📔설명
R을 이용해 분석 모형을 선택해보자
🍿개별 데이터 탐색
| table(x) |
|---|
| 범주형 데이터의 빈도수 탐색 함수 |
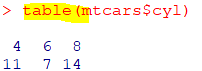
| length(x) |
|---|
| 전체 범주형 데이터의 개수 |
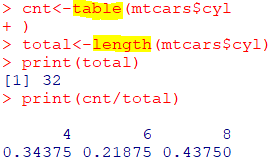
백분율 및 비율 : table함수의 결과에서 length함수로 나누어 구함
| summary(object) |
|---|
| 요약 통계량 탐색 함수 |
수치형인 경우 : 최솟값, Q1, 중위수, 평균, Q3, 최댓값 등
범주형인 경우 : 범주별 빈도수

| describe(x) |
|---|
| 요약 통계량 탐색 함수(데이터 개수, 절사 평균 포함) |
| describe 함수 출력값 | 설명 |
|---|---|
| vars | 변수의 개수 |
| n | 샘플의 크기 |
| mean | 평균 |
| sd | 표준편차 |
| median | 중위수 |
| trimmed | 절사평균(이상값 제외 데이터의 평균) |
| mad | 중위 절대 편차 |
| min | 최솟값 |
| max | 최댓값 |
| range | 범위(=최대-최소) |
| skew | 왜도(좌우 치우침 정도) |
| kurtosis | 첨도(뾰족한 정도) |
| se | 표준오차 |
library(psych)필요

🥩다차원 데이터 탐색
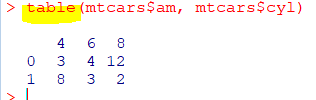
범주형-범주형 데이터 탐색
: table함수를 이용해 빈도수와 비율 활용
수치형-수치형 데이터 탐색
: 상관계수로 상관관계 파악 (피어슨 상관계수)
| cor(x, y, method) |
|---|
| method 기본값은 "pearson" "spearman"은 스피어만 순위 상관계수 "kendall"은 켄달 순위 상관계수 |

피어슨 상관계수: 두 변수가연속형 자료일 경우 사용,정규성만족 가정스피어만 순위 상관계수: 두 변수가순서적 데이터일 경우 사용,정규성만족X켄달 순위 상관계수: 두 변수가순서적 데이터일 경우 사용- x가 증가시 y도 증가하면 부합, x증가시 y 감소하면 비부합
τ=(C-D)/(C+D), C: 부합 쌍의 수, D : 비부합 쌍의 수
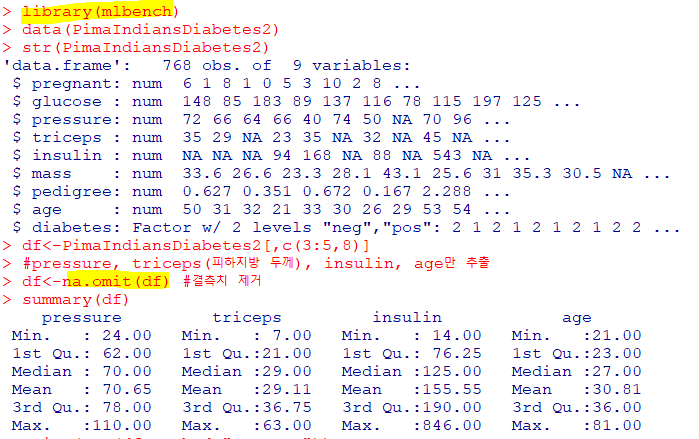
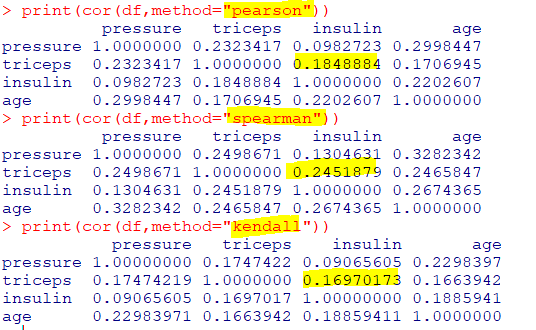
범주형-수치형 데이터 탐색
: 범주형 데이터를 그룹으로 간주하고 항목들에 관한 기술 통계량으로 탐색
| aggregate(formula, data, FUN, ...) |
|---|
| 그룹 간의 기술 통계량 제공 함수 FUN은 적용할 함수 |
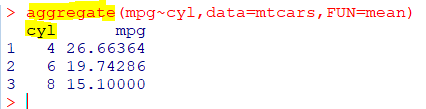
🍯전체 데이터 파악
| str(object) |
|---|
| 데이터의 구조를 알려주는 함수 |
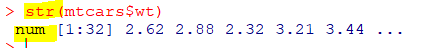

MySQL DBA 신입