BARC: Breed-Augmented Regression Using Classification for 3D Dog Reconstruction from Images
0. Abstract
목표 : 단일 이미지에서 3D Dog Reconstruction
- 개의 형태와 자세 매개변수를 추정하는 3D 관절 형태 모델을 기반으로 한 모델링 방법을 채택
문제점
- 양한 형태와 외모로 이루어짐
- 기존의 SMAL 모델은 다양한 개 종류를 표현하기에 충분한 표현력이 없음
- supervision signal인 2D 키포인트와 실루엣이 다양한 개 종류를 구별할 수 있는 regressor를 학습하기에 충분하지 않다
해결방법
- 개 형태를 보다 적합하게 표현하기 위해 SMAL 형태 공간을 수정
- 개 종류에 관한 정보를 활용하는 새로운 손실 함수를 정의
- 삼중 손실 : 같은 종류의 개의 형태가 다른 종류의 개보다 더 유사하도록 장려
- 종류 분류 손실
BARC (Breed-Augmented Regression using Classification), 3D 훈련 데이터 부족(lack)을 종류와 외모 유사성에 대한 사전 측면 정보를 사용하여 해결함
1. Introduction
인간의 경우에는 3D 형태 모델을 활용하여 재구성을 시도할 수 있지만, 동물의 경우에는 제한된 데이터와 형태 변동성의 어려움으로 인해 어렵다. 또한 특정 종에 대한 많은 개체에 접근하기 어렵다.
목표는 단일 이미지에서 개의 3D 형태와 자세를 추정하는 것이다.
- supervised, model-based 접근 방식
- 3D 관절 개 형태 모델의 매개변수를 예측하기 위한 regressor 훈련 부족한 3D 훈련 데이터 → 키포인트와 실루엣의 형태로 2D supervision network 훈련
- 2D 정보는 불충분함 → Normalizing Flows를 기반으로 하는 3D pose prior을 정의
- 개의 형태를 학습하기 위해 SMAL을 확장하여 ‘종(kind, breed)’ 라벨을 활용하는 "Breed-Augmented Regression using Classification" (BARC)라는 신경망을 훈련
Contribution
- 단일 이미지에서 3D 개 형태와 3D 자세를 회귀시키기 위해 새로운 신경망 구조를 제안
종류 분류 손실과 삼중 손실 부과 (동일한 종류의 이미지는 유사한 3D 형태를 생성하고, 다른 종류의 이미지는 다른 형태를 가져야 한다는 사실을 활용)
종류를 고려한 잠재적인 형태 공간을 학습 → 종류 간의 클러스터와 관계를 파악
일부 종류에 대해서는 3D 모델이 제공된 경우 이를 활용
120가지 다른 개 종류를 포함한 Stanford Extra (StanExt) 훈련 세트에 눈, 등뼈, 목의 키포인트를 추가하여 주석을 확장

모델이 학습하는 잠재공간에서, 관계있는(종이 비슷한) 개들이 가까이 위치하는 것을 확인할 수 있다. 정확도 측정을 위해 PCK, IOU와 같은 standard 2D measure를 사용하지만 3D 정확도를 완전히 반영하지는 못하기에 추가적인 3D 개 데이터셋을 만들어 대응하는 의 형태를 비교한다.
2. Related Work
생략
3. Approach
훈련 시 알려진 종 정보의 활용을 탐구하고 고품질의 3D 개 모델을 회귀하는 것을 목표로 한다. 이를 위해 매개변수화된 개 모델과 이미지를 모델 인스턴스로 매핑하는 신경망을 결합한다.
3.1 Dog Model
개의 형태와 자세를 매개변수화하기 위해 SMAL의 변형을 사용한다. 스캔된 동물 toy figurine과 3D 유니티 개 모델을 활용하여 SMAL 형태 공간을 재학습한다. 결과 모델은 SMAL과 다음과 같은 차이가 있다.
(1) 다른 입력 데이터
(2) 입력에 대한 가중치 재조정으로 전체 가중치의 50%가 개에 할당
(3) 표면 메쉬의 허리 부분의 길이를 항상 1로 조정하는 메쉬의 크기 조정
또한 limb에 대한 스케일링 파라미터 k와 머리 길이에 대한 추가적 스케일을 도입한다. 스케일링은 뼈 길이에 적용되고 linear blend skinning(LBS)가중치를 통해 mesh에 적용된다.
특정 개의 형태는 다음과 같이 계산된다
-
Calculating shape deformations caused by βpca
PCA 방향은 instance specific shape coefficients βpca와 곱해져 정점마다 shape displacement vector가 생성된다.
-
Adding displacements to shape template
shape displacement는 generic shape template(mean shape of PCA)에 추가된다. 결과는 t-pose dog mesh이다.
-
Posing model and adding shape deformations caused by κ
linear blend skinning weights(LBS)를 사용하여 limb scaling parameter가 각 정점에 미치는 영향을 결정한다. LBS 가중치에 따라 해당하는 정점의 shift 값이 계산된다. 즉 limb scaling과 posing을 동시에 수행한다.
PCA 형태 계수인 βpca와 사지 스케일링 매개변수인 κ를 shape vector β로 둔다.
3.2 Architecture
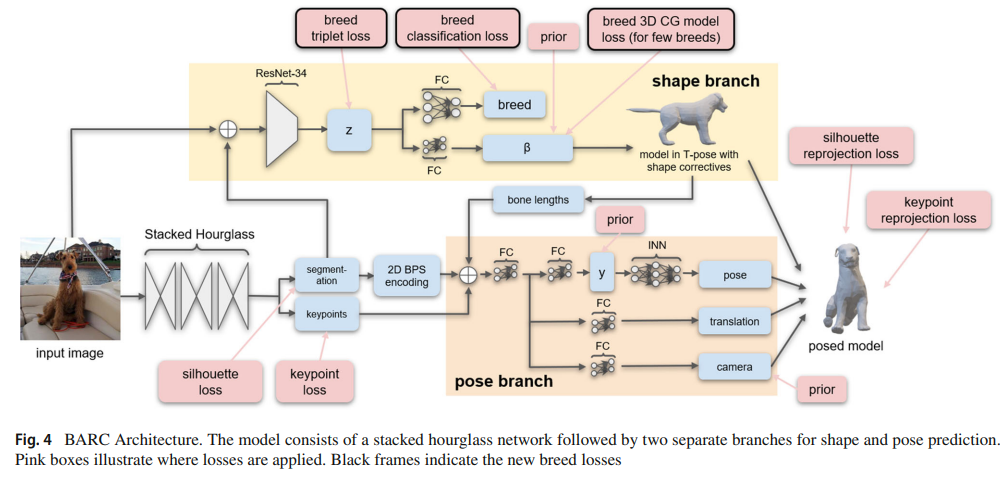
shape과 pose에 대한 별도의 branch를 갖는다. BARC는 stacked hourglass encoder, shape branch, pose branch, 3D prediction reprojection 모듈로 결합되어 있다.
3.2.1 Stacked Hourglass
pre-trained stacked hourglass네트워크에 입력 이미지를 넣으면 2D keypoint heat map과 segmentation map을 예측한다. 2D keypoint는 NCR(numerical coordinate regression)을 통해 히트맵에서 추출되고 segmentation map은 3D point cloud encoding을 위해 BPS(basis point sets)와 유사한 방법으로 인코딩된다.
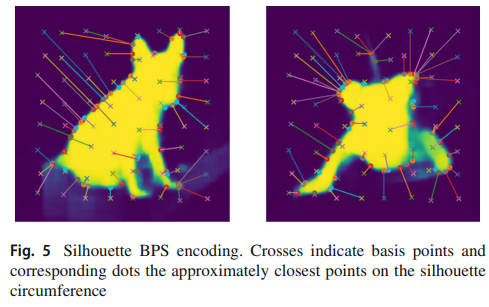
basis point set을 구성하는 64개의 십자 점과, 윤곽선에 가장 가까운 점을 볼 수 있다. basis point는 이미지에 regular 8X8 grid를 겹치고 무작위 변동을 추가하여 사전에 정의한다. 윤곽점의 x, y좌표를 연결해서 128차원 인코딩을 얻는다. → 가볍고 윤곽선에 대한 계산이 쉬우며 NCR keypoint와 유사한 형식을 갖음 → 2D 키포인트만 사용하는 것보다 3D 예측을 개선
3.2.2 Shape-Branch
입력 이미지와 예측된 segmentation map은 concat되어 ResNet34에 입력으로 들어가서 shape에 대한 latent encoding z를 예측한다. z는 개의 종류 (breed, 클래스) 점수와 body shape coefficient β로 디코딩된다. z와 각각의 shape vector κ와 βpca 사이에는 single fully-connected layers 연결이 breed similarity loss에 가장 효과적이었다. β는 3D dog template에 적용되어 shape을 얻고, 뼈 길이가 pose branch로 전달된다.
3.2.3 Pose-Branch
2D keypoint, 실루엣에 대한 BPS encoding, shape-branch로부터 온 뼈 길이는 개의 3D pose, 카메라 좌표계에 대한 이동 및 카메라의 초점 길이를 추정하는 데 사용된다. pose는 관절에 대한 6D rotation으로 표현되고 root rotation을 포함한다. 모든 회전을 직접 예측하는 대신 루트 회전과 pose latent representation y를 예측한다. 각 y를 pose로 매핑하는 invertible neural network (INN)을 구현한다. INN의 목표는 3D dog pose의 분포를 간단하고 추론 가능한 밀도 함수인 spherical multivariate Gaussian distribution로 매핑하는 것이다.
3.2.4 3D Prediction and Reprojection Module
shape, pose, translation에 따라 모델을 pose하고, focal length를 사용해서 keypoint와 실루엣을 이미지 공간으로 재투영한다. 이 재투영 오차를 최소화하기 위해서 PyTorch3D differentiable
renderer를 사용한다.
3.3 Training Procedure
stacked hourglass
키포인트 손실 : 실제와 예측된 히트맵 사이의 평균 제곱 오차 (MSE), 실제와 예측된 키포인트 좌표 사이의 L2 거리
윤곽선 손실 : 실제와 예측된 mask 사이의 cross-entropy
pose branch
pose와 random shape을 샘플링해서 random translation과 focal length로 이미지 공간에 투영, 투영된 keypoint와 실루엣이 입력으로 사용된다. MSE loss를 사용. 실제와 예측된 y 사이의 MSE loss도 사용함
main training
stacked hourglass는 fixed되며 다른 네트워크 파라미터는 같이 최적화된다. 정규화를 위해서 재투영 손실과 적절한 prior를 결합한다.
3.4 Standard Losses
생략
3.5 Novel Breed Losses
생략
4. Experiments
Stanford Extra Dog(StanExt)를 사용하여 평가한다. Animal Pose에서 별도의 stacked hourglass를 훈련시켜서 별도의 20개의 키포인트를 확장한다.
4.1 Evaluation Methods
2D Reprojection Error
3D GT가 없으므로 이미지 공간에서의 재투영 오차를 기준으로 평가. 실루엣에 대해 IoU(intersection over union), 키포인트에 대해 PCK(percentage of correct keypoints) 사용
Perceptual Shape Evaluation

인간의 시각적 평가를 통해 야외 이미지에서 회귀된 3D 형태의 상대적인 정확성을 평가하기 위해 연구를 진행
Breed Prototype Consistency

동일한 개 종의 개들이 유사한 형태를 가지는 사실을 활용하여 평가를 보완한다. 모형을 사용하여 여러 개 종에 대한 프로토타입 형태를 정의하고, 이를 기준으로 예측된 형태와의 오차를 측정하여 종 형태를 얼마나 잘 포착하는지를 판단한다.
4.2 Comparison to Baselines
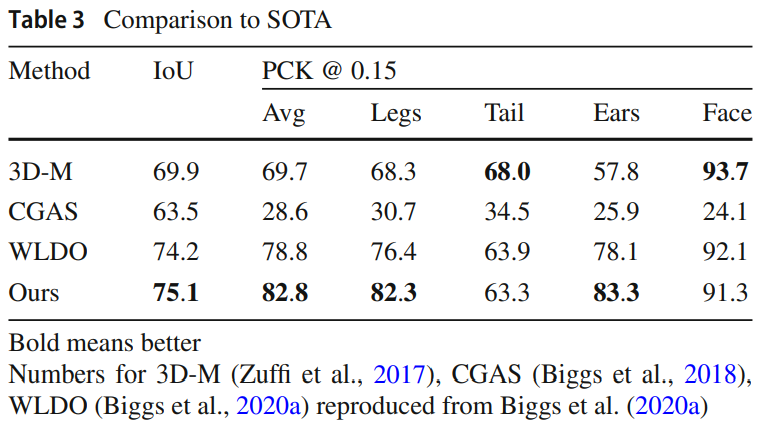

2D 오차 지표(IoU 및 PCK)에서 다른 선행 연구들보다 우수한 성능을 보인다. 개 종 라벨에 접근할 수 있고 눈과 목에 대한 추가적인 키포인트를 활용하는 등의 차이점을 가지고 있다. 시각적 비교에서도 BARC는 WLDO와 비교하여 92.4%의 경우에서 더 나은 표현력을 보다.
4.3 Ablation Study
생략
4.4 Failure Case Analysis

Pose Failure Cases
카메라를 향하지 않거나 앞 다리를 심하게 구부린 개의 자세를 예측하는 데 어려움이 있다 → 이미지 데이터셋의 문제 → 드문 자세가 더 높은 가중치를 얻거나 더 자주 반복되도록 훈련
전면에서 본 경우 측면보다 3D 품질이 더 높게 인식되는 경우가 많다 → 강력한 3D 정규화가 필요
개가 부분적으로만 보이는 경우나 훈련할 때 보이던 자세와 거리가 있는 경우 BARC는 정확하게 자세를 예측할 수 없
Shape Failure Cases
breed loss는 shape을 정규화하는데 도움을 준다. 그러나 개가 눕거나 카메라를 향해 있는 등의 자세로 인해 예측이 어려운 경우에는 사지가 단축된다.
품종 내부의 가변성으로 각 품종마다 단일 형상을 사용하는 것은 불가능하다. 개의 털은 shape의 가변성과 mesh로 긴 털을 표현하는 것이 이상적이지 않기에 도전적인 문제이다.
5. Conclusion
개의 3D pose와 shape을 이미지로부터 재구성하기 위한 방법을 제안한다. 품종을 고려한 손실 함수를 사용하여 모델 기반의 모양 예측을 훈련한다.
5.1 Limitation
shape space에 제한되어 있다. 향후 연구에서는 품종 제약들을 활용해서 개선된 shape space를 활용해야한다. 해당 연구는 주로 shape에 초점을 두었지만 pose와 움직임도 중요하다.
