📔설명
R을 이용해 데이터 전처리를 해보자
🧇데이터 전처리 패키지
plyr패키지
: 원본 데이터를 분석하기 쉬운 형태로 나눠서 다시 새로운 형태로 만들어주는 패키지
**ply형태 중앞글자는입력 데이터,뒷글자는출력 데이터
ex)dataframe->nothing : d_ply
dplyr패키지
: 데이터 일부를 추출, 종류별로 나누거나, 여러 데이터를 합치는 등의 가공
| dplyr함수 | 기능 |
|---|---|
| filter | 행 추출 |
| select | 열 추출 |
| arrange | 정렬 |
| mutate | 변수 추가 |
| summarise | 요약 통계치 |
| group_by | 데이터를 그룹별로 나누기 |
| bind_rows | 행 방향으로 데이터 결합 |
| bind_cols | 열 방향으로 데이터 결합 |
| 데이터 프레임 %>% select(선택할 변수명, -제외할 변수명) |
|---|
| 데이터에서 원하는 변수의 특정 열만 추출 |
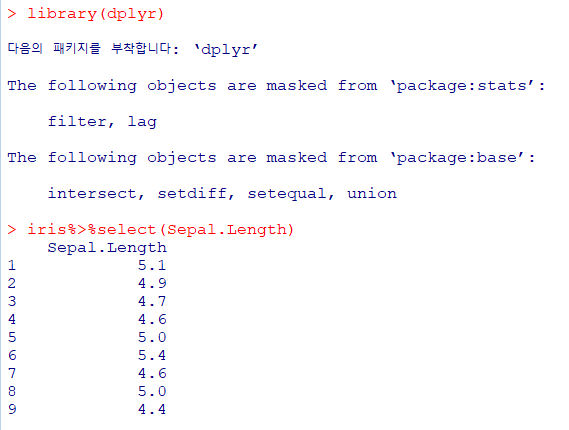
%>% : 함수들을 연결하는 기능을 하는 기호
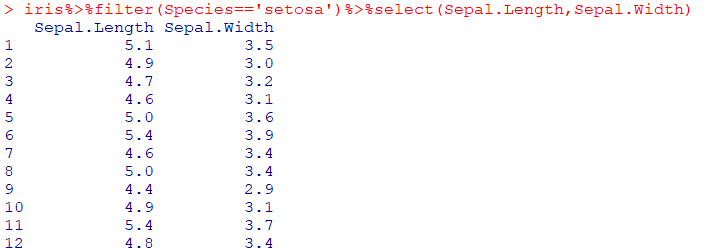
| 데이터 프레임 %>% filter(조건) |
|---|
| 원하는 조건에 따라 데이터 필터링, 추출 |
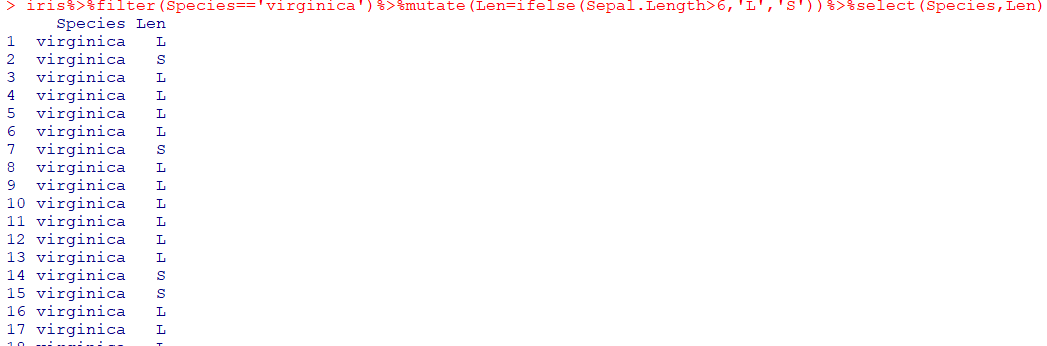
| 데이터 프레임 %>%mutate(새로운 변수명=값) |
|---|
| 파생변수를 추가하는 함수 |
| 데이터 프레임 %>% group_by(그룹화할 기준 변수,..) %>% summarise(새로운 변수명=계산식) |
|---|
| 데이터를 그룹화하는 함수와 요약 통계치 계산 |
n함수 : 빈도(총 개수)

| 데이터 프레임 %>% arrange(정렬 기준) |
|---|
| 특정한 열을 기준으로 데이터 정렬 |
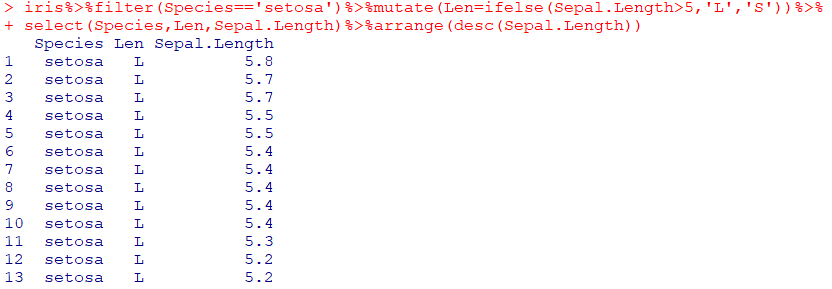
| bind_rows(데이터명1,...) |
|---|
| 데이터의 행들을 이어 붙이는 함수 |

| bind_cols(데이터명1,...) |
|---|
| 데이터의 열들을 이어 붙임 |

🥧데이터 정제
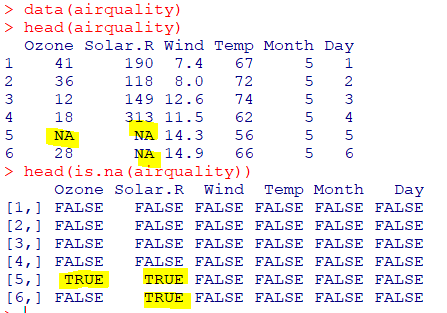
| is.na(x) |
|---|
| 결측값일 경우 TRUE |
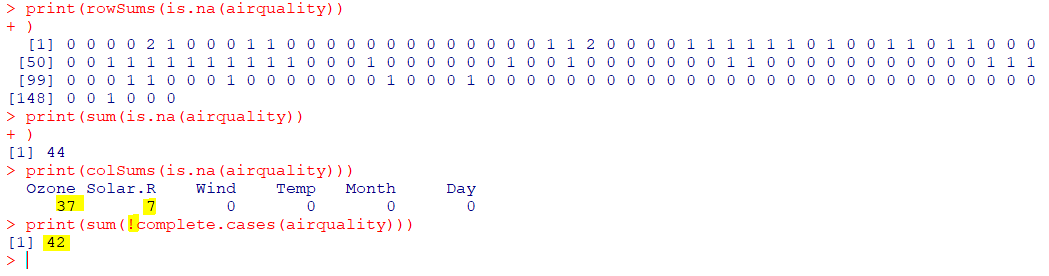
| complete.cases(x) |
|---|
| 행별로 결측값이 아닐 경우 TRUE, 있으면 FALSE |
| na.omit(x) |
|---|
| 결측값이 있는 전체 행 삭제 |
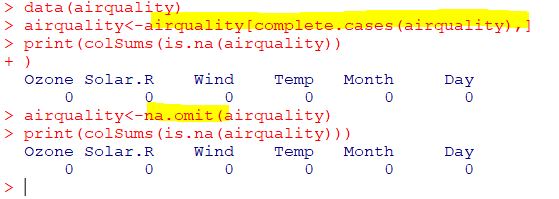

table : 요인 수준 별로 표로 보여줌



| μ-3σ < X < μ+3σ <=> |(X-μ)/σ|<3 |
|---|
| ESD, X는 관측값, μ는 평균, σ는 표준편차 |

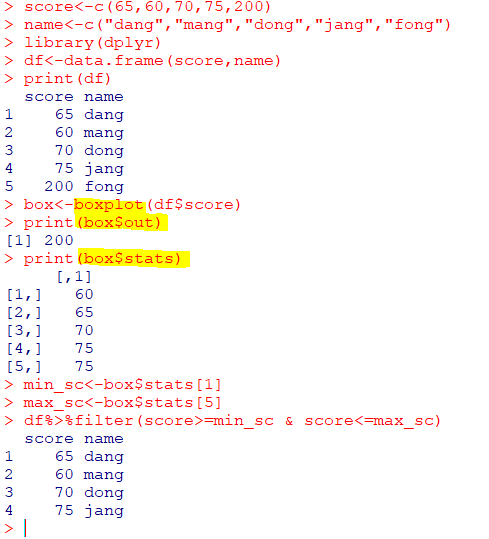
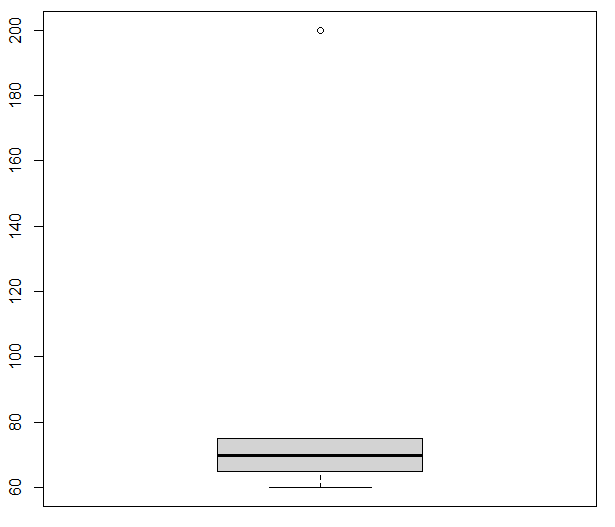
| boxplot(x) |
|---|
| 박스 플롯 |
| 박스 플롯 변수 | 설명 |
|---|---|
| $stats | 최솟값, 1, 2, 3 사분위수, 최댓값 저장 행렬 |
| $out | 이상값 |
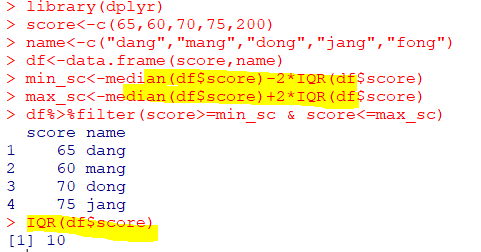
| IQR(x, na.rm) |
|---|
| 사분위수범위 (Q3-Q1) x는 수치형 행렬, na.rm는 결측치 제거 여부(기본 F) |
🍷데이터 변환
| as.character() |
|---|
| 문자형으로 변환 |
| as.numeric() |
|---|
| 숫자형으로 변환 |
| as.double() |
|---|
| 실수형으로 변환 |
| as.integer() |
|---|
| 정수형으로 변환 |
| as.logical() |
|---|
| 논리형으로 변환 |
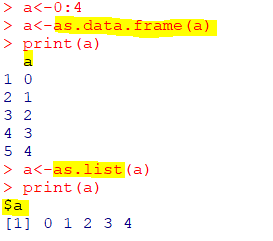
| as.data.frame() |
|---|
| 데이터 프레임으로 변환 |

| as.list() |
|---|
| 리스트로 변환 |
| as.matrix() |
|---|
| 행렬로 변환 |

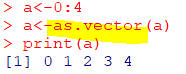
| as.vector() |
|---|
| 벡터로 변환 |
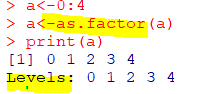
| as.factor() |
|---|
| 요인으로 변환 |
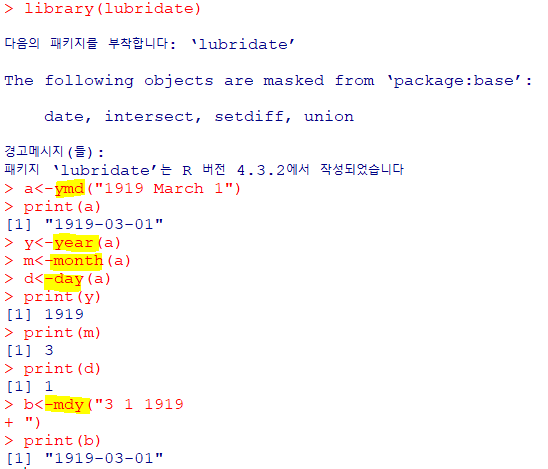
| ymd(x, ..) |
|---|
| 날짜 또는 수치형 데이터를 날짜형으로 변환(년월일 형식) == mdy, dmy year , month , day 함수로 연 월 일 추출 |
| make_date(year, month, day, ...) |
|---|
| 연, 월, 일 데이터를 날짜 형식으로 변환 |

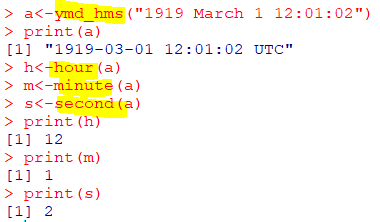
| ymd_hms(x, ...) |
|---|
| ymd_h : ymd+시 ymd_hm : ymd+시,분 ymd_hms : ymd+시,분,초 hour, minute, second 함수로 시, 분, 초 추출 == mdy_hms, dmy_hms |
| make_datetime(year, month, day, hour, minute, second, ...) |
|---|
| 연, 월, 일, 시, 분, 초 데이터를 날짜 형식으로 변환 |

| difftime(time1, time2, units) |
|---|
| time1에서 time2를 뺀 값 units : "auto"(자동),"secs","mins","hours","days","weeks" |

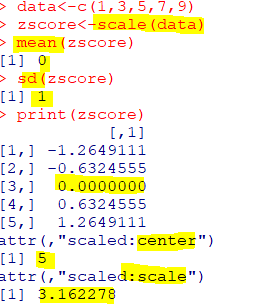
| scale(x, center=TRUE, scale=TRUE |
|---|
| x는 수치형 행렬 center는 수치형 데이터 입력 시 center에 지정된 값으로 뺄셈 실행, TRUE면 x의 평균으로 값을 빼서 정규화 scale는 수치형 데이터 입력 시 scale에 지정된 값으로 나눗셈 실행, TRUE면 x의 표준편차로 나눠서 정규화 X의 scale 적용 값=(X-center)/scale |
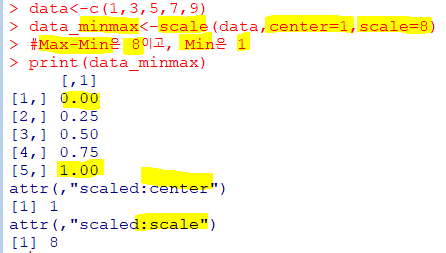
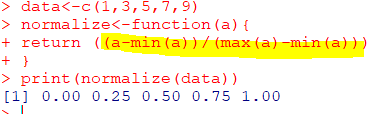
| MinMax=(X-Min)/(Max-Min) |
|---|
| 최소-최대 정규화 |
| Z=(X-X바)/s |
|---|
| Z-score(점수) 표준화. X바는 표본평균 scale함수의 center=T, scale=T일 경우 Z점수 표준화 적용 |
🍿표본 추출 및 데이터 전처리
| sample(x, size, replace, ...) |
|---|
| x는 데이터 프레임 또는 정수 size는 추출 개수 replace는 복원추출여부(기본 F), TRUE는 복원 추출 |

| mean(x, trim=0, na.rm=FALSE, ...) |
|---|
| x는 데이터, trim은 제외할 데이터 백분율 범위(양 옆 제외) |

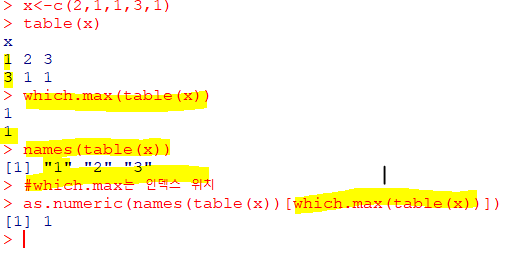
| as.numeric(names(table(x))[which.max(table(x))] |
|---|
| 최빈수 구하는 함수 |
| var(x,y=NULL, na.rm=FALSE) |
|---|
| x, y는 계산을 위한 데이터 |
| range(x) |
|---|
| 범위 계산 |

| quantile(x, probs) |
|---|
| probs는 계산할 백분위수 값 (0~1 값) x는 데이터 |

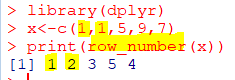
| row_number(x) |
|---|
| 동일 순위 X, 작은 순서대로 순위 지정 |
| min_rank(x) |
|---|
| 동일 순위 O, 동일한 값 있으면 다음 순위는 건너뜀 (==SQL의 RANK()) |

| dense_rank(x) |
|---|
| 동일 순위 O, 다음 순서 건너뛰지 않음 |


MySQL DBA 신입