NeurlPS 2020 - Deeper conversational AI
Part 1 : Conversational AI Overview
conversational system의 기능
- task oriented dialogues
- information consumption(정보 소비)
- task completion(임무 수행)
- decision support(open edded, none specific answer)
- social chit-chat
- turing test(just chat, no goals)
Modularized Task-Oriented Dialogue Systems
- help acheive pre-defined goals/tasks with least turns
- dealing with(다루다) APIs/databases
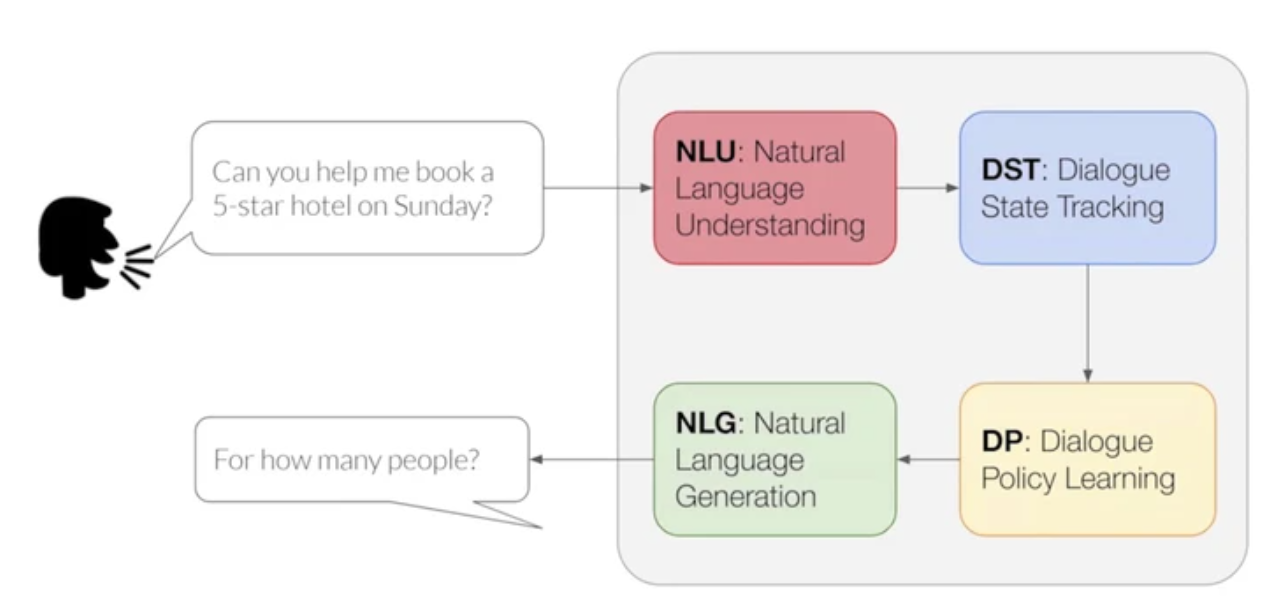
user 음성 → NLU → DST → DP → NLG → (기계)음성
1. NLU(Natural Language Understanding)
try to map the utterance(말) into semantic frames(의미론적) = turn level task
input : user utterance (ex: For two people, thanks!)
output : semantic information
constraint : number of people is equal to two
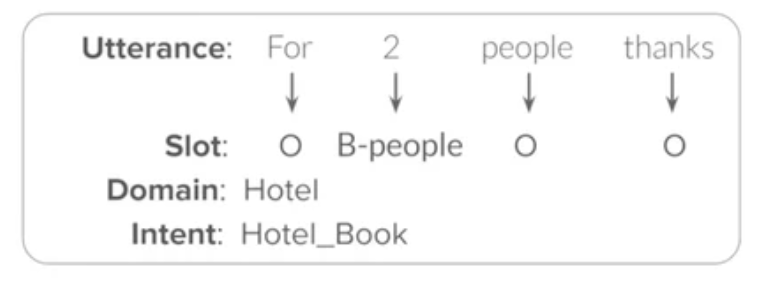
- domain/intent detection ⇒ classification task
- classify sentence into specific domain or intent
- cnn, lstm, attention model - slot tagging ⇒ sequence labelling(IOB)
- extract value(=slot value)
- IOB task, name entity recognition task
- cnn, lstm, rnnem, joint pointer - slot filling ⇒ compute the slot-F major as the evaluation metrics
- calculate the frame accuracy
trends&challenges
- Joint Intent / Slot Prediction
- Better Scalability
- Better Robustness
2. DST(Dialogue State Tracking)
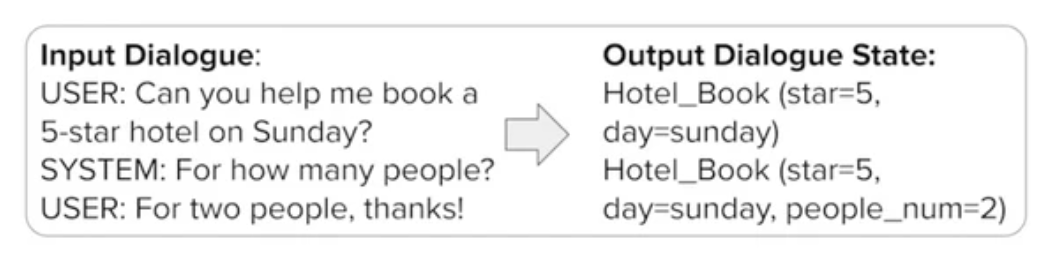
map partial dialogue into dialogue state
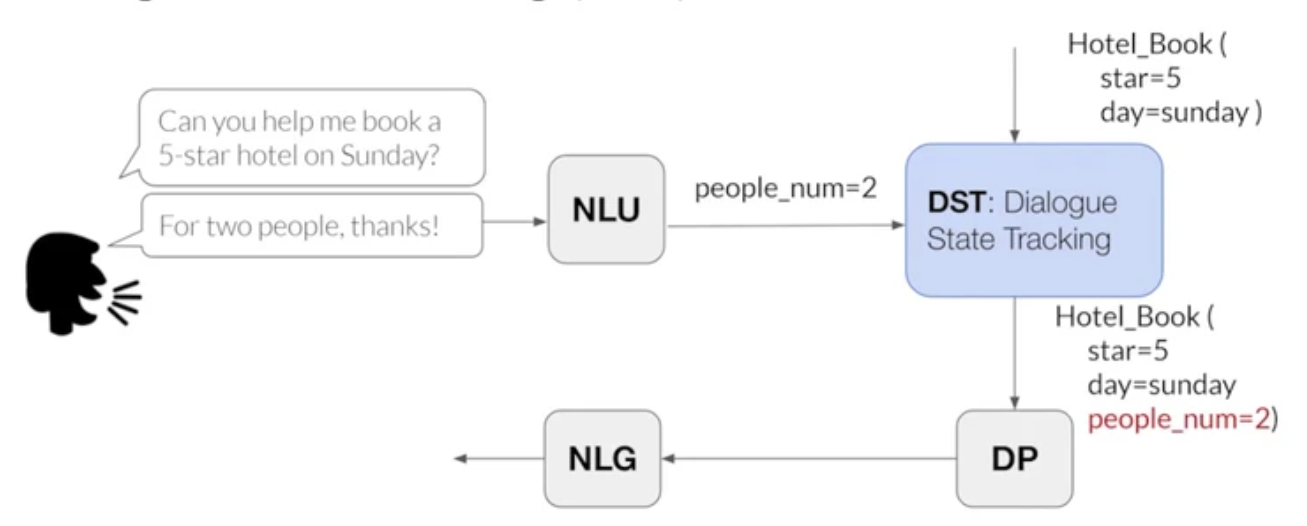
input : dialogue(turn with its previous states)
output : dialogue state
- Rule-based
expert-designed rules(state-update by adding slot values)
RNN based - Classification DST(one clasfficier per slot)
필요한 context마다 분류기를 걸어놓고 이 대화에 이 context가 포함되었나 아닌가, 값은 무엇인가 확인 ⇒ need ontology with predefined values = need to know how many labels will be needed
- cnn, lstm, context att, hierachical lstm, bert
compute slot accuracy for evaluation metrics
joint Acc
trends&challenges
since the limitation of classification, move foward to generation based approach
- Generation DST
generate state as a sequence or dialogue state updates
have to multiple foward - Scalability
- Multi-Domain(dataset : MultiWoz)
- Cross-Domain(dataset : SGD)
- Cross-Lingual - Other State Representations
- Graph
- Queries
- data-flow
3. DP(Dialogue Policy(action) Learning)
design a system action for interacting with people’s based on dialogue states
input : dialogue state + KB results
output : system action

- Supervised Learning
learn (dialogue state, assistant action) from collected corpus - Reinforcement Learning : learn from interaction with the user(simulator) ⇒ task success rate / dialogue length (클수록 큰 보상)
trends&challenges
- RL for DP
- User Simulator
Agenda-based, reward shaping - Learning dialogue policy using few well-annotated dialogues
4. NLG(Natural Language Generation)
generate corresponding sentence and get back to user
input : system speech-act + slot-value(option)
output : natural language response

- Template-Based
- Generation-Based
- SC-LSTM
- Seq2Seq
- Structural NLG
- Hierarchical Decoding
- NLG
- Hierarchical Decoding
- Controllable NLG
논점 : how can we evaluate?- calculate the slot error rate
- Hybrid : Template + Generation
- Rewriting Simple Templates
trends&challenges
- Scalability
- Few-shot domain learning for NLG
- Unsupervised NLG
Retrieval-Based Chit-Chat Dialogue Systems
- free-form, open-domain
- engaging users for long conversation
- rare API, knowledge
Retrieval-based(검색 기반)
learn a scoring function between dialogue history&response candidate
- PolyEncoder(pretrained)
- Blended-Skill-Task
- Pros(response is from the pool of the response candidates→ safer response)
- fluent, correct
- poor scalability : no suitable candidate in new domain
⇒ solution : generation-based model
Generation-based(next chapter)
