Part 2 : Generation-Based Deep Conversational AI
Vanilla Seq2Seq ConvAI
- Choose the data : Human to human Conversations
- Choose the model : Large pre-trained
- Train the model with data : Supervised learning
- Evaluate : Automatic or Human Evaluation
two generative models for vanilla seq2seq system
- Vanilla Seq2Seqq conversational model(encoder-decoder)
- Causal Decoder
Maximum Likelihood Estimation(MLE) : 가장 데이터를 잘 설명하는 분포를 likelihood를 통해 구함. output은 probability distribution over the vocab
Greedy Decoding
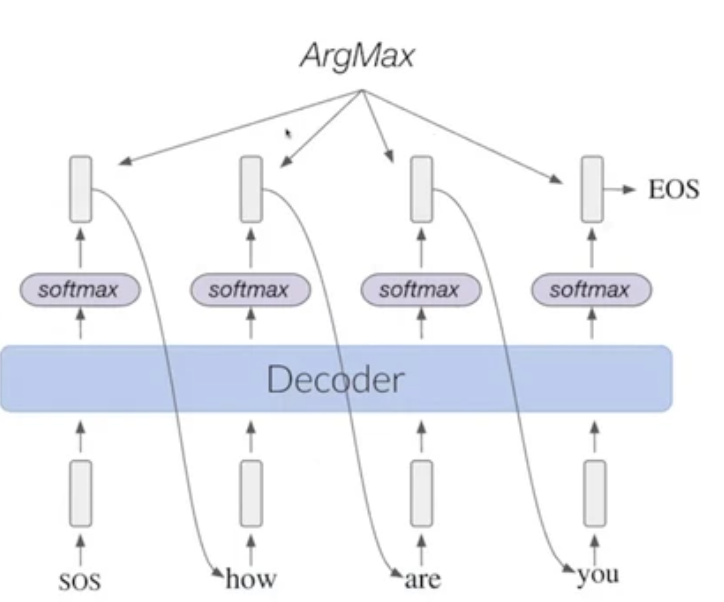
- start with token SOS
- generate distribution over the vocabulary
- choose the token with maximum probability(greedy step)
- output is the token, repeat again as the input
- end when model generate EOS token
Automatic Evaluation
- Perplexity : 가능한 경우의 수를 의미하는 분기계수(branching factor)
- N-gram overlapping ⇒ BLEU
- Distinct N-grams ⇒ response diversity
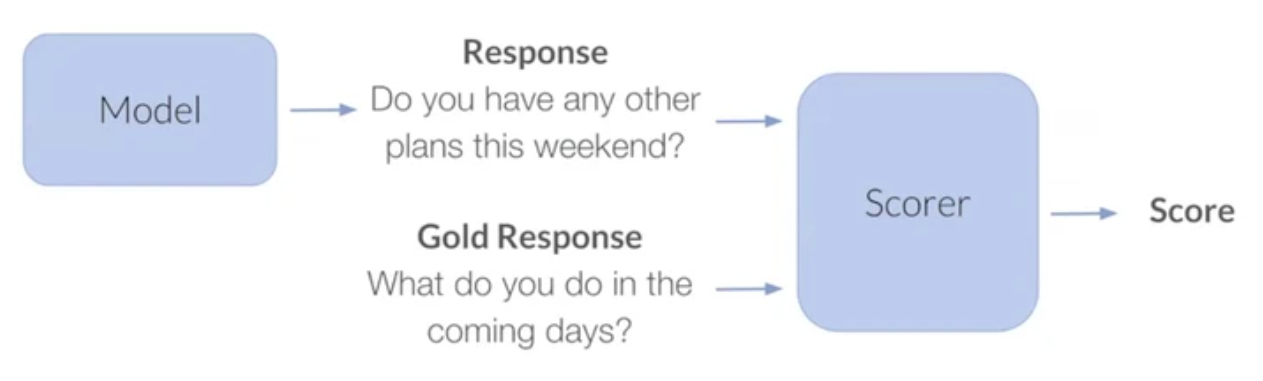
그러나 test data에서 정확도가 높다는 것이지, 사람의 평가도 필요함
Human Evaluation
Likert(리커트 척도)
- judge가 Humanness, Fluency, Coherence 세가지에 대해서 0-5까지 평가함
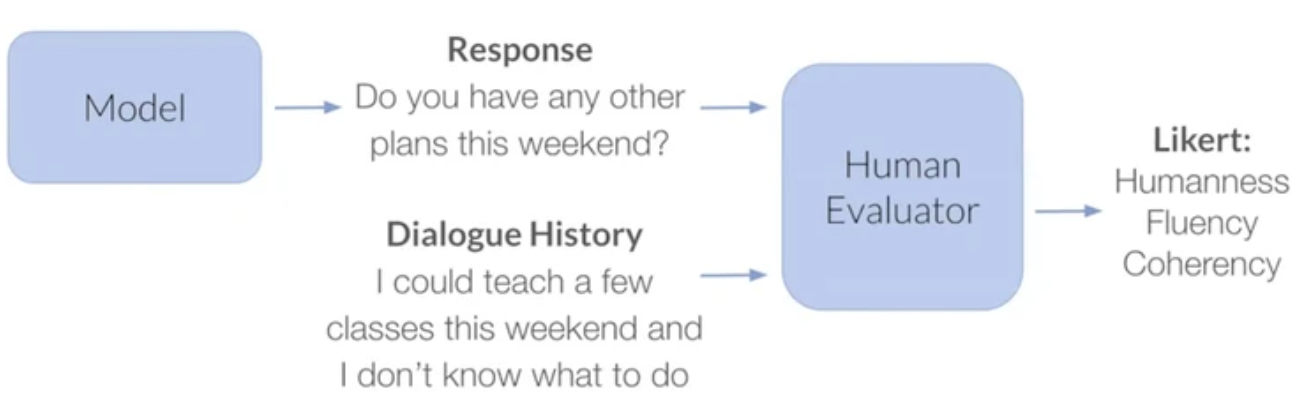
Dynamic Likert
- judge가 모델과 interact하고, judge가 평가
A/B
- 모델 2개(하나는 human일수도 있음)의 response를 비교해서 평가
Dyamic A/B
- interaction을 보여줌
Limitations in Vanilla ConvAI
- Lack of Diversity
local minimum에 빠져서 high frequency response만 제공함
to week Parameterization(매개변수화 : 하나의 표현식에 대해 다른 parameter를 사용해 다시 표현하는 과정)
not enough capacity to capture one-many relation - Lack of consistency
train data의 다른 speaker들이 다른 성격, 특징,선호드를 가짐
encode attributes information 기능이 없으므로 계속 다른 speaker들의 불일치한 반응을 생성해냄 - Lack of knowledge
outside(external) knowledge가 필요함
cannot carry out engaging conversation - Lack of Empathy
human emotion - Lack of Controllability
need mechanism to control dialogue output for- Response style
- topics
- engagement
- toxic and inappropriate responses
- Lack of versatility(다재다능)
task oriented system needs modules(NLU-DST-DP-NLG) + access external KB ⇒ challenging
Deeper ConvAI Solutions
-
Lack of diversity ⇒ Diversify Responses
a. training, decoding 전략 : Maximum Mutual Information
b. model 구조 : conditional variational autoencoder
c. more data, large model : large scale pre-training
d. decoding 전략 : top-k sampling, Nucleus Samplingvanilla seq2seq 문제점 : small conversational corpus, overfit easily, generate repetitive response, not grammatical
해결 : use pre-trained model(2가지 있음)- Large scale pretraining
ex) BART T5 (random mask), meena blenderbot(large conversational data) GPT(initialization for casual decoder, autoregressive)
- Nucleus sampling
- beam search, greedy search decoding은 반복적 대화를 생성해냄
- top-N ranking words에서 sampling함
- Large scale pretraining
-
Lack of consistency
a. learning speaker embedding : speaker attributes feature vector
b. conditioning on persona descriptions둘 다 특정 dataset이 필요함 : human-to-human conversations + persona features
- Personalization via TransferTransfo
- GPT로 fine-tuning
- (persona + histroy + reply)가 한 sequence
- dialogue history + persona description이 주어지면 주어진 persona가 반영된 response를 줌
- Personalization via Speaker Model
- spaeker embedding을 주고 persona 정보를 encode함
- Personalization via TransferTransfo
-
Lack of knowledge
a. Textual- IR Systems : TF_IDF , BM25
- Neural Retriever : DPR
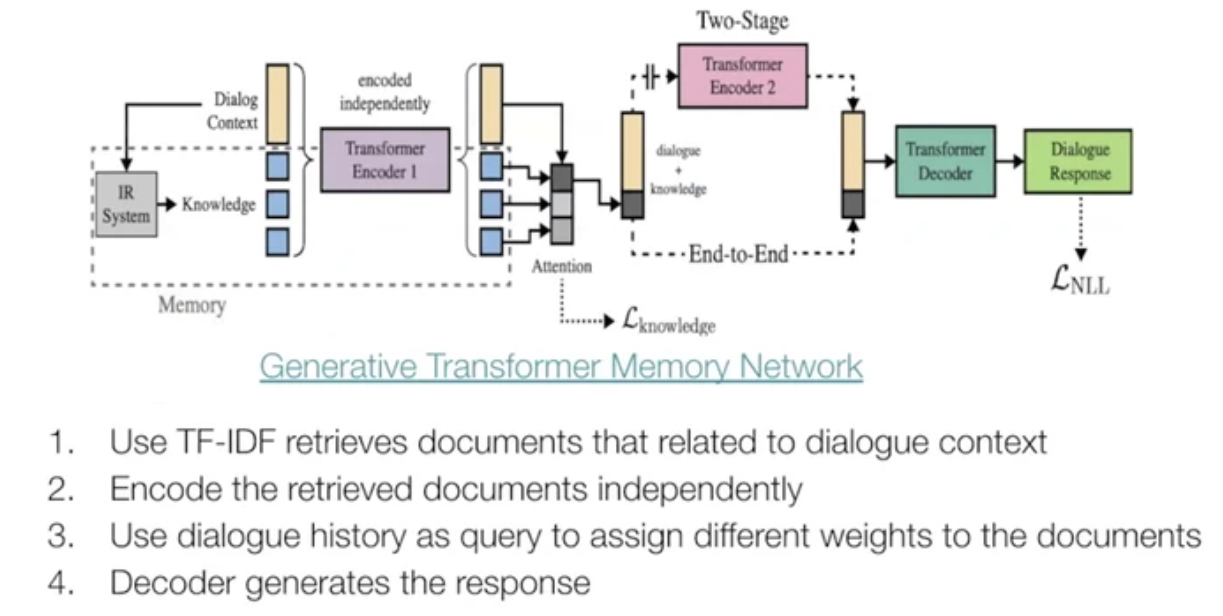
b. Graph
dialogue history → knowledge graph → subgraph → encoder → decoder → response
1 hop reasoning : all knowledge in dialogue
multi hop reasoning : neural retrieverc. Tabular
convert tabular knowledge into triples(?) tribles?
KVR, Mem2Seq, Neural Assistantd. Service API interaction
user request를 처리하기 위해 API가 필요할 수도 있음
response와 API call 두개를 다 generate해야함
-
Lack of empathy
a. emotional response generation
- MojiTalk
- Emotional Chatting Machine
b. Understand user’s emtion + response generation
- Empathetic Dialogues
- MoEL
- Cairebot -
Lack of controllability
a. low-level attribute ⇒ Conditional Training+Weight Decoding
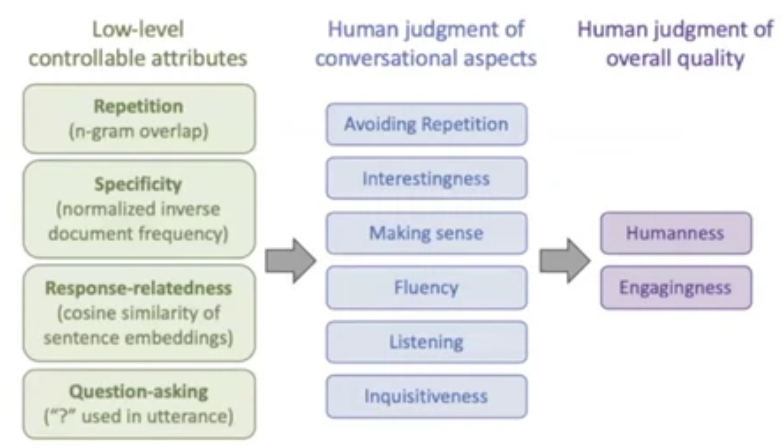
conditional training + weight decodingb. fine-tuning ⇒ arXivstyle and Holmes-style
fine-tune with special loss function on word/sentence level
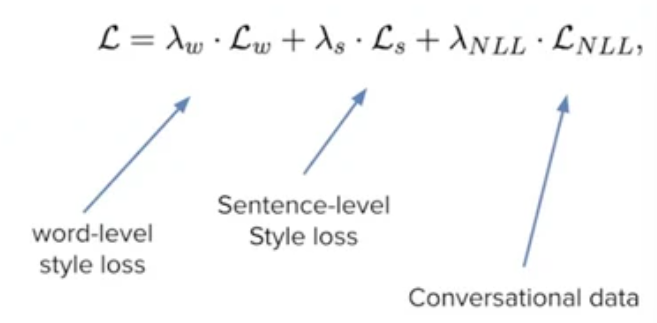
inject the target style into modelc. perturbation ⇒ PPLM(Plug and Play Conversational Models) + Residual Adapters
control the style and topic of the responses
d. conditioned generation ⇒ Retrieve&Redefine + PPLM + CTRL -
Lack of versatility(+task or more)
ToDs + Chit-Chat
task oriented나 chit-chat 외에도, (구조를 보면 다들 비슷비슷하다 따라서 유사하게) output은 input에 따라 무궁무진하게 바뀐다- Attention over Parameters
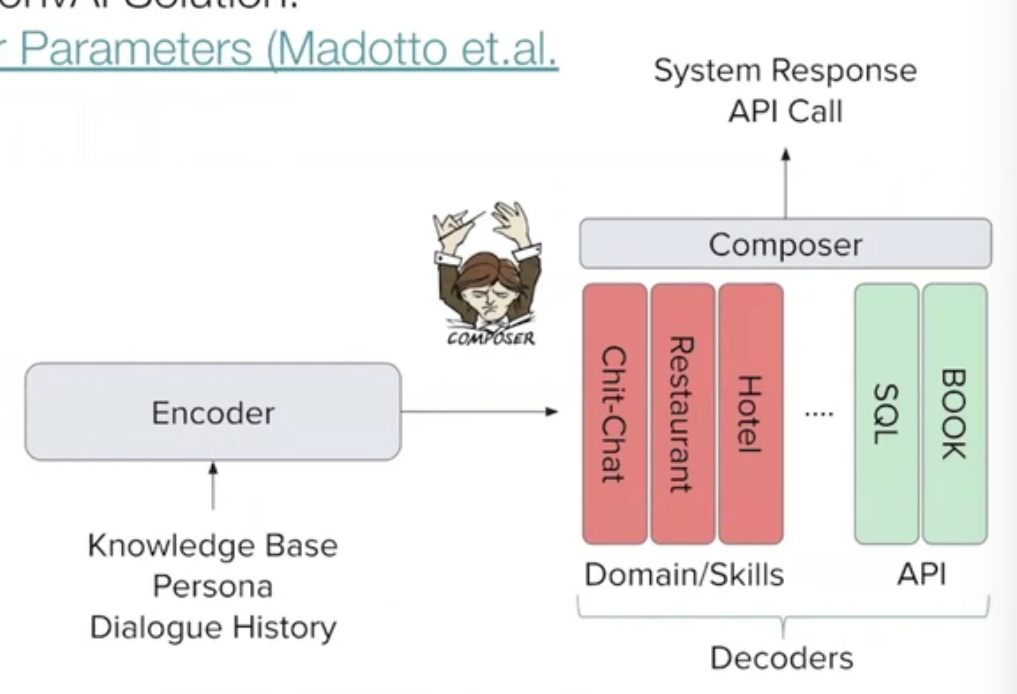
예를 들어 호텔 예약 관련 발화라면 hotel + book을 합쳐서~(mixing multiple decoder) - Adapter-Bot
use fixed backbone(DialGPT) + encode each dialogue skill with independently trained adapters + BERT(skill manager) is trained to select each adapter based on history - Blender-bot
- Attention over Parameters
