LG Aimers 2기 Phase1 수료 후 진행했던 Phase 2 온라인 해커톤에서 Public 10위, Private 1위를 달성했다. 당시 제출했던 PPT 자료와 함께 간단하게 정리하고자 한다.
Project Definition

먼저 프로젝트 주제는 스마트 공장 제품 품질 상태 분류 AI 모델 개발이었으며 데이터는 다음과 같았다
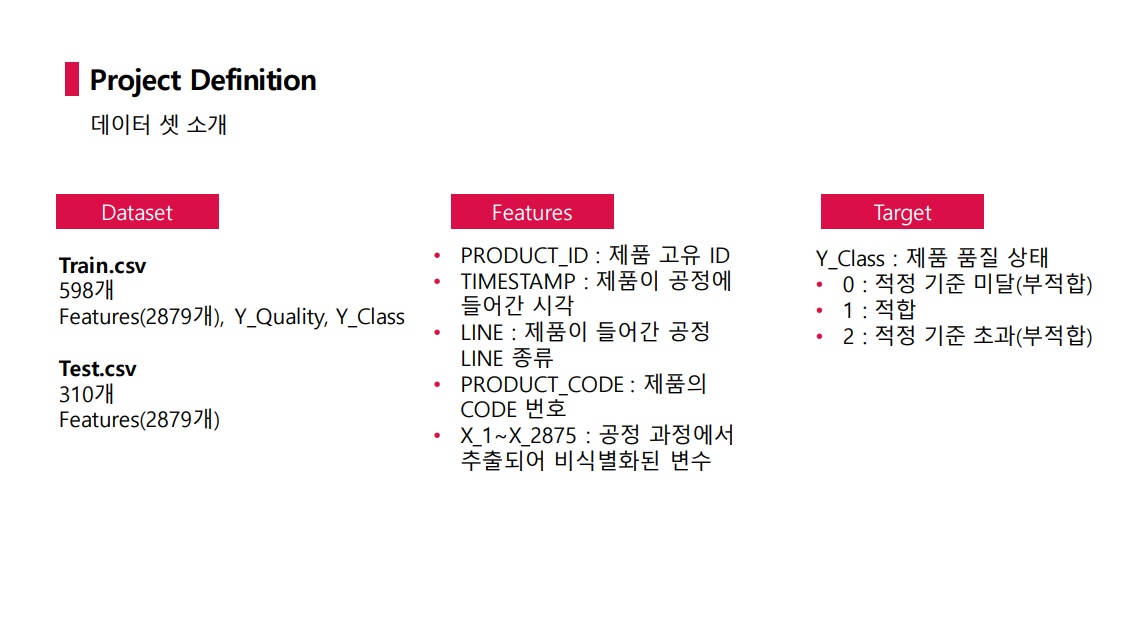
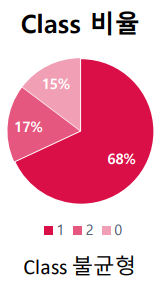
변수는 정말 많았고, 반면 데이터 수는 정말 적었다. 무엇보다 target 변수인 Y_Class에 총 3가지 클래스가 존재했지만 불균형이 매우 심했다. 또한 데이터에 결측값이 말도안되게 많았다.
EDA
범주형 변수에는 결측값이 존재하지 않았다. 따라서 EDA 진행시 범주형 변수들에 집중해서 봤다.
PRODUCT_ID의 경우 제품 고유 ID로 Test 예측에 불필요한 정보였으며 TIMESTMAP는 연도는 동일한 약 4개월 간의 정보였다. 중요했던 것은 PRODUCT_CODE와 LINE 정보였다.

PRODUCT_CODE 별 Y_Class를 봤을 때 눈에 띄는 점은 A_31의 경우 정상 제품이 절반에 불과했지만 T_31의 경우 정상 제품의 비율이 훨씬 높았다. 따라서 A_31에 대해 자세히 본 결과, LINE feature는 총 6개의 unique 값을 갖는데 그 중 A_31이 4개만 갖는다는 것이었다.
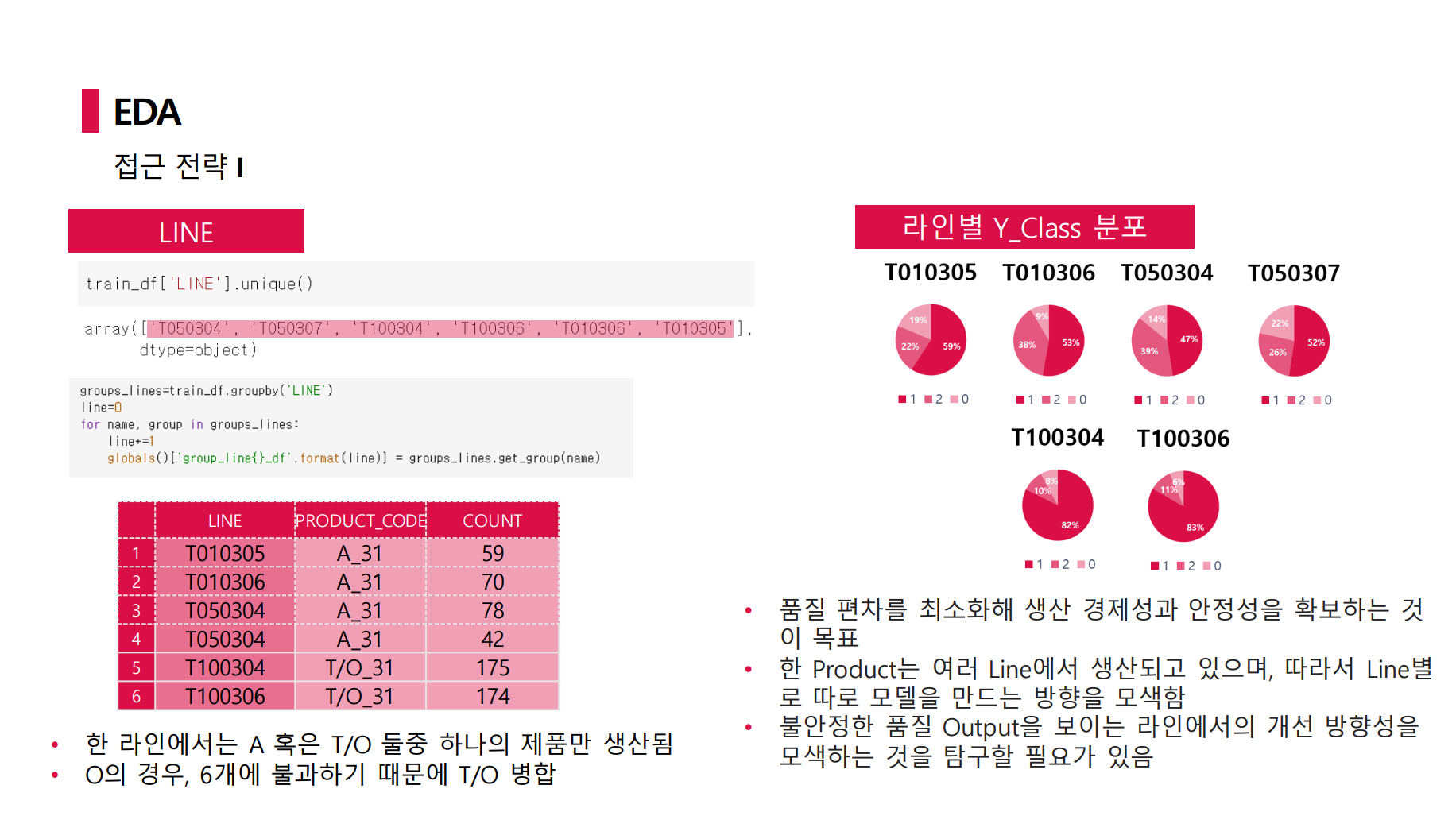
따라서 LINE을 살펴본 결과 한 LINE에서는 한 종류의 PRODUCT_CODE만을 생산하고 있었다. 이때 O_31의 경우 데이터가 6개밖에 없었기에 T_31에 포함시켜 보기로 했다.
또한 데이터 소개에서 보면, target 변수는 Y_Class이지만 TEST 데이터에는 Y_Class 뿐만 아니라 Y_Quality 변수 역시 존재하지 않았다. 이 Y_Class와 Y_Quality 변수 사이의 관계에 주목하였다.

우리의 전략은 Y_Quality의 회귀 예측을 통해 Y_Class를 추정하는 Regression을 사용하는 것이다.
Preprocess
feature 수도 너무 많았고 결측값 역시 너무 많아 feature selection이 필수라고 생각했다.

모든 값이 nan인 변수는 학습에 영향을 주지 않으므로 제거하였고, 모델의 복잡도를 줄이고 다중공선성 문제를 해결하기 위해 일정 값 이상(우리의 경우 0.8) 상관계수를 갖는 column을 제거하고자 하였으나 삭제되는 column이 너무 많아 오히려 성능이 떨어졌고, 이를 완화시켜 nunique가 1 즉 nan을 제외한 후 모든 열의 값이 동일한 column을 삭제하였다.
그럼에도 결측치가 너무 많았는데, 이를 실제 공정 과정에서 생성되지 않은 변수라고 가정하였다. 즉 해당 변수를 발생시키는 event가 발생하지 않았을 것이라고 해석한 것이다.

PRODUCT_CODE 별로 Y_Qulity 추세를 TIMESTAMP로 보았을 때 O_31의 경우 데이터 수가 적어 판단하긴 어렵지만 A_31과 T_31의 경우 명확한 downward trend를 관찰할 수 있었다.
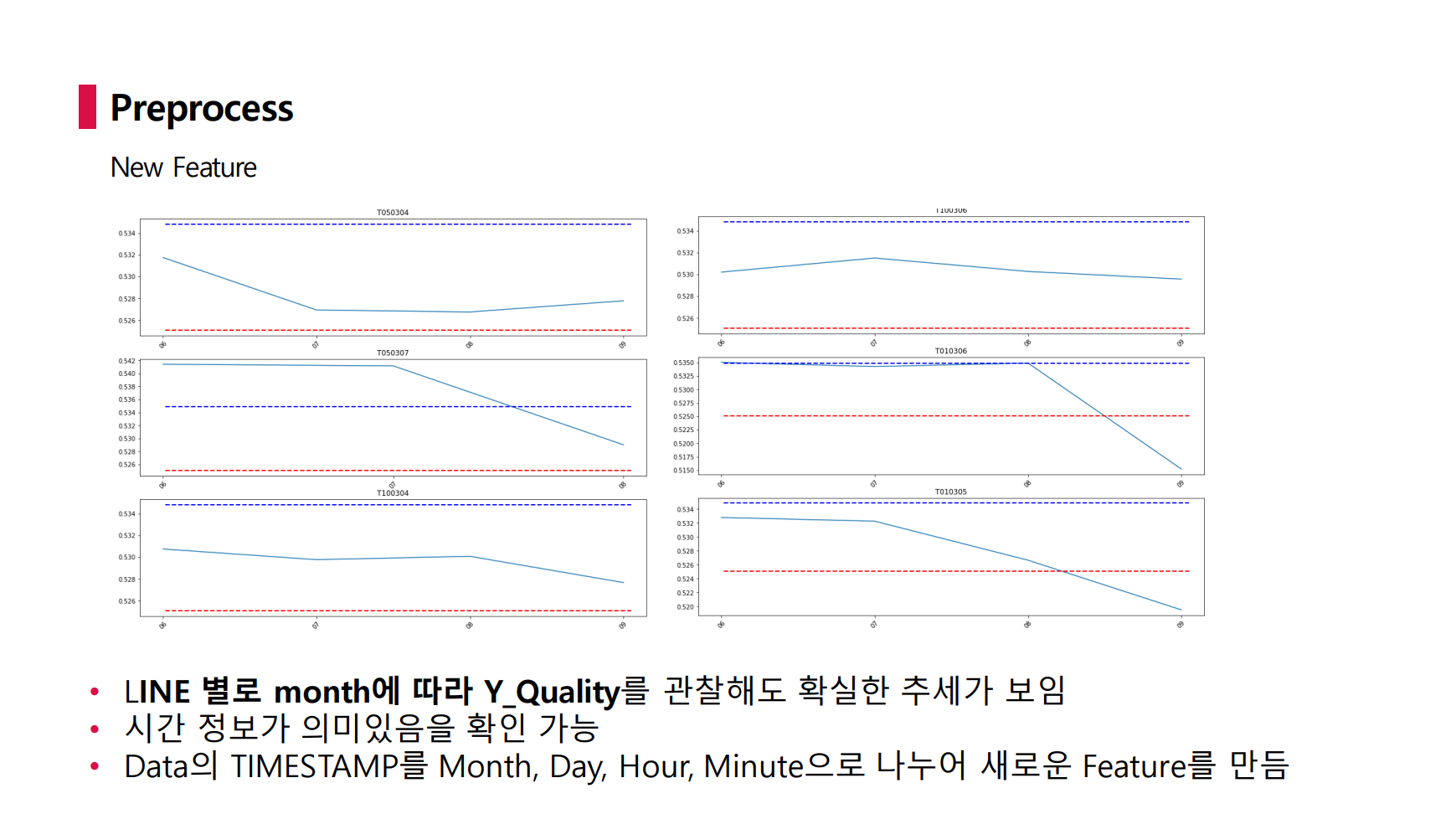
또한 LINE 별로 TIMESTAMP에 따라 Y_Qatliy를 관찰해도 명확한 추세가 보였다. 따라서 시간 정보가 의미있다고 판단하고 TIMESTAMP 변수를 Month, Day, Hour, Minute으로 나누어 새로운 feature를 생성하였다.
Model
먼저 일반화 전략이다. 데이터의 클래스 불균형 문제를 해결하기 위해 oversampling, undersampling 그리고 class에 가중치를 부여하는 학습도 해보았으나 성능 향상은 없었다.
따라서 Class 간의 비율을 고려하여 validaiton set을 구축할 수 있는 Repeated Stratified K-fold를 통해 overfitting을 방지하였다.

모델은 CatBoost를 선택하였다. Line과 PRODUCT_CODE와 같은 주요 feature들이 범주형 변수이므로 이를 다루는데 CatBoost가 다른 알고리즘보다 우수하다고 판단하였다.
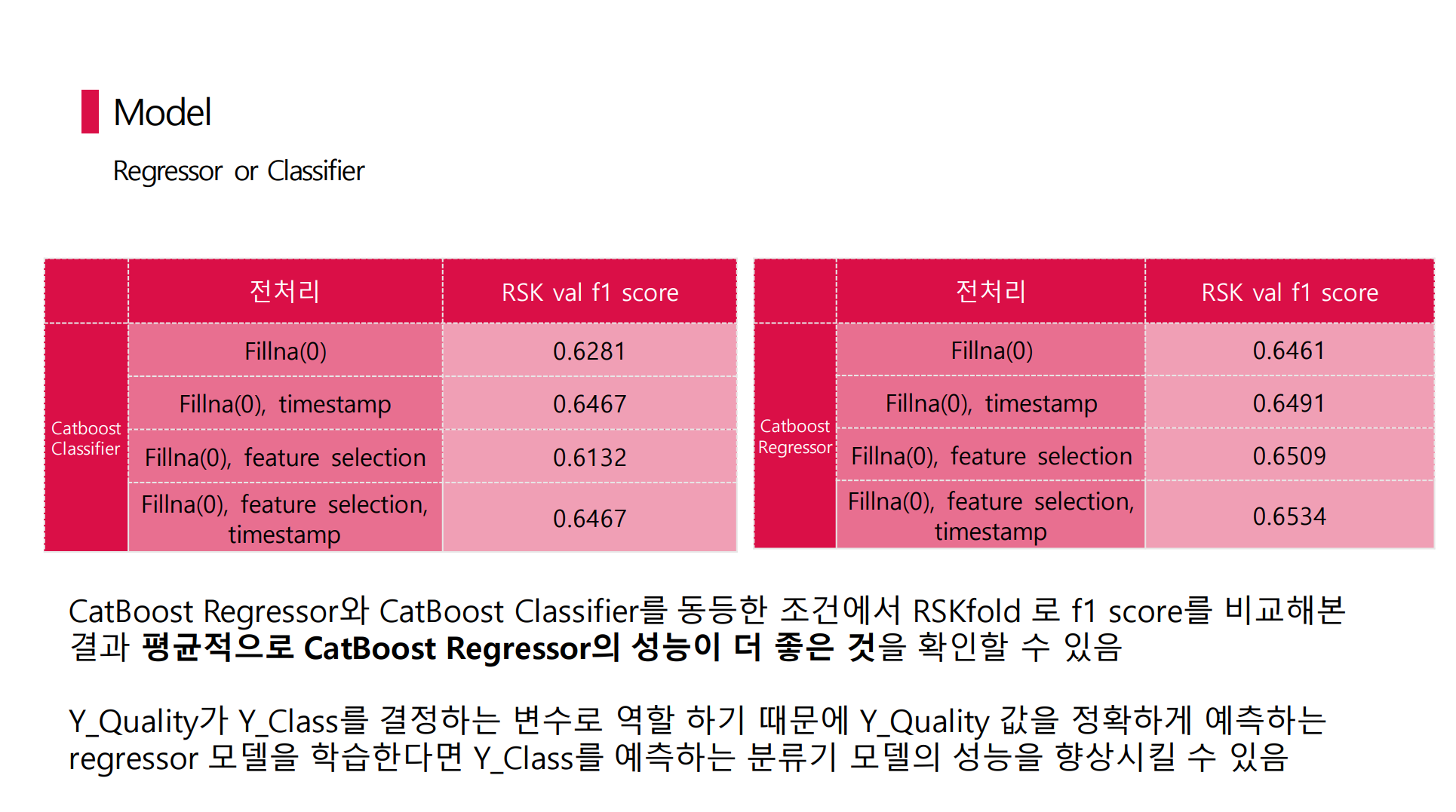
추가적으로 CatBoost Regressor와 CatBoost Classifier를 동등한 조건에서 RSKfold로 비교해보았으나 평균적으로 CatBoost Regressor의 성능이 더 좋았다.
즉 Y_Quality가 Y_Class를 결정짓는 변수 역할을 하기 때문에 Y_Quality 값을 정확하게 예측할 수 있는 regressor 모델을 학습하는 것이 중점이 라고 생각했다.
Tuning
위와 같은 전처리와 regressor 모델 선택 외에도 우리 모델의 성능을 높게 끌어올린 전략이 하나 더 있었다.
바로 위에서 언급한 LINE 별 EDA에서 발전시킨 아이디어였다.
해당 내용은 Phase 3 오프라인 해커톤 포스팅에서 더 자세하게 적고자 생략한다
이번 Phase2의 경우 public과 private score 사이 shake-up이 굉장히 심한 편이었다고 생각한다. feature는 너무 많고 데이터 수는 너무 적었으며 결측치가 매우 많아 overfitting되기 너무 쉬운 조건이었던 것 같다. Aimers 1기때 일반화의 중요성에 대해 크게 실감하여 이번 대회에서도 일반화에 초점을 두었고, 또한 Tuning 내용을 이번 글에서는 생략했지만 이 전략이 좋은 성과에 큰 역할을 했다고 생각한다.
1등... 정말 실감도 안나고 아직도 놀랍기만 한 것 같다...
이번 Phase 2에서 30위권 안에 들어 오프라인 해커톤인 Phase 3에 진출하게 되었고 끝난 지금 돌아보면 새롭고 소중했던 경험이었다.
또한 동기부여도 되고, 뭔가 열정같은 것도 다시 얻어갈 수 있었다.
Aimers 3기도 도전..?!

저도 해당 대회 본선에 참가했는데, 잘 들었습니다!
시간이 많이 지났네요! 많이 배웠습니다!