NLU
-
다른 agent의 intent를 parse
-
utterance를 input으로 corresponding dialogue acts를 outputs로
모델은 3개 : semantic tuple classifier, MILU, BERTNLU
BERTNLU는 intent 분류와 슬롯 태깅을 위해 mlp 2개를 상단에 배치, fine tuning은 각각 특정 task에 대해서 개별적으로.
predict가 가장 중요함.
input : utterance(str) context(list of str)
output : dialog act ⇒ 형식은 데이터 셋에 의존함. (ex: MultiWOZ라면 [["Inform", "Restaurant", "Food", "brazilian"], ["Inform", "Restaurant", "Area","north"]]
이렇게 나옴)
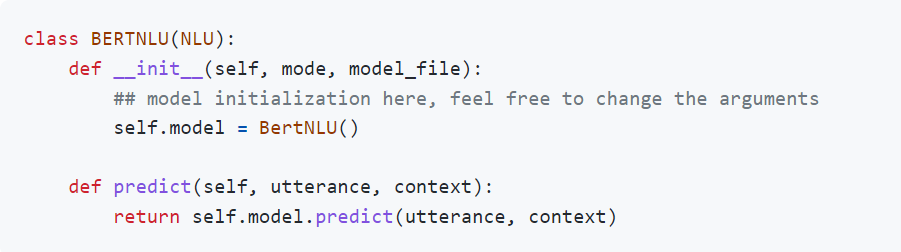
새 모델을 추가하려면 NLU를 inherit 해야함
DST
-
belief state를 업뎃. belief state는 다른 agent에 대한 constraint&requirement를 포함
-
dialogue acts parsed by NLU를 인풋으로. rule-based tracker
Word-level DST : dialogue 기록에서 belief state를 바로 얻음
MDBT, SUMBT, TRADE
DP
- belief state를 인풋으로, dialogue acts를 outputs로.
rule-based policy인데 simple neural policy임(imitation learning, reinforcement learning으로 corpus에서 바로 학습함)
NLG
- dialogue act를 natural language sentence로.
templete based, SC-LSTM
Word-level Policy : dialogue history와 belief state에서 natural language response 바로 생성
MDRG, HDSA, LaRL
User policy : 유저 시뮬레이터의 핵심. pre-set 유저 목표와 system dialogue act를 인풋으로, user dialogue act를 아웃으로.
agenda-based, neural based
end-to-end할때 NLU와 NLG에 user policy를 장착함
ent-to-end : dialogue history를 인풋, response in natural language를 아웃풋
Sequicity : 멀티 도메인 시나리오. 모델이 도메인이 바뀐걸 인식하면 belief span(현재 도메인의 정보를 기록하는)을 리셋함.
데이터 셋 : camrest, multiWOZ , dealornodeal,

