PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization
0. Abstract
PIFu(Pixel-aligned Implicit Function)은 2D 이미지 픽셀을 각각의 3D 객체와 일치시켜서 global context를 제공하는 implicit representation이다.
기존의 방법들과 달리 unseen 영역을 포함하는 고해상도의 표면도 생성하며 voxel 표현 방법과 달리 메모리 효율적이고 arbitrary topology도 처리할 수 있다. 결과로 나온 표면은 input image에 공간적으로 일치시킬 수 있다. 또한 PIFu는 임의의 수의 시점으로 확장할 수 있다.
"spatially aligned"는 공간적으로 정렬된다는 뜻으로 이미지와 3D 공간을 서로 매핑하여 정확하게 대응시키는 것을 의미한다. 이를 통해 이미지의 각 픽셀과 3D 공간의 각 지점을 일치시키고, 3D 모델과 이미지 간의 일관성을 유지할 수 있다.
1. Introduction
기존의 2D 이미지 처리에서 효과적이었던 딥러닝 방법들은 (semantic segmentation, 2D joint detection 등) 이미지와 아웃풋 사이의 spatial alignment를 유지하는 ‘fully-convolution’ 구조를 활용하지만 3D 도메인에서는 어렵다.
- voxel 표현법은 fully-convolutional 측면으로 적용될 수 있으나 fine-scale의 디테일한 표면을 생성하기에는 메모리 문제로 제한적이다.
- global representation에 기반을 둔 추론 기술은 메모리 효율적이지만 입력 이미지의 디테일이 보존된다는 보장이 없다.
- implicit function에 기반을 둔 방법 역시 이미지의 global context에 의존하여 전체적 shape을 추론하기에 입력 이미지와 정확하게 일치하지 않을 수 있다.
반면 PIFu는 픽셀 수준의 개별적인 local feature를 전체 물체의 global context에 fully convolutional 방법으로 align하기 때문에 높은 메모리 사용량을 필요로 하지 않는다. 특히, shape이 arbitrary topoogy일 수도 있으며 매우 변형이 심하고 매우 디테일한 clothed subject의 3D 재구축과 관련있다.
구체적으로, 이미지의 각 pixel에서, 그 위치에 관련된 global context를 고려하여 개별 feature vector를 학습하는 encoder를 학습시킨다. 이 per-pixel feature vector와 이 픽셀에서 나아가는 카메라 ray를 따라가는 specified z-depth가 주어지면 implicit function을 학습할 수 있다. 이 implicit function은 해당 z-depth에 대응하는 3D point가 surface의 안에 존재하는지 밖에 존재하는지를 분류한다. 특히 feature vecotr는 global 3D surface shape을 픽셀에 spatially align하는데 이는 입력 이미지에서 나타나는 local 디테일을 보존하게 하는 동시에 unseen 지역에 대해 합리적인 추론을 가능하게 한다.
PIFu는 ray를 따르는 각 queried point의 RGB 값을 회귀하기 위해 단순히 implicit function을 적용하는 것만으로, per-vertex(정점마다) 색상을 추론하는 것으로 확장될 수 있다. 따라서 우리의 디지털화 프레임워크는 또한 표면의 복잡한 질감을 생성하고 unseen 지역에 대한 합리적인 외관 디테일을 예측한다.
다중뷰 스테레오 제약조건을 통해 PIFu는 또한 다중 입력 이미지를 처리하도록 확장될 수 있다. 단일 이미지로도 복잡한 textured mesh를 생성하는 것이 가능하지만 다중뷰를 사용하면 unseen 지역에 대한 정보를 추가적으로 제공하므로 결과를 개선할 수 있다.
2. Related Work
생략
3. PIFu: Pixel-Aligned Implicit Function
Implicit function(IF)는 surface를 함수 f 즉 예를 들어 f(X) = 0 으로 정의한다. 이는 surface가 임베드된 공간이 명시적으로 저장될 필요가 없으므로 surface를 메모리 효율적으로 표현하게 한다. 제안된 pixel-aligned implicit function은 fully convolutional image encoder인 g와 MLP로 표현된 continuous implicit function인 f로 구성되어있다. 이때 표면은 다음과 같이 정의된다.

이때 X는 3D point, x = π(X)는 X의 2D 투영값, z(X)는 카메라 좌표계에서 depth 값, F(x) = g(I(x))는 x에서의image feature이다.
X의 2D 투영값인 x는 이산 공간(픽셀)이 아닌 연속적인 공간에서 정의되므로 pixel aligned feature인 F(x)는 bilinear sampling을 통해 얻는다.
즉 global feature가 아닌 pixel-aligned image feature를 통해 3D 공간에서 implicit function을 학습한다는 것이다. 이는 IF가 이미지에 나타나있는 local detail을 보존하도록 한다. PIFu의 연속적 특성은 메모리 효율적인 방법으로 임의의 topology의 디테일한 geometry를 생성하도록 한다.
Digitization Pipeline
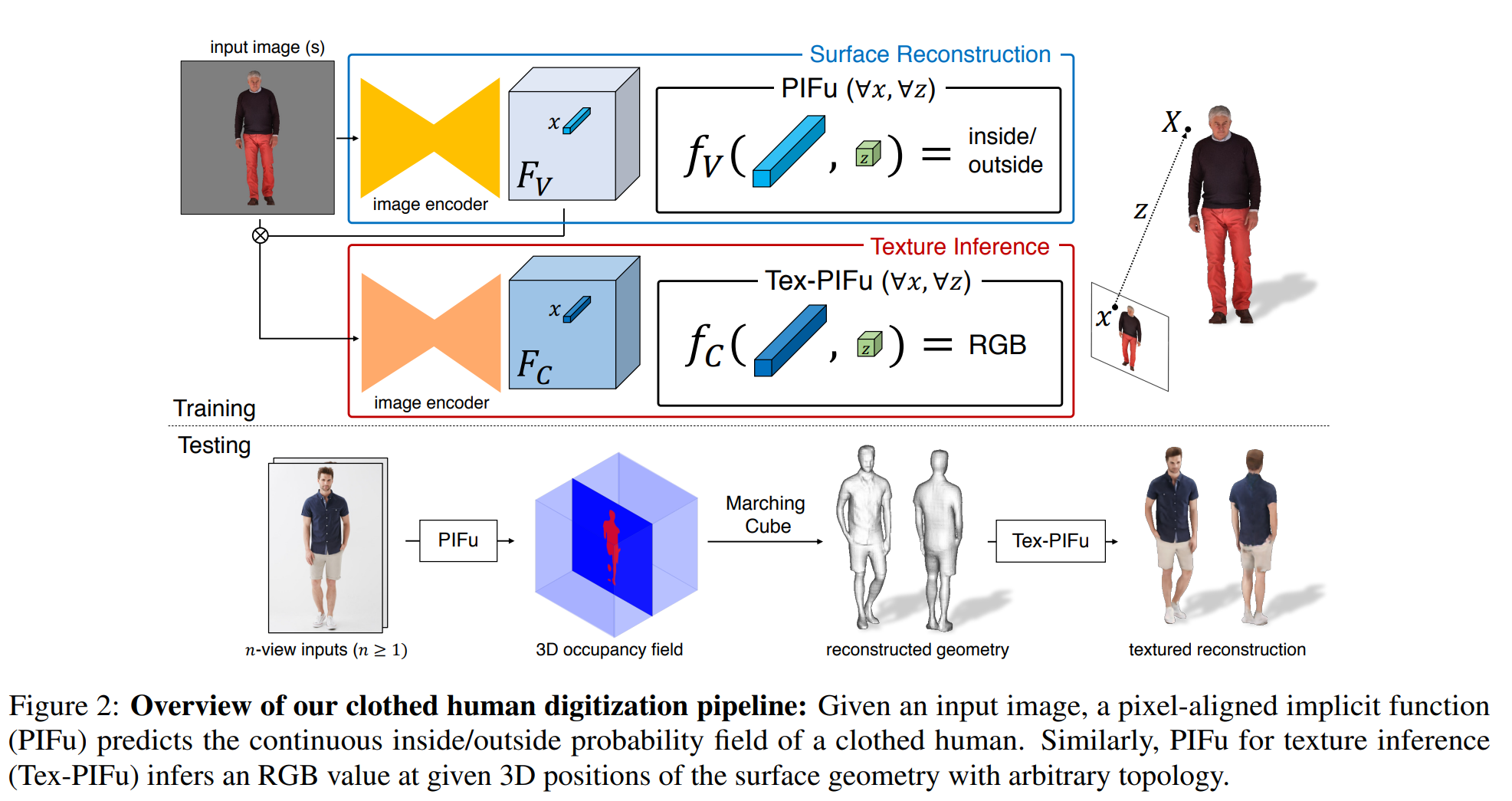
입력 이미지가 주어지면 surface 재구축을 위한 PIFu가 clothed human의 연속적인 내부/외부 확률 필드를 예측하여 iso-surface가 쉽게 추출되도록 한다. 비슷하게 텍스쳐 추론을 위한 PIFu(Tex-PIFu)가 surface geomery의 3D 위치의 RGB 값을 출력해서 self-occluded surface 영역과 임의의 topology의 shape의 텍스처 추론을 가능하게 한다. 더욱이 단일 및 다중 뷰 입력을 자연스럽게 처리할 수 있으며 더 많은 뷰가 사용 가능할 때 더 높은 정확도로 결과를 생성한다.
a. Single-View Surface Reconstruction
surface 재구성을 위해서, GT surface를 연속적인 3D occupacy field의 0.5 level-set으로 표현한다.
- 레벨셋(Level-set)은 특정 값(예를 들어 0)을 가지는 함수의 등면(isosurface)을 표현하는 방법이다.
- Iso-surface는 implicit function이 특정 값을 가지는 지점들의 집합을 의미한다.
- 3D occupancy field는 3차원 공간을 격자 형태의 3D 그리드로 분할하고, 그리드 셀 안에 오브젝트가 존재하는지 여부를 나타내는 이진 값 (occupied or not)으로 표현한 것이다.

ixel-aligned implicit function인 fv를 MSE의 평균을 최소화하는 방향으로 학습시킨다
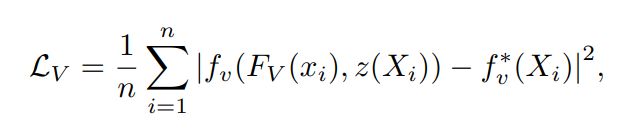
이때 Xi는 3차원 값, FV(x) = g(I(x))는 image encdoer인 g에서 나온 image feature이며 이때 x는 π(X)이며 n은 샘플링 된 포인트의 개수이다. 인풋 이미지와 그 이미지에 spatially aligned되는 대응하는 3D mesh가 쌍으로 주어지면 , image encoder인 g의 파라미터와 PIFu인 fv가 위 식을 최소화하는 방향으로 업데이트된다.
추론하는 동안, 3D 공간에서 probability field를 밀도있게 샘플링하고 probability field에서 Marching Cube 알고리듬을 사용하여 임곗값 0.5로 iso-surface를 추출한다. implicit surface 표현은 임의의 topology의 디테일한 물체에 적합한 표현이다. PIFu의 표현력과 메모리 효율성 외에도 고품질적 추론에 중요한 공간 샘플링 전략을 개발했다
Spatial Sampling
ray tracing 알고리즘을 사용해 원본 해상도의 GT mesh에서 3D point를 직접 샘플링한다. watertight(완전히 닫힌) mesh가 필요하다.
샘플링 전략 역시 최종 재구성 품질에 큰 영향을 준다. 3D 공간에서 균일하게 샘플링한다면 대부분 point가 iso-surface에서 멀어서 네트워크의 outside 예측을 가중시킨다. iso-surface 주변만 샘플링하는 것은 오버피팅을 야기할 수 있다. 따라서 surface geometry에 기반하여 uniform 샘플링과 adaptive 샘플링을 합친다. 먼저 surface geometry에서 무작위로 샘플링하고 x,y,z축에 대해 정규 분포 N (0, σ)로 offset을 더해서 surface 주변인 위치를 혼란시킨다. 이 샘플들을 16:1 비율을 사용한 bounding box 내에서 균일하게 샘플링한 포인트와 합친다.
b. Texture Inference
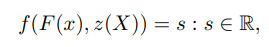
PIFu는 s를 스칼라 필드가 아닌 RGB 필드로 정의하여 surface geometry에서 RGB 색을 직접 예측한다. 이는 임의의 topology와 self-occlusion이 있는 shape의 텍스쳐링을 가능하게 한다.
surface 위의 샘플링된 3D 포인트 X ∈ Ω가 주어지면 텍스처 추론을 위한 목적(손실) 함수는 샘플링 된 색의 L1 오차의 평균이다
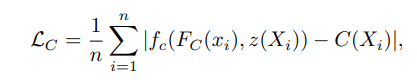
C(Xi)는 surface point인 Xi ∈ Ω에서의 GT RGB 값이며 n는 샘플링된 point 개수이다. 위의 손실함수로 fc를 단순히 학습하면 심각한 오버피팅이 발생한다. 문제는 fc가 surface의 RGB 값 뿐만 아니라 물체의 underlining 3D surface 또한 학습하여 fc가 다른 pose, shape에서 보이지 않는 surface의 텍스처를 추론할 수 있도록 기대되기 때문이다.
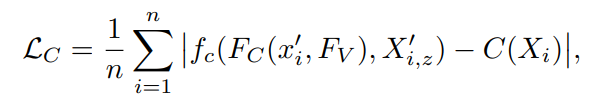
텍스처 추론을 위한 image encoder를 image feature인 Fv로 조건화한다. 이렇게 하면 image encoder는 보지 않은 물체가 다른 shape, pose, topology를 갖더라도 색상 추론에 집중할 수 있다. 또한 surface의 법선 N을 따라 surface 포인트에 offset을 도입해서 색상이 정확한 surface 뿐만 아니라 주변의 3D 공간에도 정의될 수 있도록 했다.
c. Multi-View Stereo
다중뷰로부터의 정보를 통합하기 위해 PIFu로 공간의 모든 3D point의 feature embedding을 학습한다.
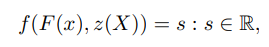
위 식의 출력 도메인은 3D 좌표와 각 뷰에서의 image feature와 연관된 latent feature embedding를 표현하는 n-차원 벡터 공간 s이다. 이 임베딩이 3D 세상 좌표계에 정의되기에 동일한 3D point를 공유하는 모든 가능한 뷰의 embedding을 통합할 수 있다. 통합된 feature vector는 surface와 texture의 예측에 사용될 수 있다.
pixel-aligned function f를 feature embedding network f1과 multi-view reasoning network f2로 분해한다. (f := f2 ◦ f1.)
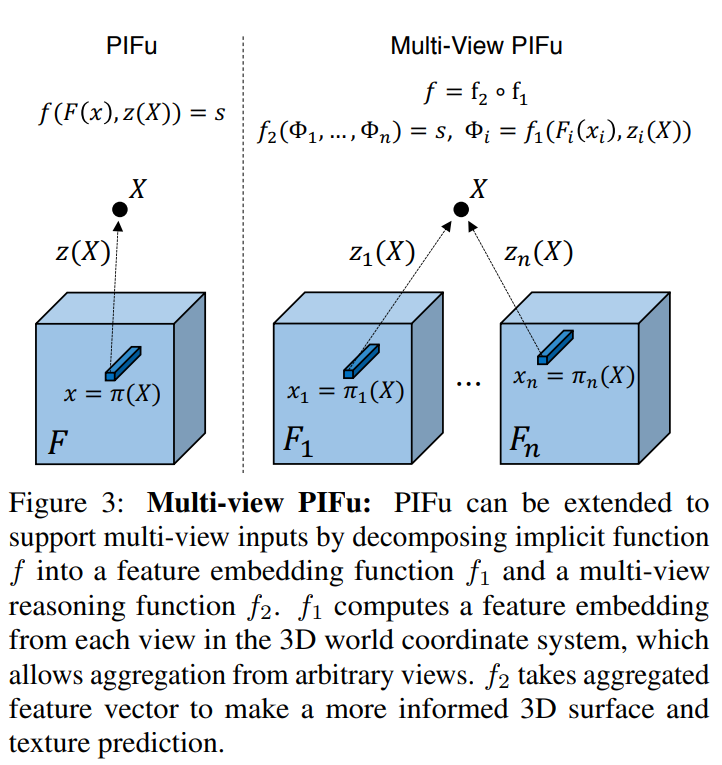
첫 f1은 image feature인 Fi(xi) : xi = πi(X)와 각 뷰 포인트 i에서의 depth 값인 zi(X)를 latent feature embedding Φi로 인코딩한다. 이는 모든 뷰에서 대응하는 pixel feature를 통합하게 한다. 대응하는 3D point X가 다른 뷰에서 공유되므로 각 이미지는 X를 자신의 이미지 좌표에 πi(X)와 zi(X)로 투영할 수 있다. 그 다음 latent feature인 Φi를 average pooling 연산으로 통합하고 fused된 임베딩인 ¯Φ =mean({Φi})를 얻는다.
두번째 f2는 통합된 임베딩 ¯Φ를 target implicit field인 s(surface 재구성을 위한 inside/outside probability와 텍스쳐 추론을 위한 RGB 값)로 매핑한다. latent embedding의 additive 성질로인해 임의의 개수의 인풋을 통합할 수 있다. 단일 뷰 역시 수정 없이 같은 프레임 워크에서 처리할 수 있으며, 평균 연산이 원본 latent embedding을 반환한다.
4. Experiments
RenderPeople, BUFF, DeepFashion을 포함한 다양한 데이터 셋으로 평가함
Implementation Detail
PIFu는 특정 네트워크 구조에 국한되지 않기에 image encoder로써 어떠한 fully convolutional neural network를 사용해도 가능하다.
surface 재구성을 위해서는 실제 이미지에 일반화하는데 효과적인 stacked hourglass가 효과적이었다. 텍스처 추론은 residual block으로 구성된 CycleGAN 구조를 사용했다. IF는 depth 정보를 효과적으로 전파하기 위해서 image feature인 F(x)와 depth인 z에 skip connection이 있는 MLP가 기반이 되었다. Tex-PIFU은 Fc(x)와 surface 재구성을 위한 image feature인 Fv(x)를 인풋으로 사용한다. 다중뷰 PIFu는 중간 레이어 출력을 feature embedding으로 사용하고 average pooling을 적용하여 다른 뷰의 임베딩을 통합한다.
a. Quantitative Results
세 가지 측정 항목을 사용하여 재구축 정확도를 평가한다.
- 재구축된 surface의 꼭지점에서 GT까지 평균 point-to-surface Euclidean distance(P2S)를 cm 단위로 측정
- 재구축된 surface와 GT surface간의 Chamfer distance
- normal reprojection error
local detail의 섬세함과 입력 이미지에서의 투영 일관성을 확인
재구축된 surface와 GT에 대해서 입력 시점에 대한 normal map을 이미지 공간에 렌더링한다.
Single-View Reconsturction
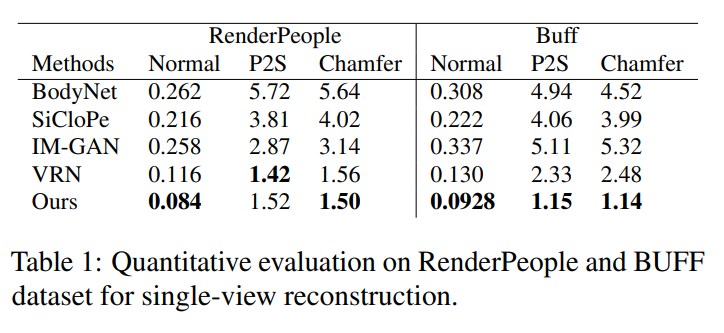
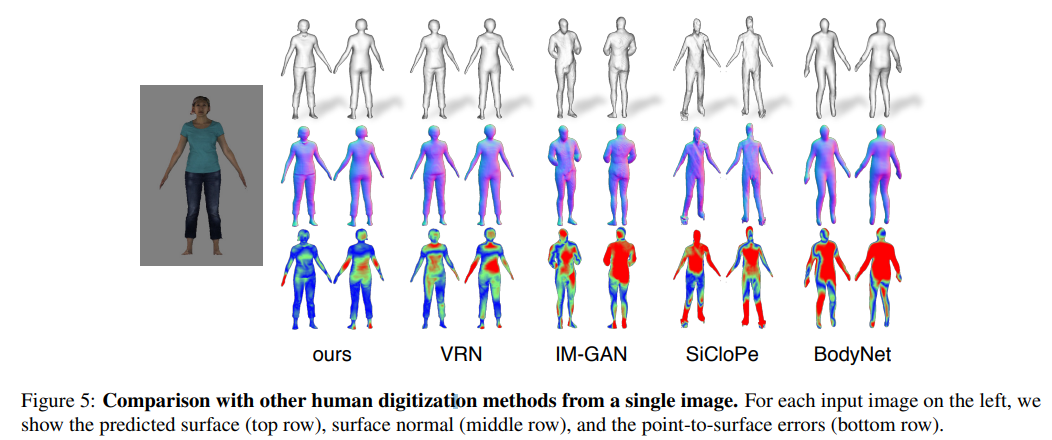
surface를 이미지 당 하나의 global feature로 재구축하는 IM_Gan과 비교한 결과, PIFu가 머리카락이나 옷의 주름까지 잡아내는 pixel-aligned 고해상도 surface 재구축을 출력한다.
Voxel Regression Network(VRN)과 PIFu는 같은 구조의 image encoder를 사용하지만 implicit representation의 높은 표현력이 PIFu가 높았다.
clothed human에서 texture를 추론하는 SOTA인 SiCloPe는 2D 이미지에서 후면 뷰를 추론하고 인풋인 정면 이미지에 붙여서 textured mesh를 얻는다. SiCloPe는 투영 왜곡과 실루엣 경계에서 artifects 문제가 발생하지만 PIFu는 surface mesh에 직접 텍스쳐를 예측하므로 projection artifects 문제를 제거한다.
경계 주변의 아티팩트"는 3D 모델링에서 모델의 경계 부분에서 발생하는 현상으로, 일반적으로 텍스처나 노말 맵의 투영 과정에서 발생하는 불필요한 변형이나 노이즈 등을 의미한다
Multi-View Reconstruction
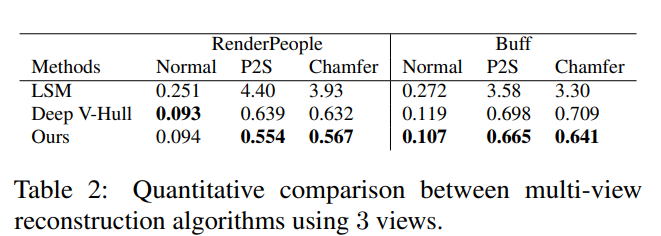
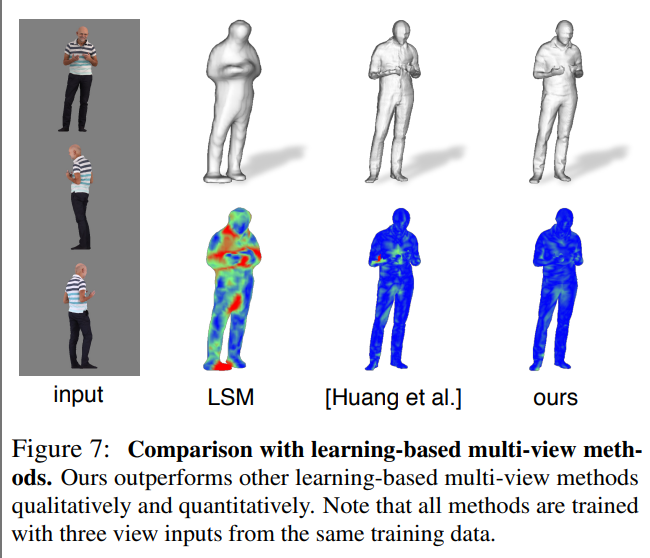
LSM을 포함한 딥러닝 기반 다중뷰 방법들과 deep visual hull 기반 방법과 PIFu를 비교한다. Deep V-Hull의 경우 3D 좌표 정보를 고려하지 않고 이미지 특징만을 이용하여 다중 뷰 특징 퓨전 과정을 수행하기에 PIFu의 퇴화한 형태로 볼 수 있다.
깊이 정보에 대한 조건부의 중요성을 확인하고자 실험을 진행했고, PIFu가 임의의 수의 뷰를 통합하여 기하학과 텍스처를 점차적으로 개선할 수 있음을 보여주며, 최고 수준의 재구성을 달성한다는 것을 보여준다.
b. Qualitative Results
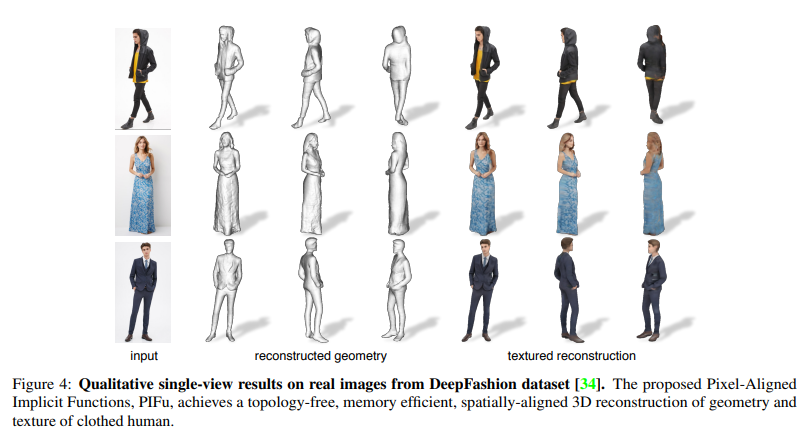
위는 DeepFashion 데이터셋에서 가져온 실제 옷 이미지를 사용하여 수행한 디지털화 결과이다. 스커트, 자켓, 드레스 등 다양한 의류를 다룰 수 있으며, 복잡한 형태의 지역적인 디테일을 높은 해상도로 추론할 수 있다. 또한 단일 입력 이미지로 전체적인 텍스처를 성공적으로 추론하여 360도에서 3D 모델을 볼 수 있다.
