https://github.com/thu-coai/ConvLab-2
튜토리얼 보면서 함수와 코드 따라가기
sys_nlu = BERTNLU()
convlab2/nlu/jointBERT/multiwoz/nlu.py
nlu = BERTNLU(mode='sys', config_file='multiwoz_sys_context.json',
model_file='https://convlab.blob.core.windows.net/convlab-2/bert_multiwoz_all_context.zip'main에서 이렇게 부름
Dataloader(intent_vocab=intent_vocab, tag_vocab=tag_vocab,
pretrained_weights=config['model']['pretrained_weights'])init에서 Dataloader함수 부름 아마 여기서 multiwoz 데이터를 넣어주는 듯.
intent_vocab?
tag_vocab?
(두개 개수가 다름)
model = JointBERT(config['model'], DEVICE, dataloader.tag_dim, dataloader.intent_dim)그 다음 JointBERT 함수 호출(forward로 들어가는 듯)
convlab2/nlu/jointBERT/jointBERT.py
nn.Module을 상속
def forward(self, word_seq_tensor, word_mask_tensor, tag_seq_tensor=None, tag_mask_tensor=None,
intent_tensor=None, context_seq_tensor=None, context_mask_tensor=None):
if not self.finetune:
self.bert.eval()
with torch.no_grad():
outputs = self.bert(input_ids=word_seq_tensor,
attention_mask=word_mask_tensor)
else:
outputs = self.bert(input_ids=word_seq_tensor,
attention_mask=word_mask_tensor)
sequence_output = outputs[0][0]
pooled_output = outputs[1]
if self.context and (context_seq_tensor is not None):
if not self.finetune or not self.context_grad:
with torch.no_grad():
context_output = self.bert(input_ids=context_seq_tensor, attention_mask=context_mask_tensor)[1]
else:
context_output = self.bert(input_ids=context_seq_tensor, attention_mask=context_mask_tensor)[1]
sequence_output = torch.cat(
[context_output.unsqueeze(1).repeat(1, sequence_output.size(1), 1),
sequence_output], dim=-1)
pooled_output = torch.cat([context_output, pooled_output], dim=-1)
if self.hidden_units > 0:
sequence_output = nn.functional.relu(self.slot_hidden(self.dropout(sequence_output)))
pooled_output = nn.functional.relu(self.intent_hidden(self.dropout(pooled_output)))
sequence_output = self.dropout(sequence_output)
slot_logits = self.slot_classifier(sequence_output)
outputs = (slot_logits,)
pooled_output = self.dropout(pooled_output)
intent_logits = self.intent_classifier(pooled_output)
outputs = outputs + (intent_logits,)
if tag_seq_tensor is not None:
active_tag_loss = tag_mask_tensor.view(-1) == 1
active_tag_logits = slot_logits.view(-1, self.slot_num_labels)[active_tag_loss]
active_tag_labels = tag_seq_tensor.view(-1)[active_tag_loss]
slot_loss = self.slot_loss_fct(active_tag_logits, active_tag_labels)
outputs = outputs + (slot_loss,)
if intent_tensor is not None:
intent_loss = self.intent_loss_fct(intent_logits, intent_tensor)
outputs = outputs + (intent_loss,)
return outputs # slot_logits, intent_logits, (slot_loss), (intent_loss),self.bert = BertModel.from_pretrained(model_config['pretrained_weights'])self.bert는 init에서 요렇게 부름 즉 사전훈련된 bert 모델을 가져온듯
self.bert는 init에서 요렇게 부름 즉 사전훈련된 bert 모델을 가져온듯보면 처음에는 word_seq_tensor를 넣고
*word_seq_tensor는 tokenizer 결과임
여기서 outputs[0][0]을 sequence_output으로
outputs[1]을 pooled_output으로 받음
context_output = self.bert(input_ids=context_seq_tensor, attention_mask=context_mask_tensor)[1]두번째로는 context_seq_tensor를 넣음
sequence_output = torch.cat(
[context_output.unsqueeze(1).repeat(1, sequence_output.size(1), 1),
sequence_output], dim=-1)
pooled_output = torch.cat([context_output, pooled_output], dim=-1)그리고 sequence_output하고 pooled_output 생성(위에서 만든거에다 context_output을 붙인듯)
sequence_output = self.dropout(sequence_output)
slot_logits = self.slot_classifier(sequence_output)
outputs = (slot_logits,)
pooled_output = self.dropout(pooled_output)
intent_logits = self.intent_classifier(pooled_output)
outputs = outputs + (intent_logits,)다시 nlu.py로 돌아오자
자, main에서 nlu에 BERTNLU를 할당하고, BERTNLU 클래스의 init에서 dataloader를 불러왔고 그 다음 JointBERT 클래스를 실행해서 model 변수로 받음. 아마 이때 실행되는 것은 JointBERT의 init인듯. 다시 main에서 nlu.predict(text)를 실행함. 따라서 BERTNLU 클래스의 predict 함수가 실행
토크나이닝하고 model.forward로 slot_logits와 intent_logits를 받아옴
recover_intent로 das를 받음 이때 das는 (intent, slot, values)로 이루어짐
recover_intent
convlab/nlu/jointBERT/multiwoz/postprocess/recover_intent
intent를 ‘-’로 domain과 intent로 나누고
반환값인 dialog_act에 [intent, domain, slot, value]를 넣고 끝!
sys_agent.response("Which type of hotel is it ?")물론 pipeline이라서 nlu-dst-pl-nlg 중 nlu 부분 출력만 일단 보자면


이렇게 나옴. [intent, domain, slot, value] 이런 식으로 utterance의 발화를 parse해서 반환하는 느낌!
이제 dst 보러가자
convlab2/dst/dst.py

간략한 dst 구조를 먼저 보자
internal dialog state 변수를 업뎃하는데 update에서는 action을 인풋으로, update_turn에서는 sys_utt와 user_utt를 인풋으로 받는다. 둘 다 new_state 즉 업데이트한 dialog state를 반환한다.
자세한 코드를 보자
sys_dst = RuleDST()multiwoz를 통해 학습시킨 전체 구조를 따라가므로
convlab2/dst/rule/multiwoz/dst.py
self.state = default_state()RuleDST함수의 init에선 먼저 default_state()를 부른다
대충 [domain, slot, value] 요 구조 틀을 state에 넣는 듯

action = [
["Inform", "Hotel", "Area", "east"],
["Inform", "Hotel", "Stars", "4"]
]action은 [intent, domain, slot, value] 이 구조임 즉 nlu에서 받아온 반환 값과 구조가 똑같음.
- domain은 'Attraction', 'Hospital', 'Booking', 'Hotel', 'Restaurant', 'Taxi', 'Train', 'Police’ 중 하나. 왜? default_state 구조에 저 항목만 있으니까!
- intent(=type)은 request와 inform 둘 중 하나. (기억 난다면, nlu에서 intent를 ‘-’로 domain과 intent로 나눔. 원래는 Hotel-inform이었다가 나눠서 domain은 hotel, intent은 inform이 되는 것.
- area는 슬롯
- 4는 value 값
state = dst.update(action)update 함수로 들어가자
- domain이 unk, general, booking이라면 continue를 통해 다시 반복문 돌아감
- intent가 inform이라면?
domain_dic = self.state['belief_state'][domain]belief state가 내 생각에는 대화가 진행되면서 얻은 정보 (예를 들면 지금 action이 inform-hotel-area-east ⇒ 서쪽 지역의 호텔 inform)이라면 이걸 저장해두는거임

이런 식으로 action 정보를 알맞은 belief state에 저장함
- intent가 request라면?

request_state에 해당하는 알맞는 곳에 저장하기
자 이제 예제를 보자
먼저 main에서
action = [
["Inform", "Hotel", "Area", "east"],
["Inform", "Hotel", "Stars", "4"]
]
# method `update` updates the attribute `state` of tracker, and returns it.
state = dst.update(action)이때 update 함수에서 인자로 들어간 action을 user_act 변수로 받고
user_act : [['Inform', 'Hotel', 'Area', 'east'], ['Inform', 'Hotel', 'Stars', '4 ']] 요렇게 됌
self.state : {'user_action': [],
'system_action': [],
'belief_state': {'police':
{'book':
{'booked': []},
'semi': {}},
'hotel':
{'book':
{'booked': [],
'people' : '',
'day': '',
'stay': ''},
'semi':
{'name': '',
'area': 'east',
'parking': '' ,
'pricerange': '',
'stars': '4',
'internet': '',
'type': ''}}이런 식으로 inform이니까 belief_state에 정보가 박힘
싱기한건 요 예제에서는 history에 뭐가 안남음 근데
sys_agent.response("I want to find a moderate hotel")
sys_agent.response("Which type of hotel is it ?")
sys_agent.response("OK , where is its address ?")이렇게 하고 나면?
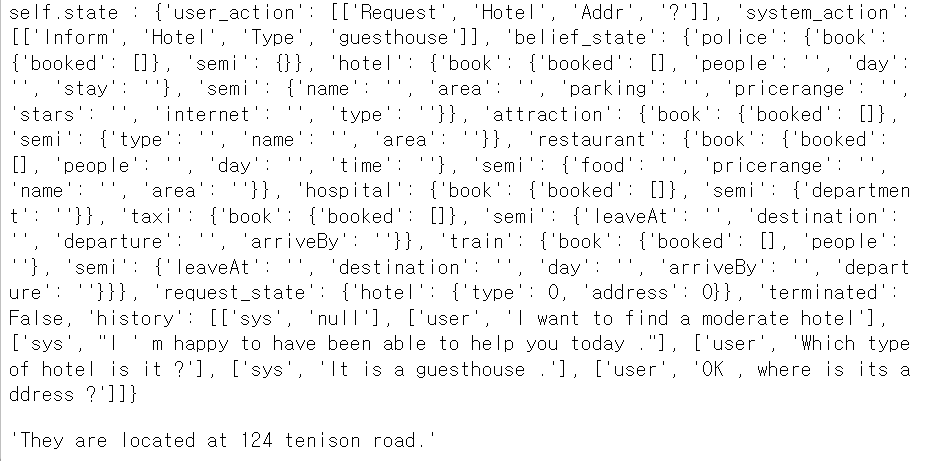
이런 식으로 hitory에, 특히
sys_agent = PipelineAgent(sys_nlu, sys_dst, sys_policy, sys_nlg, name='sys')sys_agent를 ‘sys’로 뒀으니 response에 들어가는게 user_action이잖아? 그래서 hitory의 ‘user’부분에 여태 대화가 쭉 남음
이런식으로 state를 dic 형태로 남겨주는게 dst가 하는 역할 같음
다음 dp로 넘어갑시다
pipeline ToD에 DP 모듈은, dialog state를 인풋으로 받아서 DP를 바탕으로 system action을 고름!
간단한 구조를 보면
predict 함수에서 주어진 dialog state에 기반하여 next agent action을 선택하게 됌
sys_policy = RulePolicy()convlab2/policy/rule/multiwoz/README.md를 잠깐 보자
- rule policy는 system dialog policy임. dialog state를 받아서 system의 dialog act를 생성함
- agenda policy는 user dialog policy임. system dialog act를 받아서 user dialog act를 생성함.
convlab2/policy/rule/multiwoz/rule.py를 보자
class RulePolicy(Policy):
def __init__(self, is_train=False, character='sys'):
self.is_train = is_train
self.character = character
if character == 'sys':
self.policy = RuleBasedMultiwozBot()
elif character == 'usr':
self.policy = UserPolicyAgendaMultiWoz()
else:
raise NotImplementedError('unknown character {}'.format(character))init에서 먼저 sys인지 usr인지 구분하고 들어감
위에서 말했듯 sys인 경우 rule, usr인 경우 agenda로 들어감 우리 예제는 일단 sys이므로
RuleBasedMultiwozBot()을 먼저 보자

이게 state랑 다른게 뭘까? 일단 넘어가봅시다
class RuleBasedMultiwozBot(Policy):
''' Rule-based bot. Implemented for Multiwoz dataset. '''
recommend_flag = -1
choice = ""
def __init__(self):
Policy.__init__(self)
self.last_state = {}
self.db = Database()궁금하니까 잠깐 Database()를 보자
음… 대충 도메인 설정해주고 필요한 정보 읽어오는듯?
다시 rule.py로 돌아오면 self.policy에 지금 rulebasedmultiwozbot 클래스를 할당함
self.output_action = deepcopy(self.policy.predict(state))다시 rulebased multiwozbot 클래스의 predict함수를 보자
- state에 user_action이 존재하고 1개보다 더 많고 str 타입이 아니라면?
- [k-i, s,v] 형식으로 바꿔주는 듯?
- else라면?
- check_diff()
- 뭐하는거야… 개복잡함
- check_diff()
아무튼 이렇게 user_action이라는 변수가 생김
현재 state는 last_state에 저장해두고
user_action을 for문으로 돌림

** dst update할 때, general하고 booking은 state에 안넣고 그냥 continue로 패스했던 기억이 있음 그래서 이거 처리하려고 (아마도) check_diff에서 뭔가 해결하지 않나 싶긴 함
각각의 조건문에서 알맞은 함수로 들어가서 DA라는 list에다가 필수? 필요한? 요소를 넣음
뭔지는 출력해봐야 알것 같음
- 잘 보면 세번째 elif문 (domain≠Train) 즉 우리 도메인에 없는 얘기를 하면 Answer user's utterance about any domain other than taxi or train 으로 답변한다고 함… 여기 코드 넘 복잡…
- booking은 아예 코드 구현이 안됌
- train같은 경우에는 뭔가 되묻는 그런 내용이 DA에 들어가는거 같음
self._judge_booking(user_act, user_action, DA)그 다음에는 유저가 booking을 원하는지
if len([domain_intent for domain_intent, slots in DA.items() if slots or 'nooffer' in domain_intent.lower()]) == 0:
DA = {'general-greet': [['none', 'none']]for domain_intent, svs in DA.items():
domain, intent = domain_intent.split('-')
if not svs and domain=='general':
tuples.append([intent, domain, 'none', 'none'])
else:
for slot, value in svs:
tuples.append([intent, domain, slot, value])즉 DA는 지금 domain_intent랑 svs로 이루어짐
svs가 없고 domain이 general이면 저렇게 하고~
아니면 이렇게 하고~
tuple을 state[’system_action’]에 저장하고 반환하고 끝
그리고 그걸 self.output_action에 저장!
첫번째 예시
sys_agent.response("I want to find a moderate hotel")state를 보면, user_action에 뭐가 없음.
따라서 check_diff로 가는데, 인자가 last_state, state임
아마 이게 첫 실행 문장이라 last_state가 없으므로 user_action도 비어있는거 같음
따라서 아예 for문이 돌지 않고 DA2로 넘어가고 DA가 비어있으므로 DA = {'general-greet': [['none', 'none']]} 이걸 채워줘서 최종 DA는 저게 됌
이때 domain은 general, intent는 greet, svs는 [[’none’,’none’]]
따라서 tuple역시 같은 값, 이 tuple을 state[’system_action]에 넣어주고 끝

system action과 history에 채워진게 보임
두번째 예시
sys_agent.response("Which type of hotel is it ?")nlu에서
das : [['Hotel-Request', 'Type', '?']]
dialog_act : [['Request', 'Hotel', 'Type', '?']]이거까지 뽑아오고 dst에서
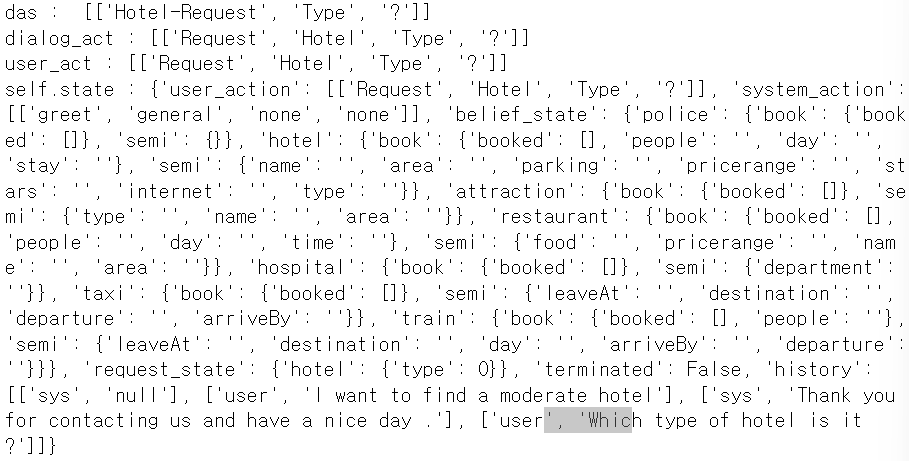
잘 보면 user_action에 잘 들어간게 보임. history를 보면 여태 한 대화 순서가 보임.
자 이번에는 user_action에 무언가 있으니까 [k-i, s,v] 요 형태로 바꿔줌
user_action : {'Hotel-Request': [['Type', '?']]}
DA : {'Hotel-Inform': [['Type','guesthouse']]}
따라서 domain은 hotel, intent눈 inform, svs는 [[’Type’,’guesthouse’]]
요걸 tuple로 해서 system_action에 넣어줌

