearman"))상관관계(cor/rcorr)
cor(x, y=NULL, use="everything", method=c("pearson","kendall","spearman"))
#Hmisc패키지의 rcorr사용
rcorr(matrix(data명), type=c("pearson","kendall","spearman"))
rcorr(x, y, type = c("pearson", "spearman"))상관분석의 가설 검정
상관계수 𝛾가0이면입력변수 x와출력변수 y사이에는아무런 관계가 없다.
(귀무가설:𝛾=0,대립가설:𝛾!=0)t-검정통계량을 통해 얻은p-value 값이0.05이하인 경우대립가설을 채택하게 되어 우리가 데이터를 통해 구한상관계수를 활용가능
상관분석 예제
datasets 패키지의mtcars라는 데이터셋의마일(mpg),총마력(hp)의 상관관계 분석 실시
data(mtcars)
a<-mtcars$mpg
b<-mtcars$hp
cov(a,b)
cor(a,b)
cor.test(a,b,method="pearson")결과 및 해석
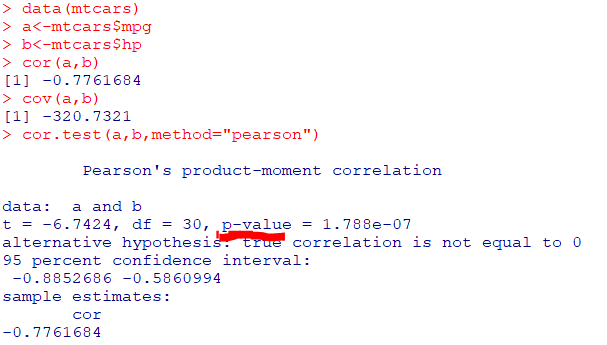
-
mtcars 데이터셋의mpg와hp를 각각a,b에 저장하여mpg와hp의공분산(cov),상관계수(cor)를 구함 -
공분산은-320.7321,상관계수는-0.7761684
->mpg와hp는공분산으로음의 방향성을 가짐을 알 수 있고,
상관계수로강한 음의 상관관계가 있음을 알 수 있음 -
cor.test를 이용해상관관계 분석을 실행 -
p-value가1.788e-07로유의수준 0.05보다 작게나타나상관관계가 있음
->p-value가0.05보다 작으면 통계적으로 유의미
🍠회귀분석
회귀분석의 개요
하나나그 이상의독립변수들이종속변수에미치는 영향을추정할 수 있는 통계기법변수들 사이의인과관계를 밝히고모형을 적합하여 관심있는 변수를예측하거나추론하기 위한 분석방법독립변수의 개수가하나이면단순선형회귀분석,
독립변수의 개수가두 개 이상이면다중선형회귀분석
회귀분석의 변수
영향을 받는 변수(y):반응변수(Response Variable),종속변수(Dependent Variable),결과변수(Outcome Variable)영향을 주는 변수(x):설명변수(Explanatory Variable),독립변수(Independent Variable),예측변수(Predictor Variable)
선형회귀분석의 가정
-
선형성
:입력변수와출력변수의관계가선형
(선형회귀분석에서 가장 중요한 가정) -
등분산성(분산이 같음)
:오차의 분산이입력변수와 무관하게일정.
-잔차플롯(산점도)을 활용하여잔차(표본으로 추정한 회귀식과 실제 관측값의 차이)와입력변수간에 아무런 관련성이 없게무작위적으로 고루 분포되어야 등분산성 가정 만족 -
독립성
:입력변수와오차는관련X
-자기상관(독립성)을 알아보기 위해Durbin-Waston 통계량사용
-시계열 데이터에서 많이 활용 -
비상관성
:오차들끼리상관X -
정상성(정규성)
:오차의 분포가정규분포를 따름.
-Q-Q plot,Kolmogorov-Smirnov 검정,Shaprio-Wilk 검정등을 활용해 정규성 확인
*Anderson-Darling Test
: 콜모고로프-스미르노프 검정(K-S검정)을 수정한 적합도 검정
-특정분포의 꼬리(Tail)에 K-S검정보다 가중치를 더 두어 수행
-여러 분포의 적합도 검정이 가능하지만 정규성 검정에 강력
*D'Agostino-Pearson Test
: 왜도와 첨도를 사용해 데이터가 정규분포를 따르는지 검정(표본크기 20이상)
*Jarque-Bera Test
: 정규분포의 기대 왜도와 첨도가 데이터에서 얻은 값과 일치하는지 검정
그래프를 활용한 선형회귀분석의 가정 검토
-
선형성
:선형회귀모형에서는 아래Linear 그래프와 같이설명변수(x)와반응변수(y)가선형적 관계에 있음이 전제되어야 함
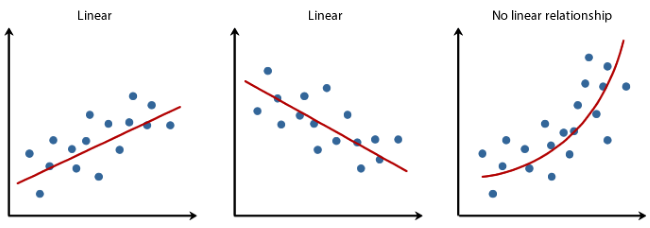
-
등분산성
:설명변수(x)에 대한잔차의 산점도를 그렸을 때, 아래 첫번째 그래프처럼설명변수(x)값에 관계없이잔차들의 변동성(분산)이일정한 형태를 보이면선형회귀분석의 가정중 등분산성 만족
-등분산 가정이 무너진그래프는설명변수(x)가 커질수록잔차의 분산이줄어드는이분산의 형태
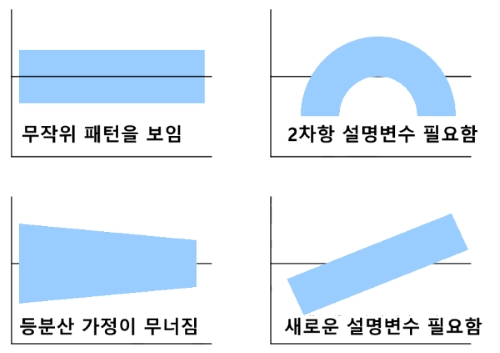
-
정규성
:Q-Q Plot출력시 아래처럼잔차가대각방향의 직선 형태를 지니고 있으면잔차는 정규분포를 따른다고 할 수 있음.
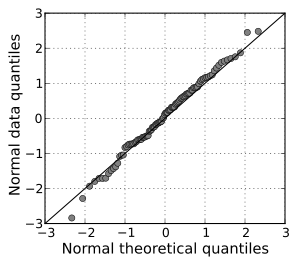
가정에 대한 검증
-
단순선형회귀분석
:입력변수와출력변수간의선형성을 점검하기 위해산점도확인 -
다중선형회귀분석
:선형성,등분산성,독립성,정상성이 모두 만족하는지 확인
단순선형회귀분석
하나의독립변수가종속변수에미치는 영향을추정하는 통계기법
회귀분석에서의 검토사항
-
회귀계수들이유의미한가?
: 해당 계수의t-통계량(평균)의p-값이0.05보다 작으면회귀계수가 통계적으로 유의 -
모형이얼마나 설명력을 갖는가?
:결정계수(𝑅^2)확인
-결정계수는0~1값을 가지며,높은 값을 가질 수록 추정된 회귀식의설명력이 높음 -
모형이데이터를 잘 적합하고 있는가?
:잔차를그래프로 그리고회귀진단
회귀계수의 추정(최소제곱법, 최소자승법)
: 측정값을 기초로 하여 적당한 제곱합을 만들고 그것을 최소로 하는 값을 구하여 측정결과를 처리하는 방법
잔차제곱이가장 작은 선을 구하는 것

회귀분석의 검정
회귀계수의검정
회귀계수 β1이0:입력변수 x와출력변수 y사이에는아무런 인과관계X
->회귀계수 β1이0이면적합된 추정식은아무 의미 없음
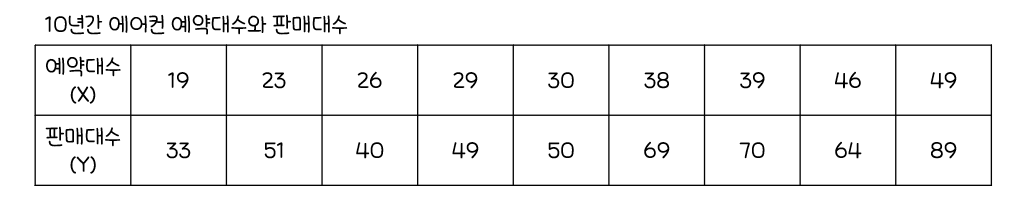
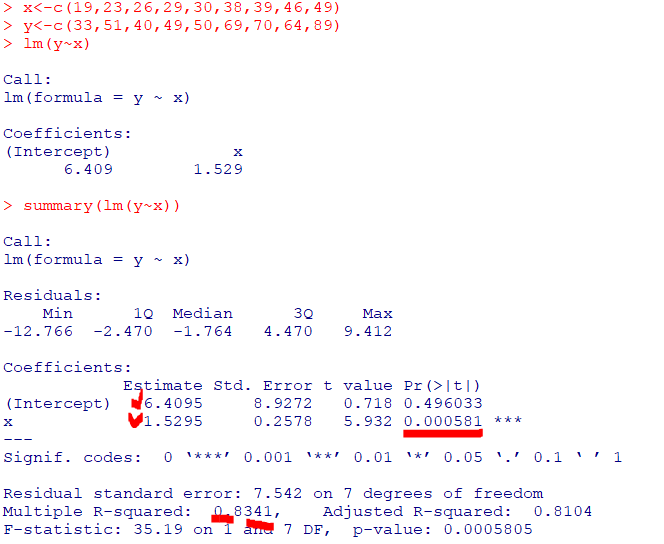
x의 회귀계수인t-통계량에 대한p-값: 0.000581
->유의수준인0.05보다 작으므로회귀계수 추정치들이통계적으로 유의Intercept(절편): 6.409,x(기울기): 1.529결정계수(R-squared): 0.8341
-> 이 회귀식이데이터를 적절하게 설명하고 있다곤 할 수 있음결정계수가 높아데이터의설명력이 높고회귀분석결과에서회귀식과회귀계수들이 통계적으로 유의미하므로에어컨 판대매수를 에어컨 예약대수로 추정 가능
->회귀식:"판매대수(y)=6.4095+1.2595*예약대수(x)"
결정계수
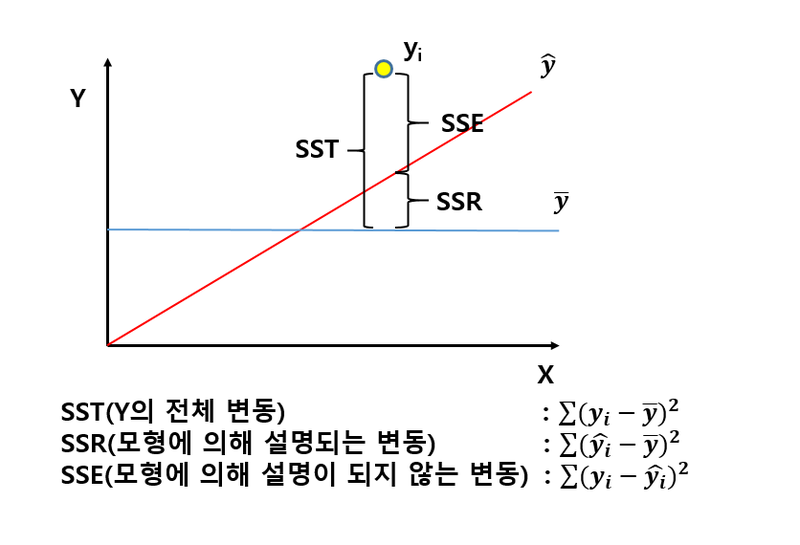
전체제곱합(Total Sum of Squares, SST)
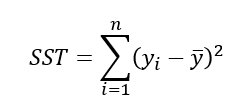
회귀제곱합(Regression Sum of Squares, SSR)
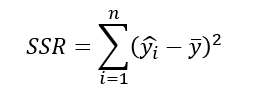
오차제곱합(Error Sum of Squares, SSE)
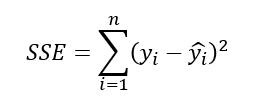
결정계수(R^2)는전체제곱합에서회귀제곱합의비율:SSR/SST
0<=R^2<=1,SST=SSR+SSE결정계수(R^2)는전체 데이터를회귀모형이 설명할 수 있는설명력을 의미단순회귀분석에서결정계수=상관계수 𝛾^2
회귀직선의적합도 검토
-
결정계수(R^2)을 통해추정된 회귀식이얼마나 타당한지검토
(결정계수가1에 가까울수록회귀모형이 자료를 잘설명) -
독립변수가종속변수 변동의몇%를설명하는지 나타내는 지표 -
다변량 회귀분석(다중선형회귀분석)에서는독립변수의 수가 많아지면,결정계수가 높아지므로독립변수가 유의하든, 유의하지 않든독립변수의 수가 많아지면결정계수가 높아지는 단점O
-> 단점 보완을 위해수정된 결정계수(Ra^2 : adjusted R^2)활용 -
수정된 결정계수
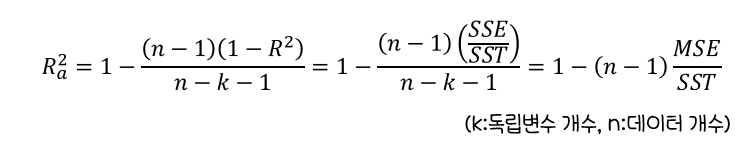
-
수정된 결정계수는결정계수보다작은 값으로 산출 -
MSE:평균제곱 오차
*오차(Error)와 잔차(Residual)의 차이
오차:모집단에서실제값이회귀선과 비교해볼 때 나타나는차이
(정확치와관측치의 차이)잔차:표본에서 나온관측값이회귀선과 비교해 볼 때 나타나는차이.
->회귀모형에서오차항은측정X로잔차를오차항의 관찰값으로 해석하여오차항에 대한 가정들의 성립 여부 조사.
다중선형회귀분석
다중선형회귀분석(다변량회귀분석)
-
다중 회귀식
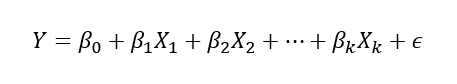
-
모형의통계적 유의성
F-통계량(분산)으로 확인유의수준 5% 이하에서F-통계량의p-값이 0.05보다 작으면 추정된 회귀식은 통계적으로 유의
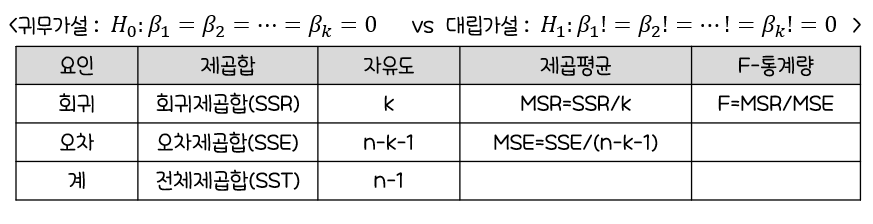
F-통계량이 크면p-value가 0.05보다 작아지고이렇게 되면귀무가설을 기각. 즉,모형이 유의
회귀계수의유의성
단변량회귀분석(단순선형회귀분석)의회귀계수 유의성 검토와 같이t-통계량(평균)으로 확인모든 회귀계수의 유의성이 통계적으로 검증되어야선택된 변수들의 조합으로모형 활용 가능
모형의설명력
결정계수(R^2)나수정된 결정계수(R^2)확인
모형의적합성
모형이데이터를 잘 적합하고 있는지잔차와종속변수의 산점도로 확인
데이터가 전제하는가정을 만족시키는가?
선형성,독립성,등분산성,비상관성,정상성
다중공선성(Multicollinearity)
다중회귀분석에서설명변수(x) 사이에 선형관계가 존재하면회귀계수의 정확한 추정곤란다중공선성검사 방법분산팽창요인(VIF):4보다 크면다중공선성존재,10보다 크면심각한 문제상태지수:10이상이면문제O,30보다 크면심각한 문제다중선형회귀분석에서다중공선성의 문제가 발생하면,문제가 있는 변수를제거or주성분회귀,능형회귀 모형을 적용하여 해결
회귀분석의 종류
단순회귀 : 독립변수가 1개, 종속변수와의 관계가 직선
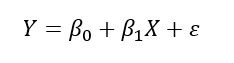
다중회귀 : 독립변수가 k개, 종속변수와의 관계가 선형(1차 함수)
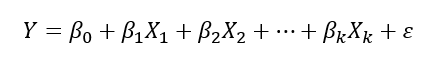
로지스틱 회귀 : 종속변수가 범주형(2진변수)
-단순 로지스틱 회귀/다중/다항 로지스틱 회귀
-exp=e^
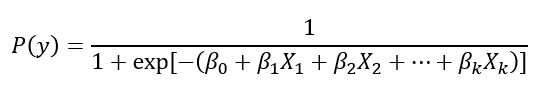
다항회귀 : 독립변수와 종속변수와의 관계가 1차함수 이상인 관계
-단, k=1이면 2차 함수 이상, k는 항의 수
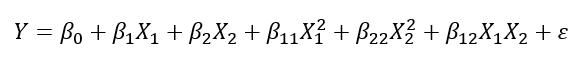
곡선회귀 : 독립변수가 1개, 종속변수와의 관계가 곡선
-2차 곡선인 경우
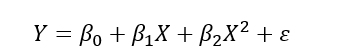
-3차 곡선인 경우
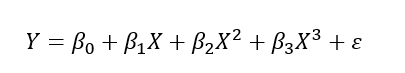
비선형 회귀 : 회귀식의 모양이 미지의 모수들의 선형관계로 이뤄져 있지 않은 모형
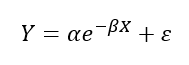
회귀분석 사례
R프로그램을 통한 회귀분석
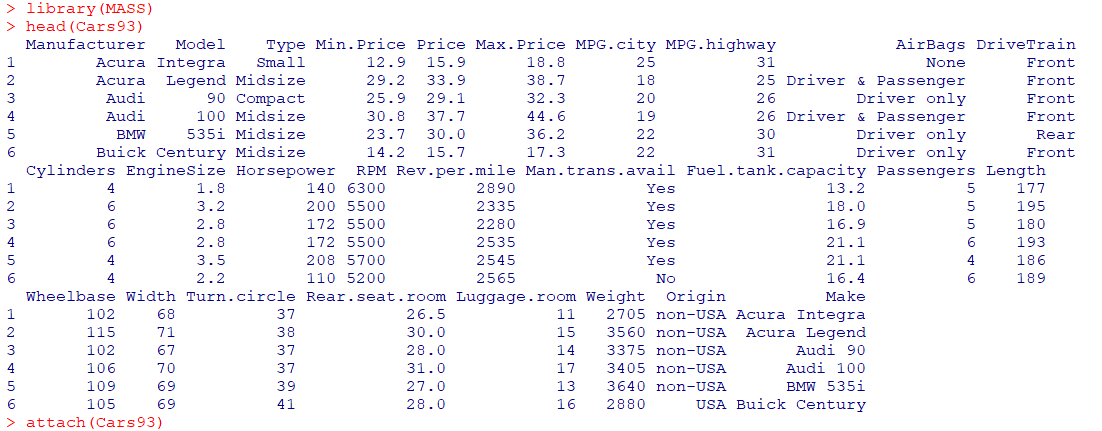
MASS 패키지의Car93데이터셋의가격(Price)를종속변수(y)로 선정하고엔진 크기(Engine-Size), RPM, 무게(Weight)를 이용해서다중회귀분석실시
library(MASS)
head(Cars93)
attach(Cars93) #데이터를 R 검색경로에 추가해 변수명으로 바로 접근 가능
lm(Price~EngineSize+RPM+Weight, data=Cars93) #lm 선형회귀분석
summary(lm(Price~EngineSize+RPM+Weight, data=Cars93))- 결과 및 해석
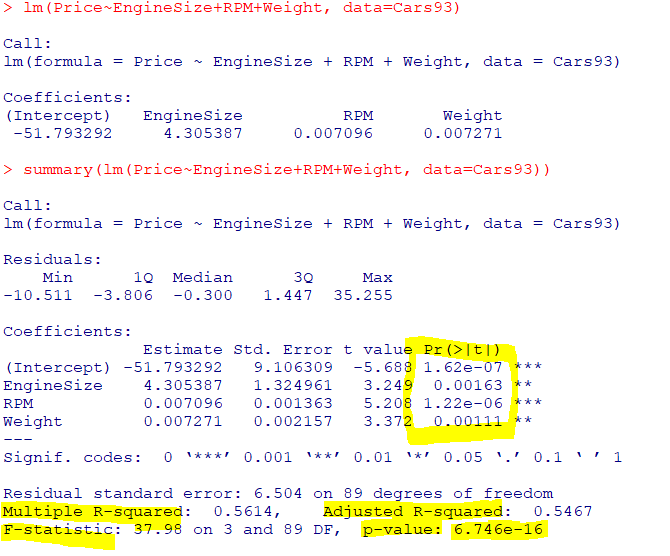
F-통계량: 37.98,p-value(유의확률): 6.746e-16
-> 유의수준 5%하에서 추정된회귀모형이 통계적으로매우 유의함결정계수: 0.5614 ,수정된 결정계수: 0.5467
-> 조금 낮게 나타나회귀식이 데이터를적절하게 설명하고 있다곤 할 수 X회귀계수들의p-값이 0.05보다 작으므로회귀계수의 추정치들이 통계적으로 유의결정계수가 낮아데이터설명력은 낮으나, 회귀분석 결과에서회귀식과회귀계수들이통계적으로 유의하여자동차의 가격을엔진의 크기,RPM,무게로 추정 가능
R프로그램을 통한 로지스틱 회귀분석
- 데이터 설명 :
림프절이전립선 암에 대해양성인지 여부를예측하는 데이터
| 변수명 | 설명 |
|---|---|
| 양성여부(r) | 전립선암에 대한 양성 여부 |
| age | 환자의 연령 |
| stage | 질병 단계 : 질병이 얼마나 진행되어 있는지 나타내는 척도 |
| grade | 종양의 등급 : 진행의 정도 |
| xray | x-선 결과 |
| acid | 특정한 부위에 종양이 전이되었을 때 상승되는 혈청의 인산염값 |
- 분석 결과
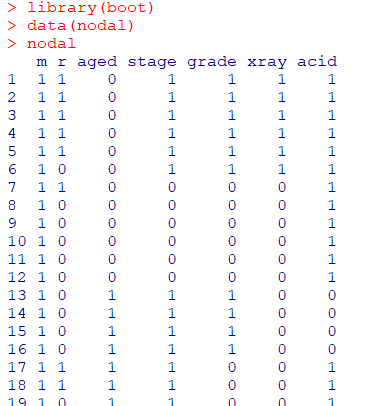
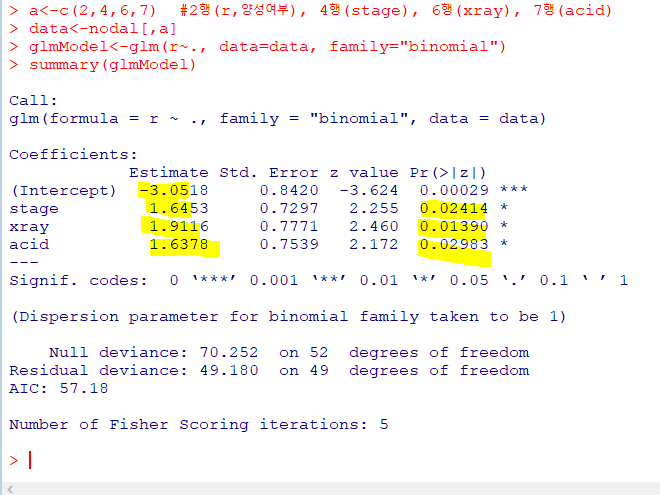
glm:로지스틱 회귀분석2번째 변수인양성여부(r)를종속변수(y)로 두고,5개의 변수를독립변수(x)로 하여로지스틱 회귀분석실시age와grade는유의수준 5%하에서유의X로 이를 제외한3개의 변수(stage, xray, acid)를 활용해 모형 개발stage, xray, acid의추정계수는유의수준 5%하에서유의하게 나타나므로
p(r=1)=1/(1+exp-(-3.05+1.65stage+1.91xray+1.64acid))의선형식가능
최적회귀방정식
최적회귀방정식의 선택
설명변수(x) 선택
:필요한 변수만 상황에 따라타협을 통해 선택
y에영향을 미칠수 있는모든 설명변수 x들을y의 값을 예측하는 데참여- 데이터에
설명변수 x들의 수가많아지면관리하는데 많은 노력이 요구되므로, 가능한범위 내에서적은 수의설명변수 포함
모형선택(Exploratory Analysis)
:분석 데이터에가장 잘 맞는 모형을 찾아내는 방법
모든 가능한 조합의 회귀분석(All Possible Regression):모든 가능한 독립변수들의조합에 대한회귀모형을 생성한 뒤가장 적합한 회귀모형 선택
단계적 변수선택(Stepwise Variable Selection)
-
전진선택법(Forward Selection):절편만 있는 상수모형으로부터 시작해 중요하다고 생각되는설명변수부터 차례로 모형에추가
-변수의 개수가많은경우에도 사용 가능
-변수값의 작은 변동에도그 결과가 크게 달라짐=>안정성 부족 -
후진제거법(Backward Elimination):독립변수 후보 모두를 포함한 모형에서 출발해가장 적은 영향을 주는변수부터 하나씩제거하면서 더 이상제거할 변수가 없을 때의 모형 선택
-변수의 개수가많은경우 사용하기 어려움
-전체 변수들의 정보를이용 -
단계선택법(Stepwise Method):전진선택법에 의해변수를 추가하면서새롭게 추가된 변수에 기인해기존 변수의 중요도가약화되면해당 변수를 제거하는 등 단계별로추가또는제거되는 변수의 여부를 검토해더 이상 없을 때 중단
벌점화된 선택기준
: 모형의 복잡도에 벌점을 주는 방법
방법
AIC(Akaike Information Criterion)
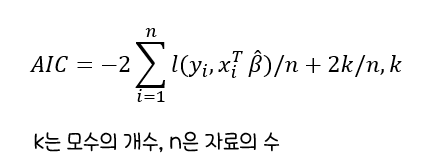
BIC(Bayesian Information Criterion)
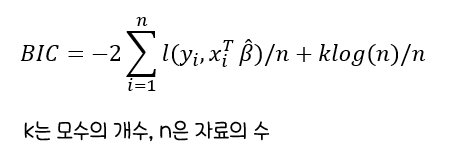
설명
- 모든
후보 모형들에 대해AIC또는BIC를 계산하고,그 값이 최소가 되는 모형을 선택 모형선택의 일치성(Consistency Inselection)
:자료의 수가늘어날 때참인 모형이 주어진 모형 선택 기준의최소값을 갖게 되는 성질AIC는일치성 성립X,BIC는주요 분포에서 성립AIC활용이 보편화된 방법- 그 외의
벌점화 선택기준:RIC(Risk Inflation Criterion),CIC(Covariance Inflation Criterion),DIC(Deviation Information Criterion)
최적회귀방정식의 사례
변수 선택법 예제(유의확률 기반)
x1, x2, x3, x4를 독립변수로 가지고y를 종속변수로 가지는선형회귀모형을 생성한 뒤,step()함수를 이용하지 않고직접후진제거법을 적용하는 R코드 작성
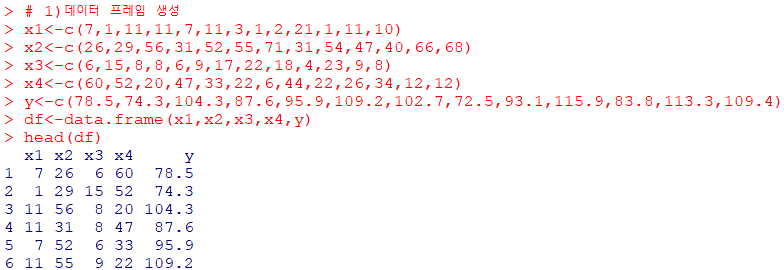
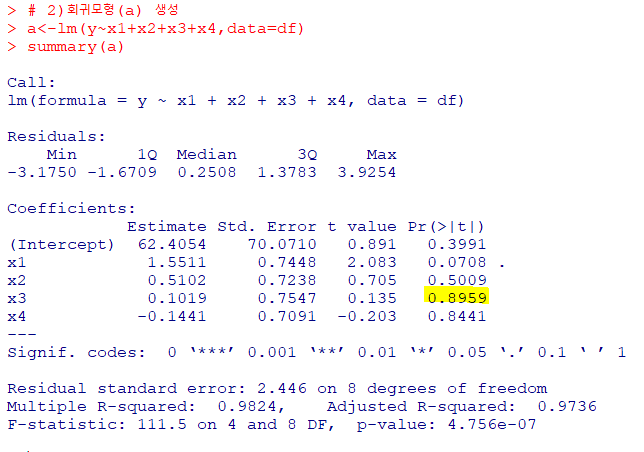
summary(a)에서모형의 유의성을 판단
:F-통계량을 확인한 결과111.5이며,p-value가4.756e-07임으로통계적으로 유의각각의 입력변수들의통계적 유의성 검토
:t-통계량을 통한 유의확률이0.05보다 작은 변수가 하나도 존재하지 않아모형을 활용할 수 없다고 판단
->유의확률이 가장 높은x3을 제외하고 다시 회귀모형 생성
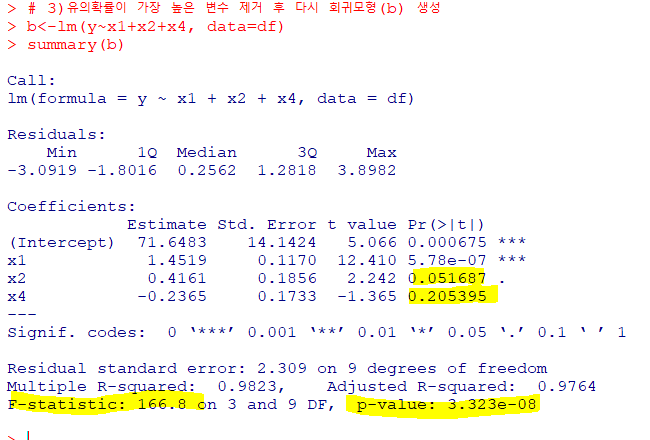
x3변수 제거 후,모형의 유의성:F-통계량에 대한 유의확률은 통계적으로 유의x1을 제외한 2개의 변수의 유의확률이0.05보다 높게나타나 유의하지 않음
->유의확률이 가장 높은 x4 변수를제외하고 회귀모형 다시 생성
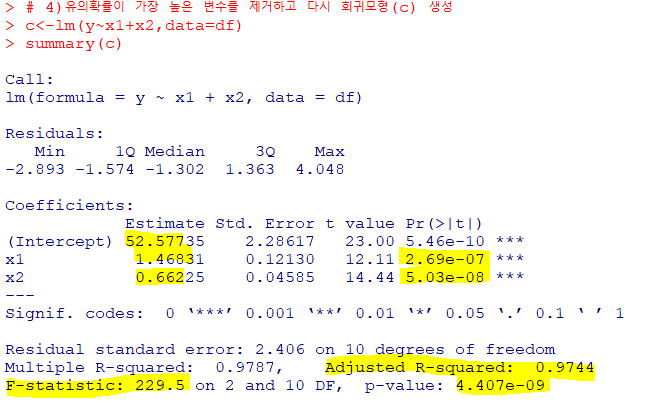
F-통계량을 통해유의수준 0.05하에서모형이 통계적으로 유의미다변량회귀분석에 선정된x1, x2변수에 대한 각각의 유의확률 값이 모두통계적으로 유의수정된 결정계수는0.9744로 선정된다변량회귀식이전체 데이터의 97.44%를 설명하고 있는 것을 확인후진제거법을 통해 최종적으로 얻게 된 추정된회귀식
:y=52.57735+1.436831x1+0.66225x2
*부동소수점(Floating Point) : 컴퓨터에서 실수를 표시하는 방법
-(가수)(밑수)^(지수)로 표현
-가수: 유효숫자
-지수:소숫점 위치
변수 선택법 예제(벌점화 전진선택법)
step함수를 사용하여전진선택법을 적용하여 변수 제거를 수행해보자.
step(lm(출력변수~입력변수, 데이터셋), scope=list(lower=~1, upper=~입력변수)
, direction="변수선택방법")
#scope:변수선택과정에서 설정할 수 있는 가장 큰 모형/가장 작은 모형
#scope가 없는 경우
전진선택법 : 현재 선택한 모형을 가장 큰 모형으로,
후진제거법 : 상수항만 있는 모형을 가장 작은 모형으로 설정
#direction
forward : 전진선택법, backward : 후진제거법, stepwise : 단계선택법
#k : 모형선택 기준에서 AIC, BIC와 같은 옵션 사용
k=2이면 AIC, k=log(자료의 수)이면 BIC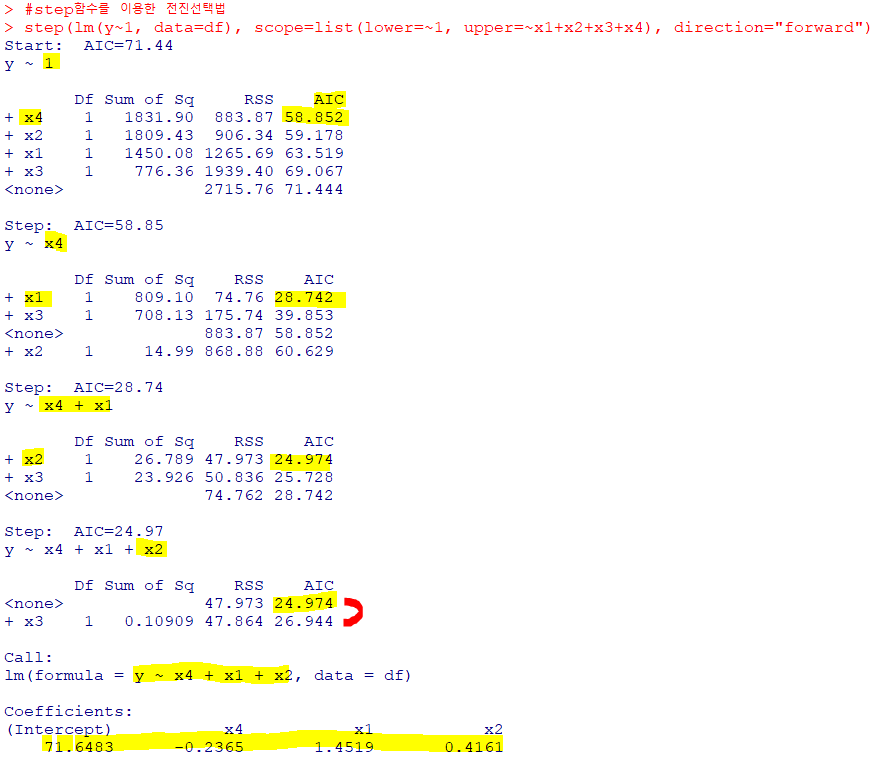
벌점화방식을 적용한전진선택법실시 결과, 가장 먼저 선택된 변수는AIC값이 58.852로 가장 낮은x4x4에x1을 추가 했을 때,AIC값이28.742가 되고x2를 추가했을 때AIC값이24.974로 최소화
-> 더 이상AIC를 낮출 수 없어 변수 선택 종료- 최종적으로 선택된 추정된
회귀식
:y=71.6483-0.2365x4+1.4519x1+0.4161x2
변수 선택법 예제(벌점화 후진제거법)
- 활용데이터
-전립선암 자료(8개의 입력변수와1개의 출력변수)
-마지막 열(train)에 있는 변수는 학습자료인지 예측자료인지를 나타내는 변수로 이번 분석에서 사용X
| 변수명 | 설명 |
|---|---|
| lcavol | 종양 부피의 로그 |
| lweight | 전립선 무게의 로그 |
| age | 환자의 연령 |
| lbph | 양성 전립선 증식량의 로그 |
| svi | 암이 정낭을 침범할 확률 |
| lcp | capsular penetration의 로그 값 |
| gleason | Gleason 점수 |
| pgg45 | Gleason 점수가 4 또는 5 인 비율 |
| lpsa | 전립선 수치의 로그 |
library(ElemStatLearn)
Data=prostate
data.use=Data[,-ncol(Data)]
lm.full.Model=lm(lpsa~.,data=data.use)
후진제거법에서AIC를 이용한변수선택
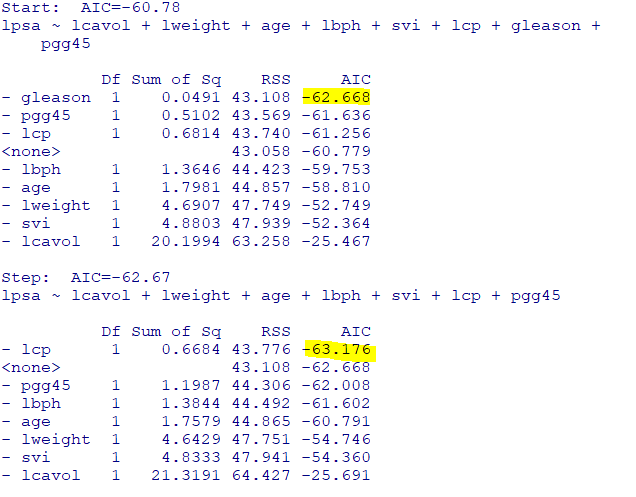
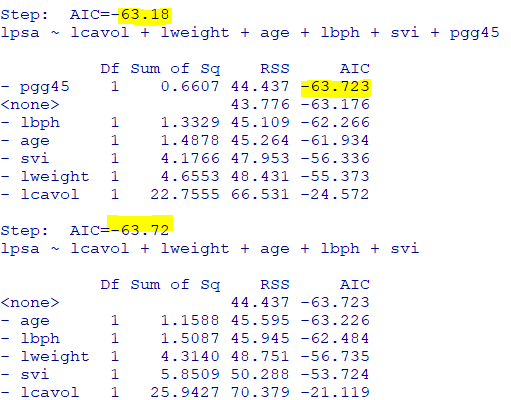
-맨 처음AIC는-62.67로gleason을 제거하고 회귀분석 실시
-차례로lcp, pgg45순서로 제거되어 회귀분석 실시
-Step : AIC=~에 적혀있는AIC보다작으면(절대값 기준 크면)삭제
🕑시계열 분석
시계열 자료
시간의 흐름에 따라관찰된 값시계열 데이터 분석을 통해미래의 값을예측하고경향,주기,계절성등을 파악하여 활용
시계열 자료의 종류
-
비정상성 시계열 자료
:시계열 분석을 실시할 때다루기 어려운 자료.
-대부분의 시계열 자료 -
정상성 시계열 자료
:비정상 시계열을핸들링해 다루기 쉬운 시계열 자료로 변환한 자료
정상성
평균이 일정할 경우
모든 시점에 대해일정한 평균- 평균이 일정하지 않은 시계열은
차분(Difference)를 통해 정상화
*차분
: 현시점 자료-전 시점 자료
-일반차분(Regular Difference) : 바로 전 시점의 자료를 빼는 방법
-계절차분(Seasonal Difference) : 여러 시점 전의 자료를 빼는 방법.
=> 계절성을 갖는 자료를 정상화하는데 사용
분산이 일정
분산도시점에의존하지 않고 일정- 분산이 일정하지 않을 경우
변환(Transformation)을 통해 정상화
공분산(두 확률변수의 방향의 조합)도 단지 시차에만 의존, 실제 특정 시점 t, s에는 의존x
정상 시계열의 모습
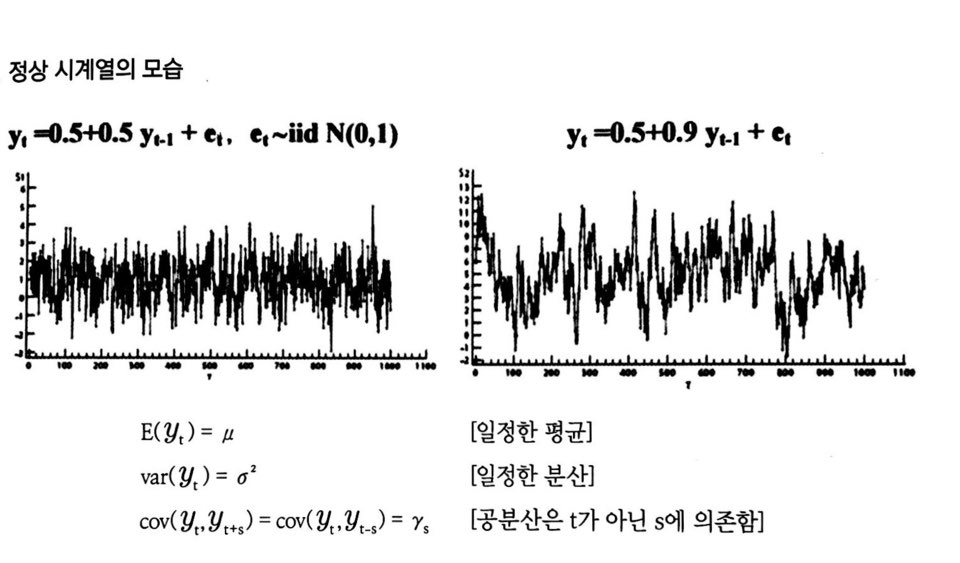
정상 시계열의특징
정상 시계열은어떤 시점에서평균과분산그리고 특정한시차의 길이를 갖는자기공분산을 측정하더라도동일한 값- 정상 시계열은 항상
그 평균값으로회귀하려는 경향이 있으며, 그 평균값 주변에서의변동은대체로 일정한 폭 정상 시계열이 아닌 경우특정 기간의 시계열 자료로부터 얻은 정보를다른 시기로일반화 불가능
시계열자료 분석방법
분석방법
: 회귀분석(계량경제)방법, Box-Jenkins 방법, 지수평활법, 시계열 분해법 등

자료 형태에 따른 분석방법
-
일변량 시계열분석
:Box-Jenkins(ARMA),지수 평활법,시계열 분해법등
-시간(t)를설명변수(x)로 한 회귀모형주가, 소매물가지수 등하나의 변수에관심을 갖는 경우의 시계열 분석 -
다중 시계열분석
:계량경제 모형(회귀분석방법),전이함수 모형,개입분석,상태공간 분석,다변량 ARIMA등
-여러 개의 시간(t)에 따른 변수들을 활용하는 시계열 분석
-계량경제:시계열 데이터에 대한 회귀분석(ex. 이자율, 인플레이션이 환율에 미치는 요인)
이동평균법
과거로부터현재까지의시계열 자료를 대상으로일정 기간별이동평균을 계산하고, 이들의 추세를 파악하여다음 기간을 예측시계열 자료에서계절변동과불규칙 변동을제거
->추세변동과순환변동만 가진 시계열로 변환하는 방법

n개의 시계열 데이터를m기간으로이동평균하면n-m+1개의 이동평균 데이터가 생성
이동평균법의특징
간단하고쉽게미래 예측 가능자료의 수가많고안정된 패턴을 보이는 경우예측의 품질(Quality)이높음특정 기간 안에 속하는 시계열에 대해서는동일한 가중치 부여- 일반적으로 시계열 자료에
뚜렷한 추세가 있거나불규칙변동이 심하지 않은 경우에는짧은 기간(m개수 적음)의평균 사용 불규칙 변동이 심한 경우긴 기간(m의 개수가 많음)의평균을 사용- 가장 중요한 것은
적절한 기간을 사용하는 것
->적절한 m의 개수를 결정하는 것
지수평활법
일정 기간의 평균을 이용하는이동평균법과는 달리
모든 시계열 자료를 사용하여 평균을 구하며,시간의 흐름에 따라최근 시계열에더 많은 가중치를 부여하여 미래 예측

지수평활법의특징
단기간에 발생하는불규칙 변동을 평활자료의 수가 많고,안정된 패턴을 보이는 경우일수록예측 품질 높음지수평활법에서가중치의 역할을 하는 것은지수평활계수(α)불규칙변동이 큰시계열의 경우지수평활계수(가중치)는작은 값,
불규칙변동이 작은시계열의 경우큰 값의지수평활계수(가중치)를 적용
(일반적으로,0.05<=α<=0.3)- 지수평활계수는
예측오차(실제 관측치와 예측치 사이의 잔차 제곱합,SSE)를 비교하여예측오차가 가장 작은 값을 선택 지수평활계수는과거로 갈수록지속적으로 감소지수평활법은불규칙변동의영향을 제거하는 효과가 있음중기 예측 이상에 주로 사용
(단,단순지수 평활법의 경우,장기추세나계절변동이 포함된 시계열 예측에는 적합x)
시계열모형
자기회귀 모형(AR모형, Autoregressive Model)
: p시점 전의 자료가 현재 자료에 영향을 주는 모형

-
AR(1) 모형:직전 시점데이터로만 분석
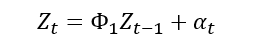
-
AR(2) 모형:연속된 2시점 정도의 데이터로 분석
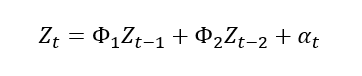
-
자기상관함수(ACF)는빠르게 감소 -
부분자기함수(편자기상관함수)(PACF)는어느 시점에서절단점을 가짐 -
ACF가빠르게 감소하고,PACF가3시점에서절단점을 갖는 그래프가 있다면,2시점 전의 자료까지가현재에 영향을 미치는AR(2)모형
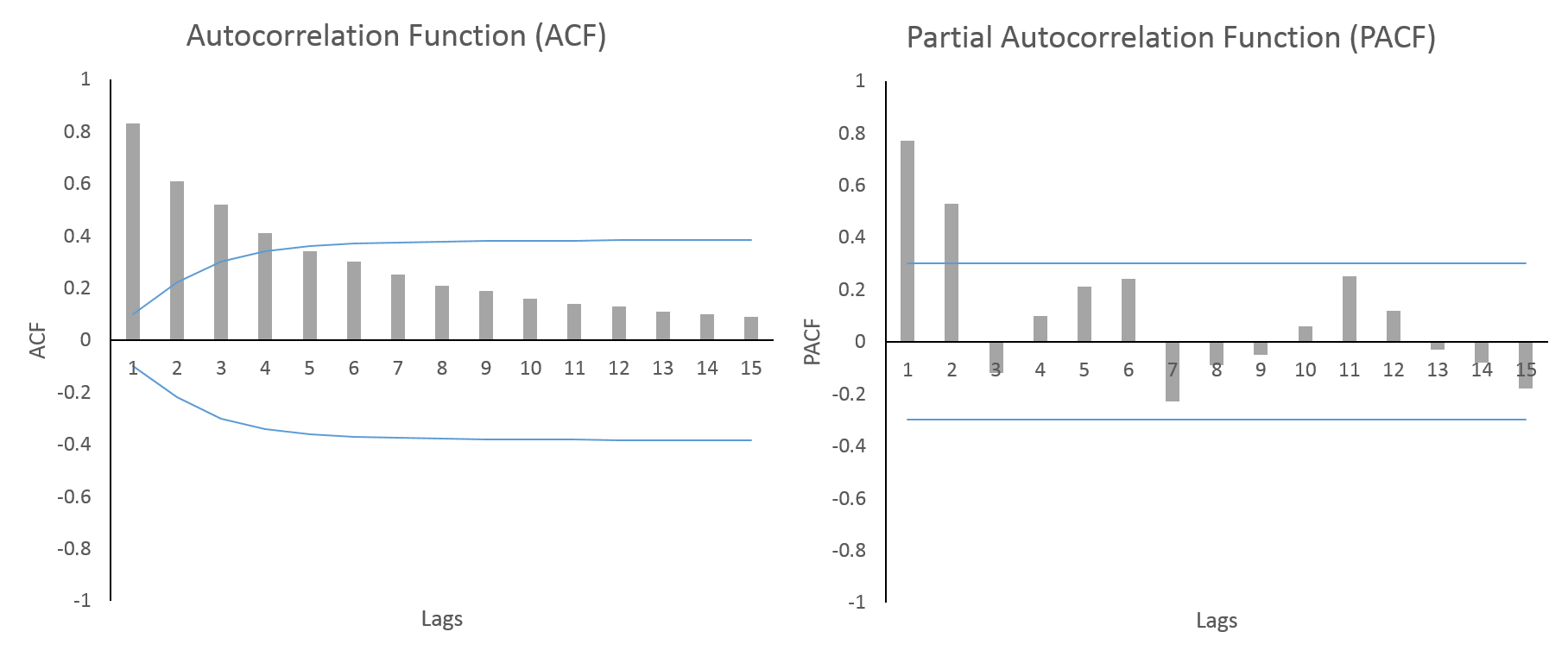
*자기상관계수와 부분자기상관계수


이동평균 모형(MA모형, Moving Average Model)
: 유한한 개수의 백색잡음의 결합이므로 언제나 정상성 만족
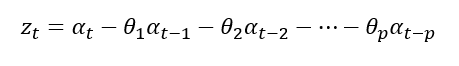
-
1차 이동평균모형(MA(1) 모형):이동평균모형중 가장간단한모형
-시계열이같은 시점의백색잡음과 바로전 시점의백색잡음의 결합
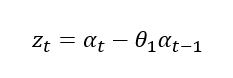
-
2차 이동평균모형(MA(2) 모형):바로 전 시점의백색잡음과시차가 2인백색잡음의 결합으로 이뤄진 모형
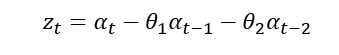
-
AR모형과반대로ACF에서 절단점을 갖고,PACF가빠르게 감소
자기회귀누적이동평균 모형(ARIMA(p,d,q) 모형, Autoregressive Integrated Moving Average Model)
비정상시계열모형차분이나변환을 통해AR모형이나MA모형, 이 둘을 합친ARMA모형으로 정상화 가능p는AR모형q는MA모형과 관련이 있는 차수시계열 {Zt}의d번 차분한 시계열이ARMA(p,q)모형이면,
시계열 {Zt}는 차수가p,d,q인ARIMA모형, 즉ARIMA(p,d,q)모형을 갖는다d=0:ARMA(p,q)모형,정상성만족
(ARMA(0,0)일 경우정상화 불필요)p=0:IMA(d,q)모형,d번 차분하면MA(q)모형따름q=0:ARI(p,d)모형,d번 차분하면AR(p)모형따름
ARIMA(0,1,1) #1차분 후 MA(1) 활용
ARIMA(1,1,0) #1차분 후 AR(1) 활용
ARIMA(1,1,2) #1차분 후 AR(1), MA(2), ARMA(1,2) 선택
->가장 간단한 모형을 선택하거나 AIC를 적용하여 점수가 가장 낮은 모형 선정*자기회귀이동평균(Autoregressive and Moving Average, ARMA) 모형
: 자기회귀와 이동평균 다항식으로, 약한 정상성을 가진 확률적 시계열을 표현하는데 사용.
-ARMA(p,q)로 표기(p는 자기회귀 다항식 차수, q는 이동평균 다항식 차수)
분해 시계열
: 시계열에 영향을 주는 일반적인 요인을 시계열에서 분리해 분석하는 방법
회귀분석적인 방법 주로 사용분해식의 일반적 정의

R을 이용한 시계열분석
- 영국 왕들의
사망 시나이데이터를 이용한 시계열분석 - 영국 왕 42명의 사망시 나이 예제는
비계절성을 띄는 시계열 자료 - 비계절성을 띄는 시계열 자료는
트렌드 요소(추세요인),불규칙 요소로 구성 - 20번째 왕 까지는 38세~55까지 수명 유지, 그 이후부터 수명이 늘어 40번째 왕은 73세까지 생존
분해 시계열
자료 읽기및그래프 그리기
library(tseries) #시계열 분석 및 전산 금융
library(forecast) #시계열 및 선형 모델에 대한 예측 함수
library(TTR) #기술 거래 규칙
king<-scan("http://robjhyndman.com/tsdldata/misc/kings.dat",skip=3)
#skip=3은 3번째 열 건너뜀, scan()은 입력함수
king.ts<-ts(king) #ts()는 시계열 데이터 생성
plot.ts(king.ts)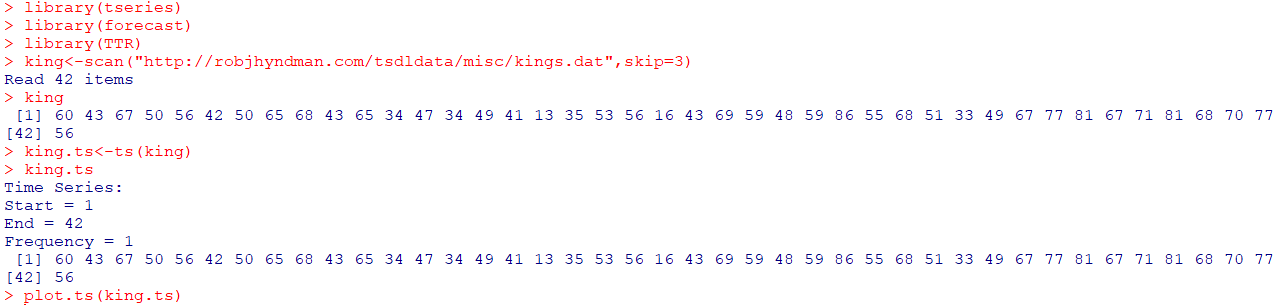
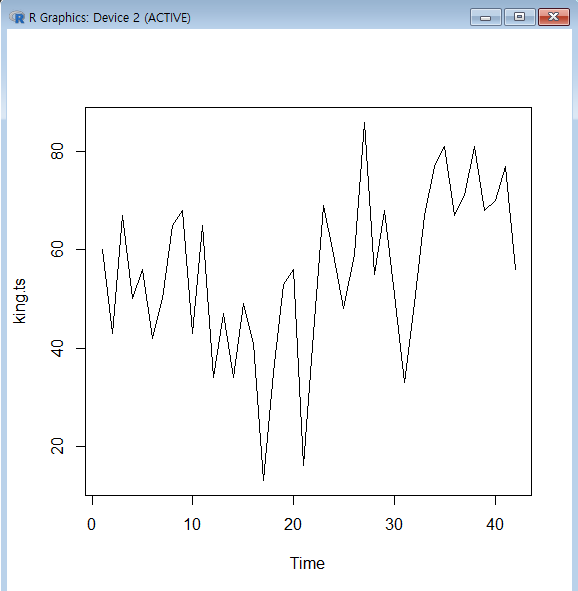
3년마다 평균을 내서그래프를 부드럽게 표현
king.sma3<-SMA(king.ts,n=3) #SMA : 이동평균
plot.ts(king.sma3)
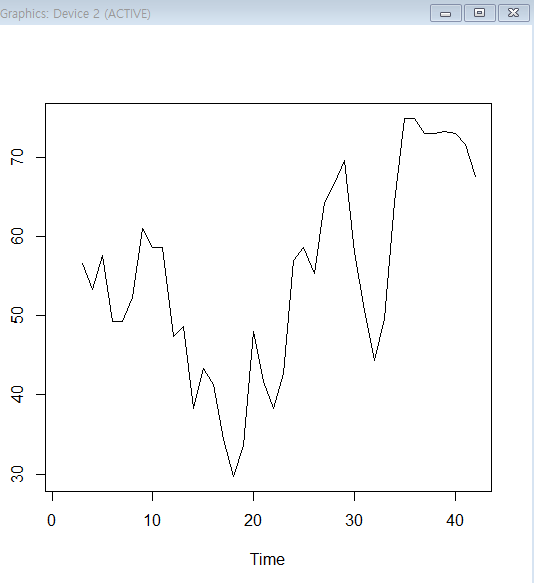
8년마다 평균을 내서 그래프를 부드럽게 표현
king.sma8<-SMA(king.ts,n=8) #SMA : 이동평균
plot.ts(king.sma8)
ARIMA 모델
-ARIMA모델은정상성 시계열에 한해 사용
-비정상 시계열 자료는차분해 정상성을 만족하는 조건의 시계열로 변경
-이전 그래프에서평균이 시간에 따라 일정치 않은 모습을 보이므로비정상시계열=>차분진행
diff(data, differences=차분횟수)
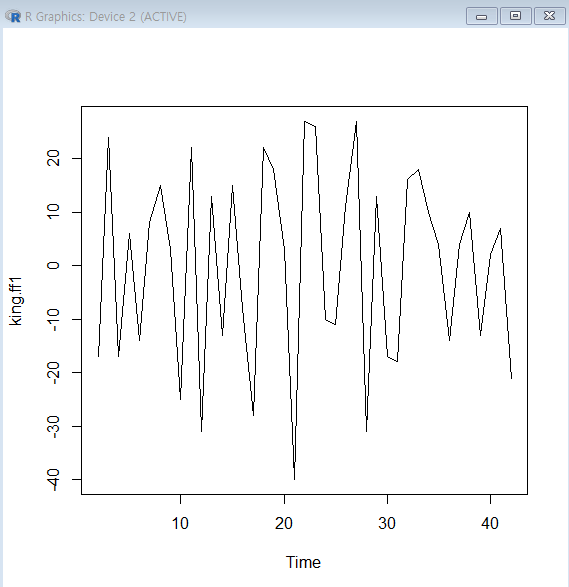
-1차 차분 결과에서 평균과 분산이 시간에 따라 의존하지 않음을 확인
-ARIMA(p,1,q)모델이며 차분을 1번해야 정상성 만족
-
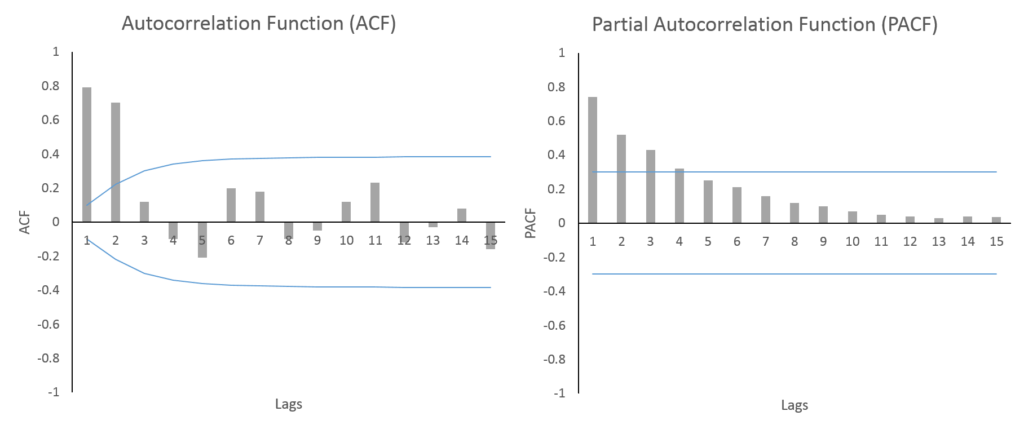
ACF와PACF를 통한적합한 ARIMA 모델결정
-ACF-
lag는0부터 값을 갖는데,너무 많은 구간을 설정하면그래프를 보고 판단 어려움

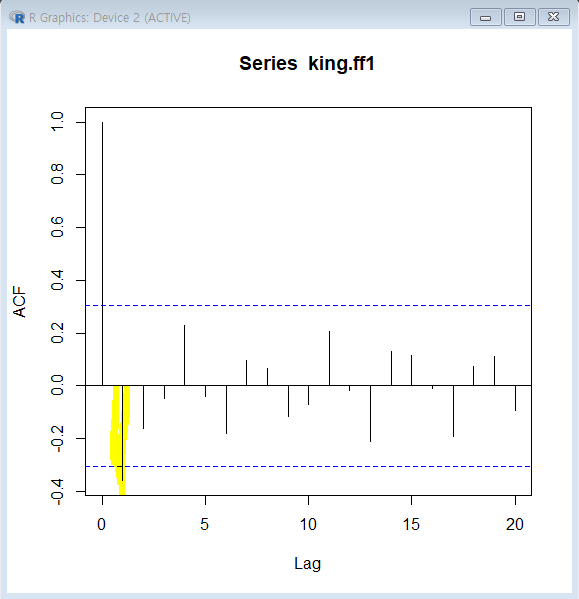
-
ACF값이lag 1인 지점빼고 모두점선 구간 안
-
PACF

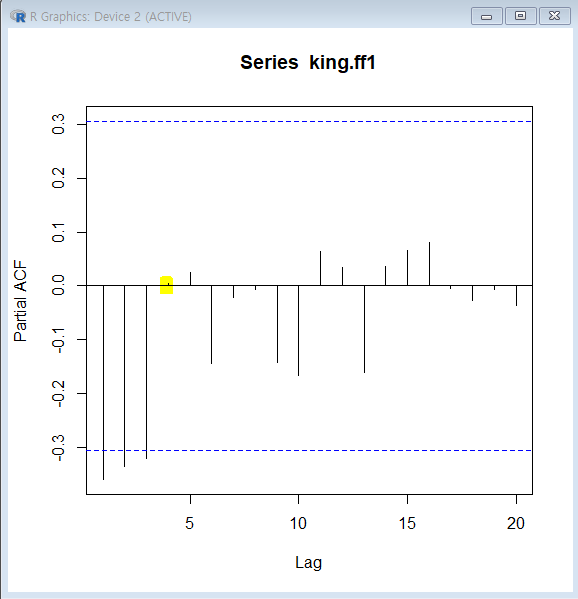
PACF값이lag 1, 2, 3에서점선 구간을초과하고음의 값을 가지며절단점은lag 4
-
종합
-ARMA 후보들이 생성ARMA(3,0)모델: PACF값이lag4에서 절단점을 가짐.AR(3)ARMA(0,1)모델: ACF값이lag2에서 절단점을 가짐.MA(1)ARMA(p,q)모델:AR모형+MA모형
적절한 ARIMA 모형 찾기
-forecast패키지에 내장된auto.arima()함수이용
-auto.arima(): 데이터를 활용하여최적의 ARIMA 모형선택
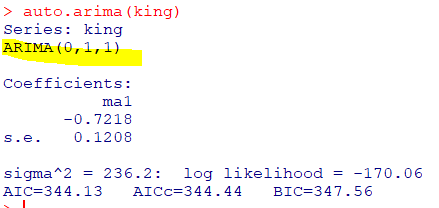
-영국 왕 사망 나이 데이터의 적절한ARIMA 모형은ARIMA(0,1,1)
예측
king.arima<-arima(king,order=c(0,1,1))
#선정된 ARIMA 모형으로 데이터 보정(fitting)
king.forecasts<-forecast(king.arima)
#시계열 모델을 입력받아 적절한 예측치를 냄
king.forecasts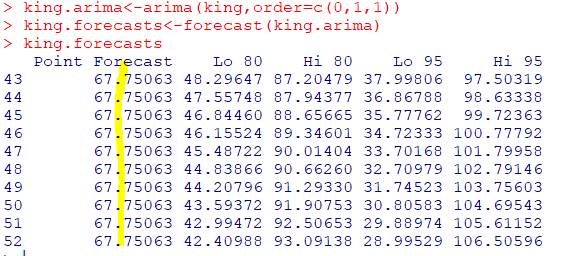
-42명의 영국왕 중에서 마지막 왕의 사망시 나이는 56세
-43번째에서 52번째 왕 까지의 10명의 왕의 사망시 나이를 예측한 결과 67.75살로 추정
-5명 정도만 예측하고 싶다면, 옵션에 h=5 입력(forecast에)
-신뢰 구간은 80%~90% 사이
🔏다차원척도법
다차원척도법(Multidimensional Scaling/MDS)
객체간근접성(Proximity)을시각화하는 통계기법군집분석과 같이객체들을 대상으로 변수를 측정한 후, 개체들 사이의유사성/비유사성을 측정하여개체들을 2차원 공간상에점으로 표현하는 분석 방법- 개체들을 2차원 또는 3차원 공간상에
점으로 표현하여개체들 사이의 집단화를시각적으로 표현
다차원척도법 목적
데이터속에 잠재해 있는패턴(Pattern),구조를 찾아냄- 그 구조를
소수 차원의공간에기하학적으로 표현 데이터 축소(Data Reduction)의 목적으로 다차원척도법 이용
->데이터에 포함되는 정보를끄집어내기위해서 다차원척도법을탐색수단으로써 사용다차원척도법에 의해서 얻은결과를 데이터가 만들어진현상이나과정에고유의 구조로서 의미 부여
다차원척도법 방법
-
개체들의
거리 계산:유클리드 거리행렬활용
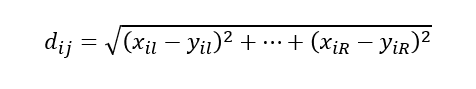
-
관측대상들의
상대적 거리의정확도를 높이기 위해적합 정도를스트레스 값(Stress Value)로 나타냄 -
개체들을공간상에 표현하기 위한 방법
:부적합도 기준으로Stress나S-Stress를 사용 -
최적모형의 적합은부적합도를 최소로 하는반복 알고리즘을 이용.
이 값이일정 수준 이하가 될 때최종적으로 적합된 모형으로 제시 -
스트레스 값

-
Stree와적합도 수준 M은 개체들을공간상에 표현하기 위한 방법으로Stress나S-Stress를부적합도 기준으로 사용
| Stress | 적합도 수준 |
|---|---|
| 0 | 완벽(Perfect) |
| 0.05 이내 | 매우 좋은(Excellent) |
| 0.05~0.10 | 만족(Satisfactory) |
| 0.10~0.15 | 보통(Acceptable, but Doubt) |
| 0.15 이상 | 나쁨(Poor) |
다차원척도법 종류
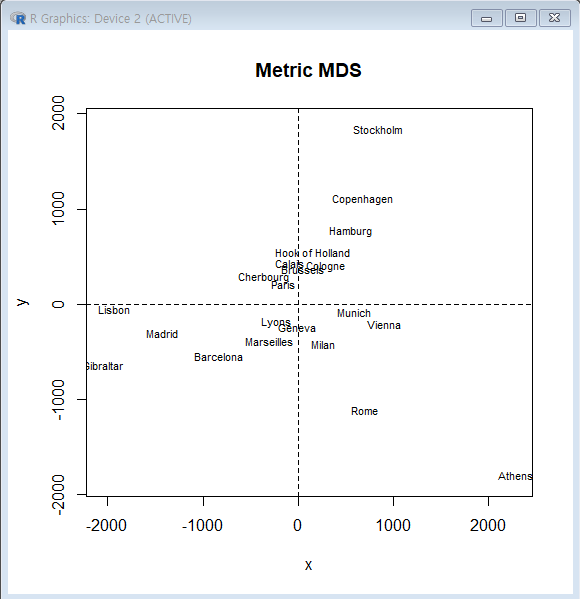
계량적 MDS(Metric MDS)
: 데이터가 구간척도나 비율척도인 경우 활용 (전통적인 다차원척도법)
-N개의 케이스에 대해서 p개의 특성변수가 있는 경우, 각 개체들간의 유클리드 거리행렬을 계산하고 개체들간의 비유사성 S(거리제곱 행렬의 선형함수)를 공간상에 표현
cmdscale사례
MASS패키지의eurodist자료 이용- 유럽 21개 도시들 사이의
거리 측정 cmdscale을 이용하여2차원으로 21개의 도시들을 맵핑종축은북쪽 도시를상단에 표시하기 위해부호 변경
library(MASS)
#matrix 데이터 상의 값들을 거리로 생각하고 2차원상으로 나타냄
loc<-cmdscale(eurodist)
x<-loc[,1]
y<- -loc[,2]
#type="n" : 좌표를 찍지 않음, asp는 종횡의 비율
plot(x,y,type="n",asp=1,main="Metric MDS")
#cex=0.7 : 폰트 사이즈
text(x,y,rownames(loc),cex=0.7)
#v는 수직선 위치, h는 수평선 위치, lty는 선 유형(2:dashed), lwd는 선 두께
abline(v=0, h=0,lty=2,lwd=0.5)

비계량적 MDS(nonmetric MDS)
: 데이터가 순서척도인 경우 활용
-개체들 간의 거리가 순서로 주어진 경우에는 순서척도를 거리의 속성과 같도록 변환(Monotone Transformation) 하여 거리 생성 후 적용
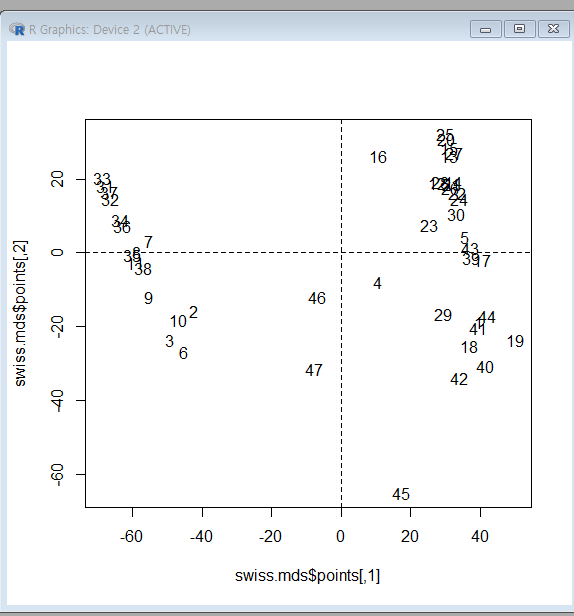
isoMDS사례
MASS패키지의Swiss자료를 이용하여2차원으로 도시 맵핑- 1888년경 스위스연방 중 47개의 불어권 주의 토양의
비옥도 지수와 여러 사회경제적 지표를 측정한 자료
library(MASS)
data(swiss)
swiss.x<-as.matrix(swiss[,-1])
swiss.dist<-dist(swiss.x) #유클리드 거리를 행렬 형태로 출력
swiss.mds<-isoMDS(swiss.dist) #2차원상으로 cmdscale과 비슷
plot(swiss.mds$points, type="n")
text(swiss.mds$points, labels=as.character(1:nrow(swiss.x)))
abline(v=0, h=0, lty=2, lwd=0.5)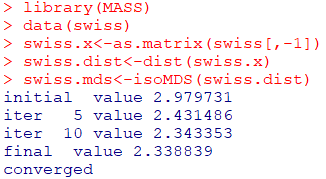

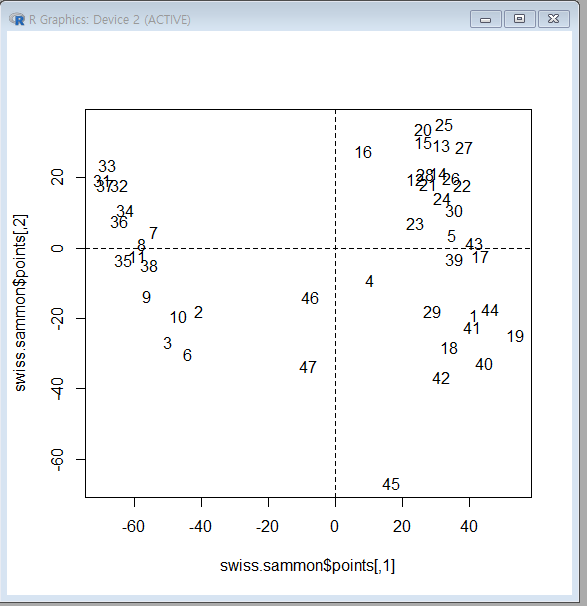
sammon사례
swiss.x<-as.matrix(swiss[,-1]) #첫번째 열 제외
swiss.sammon<-sammon(dist(swiss.x))
plot(swiss.sammon$points, type="n")
text(swiss.sammon$points, labels=as.character(1:nrow(swiss.x)))
abline(v=0, h=0, lty=2, lwd=0.5)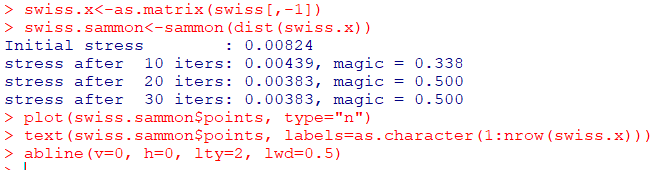
🎨주성분 분석
주성분분석(Principal Component Analysis)
- 여러 변수들의
변량을주성분(Principal Component)이라는서로 상관성이 높은 변수들의 선형 결합으로 만들어 기존의상관성이 높은 변수들을요약,축소하는 기법 첫번째 주성분으로전체 변동을가장 많이설명할 수 있도록 하고,두 번째 주성분으로는첫 번째 주성분과는상관성이 없어서(낮아서)첫 번째 주성분이설명하지 못하는나머지 변동을정보의 손실 없이 가장 많이 설명할 수 있도록 변수들의선형조합을 만듦
주성분분석의 목적
- 여러 변수들 간에 내재하는
상관관계,연관성을 이용해
소수의 주성분으로차원을 축소함으로써데이터를이해하기 쉽고관리하기 쉽게 해줌 다중공선성이 존재하는 경우,상관성이 없는(적은) 주성분으로변수들을 축소하여 모형 개발에 활용회귀분석등의 모형 개발 시입력변수들간 상관관계가 높은다중공선성(Multicollinearity)이 존재할 경우모형이 잘못 만들어져문제 발생연관성이 높은변수를주성분분석을 통해차원을 축소한 후에군집분석을 수행하면군집화 결과와연산속도를 개선 가능- 기계에서 나오는 다수의
센서데이터를주성분분석으로차원을 축소한 후에시계열로분포나추세의 변화를 분석하면기계의 고장 징후를 사전에 파악하는데 활용
주성분분석 vs 요인분석
요인분석(Factor Analysis)
등간척도(또는 비율척도)로 측정한두 개 이상의 변수들에 잠재되어 있는공통인자를 찾아내는 기법
공통점
- 모두 데이터를
축소하는데 활용 원래 데이터를 활용해서몇 개의 새로운 변수들을 만듦
차이점
생성된 변수의수
요인분석:몇 개라고지정 없이(2 or 3, 4, 5...) 만들기 가능주성분분석:제1주성분,제2주성분,제3주성분정도로 활용
(대개 4개 이상은 안넘음)
생성된 변수의이름
요인분석:분석자가요인의 이름을명명주성분분석:제1주성분,제2주성분등으로 표현
생성된 변수들 간의관계
요인분석:새 변수들은 기본적으로대등한 관계를 갖고 '어떤 것이 더 중요하다'라는 의미는 없음. 단,분류/예측에그다음 단계로 사용된다면 그 때중요성 의미가 부여주성분분석:제1주성분이 가장중요하고, 그 다음제2주성분이 중요
분석 방법의의미
요인분석:목표변수를고려하지 않고, 그냥 데이터가 주어지면변수들을비슷한 성격들로 묶어서새로운잠재변수를 만듦주성분분석:목표 변수를고려하여목표 변수를잘 예측/분류하기 위하여원래 변수들의 선형 결합으로 이루어진 몇 개의주성분들을 찾아냄
주성분의 선택법
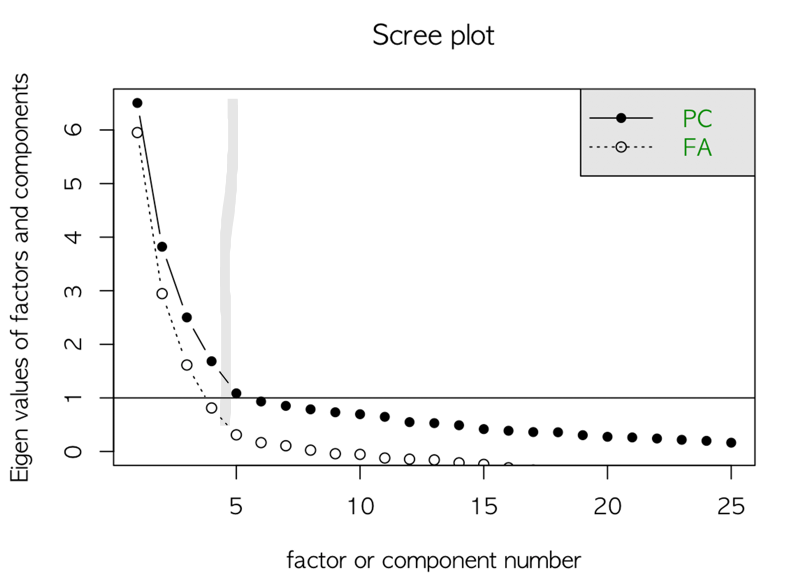
주성분분석의결과에서누적기여율(Cumulative Proportion)이85%이상이면주성분의 수로 결정 가능

Scree Plot을 활용하여고윳값(Eigenvalue)이수평을 유지하기 전단계로주성분의 수선택
주성분 분석 사례
USArrests 자료
- 1973년 미국 50개주의
100,000명의 인구 당 체포된 세 가지 강력범죄수(Assault, Murder, Rape)와 각 주마다도시에 거주하는 인구의 비율(%)로 구성 - 변수들 간의
척도의 차이가 상당히 크기 때문에상관행렬을 사용하여 분석 특이치 분해(특이값 분해) : 행렬을 특정한 구조로 분해를 사용하는 경우 자료 행렬의각 변수의 평균과제곱의 합이1로 표준화되었다고 가정
4개의 변수들 간 산점도
> library(datasets)
> data(USArrests)
> pairs(USArrests,panel=panel.smooth, main="USArrests data") # 산점도 행렬
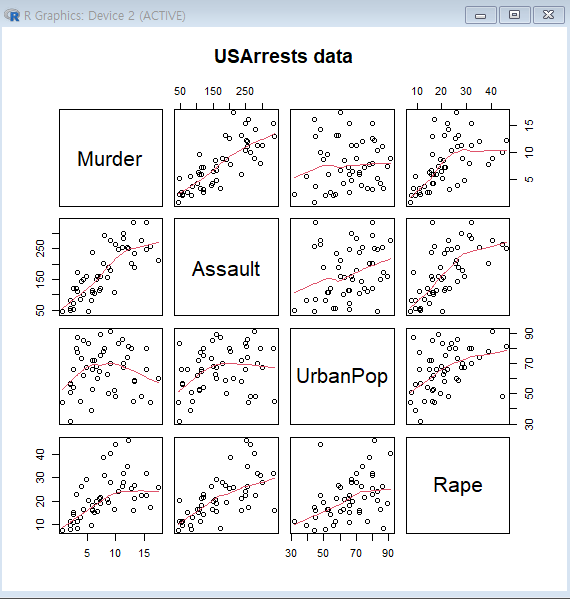
Murder과UrbanPop비율간의관련성이 작아보임
summary
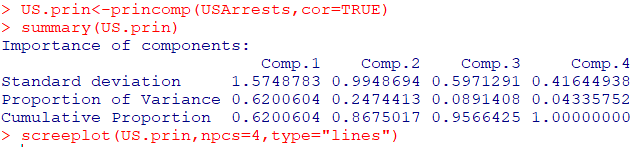
#princomp : 주성분분석을 하는 함수. cor=TRUE면 상관행렬, F이면 공분산행렬
> US.prin<-princomp(USArrests,cor=TRUE)
> summary(US.prin)
#주성분을 x축, 주성분의 고유값(주성분의 분산)을 y축에 둔 그래프
> screeplot(US.prin,npcs=4,type="lines")-
제1주성분과제2주성분까지의누적 분산비율은 대략86.8%로2개의 주성분 변수를 활용하여전체 데이터의 86.8%를 설명가능
-
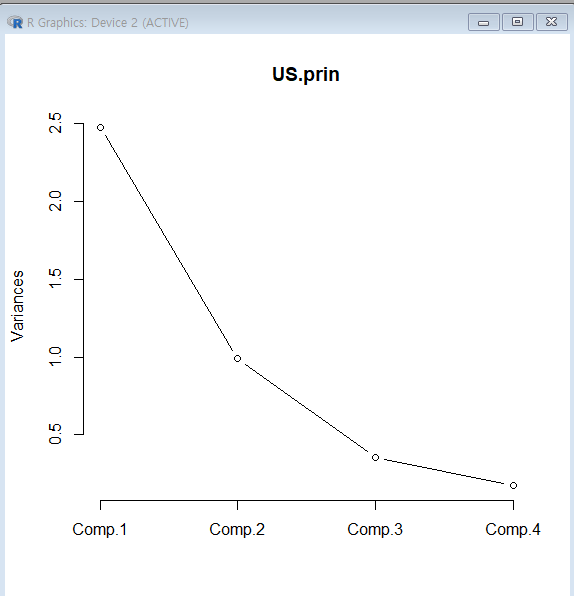
주성분들에 의해 설명되는변동의 비율은ScreePlot으로 확인
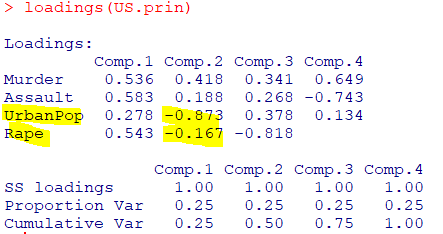
Loadings
- 네 개의 변수가 각 주성분
Comp.1-Comp.4까지기여하는 가중치가 제시 제1주성분에는네 개의 변수가평균적으로 기여제2주성분에는 (Murder,Assault)와 (UrbanPop, Rape)의 계수의부호가 서로 다름
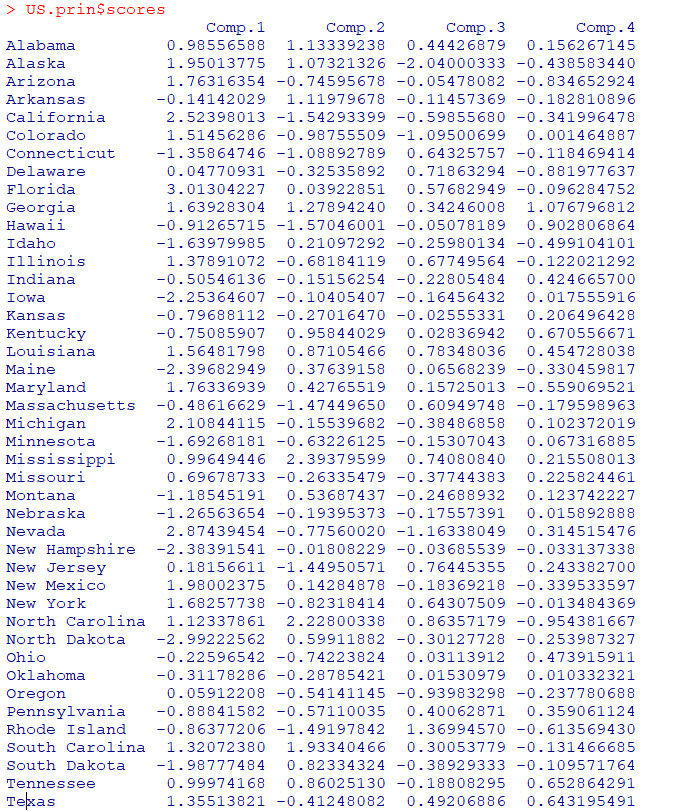
Scores
- 각 주성분
Comp.1-Comp.4의선형식을 통해각 지역(record)별로 얻은 결과 계산
제 1-2주성분에 의한행렬도
#자료행렬을 특이값 분해해 주성분분석을 실행하는 함수
#center=T : 데이터 중심이 0
#scale.=T : 데이터 표준화
> arrests.pca<-prcomp(USArrests, center=TRUE,scale.=TRUE)
#제 1,2 주성분에 의한 행렬도
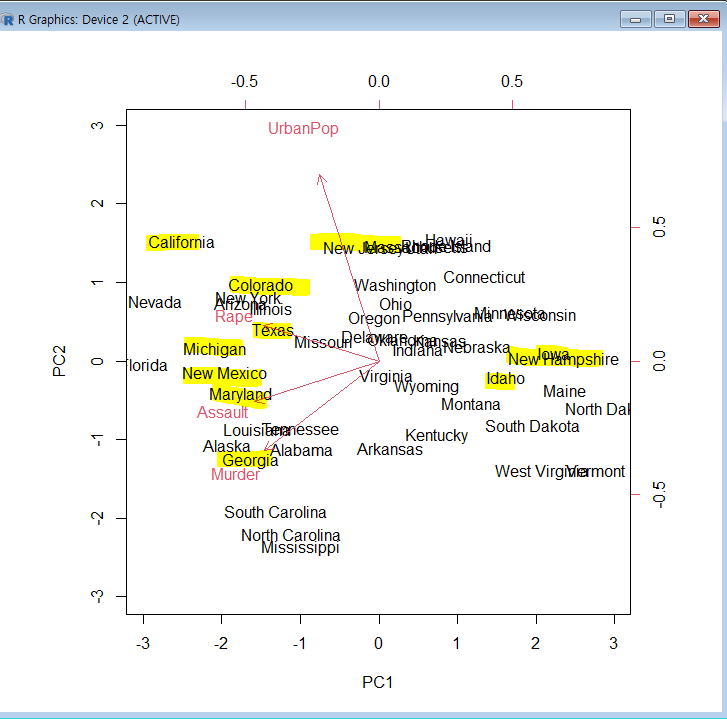
> biplot(arrests.pca,scale=0)
- 조지아, 메릴랜드, 뉴 멕시코 등은
폭행과살인의 비율이 상대적으로높은 지역 - 미시간, 텍사스 등은
강간의 비율이 높은 지역 - 콜로라드, 캘리포니아, 뉴저지 등은 도시에 거주하는
인구의 비율이 높은 지역 - 아이다호, 뉴 햄프셔, 아이오와 등의 도시들은
도시에 거주하는 인구의 비율이상대적으로 낮으면서3대 강력범죄도 낮다