📔설명
R을 이용해 분석 모형 구축을 해보자
🍿선형 회귀분석
: 독립변수와 종속변수의 관계가 선형이고, 하나 이상의 독립변수들이 종속변수에 미치는 영향을 추정
| lm(formual, data) |
|---|
| 선형 회귀분석 함수 |
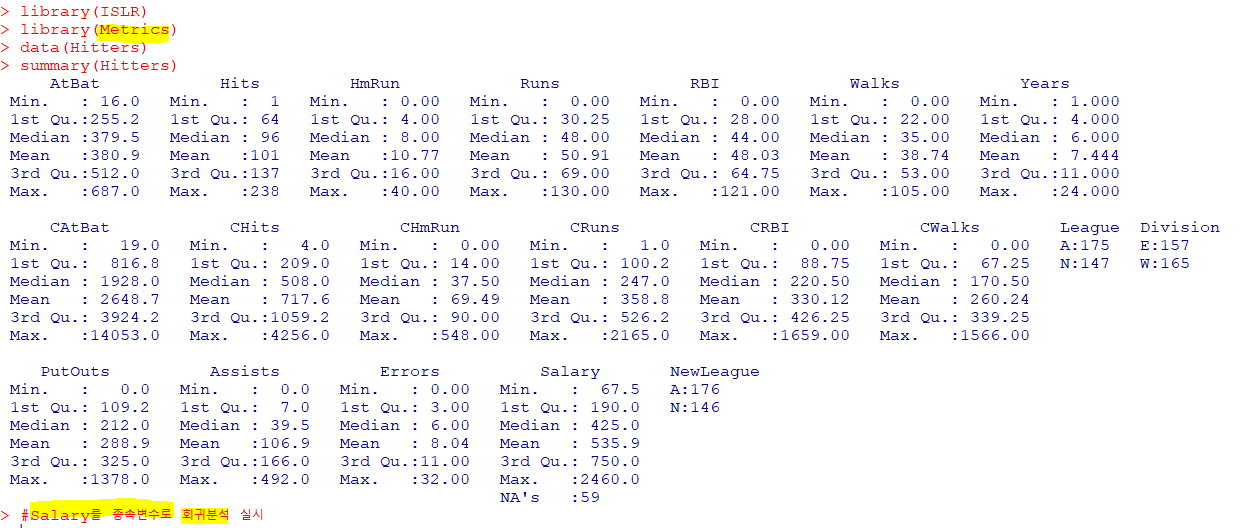
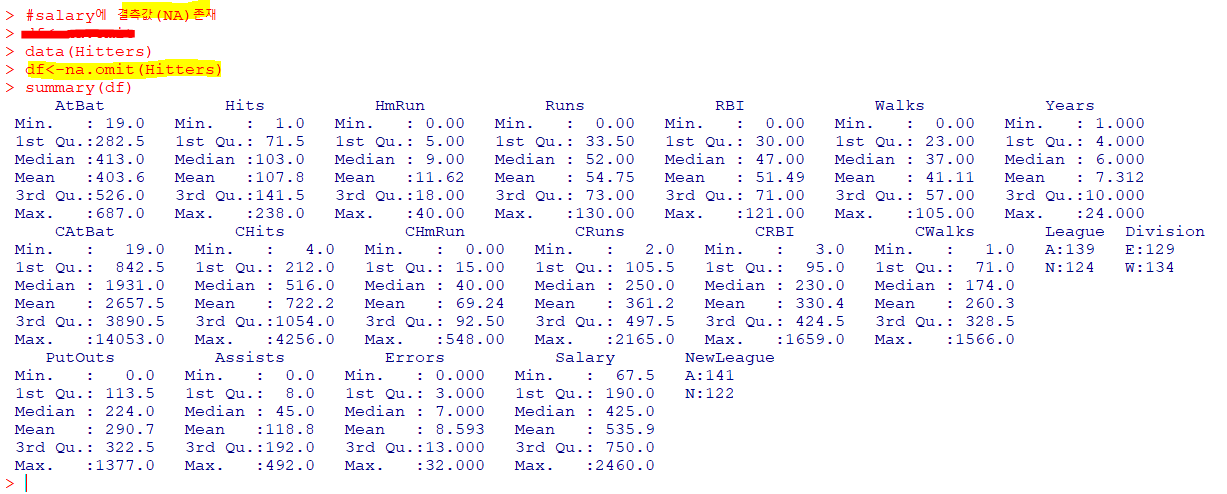
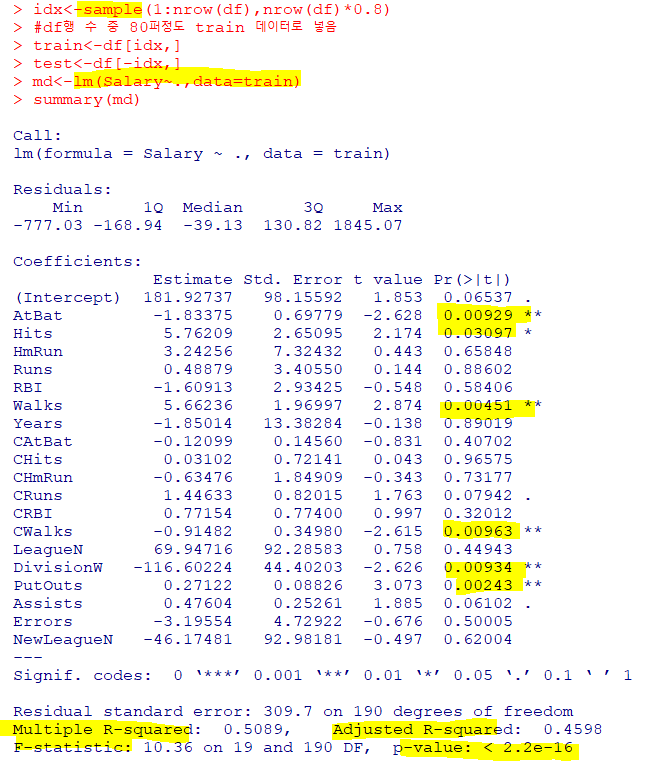

type="response" : 반응변수의 크기로 값 반환
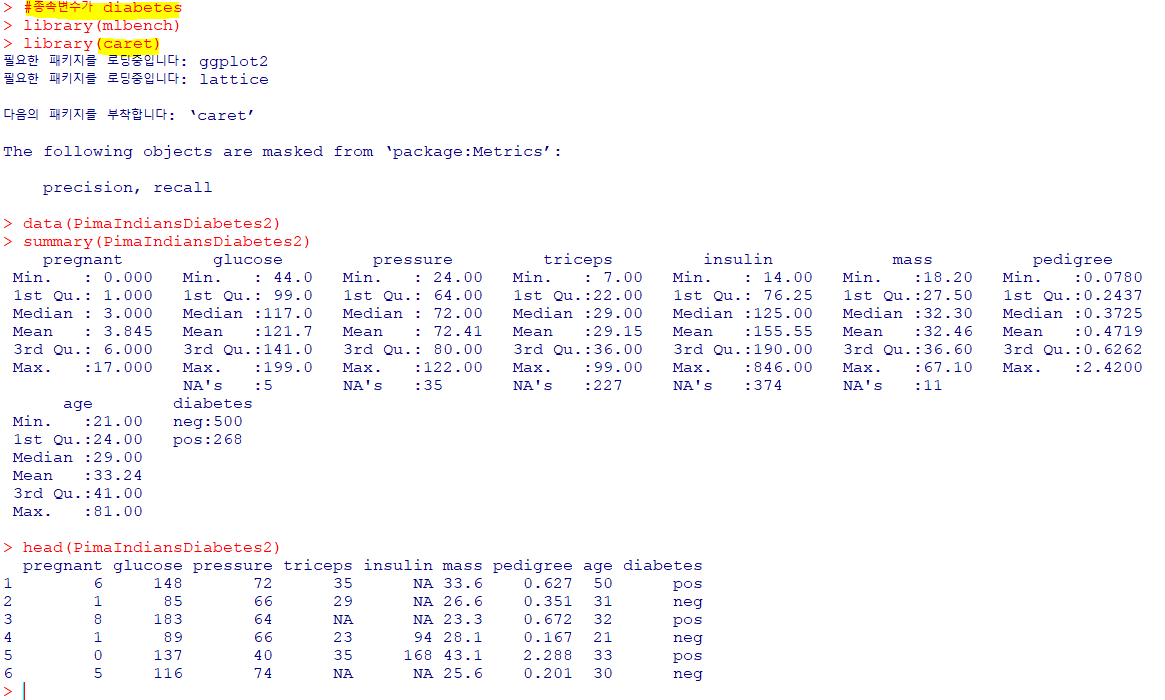
🥥로지스틱 회귀분석
: 종속변수가 범주형인 경우 적용되는 회귀분석
| glm(formual, family, data, ...) |
|---|
| 로지스틱 회귀분석 family : 이항 로지스틱 회귀분석(범주가 2개 ex.죽거나 살거나)인 경우 "binomial" |
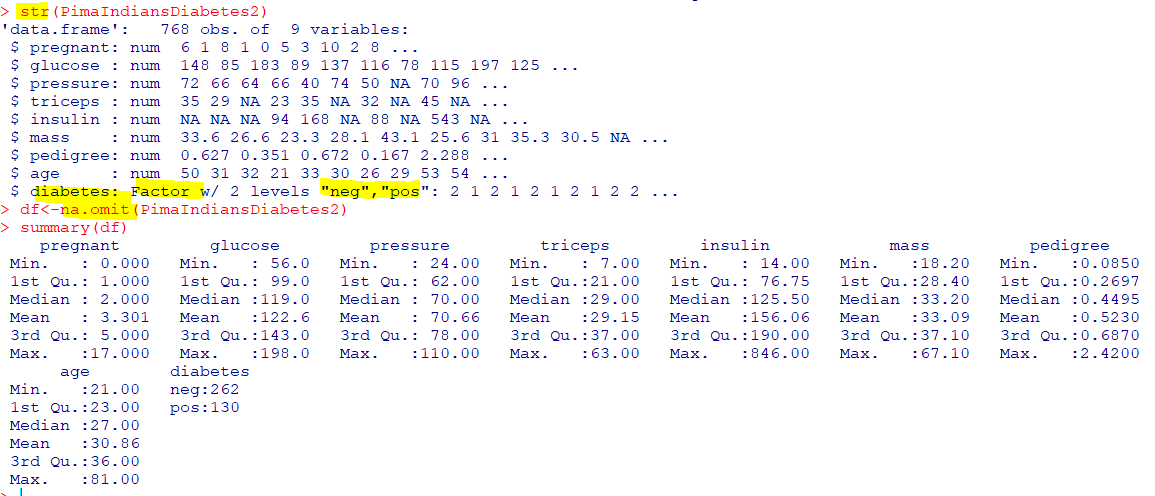
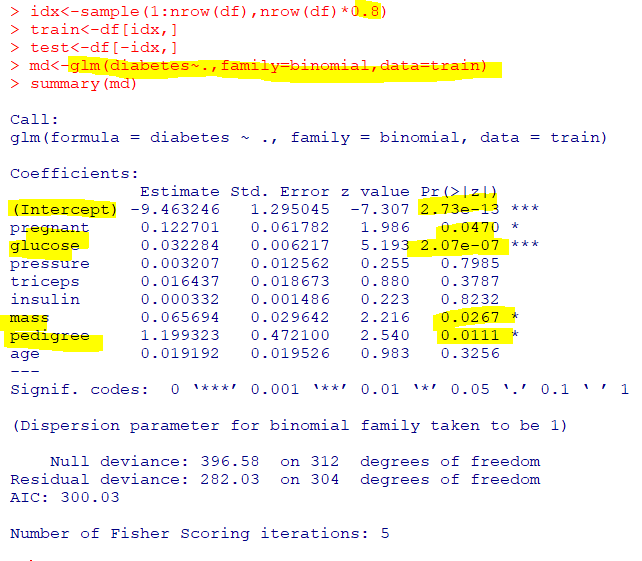
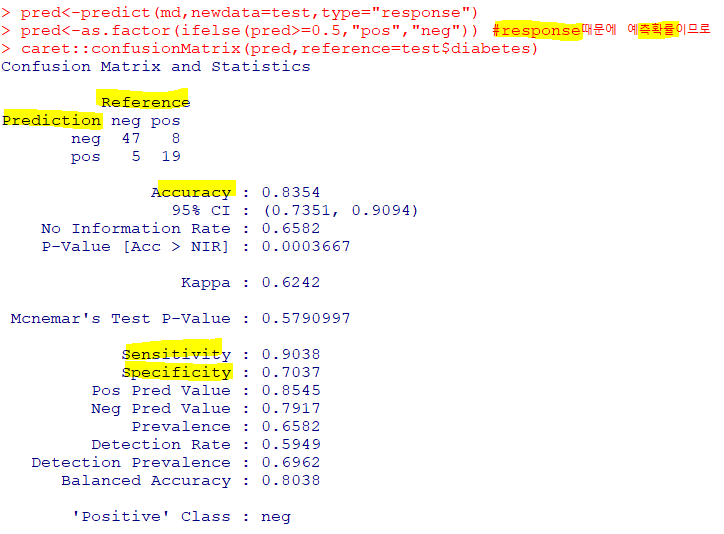

🗻의사결정 나무
: 데이터들이 가진 속성들로부터 분할 기준 속성을 판별하고, 그 속성에 따라 트리 형태로 모델링하는 분류 예측 모델
| rpart(formula, data) |
|---|
| 의사결정 나무 함수 |
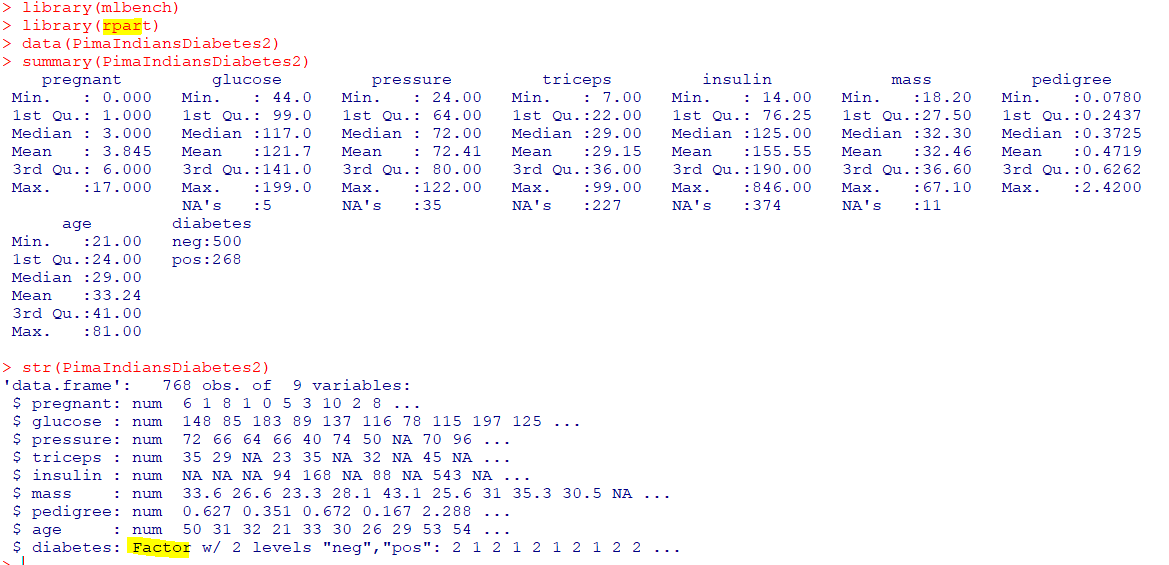
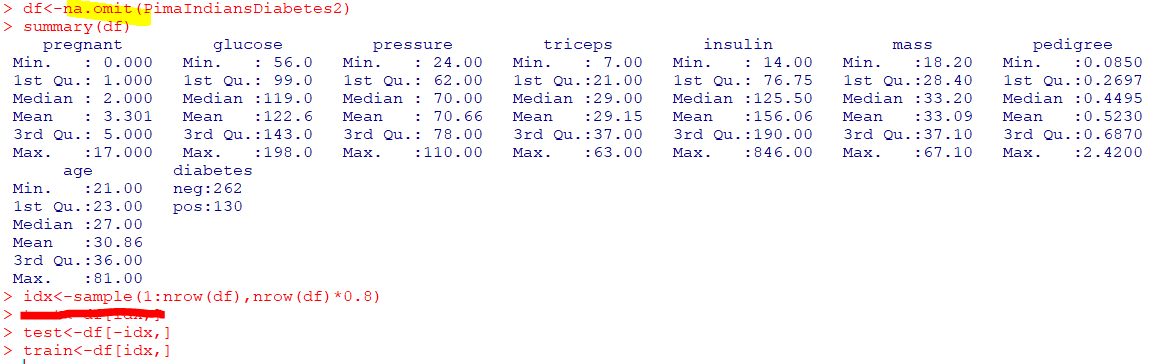
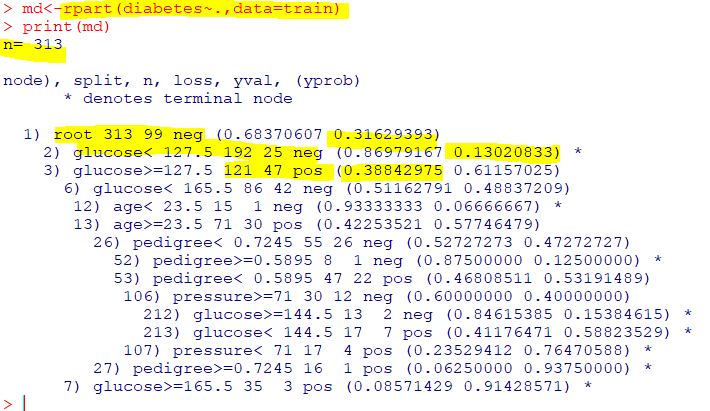
- 학습용 데이터(
n) = 313 root 313 99 neg는 루트노드이며, 313개의 데이터 중 99개의 데이터가부정(neg), 긍정(pos)은 68%, 부정은 31%glucose<127.5 192 25 neg에서glucose<127.5인 데이터의 수는313개 중 192개이며, 25개가 부정임
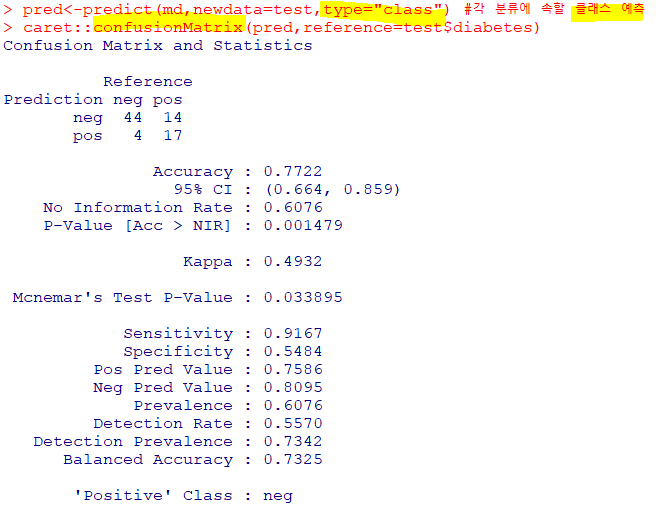
type="class" : 각 분류에 속할 클래스 예측

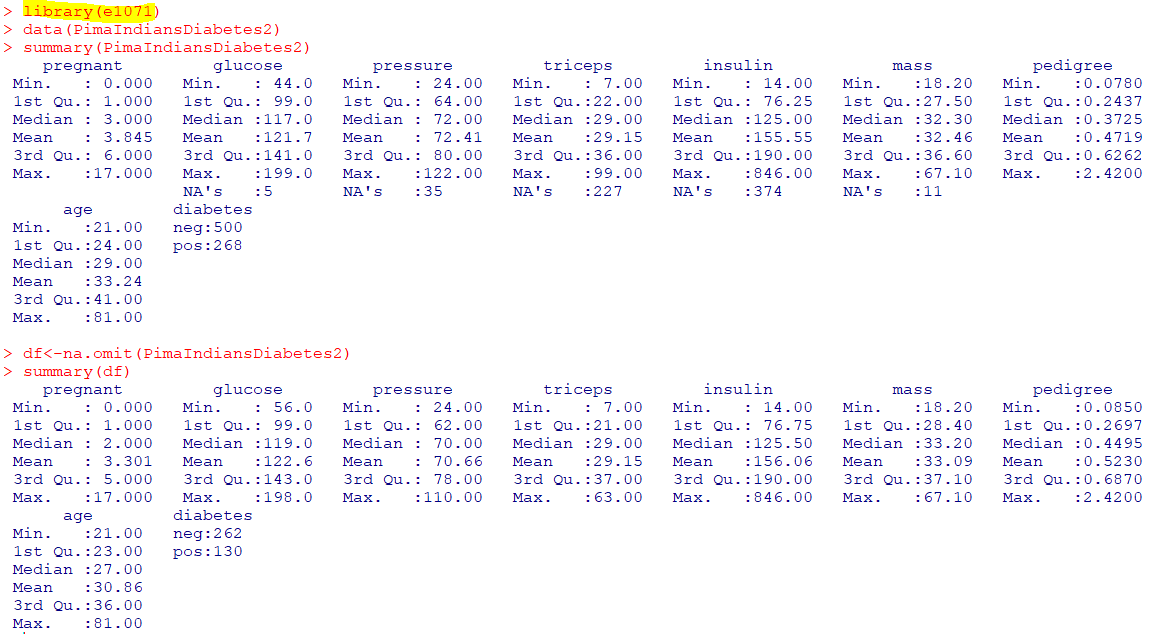
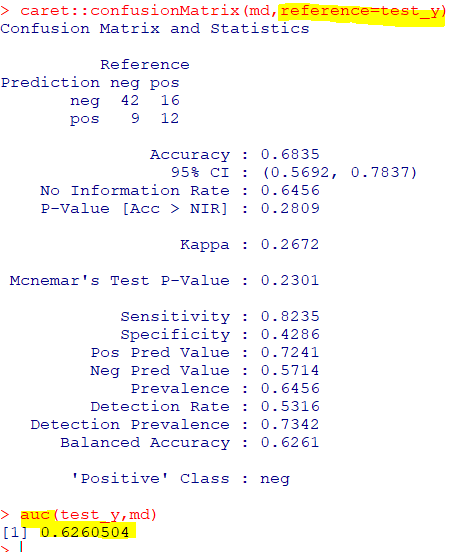
🛴서포트 벡터 머신
: 마진이 가장 큰 초평면을 선택하여 분리하는 지도학습기반 이진 선형 분류기
| svm(formula, data) |
|---|
| e1071패키지의 svm함수 |
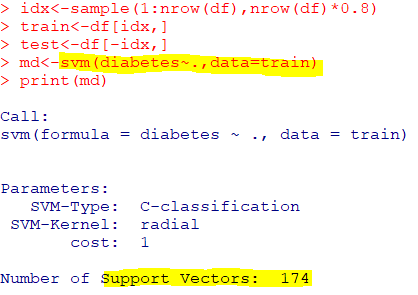
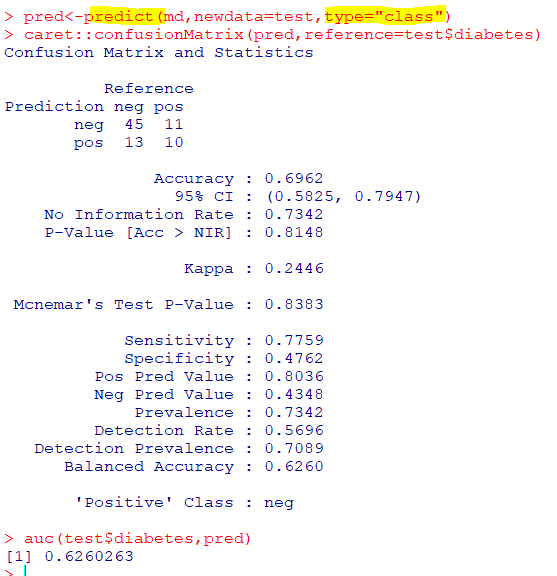
🧁K-NN
: 해당 데이터와 가장 가까운 k개의 데이터들의 클래스로 분류
- 일반적으로
k는훈련 데이터 개수의 제곱근 k는초매개변수
| knn(train, test, cl, k) |
|---|
| class 패키지의 knn함수 cl : 학습용 데이터의 종속변수 k : 근접 이웃의 수(기본 1) |

🥠인공신경망
: 입력값을 받아서 출력값을 만들기 위해 활성화 함수 사용
| nnet(formula, data, size, maxit, decay=5e-04 ...) |
|---|
| nnet패키지의 nnet 함수 size : 은닉층의 개수 maxit : 반복할 학습 횟수 decay : 가중치 감소의 모수(기본값 5e-04) |
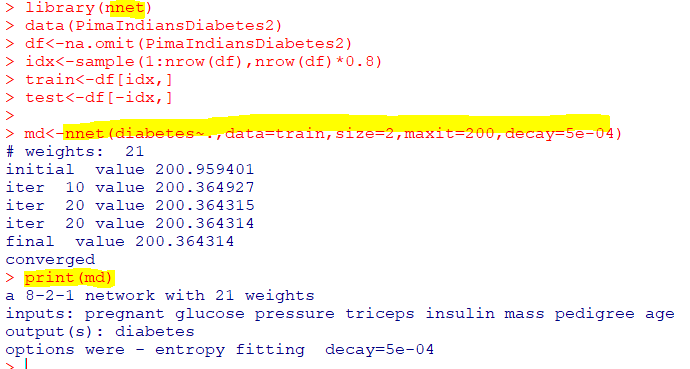
initial value : 초기 손실 함수
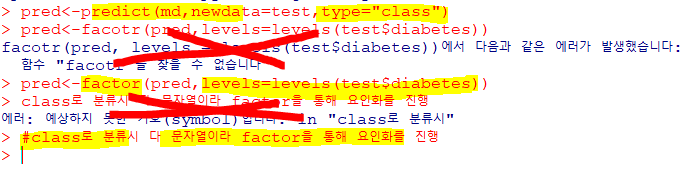
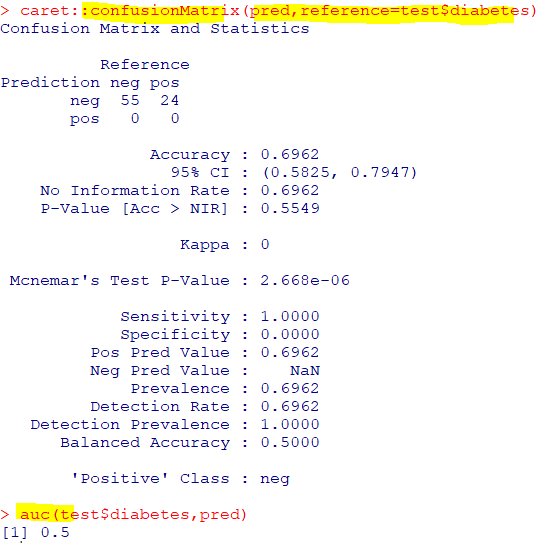
🍔앙상블
배깅 : 다수의 부트스트랩 자료를 생성해 각 자료 모델링 후 결합해 예측모형 생성
부트스트랩 : 랜덤 복원추출
| bagging(formula, data, nbagg) |
|---|
| ipred패키지의 bagging 함수 nbagg : bootstrap의 개수 설정 |
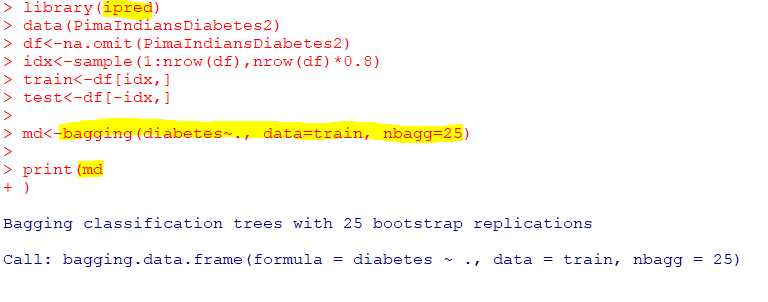
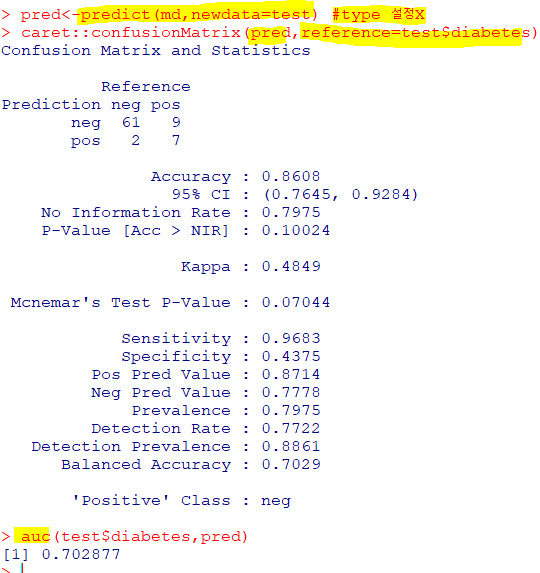
랜덤 포레스트 : 의사결정 나무의 분산이 크다는 점을 고려해 배깅과 부스팅보다 더 많은 무작위성을 주어 약한 학습기들을 선형 결합하여 최종 학습기 생성
| randomForest(formula, data, ntree, mtry) |
|---|
| randomForest패키지의 randomForest 함수 ntree : 사용할 트리의 수 mtry : 각 분할에서 랜덤으로 뽑힌 변수의 수(랜덤 표본 추출 변수 수) |
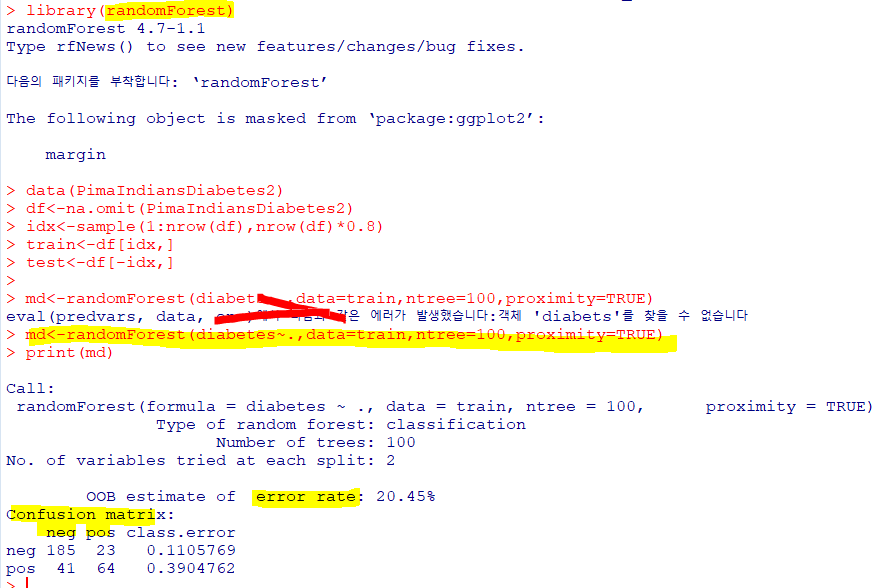
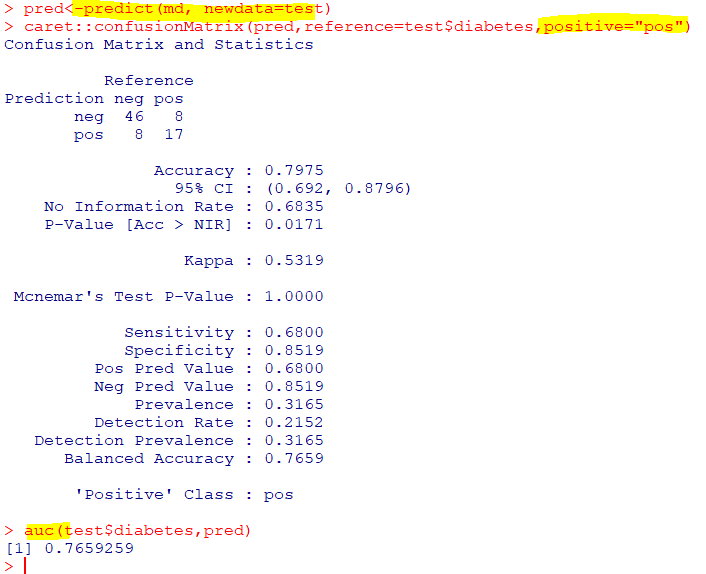
proximity=TRUE : 의사결정 트리 간 유사성 계산

MSSQL DBA 신입