ICON: Implicit Clothed humans Obtained from Normals
0. Abstract
2D 이미지에서만 아바타를 학습하는 것이 목표다. implicit functions는 머리카락과 옷같은 세부 사항을 포착할 수 있으나 현재 방법은 다양한 포즈에 적합하지 않으며 팔다리가 부러지거나 분리된 3D surface, 누락된 세부 정보, 인간이 아닌 shape을 생성한다. 이 방법들의 문제는 global pose에 민감한 global feature encoder를 사용한다는 것이다.
이를 위해 local feature를 사용하는 ICON(implicit clothed humans obtained from normals)를 제안한다. ICON은 SMPL(-X) body model을 사용하는 두 메인 모듈이 있다.
-
ICON infers detailed clothed-human normals (front/back) conditioned on the SMPL(-X) normals.
cloth-human normals"는 명시적인 의류 모델링 없이 옷을 입은 인체의 표면 방향을 나타내는 노멀 벡터를 말한다.
ICON 모델이 clothed-human normals을 추론할 때 SMPL(-X) normals을 조건으로 설정하면 ICON 모델은 SMPL 모델이 제공하는 정보를 활용하여 결과의 정확성과 일관성을 개선할 수 있다.
-
a visibility-aware implicit surface regressor produces aniso-surface of a human occupancy field
가시성 정보(visibility)를 고려하여 암시적 함수 기반 기술을 사용하여 인간의 점유 필드(occupancy field)를 나타내는 3D 공간상의 이방성(aniso-surface) 표면을 생성하는 것을 의미한다.
중요한 것은 추론하는 동안 피드백 루프가 SMPL(-X) 메쉬를 옷의 노멀 벡터 정보를 이용하여 수정한 후, 수정된 메쉬를 이용하여 노멀 벡터를 더욱 정교화하는 과정을 교대로 반복하는 것이다. 또한 한 사람이 여러 자세로 촬영한 여러 프레임으로 SCANimate의 수정 버전을 사용해 애니메이션이 가능한 아바타를 만든다.
1. Introduction
parametric body model을 넘어 fine shape detail과 다양한 topology를 나타내는 implicit functions(IFs)에 기반을 둔다. IF는 이미지에서 디테일한 shape 추론을 가능케 한다. 그러나 SOTA 방법들도 in-the-wild 데이터에서 어려움을 겪고 broken/disembodied limbs, missing details, high-frequency noise, non-human shape 등을 생성한다.
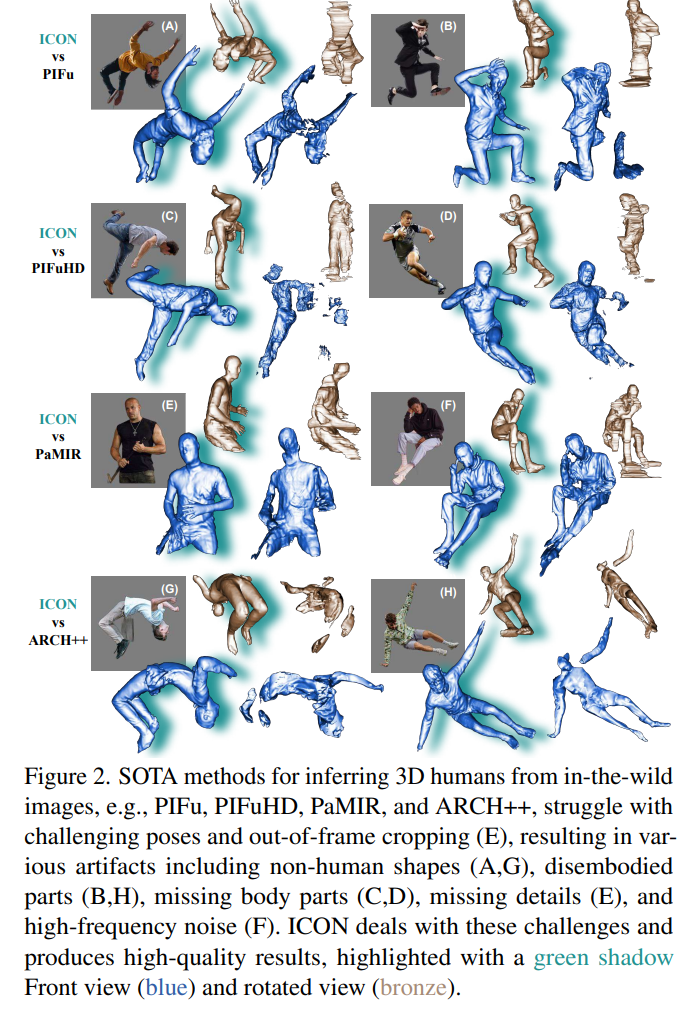
이전 방법의 문제는 두 가지이다.
- 일반적으로 pose, shape 의상 변형이 제한된 소규모의 3D 인간 데이터 셋에서 훈련된다
- 일반적으로 implicit-function 모듈에 global 2D image나 3D voxel encoder의 feautures를 입력하지만 이들은 global pose에 민감하다. 더 많은 3D 학습 데이터가 도움이 되겠지만 이러한 데이터는 한정적이다.
ICON은 기존의 global encoder을 더 효율적인 local scheme로 대체한다.
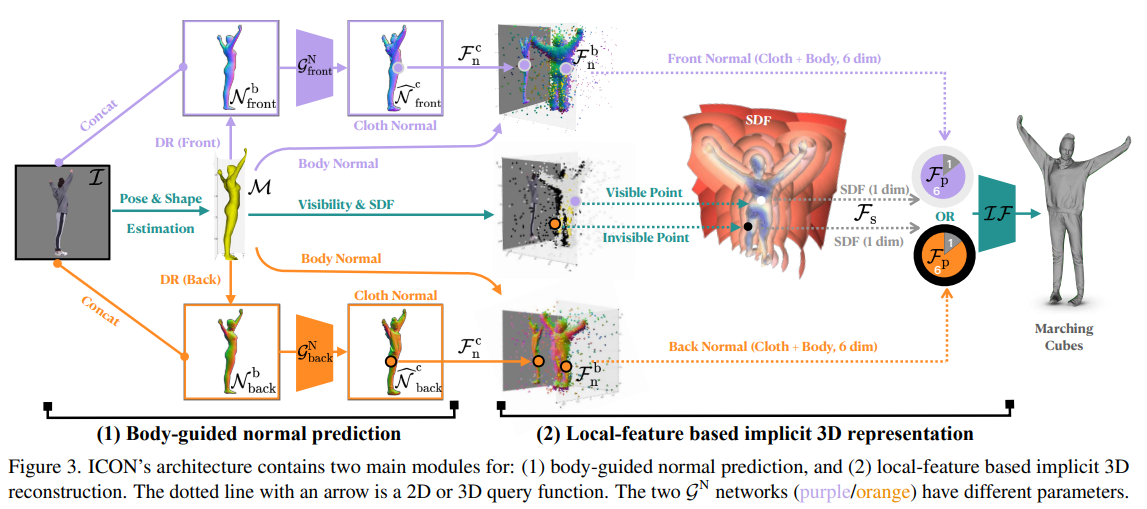
ICON은 옷을 입고있는 사람의 segmented된 RGB 이미지와 이미지에서 추정한 SMPL body를 인풋으로 받는다. SMPL body는 ICON의 두 모듈을 안내하는데 사용된다.
- detailed clothed-human surface normals(front/back views)를 추론
- visibility-aware implicit surface(iso-surface of an occupancy field)를 추론
초기의 SMPL 추론에서의 오류는 이후의 추론을 잘못 이끌 수 있다. 따라서, 추론할 때 반복적인 feedback loop가 SMPL(3D shape, pose, translation)을 개선하고 그 반대로 더 나은 3D 디테일의 implicit shape을 개선한다.
ICON을 challenging한 데이터 셋인 AGORA와 CAPE으로 양적, 질적으로 평가한다. 결과적으로 ICON은 두 가지 이점을 갖고 있다.
- Generalization
ICON은 in-the-wild와 out-of-distributed poses/clothes 이미지에서 더 좋은 성능을 보인다. ICON은 full-body 이미지로만 학습되지만 finetuning이나 post processing 없이 out-of-frame cropping 이미지도 다룰 수 있다. - Data efficacy
ICON의 지역성은 pose와 surface 사이의 잘못된 상관관계를 방지할 수 있다. 따라서 적은 데이터로도 학습이 가능하다.
3. Method
구체적으로 ICON은 segmented된 clothed human의 RGB 이미지와(PIFuHD의 제안) ‘under clothing’ human body shpae(SMPL)을 추정하여 인풋으로 받고, pixel-aligned 3D shape reconstruction을 아웃풋으로 낸다. ICON은 두개의 주요 모듈이 있다.
- SMPL-guided clothed-body normal prediction
이 모듈은 이미지 상의 segment된 옷 입힌 사람과 SMPL 모델을 입력으로 받는다. 이를 기반으로 인간 몸의 표면 법선 벡터(normal vector)를 예측한다. SMPL은 인간 몸의 통계적 모델이며, 입력된 SMPL 모델은 인간 몸의 전체 구조를 추정하기 위해 사용된다. 예측된 표면 법선 벡터는 implicit surface reconstruction 모듈에서 3D 메쉬를 생성하는 데 사용된다. - local-feature based implicit surface reconstruction
이 모듈은 예측된 표면 법선 벡터를 기반으로 입력된 이미지에서 local body feature를 추출한다. 추출된 local feature는 implicit function에 공급되어 3D 메쉬를 생성하는 데 사용된다. 이 모듈은 이미지에서 예측된 local body feature와 함께 implicit function을 사용하여 3D 표면을 생성하는 방법을 학습한다.
a. Body-guided normal prediction
model-free 방법과 다르게 ICON은 SMPL ‘body-under-clothing’ mesh를 고려하여 모호성을 줄이고 clothed-body의 앞면과 뒷면의 normal 예측을 가이드한다.
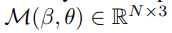
이미지 I에서 SMPL mesh인 M을 추정하기 위해서 PyMAF를 사용한다.
PyMAF는 3D 메쉬와 2D 이미지 간의 정렬(alignment)을 수행한다. 즉 인간의 신체 구조를 모델링하는 데 사용되는 SMPL 메쉬와 같은 3D 메쉬가 이미지에서 관측되는 실제 사람의 영상과 정렬(alligned)되어야 함을 의미한다.
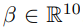
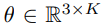
SMPL은 shape인 B와 pose인 θ로 매개변수화된다. 이때 N은 6,890 vertices며 K는 24개의 joint이다.
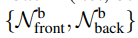
scale이 s, translation이 t인 weak-perspective 카메라 모델에서, PyTorch3D differentiable renderer(DR)를 사용하여 SMPL mesh인 M을 두 반대의 뷰에서 렌더하여 ‘front = observable side’와 ‘back = occluded side)’ SMPL-body normal maps인 Nb를 얻는다.
SMPL-body normal maps는 SMPL 모델에서 생성된 3D 인체 모델의 표면에 대한 법선 벡터의 분포를 나타내는 2D 맵이다
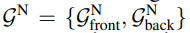
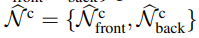
Nb와 원본 칼라 이미지인 I가 주어지면 normal network인 Gn이 clothed body normal maps인 Nc를 예측한다.
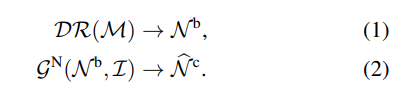
Clothed-body normal maps는 옷을 입은 인체 표면의 법선 벡터 정보가 포함된 2D 이미지를 의미한다. 일반적으로 옷을 입은 경우 인체 표면의 형태와 움직임이 옷으로 인해 가려지기 때문에, 옷의 형태와 자세를 고려하지 않고 인체 표면의 법선 벡터를 추정하는 것은 매우 어려운 문제이다. ICON은 이러한 문제를 해결하기 위해 SMPL "body-under-clothing" mesh와 같은 정보를 사용하여 뒤쪽을 가려지는 인체 표면의 법선 벡터를 추정한다.
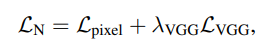
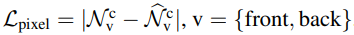
Lpixel은 GT와 예측된 normal사이의 loss(L1)이고 Lvgg는 λvgg로 가중치를 둔 perceptual loss이다. Lpixel만으로는 추론된 normal은 매우 흐릿하지만 Lvgg를 추가하면 디테일을 복구하는데 도움이 된다.
Lpixel은 예측된 법선과 실제 법선 사이의 L1 거리이다.
ICON에서 VGG는 perceptual loss를 계산하는데 사용된다. 구체적으로, VGG의 특징 추출 능력을 이용하여 예측된 법선 맵과 실제 법선 맵 사이의 차이를 계산한다.
λVGG는 VGG 손실을 가중치로 사용한 것이다. 두 이미지 간의 차이를 계산하는 데 사용되는 것으로, 이미지의 특징을 보존하는여 예측된 이미지가 실제 이미지와 유사하도록 한다.
LN은 예측된 법선과 실제 법선 간의 거리 측정에 가중치를 두어, 가능한 한 실제 법선에 가깝게 예측되도록 한다.
Refining SMPL
human pose와 shape(HPS) regressors는 pixel-aligned SMPL fit을 주지 않는다. 따라서 SMPL fit은 렌더링 된 SMPL-body normal maps인 Nb와 예측된 clothed-body normal maps Nc 사이의 차이를 바탕으로 최적화된다.

구체적으로 SMPL의 shape인 β, pose인 θ, translation인 t 파라미터를 다음을 최소화하도록 최적화한다.
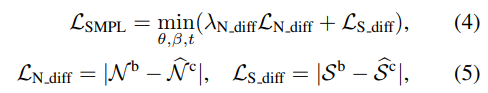
Ln_diff는 λn_diff에 의해 가중치가 적용된 normal-map los(L1)이고 Ls_diff는 SMPL body normal map(Nb)의 실루엣인 Sb와 이미지 I에서 segmented된 human mask S^c 사이의 loss(L1)이다.
Refining normals
efined된 SMPL mesh에서 렌더링된 normal maps(Nb)는 Gn 네트워크에 넣어진다. 개선된 SMPL-mesh-to-image alignment는 Gn이 더 신뢰할만하고 디테일한 normal인 N^c를 추론하도록 안내한다.
Refinement loop
추론하는 동안 ICON은 아래 두가지 작업을 번갈아 수행한다.
- 추론된 N^c normals를 사용하여 SMPL mesh를 개선
- 개선된 SMPL로 N^c를 재개선
이 피드백 루프는 앞/뒤 양쪽에서 더 신뢰할만한 clothed-body normal map으로 이끈다
Local-feature based implicit 3D reconstruction
b. Local-feature based implicit 3D reconstruction
예측된 clothed-body normal map인 N^c와 SMPL-body mesh인 M이 주어졌을 때, 우리는 local feature Fp에 기반해서 clothed human의 implicit 3D surface를 회귀한다
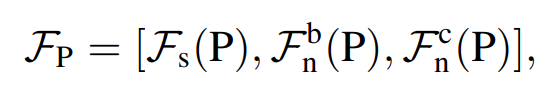
Fs는 query point P에서 가장 가까운 body point Pb까지의 signed distance이며 Fbn은 Pb의 barycentric surface normal이다.
주어진 clothed human의 3D mesh를 사용하여, 주어진 포인트 P에 대해 해당 포인트가 clothed human의 표면 내부에 있는지 아닌지를 예측하는 함수를 학습한다는 의미이다.
Barycentric surface normal은 3D 메시 상의 각 삼각형의 평면 법선 벡터를 나타내는 벡터이다. 이 벡터는 삼각형 내부의 모든 점에서 동일하기에 메시 상의 모든 점에서의 법선 벡터를 추정할 수 있다. 이것은 해당 점이 메시의 다른 부분에 가려져 있을 때도 동작한다.
따라서 self-occlusion에 대한 강한 정규화를 제공한다.
Fs는 쿼리 포인트 P와 가장 가까운 몸체 포인트 Pb까지의 부호화 된 거리를 나타내는데, 이 거리를 통해 쿼리 포인트 P가 몸체 내부에 위치하는지 외부에 위치하는지를 결정한다. 만약 P가 몸체 내부에 위치한다면 거리 Fs는 음수가 된다. 이를 이용하여 몸체 내부에 있는 점들은 occlusion-free 함을 보장할 수 있다. 따라서, Fs는 self-occlusion에 대한 강한 정규화를 제공한다.
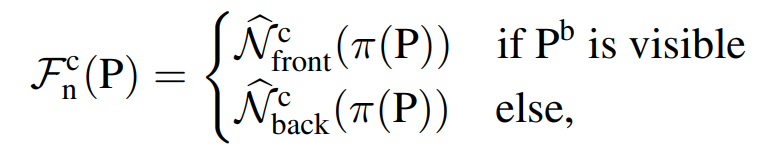
Fcn(P)은 Pb의 가시성에 따라 N^c front나 N^c back에서 추출한 normal vector이다. 이때 π(P)는 3D point P의 2D 투영을 의미한다.
Fp는 global body pose와 독립적이다. 이것이 out-of-distribution pose에 대한 견고성과 훈련 데이터에 대한 효율성의 키이다.
Fp는 local feature로, 쿼리 포인트 P의 주변 정보에 대한 특징을 담고 있다. 이에 비해 global body pose는 전체 몸의 자세를 묘사하는 정보로, Fp에는 포함되지 않는다.
Fp를 implicit function IF에 넣어서 MLP를 통해 매개변수화하여 point P에서의 occupancy를 추정한다. 이를 o^(P)라고 한다. IF를 GT occupancy인 o(P)로 학습시킬 때, MSE loss가 사용된다. 이후, fast surface localization algorithm을 통해 IF에 의해 추론된 3D occupancy로부터 mesh를 추출한다.
4. Experiments
a. Baseline models
ICON을 PIFu와 PaMIR와 중점적으로 비교한다. 각 요인들을 고립시키고 평가하기 위해 PIFu와 PaMIR를 ICON의 구조를 기반으로 ‘simulating’하여 재실행한다. ‘simulated’ 된 모델은 *을 붙여 표현한다.
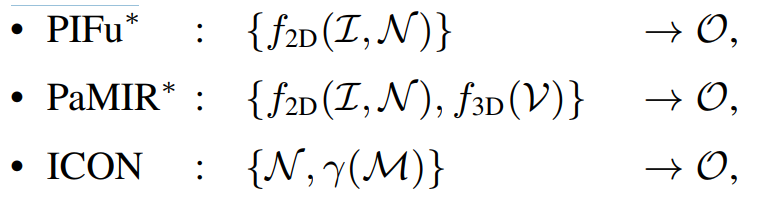
PIFu는 깊이 이미지를 입력으로 사용하여, 깊이 이미지를 통해 옷입은 인간의 3D 모델을 생성하는 기술이다. PIFu는 암시적 함수 방법론을 사용하여 이미지를 3D 모델로 변환하는 것이 특징이다.
PIFu는 적은 양의 데이터로도 높은 해상도의 인간 형상을 생성할 수 있으나 의류와 같은 세부적인 부분을 생성하는 데 어려움이 있으며, 빛이나 그림자와 같은 다양한 조건에 대한 적응성이 떨어진다.
PaMIR는 입력 이미지와 이미지에 대한 부가 정보를 통해 인간 모델을 생성한다. 이 모델은 복잡한 인체 형상을 표현하는 매개 변수화된 3D 모델과 인간의 피부 표면을 나타내는 암시적 함수로 구성된다. PaMIR는 매개 변수 모델을 사용하여 다양한 복잡한 인체 형상을 생성할 수 있으며, 피부 표면에 대한 정확한 표현력을 가지고 있다.
의류와 같은 세부적인 부분을 생성하는 데 탁월한 성능을 보이며, 다양한 조건에 대한 적응성이 뛰어나고 자세와 같은 조건을 고려할 수 있으나 많은 데이터가 필요하며 3D mesh 생성에는 적합하지 않다.
b. Datasets
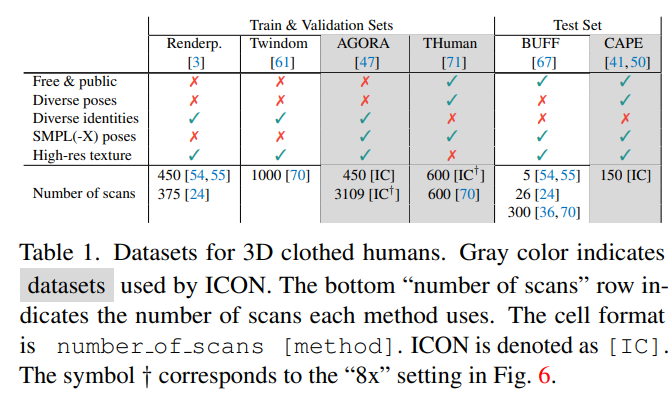
다양한 3D clothed-human 데이터 셋이 논문에서 사용되었으며 각 방법마다 다른 하위 집합과 조합을 사용한다
Trainig data
모든 베이스라인 모델을 AGORA의 하위 집합인 450 Renderedpeople scans로 재학습한다. 3D body prior를 요구하는 모델인 PaMIR와 ICON은 AGORA에서 제공되는 SMPL-X mesh를 사용한다.
Testing data
일반화 능력을 평가하기 위해 학습에 사용되지 않은 데이터 셋인 CAPE로 평가한다. 구체적으로, 복잡한 포즈에도 잘 일반화 되는지를 쉽게 분석하기 위해 CAPE 데이터를 ‘fashion’과 ‘non-fashion’ 포즈 여부에 따라 각각 CAPE-FP와 CAPE-NPE로 나눴다. train과 test 데이터의 domain gap 없이 성능을 평가하기 위해서 또한 모든 모델들을 AGORA-50으로 테스트했는데, 이는 AGORA에서 학습에 사용한 450과 다른 50개의 샘플을 포함한다.
Generating synthetic data
MonoPort의 OpenGL script를 사용하여 동적 조명과 함께 ‘사실적인’ 사진을 랜더링한다. Clothed-human 3D scan(I and Nc)과 그들의 SMPL-X fit(Nb)를 weak perspective 카메라를 사용하고 그 카메라 앞에서 스캔을 회전시켜서 멀티뷰로 랜더링한다. 이 방법으로 각각 3D clothed-human scan과 그것의 SMPL-X fit, RGB image, camera parameter, scan과 SMPL-X mesh의 2D normal map(두 반대 방향) 그리고 SMPL_X triangle visibility information을 포함하는 138,924 샘플을 생성하였다.
SMPL-X fits는 SMPL-X 모델을 사용하여 각각의 3D 스캔 데이터에 적합한 3D 인간 모델을 생성하는 것을 의미한다.
2D normal map은 2차원 이미지에서 각 픽셀의 법선 벡터 정보를 담고 있는 텍스처 맵이다. SMPL-X mesh의 2D normal map은 3D SMPL-X mesh의 각 삼각형 면에 대한 법선 벡터 정보를 매핑하여 생성된다. 이 정보는 광원 조명 모델링 및 쉐이딩을 적용하는 데 사용된다.
따라서 2D normal map은 3D 모델의 높은 해상도의 세부 정보를 2D 이미지로 투영한 것이라고 생각할 수 있다.
SMPL-X triangle visibility information은 3D mesh에서 각각의 삼각형이 카메라 시점에서 보이는지 여부를 나타내는 정보이다. 삼각형의 가시성 정보를 사용하면 3D 모델에서 렌더링되는 부분을 정확하게 결정할 수 있다.
c. Evaluation
3가지의 평가지표를 사용한다
Chamfer distance
GT scan과 구축된 mesh 사이의 Chamfer distance를 사용한다. 이를 위해서 scan/mesh에서 균등하게 points를 샘플링하여 해상도 차이를 제거하고 average bi-directional pont-to-surface distance를 계산한다. 이 평가지표는 큰 geometric 차이를 잡아내지만 디테일한 geometric 차이는 놓친다.
Chamfer distance는 주어진 두 개의 점 집합에서 각각 하나의 점을 선택하고, 이 두 점 사이의 거리를 계산한다. 그리고 이 거리가 가장 가까운 점 쌍 간의 거리인 경우 이 거리를 계산 결과로 선택하고, 다음으로 가까운 점 쌍 사이의 거리를 계산하는 것을 반복한다. 이렇게 계산된 모든 거리를 합산한 값을 최종 결과로 사용한다.
이는 점들 간의 연속성을 고려하지 않고 각 점들 간의 최단 거리를 계산하므로, 모델 간의 전체적인 유사도를 측정하는 데 유용하다.
"average bi-directional point-to-surface distances"는 각각의 샘플링된 점에서 가장 가까운 표면까지의 거리를 측정한 후, 그것을 모든 점에 대해 평균을 취한 값이다. 재구성된 모델과 원래 모델 사이의 대략적인 거리 차이를 나타낸다.
P2S distance
CAPE는 GT로써의 raw scan을 포함하는데 이는 큰 구멍을 포함할 수도 있다. 구멍을 제거하기 위해서 우리는 추가적으로 scan point에서 가장 가까운 구축된 surface point까지의 average point-to-surface(P2S) 거리를 구한다. 이는 위의 평가지표에서 1-directional 버전이라고 볼 수 있다.
Normals difference
구축된 surface와 GT surface의 normal image를 고정된 시점에서 렌더링하고(⇒ generating synthetic data) 이들 사이의 L2 error를 계산한다. 이는 Chamfer랑 P2S 에러가 작을 때 high-frequency geometric 디테일에 대한 에러를 잡아낸다.
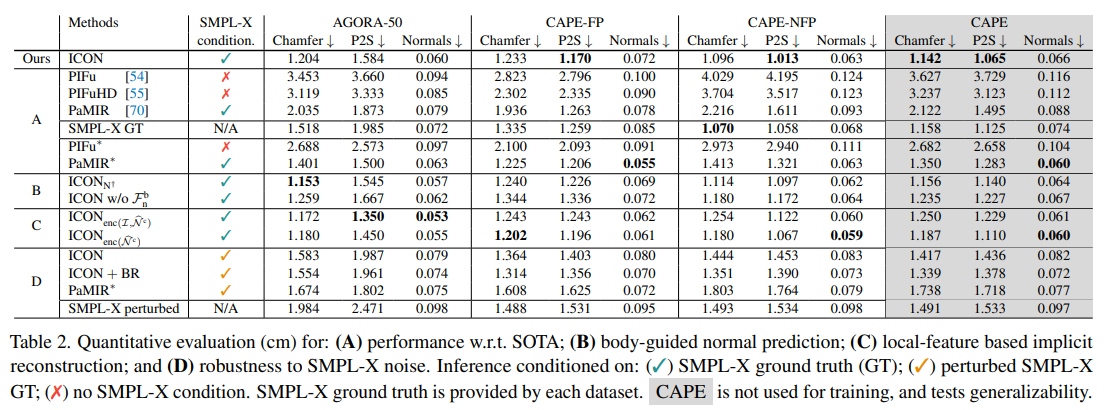
ICON -vs- SOTA
PaMIR*가 in-distribution body pose(AGORA-50, CAPE-FP) 이미지에서 SMPL-X GT보다 성능이 뛰어남을 알 수 있다. 그러나 out-of-distribution pose(CAPE-NFP)는 그렇지 않다. 이는 GT SMPL-X fit에 conditioned하더라도 PaMIR*는 global feature encoder 때문에 여전히 global body pose에 민감하며, out-of-distribution pose를 일반화하는데 실패한다는 것을 알 수 있다.
반면 ICON은 local feature가 global pose에 독립적이기 때문에 out-of-distribution pose에도 잘 일반화한다.
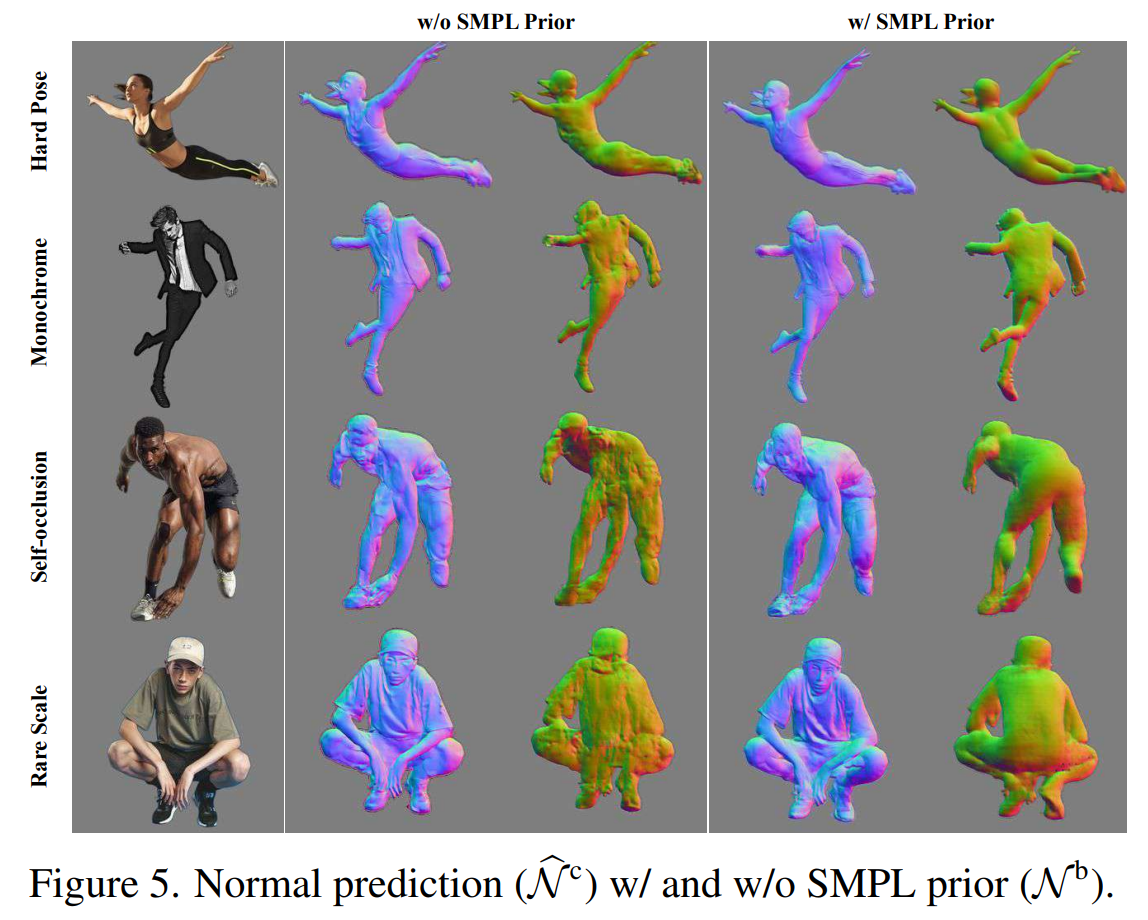
Body-guided normal prediction
ICON은 SMPL-X-body normal maps인 Nb를 통해서 clothed-body normal maps인 N^c를 추론하는데, 이때 이 조건부를 평가하고자 한다.
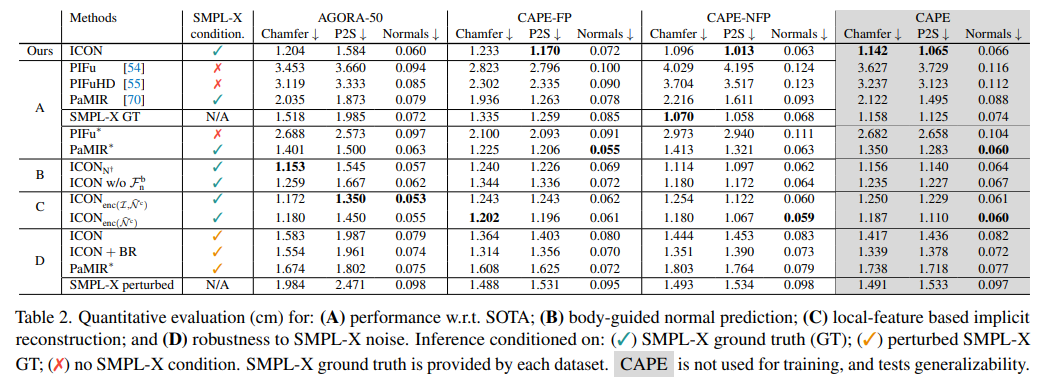
B가 conditioning을 사용했을 때인 ‘ICON’과 사용하지 않았을 떄의 ‘ICONn+’의 성능을 보여준다. conditioning이 없을 때, CAPE에서의 에러가 약간 증가한다. body normal에 대한 가이드는 추론된 normal을 강하게 개선시키는데 특히 occluded된 몸 부분에 대해서 그러하다.
또한 body-normal feature인 Fbn의 효과를 제거해보았는데 이는 결과를 더 악화시킨다. (’ICON w/o Fbn)
Local-feature based implicit reconstruction
‘local feature’ 즉 Fp의 중요성을 평가하기 위해서 Fp를 2D convolutional filter로 생산한 ‘global feature’로 대신했다.
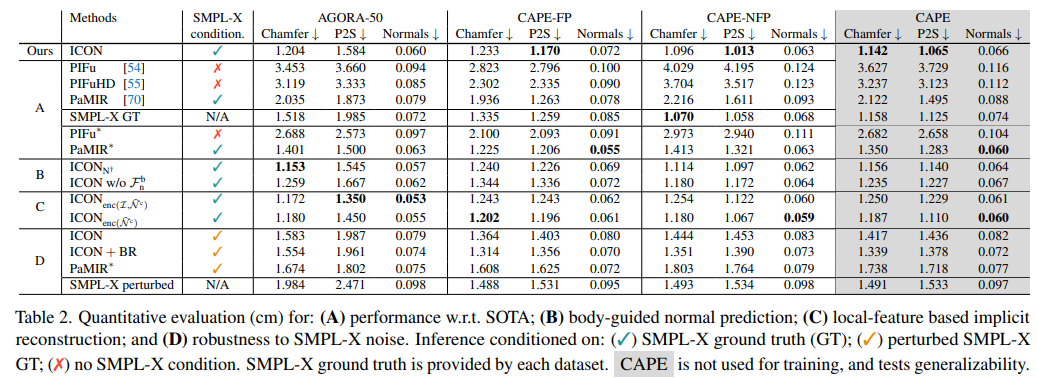
이미지와 clothed-body normal map(’ICON enc(I,N^c)’) 또는 normal maps(’ICON enc(N^c)’)에 적용되었는데 위의 C에서 확인할 수 있다.
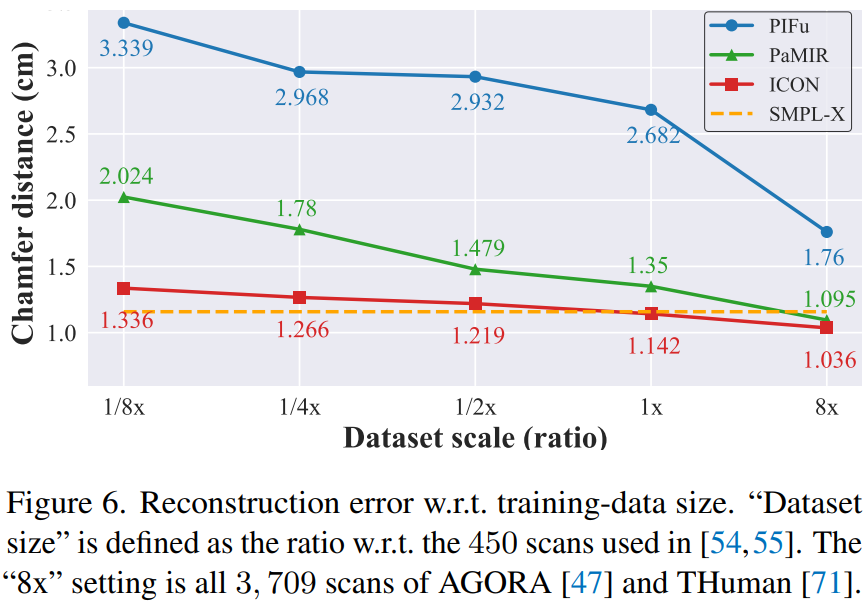
다양한 양의 훈련 데이터로 훈련시킨 SOTA 모델들과 ICON을 비교했다. ‘Dataset scale’축은 PIFu 방법의 450개 스캔을 기준으로 데이터 사이즈를 비율로 기록하였으며 가장 왼쪽은 56개의 스캔, 그리고 가장 오른쪽은 3,709개의 스캔에 해당한다. 모든 스캔은 AGORA와 THuman의 스캔이다. ICON은 모든 방법에 대해 일관적으로 성능이 뛰어나다. 중요한 것은 ICON은 단지 데이터의 일부분으로 학습했을 시에서 SOTA 성능을 보이고 있다. 우리는 이를 ICON의 point feauters의 local한 성질 덕분이라고 여긴다. 이는 ICON이 pose space에 잘 일반화되도록 하며 데이터 효율적이도록 돕는다
Robustness to SMPL-X noise
이미지에서 SMPL-X 추정은 이미지의 body pixel에 완벽하게 배치되지 않을 수 있다. 그러나 PaMIR와 ICON은 이 추정에 영향을 받는다. 따라서 SMPL-X의 shape과 pose의 다양한 노이즈에 견고해야한다.
이를 평가하기 위해 PaMIR*와 ICON에 GT SMPL-X (초록색 체크)와 perturbed 즉 노이즈가 추가된 SMPL-X(주황색 체크)를 넣었다.
ICON은 perturbed SMPL-X의 경우 GT SMPL-X에 비해 더 큰 오류를 생성한다. 그러나 body refinement 모듈 (ICON+BR)을 추가하여 SMPL-X를 개선하고 성능을 더 향상시킬 수 있었다. 결과적으로 노이즈가 있는 SMPL-X를 조건으로 하는 ‘ICON +BR’은, GT SMPL-X를 조건으로 하는 PaMIR*와 비슷한 성능을 보여주는데, in-distribution poses(학습 데이터에 포함되어 있고 일반적인 범위 내에 있는 포즈)에서는 살짝 나쁘고 out-of distribution poses에 대해서는 살짝 더 좋다.
6. Conclusion
ICON은 기존의 SOTA 성능을 뛰어넘는 정확하고 사실적인 3D clothed person을 단일 이미지에서 강건하게 복원한다. 두가지 주요 포인트가 존재한다
(1) 3D body model을 사용해 solution을 정규화하면서 그 body model을 반복적으로 최적화한다
(2) local feature를 사용하여 global pose와의 spurious(거짓된) 상관관계를 제거한다
a. Limitations and future work
ICON이 사용하는 strong body prior 때문에 몸에서 떨어져있는 헐렁한 옷은 복원하기가 어렵다

ICON이 body fit의 작은 오류에 강건할지라도, 큰 오차가 발생할 경우 이는 복원의 실패로 이어진다. ICON이 orthographic view로 학습되었기 때문에 강한 perpective 효과에 대해서는 문제가 발생하며 비대칭적이거나 해부학적으로 불가능한 shape을 만들어낸다.
b. Possible negative impact
이미지에서 생성한 virtual human의 품질이 얼굴의 ‘deep fake’ 수준에 미치지 못하지만 이 분야가 발전할 수록 full-body deep fake를 가능하게 할 수 있으며 이는 위험성이 있다. 이러한 위험성은 긍정적인 사용 사례와 균형을 이루어야하며 해당 기술의 사용 범위를 정하기 위한 규제가 필요하다.
