4. Task-oriented Dialogue Systems
Overview
Slot-filling Dialogues
작업이 성공적으로 완료되기 전에 미리 정의된 슬롯 집합에 대한 값을 채우는 것과 관련된 단순하지만 중요한 dialogue class에 중점을 두자. task를 수행하기 위해 시스템은 user와 대화하며 필요한 정보를 수집해야한다.
slot-filling 대화는 여러 도메인(영화, 레스토랑, 항공권 예약 등)에서 적용되며, 각 도메인에 대해 슬롯 set는 도메인 전문가에 의해 정의되고 어플리케이션에 따라 다르다.
핸드폰 번호처럼 슬롯의 값이 대화를 제한하는 경우 슬롯을 informable라고 하며, 티켓 가격처럼 화자가 값을 요청할 수 있는 경우 requestable이라고 부른다. 영화 이름처럼 슬롯은 informable과 requestable 둘 다일 수도 있다.
Dialogue Acts
대화 agent와 사용자 간의 상호작용은, 사용자의 발화가 관찰이고 시스템의 발화가 대화 agent에 의해 선택된 행동인 것처럼 RL agent와 환경과의 상호작용을 반영한다. dialogue act 이론은 이러한 직관에 대한 형식적 토대를 제공한다.
사용자나 에이전트의 발화는, 사용자와 시스템 모두의 상태를 즉 대화의 상태를 변경할 수 있는 동작으로 간주된다. 이 동작은 특정 정보를 제안, 알리거나 요청하는 데 사용된다. 어떤 대화 동작은 슬롯이나 슬롯 값의 쌍을 인자로 갖는다.
보통, 대화 동작은 domain-specific하다.
Dialogue as Optimal Decision Making
대화 동작이 준비되면, 대화 agent와 사용자 사이에 RL 문제로서 multi-turn 대화를 모델링할 준비가 되었다. 대화 시스템은 RL agent, 사용자는 환경이다. 대화의 매 턴마다
- <agent>는 지금까지 대화를 통해 밝혀진 정보를 바탕으로 대화 상태를 추적하고 동작을 취한다. 동작은 대화 동작 형태의 response일 수도 있고 API를 부르거나 데이터베이스를 보는 등의 내부 작동일 수도 있다.
- <사용자>는 에이전트가 다음 턴에 내부 대화 상태를 업데이트하는 데 사용할 다음 발화로 응답한다.
- 즉각적인 보상은 이번 턴의 대화의 품질/비용을 측정하기 위해 계산된다
보상 함수가 어떻게 결정되는지 논의하자.
적절한 보상 함수는 대화 시스템의 원하는 기능을 잡아내야한다. Task-oriented 대화에서 우리는 시스템이 적은 턴으로 사용자를 돕는 것을 성공하길 바란다. 따라서 작업이 성공적으로 해결되었을때 큰 보상을, 그렇지 않다면 작은 보상을 주는 것은 자연스럽다. 또한 대화이 중간 턴마다 약간의 페널티를 주어 agent가 대화를 가능한 짧게 하도록 권장한다.
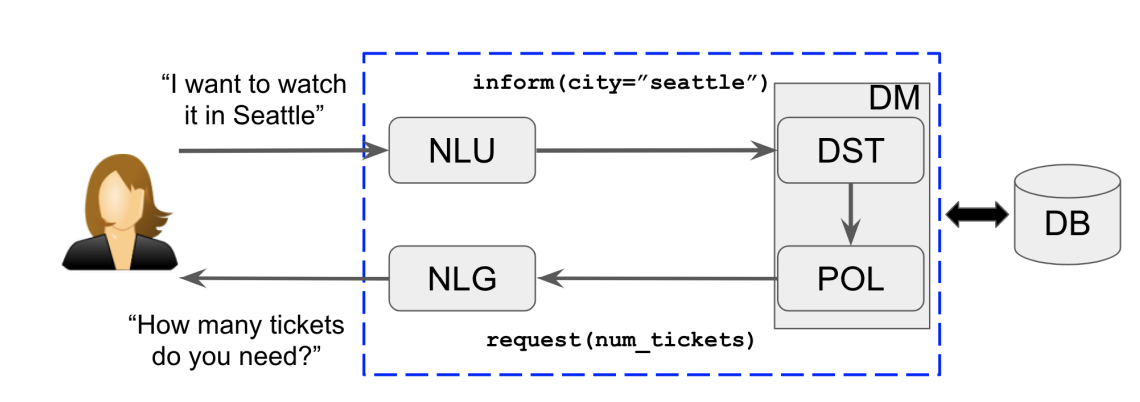
- NLU : 사용자의 raw 발화를 input으로 받아 대화 동작의 의미론적 형태로 변환한다
- DM : 대화 시스템의 중심 컨트롤러
- DST : 현재 대화 상태를 계속 추적
- POL : DST에 의해 제공된 내부 상태에 의존하여 동작을 선택. 동작은 사용자에게 주는 response일 수도, 백엔드 데이터베이스에 대한 어떠한 작업일 수도 있다.
- NLG : 정책이 사용자에게 응답하기로 선택한 경우 이 동작(종종 대화 행위)을 자연어 형식으로 변환한다
Evaluation and User Simulation
평가는 대화 시스템에 대한 중요한 연구 주제이다. 따라서 corpus-based approaches, user simulation, lab user study, actual user study 등 다양한 접근이 사용되었다.
Evaluation Metrics
전체 대화 시스템을 평가하려면 정확도, 정밀도, 재현율, F1보단 전체적인 관점이 필요하고 어렵다. 강화학습 프레임워크에서, 보상 함수가 대화의 품질의 다양한 측면을 고려해야함을 함축한다. 실제로, 보상함수는 종종 아래의 metric의 하위 집합의 weighted linear 조합이다.
- 작업 완료 성공을 측정하는 metric. 아마도 사용자의 task를 성공적으로 해결한 대화의 비율, 즉 task success rate일 것이다.
- 경과 시간과 같이 대화에서 발생하는 비용을 측정하는 metric. 다른 모든 것이 동일할 때, 더 짧은 대화가 선호된다는 직관을 반영한, number of turns.
대화 품질의 다른 측면(챗봇의 경우 일관성, 다양성, 스타일)이 보상 함수로 인코딩 될 수 있다.
Simulation-Based Evaluation
RL 알고리즘은 사용자와 상호작용하며 학습을 하며, 이는 많은 비용이 든다. 따라서, RL 알고리즘이 거의 무료로 상호작용 할 수 있는 시뮬레이션 된 사용자를 구축해야한다. 시뮬레이션 사용자는 실제 사용자가 대화에서 하는 것, 즉 대화 상태를 추적하고 RL 대화 시스템과 대화하는 것을 따라하려고 시도한다.
시뮬레이션 사용자를 분류하는데는 다양한 차원이 있다 : 결정론적 vs 확률론적, 콘텐츠 기반 vs 협업 기반, 대화 중 사용자 목표에 대해서 정적 vs 비정적.
- granularity(세분화) 차원에서, dialogue-act(intention level) vs utterance level
- methodology(방법론) 차원에서, rule-based vs model-based(실제 대화 corpus에서 학습하는)
Agenda-Based Simulation
각 대화 시뮬레이션은 대화 관리자(DM)에게 알려지지 않은 무작위로 생성된 사용자 목표로 시작한다. 일반적으로 사용자 목표는 두 부분으로 구성된다.
- inform-slot : 사용자가 대화에 부과하기를 원하는 제약 조건
으로 작용하는 많은 슬롯 값 쌍을 포함.- request-slog : 처음에 값이 알려지지 않고 대화 중에 채워지는 슬롯.

사용자 목표를 보다 현실적으로 만들기 위해 도메인별 제약 조건이 추가되어 사용자 목표에 특정 슬롯이 표시되도록 요청된다. (사용자에게 영화 도메인에서 원하는 티켓 수를 알기위해 요구하는 것)
대화가 진행되는 동안 시뮬레이션 사용자는 user agenda라고 하는 스택 데이터 구조를 유지 관리한다. agenda의 각 entry은 사용자가 달성하고자 하는 보류 중인 의도에 해당하며 우선 순위는 agenda 스택의 First-in-last-out에 의해 암시적으로 결정된. Agenda는 대화 내역과 사용자의 ‘심리’를 인코딩하는 편리한 방법을 제공하는 것이다. 사용자 시뮬레이션은 더 많은 정보가 공개될 때 매 턴의 대화가 끝난 후 agenda를 유지하는 방법으로 요약된다.
Model-based Simulation
전적으로 데이터를 기반으로 사용자 시뮬레이터를 구축한다. agenda-based 접근과 비슷하게, 시뮬레이터는 무작위로 생성된 사용자 목표와 제약으로 에피소드를 시작한다. 다음은 대화 중 고정되어야 하는 것들이다.
매 턴마다 사용자 모델은 지금까지 대화에서 수집된 context 시퀀스를 입력으로 받고, 다음 동작을 출력한다. 특히, 대화의 턴마다 context는 다음으로 구성된다
- 가장 최근의 기계 동작
- 기계의 정보와 사용자 목표 사이의 불일치
- 제약 상태
- 요청 상태
context에서 LSTM 또는 seq2seq을 사용하여 다음 사용자 발화를 출력한다. 모델은 인간-인간 대화 corpus에서 학습할 수 있다.
Further Remarks on User Simulation.
인간과 유사한 시뮬레이터를 구축하는 것은 여전히 challenging하다. 실제로 특정 사용자 시뮬레이터에 과적합된 대화 시뮬레이션은 다른 사용자 시뮬레이터나 실제 인간에게 서비스를 제공할 때 제대로 작동하지 않을 수 있음이 종종 관찰된다. 사용자 시뮬레이터와 인간 사이의 격차는 사용자 시뮬레이션 기반 대화 정책 최적화의 주요 한계이다.
Human-based Evaluatoin
시뮬레이션 사용자와 인간 사용자 간의 불일치로 인해, 품질을 안정적으로 평가하기 위해 인간 사용자에 대한 대화 시스템을 테스트해야 하는 경우가 많다. 인간 사용자에는 대략 두 가지 유형이 있다.
-
실험실 연구에서 모집된 인간 피험자들
참가자는 대화 시스템을 테스트/사용하여 주어진 task를 해결하여 대화 모음을 얻도록 요청받는다. 작업 완료율 및 대화당 평균 턴 수와 같은 관심 지표가 측정된다. 참여자 일부는 baseline 대화 시스템을 테스트/사용하도록 요청받아 두 가지를(baseline과 테스팅할 대화 시스템) 다양한 측정 기준과 비교할 수 있다.
장기간 참여할 수 있는 많은 수의 참여자를 확보하는 데 다소 비용과 시간이 많이 소요된다. 따라서 다음과 같은 제한 사항이 있다.- 적은 수의 피험자가, 통계적으로 중요하지만 수치적으로는 metric에서 작은 차이를 감지하지 못해 종종 결정적이지 않은 결론으로 이어진다.
- 매우 적은 수의 대화 시스템만 비교할 수 있다.
- 상대적으로 간단한 대화 응용 프로그램을 제외하곤, RL 에이전트를 실행하는 것은 종종 비실용적이다.
-
실제 사용자들
그들은 시스템과 대화하여 해결해야 할 실제 작업이 있다는 점을 제외하면 첫 번째 유형의 사용자와 유사하다. 평가된 metric은 인공적으로 생성된 task로 모집된 인간 대상에 대해 계산된 것보다 훨씬 더 신뢰할 수 있다. 또한 실제 사용자의 수는 훨씬 더 많을 수 있으므로 평가의 유연성이 향상된. A/B-testing, counterfactual estimation과 같은 다양한 온라인 및 오프라인 평가 기법을 사용할 수 있다. 단 주요 단점은 부정적인 사용자 경험과 서비스 중단의 위험이 있다는 것이다.
Other Evaluation Techniques
RL의 self-play 기법에서 영감을 받은 evaluation에 대한 다른 접근 방식이 연구되고 있디. 일반적으로는 두 플레이어가 동일한 RL 에이전트에 의해 제어되고 다르게 초기화될 수 있는 2인 게임(예: 바둑 게임)에서 사용된다. 에이전트가 스스로 플레이함으로써 저렴한 비용으로 많은 궤적을 생성할 수 있으며, 이를 통해 RL 에이전트는 좋은 정책을 학습할 수 있다. 대화에 참여하는 두 당사자는 종종 (바둑과 달리) 비대칭 역할을 수행하기 때문에 self-play는 DM에 사용될 수 있도록 조정되어야 한다.
실제로는 evaluation에 하이브리드 접근 방식을 사용하는 것이 합리적이다. 시뮬레이션된 사용자로 시작한 다음 인간 사용자에 대한 대화 정책을 검증하거나 미세 조정하는 것, 정책 학습을 위해 두 사용자 소스를 모두 사용하는 보다 체계적인 접근 방식이 있다.
Natural Language Understanding and Dialogue State Tracking
NLU와 DST는 대화 시스템에 필수적인 두 가지 밀접하게 관련된 구성 요소이다. 이는 전체 시스템의 성능에 상당한 영향을 미칠 수 있다.
Natural Language Understanding
NLU 모듈은 사용자 발화를 입력으로 받아 1) 도메인 감지 2) 의도 결정 3) 슬롯 태깅의 세 가지 작업을 수행한다.
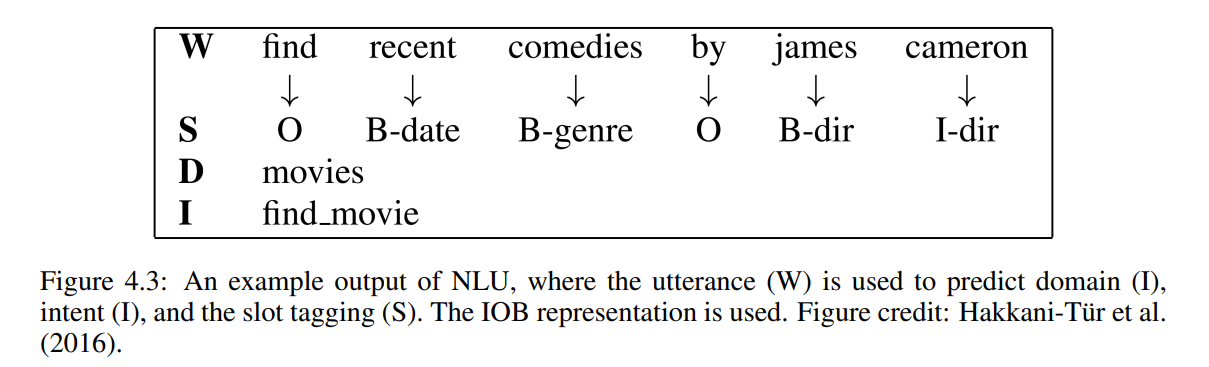
일반적으로 세 가지 작업이 차례로 해결되도록 파이프라인 방식이 사용된다. 일반적으로 정확도와 F1 점수로 모델의 예측 품질을 평가한다. NLU는 다음의 모듈들을 위한 전처리 단계로, 그 품질은 시스템의 전체 품질에 상당한 영향을 미친다.
그 중 처음 두 작업은 현재 사용자 발화를 기반으로 도메인 또는 의도(미리 정의된 후보 집합에서)를 추론하는 분류 문제로 구성된다. 다중 클래스 분류일 때 신경 접근법의 성능이 좋다.
슬롯 태깅에서 challenging task는 분류기가 입력 발화의 하위 시퀀스에 대한 semantic class label을 예측하는 시퀀스 분류이다. 그림 4.3에서 모델이 각 단어에 대해 semantic tag를 예측하는 것을 알 수 있다. RNN을 슬롯 태깅에 적용했으며, 입력은 발화의 단어를 one-hot 인코딩한 것이며 conditional random fields, SVM으로 통계적 기준보다 높은 정확도를 얻을 수 있다. (+ a-prior word information, Bi-LSTM, bLSTM) 현재 발화만으로는 모호하거나 중요 정보들이 부족할 수 있다. 이전의 발화를 포함하는 context는 모델의 정확도를 높일 것으로 기대된다. (LSTM)
NLU의 세가지 task가 각각 연구되긴 하지만, 그들을 합쳐서 해결하는 것에는 장점이 있다. 여러 도메인에 대해, 새 도메인에 대한 NLU를 생성할 때 labeled data를 적게 필요로 한다.
새 도메인에 대해 라벨링 비용을 줄이는 방법으로는 zero-shot 학습이 있다. 다른 도메인의 슬롯이, 슬롯의 (텍스트)묘사의 임베딩을 통해 공유된 잠재 의미론적 공간에 표현된다.
Dialogue State Tracking
슬롯 채우기 문제에서 대화 상태에는 대화의 현재 차례에서 사용자가 찾고 있는 모든 정보가 포함된다. 이 상태는 다음 동작을 결정하기 위한 DP(대화 정책)의 입력이다.
예) 레스토랑 도메인에서 대화 상태의 구성 요소
- slot에 값이 할당된 형태의 모든 informable slot에 대한 목표 제약. 값은 "don't care"(사용자가 기본 설정이 없는 경우), "none"(사용자가 아직 값을 지정하지 않은 경우) 등
- 사용자가 시스템에 알리도록 요청한 requested slot의 하위 집합
- 현재 dialogue search 방법 : constraint, alternative, finished. 사용자가 대화 시스템과 상호 작용하는 방법을 인코딩.
과거, DST는 전문가에 의해 생성되거나 conditional random fields와 같은 통계적 학습 알고리즘을 통해 데이터에서 얻을 수 있었다. 최근에는 심층 신경망, 순환 네트워크 등 신경 접근 방식을 사용한다.
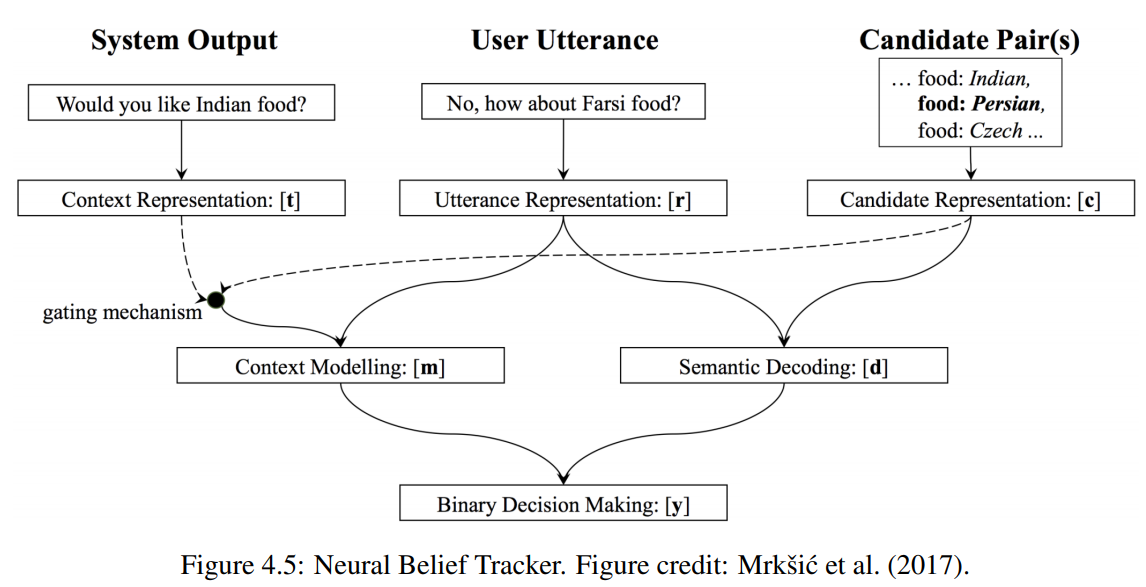
모델은 세 가지 항목을 입력으로 사용한다. 처음 두 개는 가장 마지막의 시스템과 사용자 발화로, 각각은 먼저 내부 벡터 표현에 매핑된다. MLP와 CNN을 기반으로 하는 모델로 representation 학습을 하는데, 이 두 모델은 모두 사전 훈련된 단어 벡터 컬렉션을 활용하고 입력된 발화에 대한 임베딩을 출력한다. 세 번째 입력은 DST에서 추적 중인 모든 슬롯 값 쌍이다. 3개의 임베딩은 (1. 대화의 흐름에서 추가 contextual 정보를 제공하기 위해 context 모델링을, 2. 사용자가 입력 슬롯-값 쌍과 일치하는 의도를 명시적으로 표현했는지를 결정하기 위해 semantic 디코딩을) 하기 위해서 서로 상호작용한다. 컨텍스트 모델링 및 시맨틱 디코딩 벡터는 최종 예측을 생성하기 위해 소프트맥스 계층을 거친다. 모든 가능한 후보 슬롯 값 쌍에 대해 동일한 프로세스가 반복된다.
Sequicity(순차성) 프레임 워크에서 belief spans(믿음 범위, 구간)라고 하는 대화 상태의 다른 표현은, informable slots과 requestable slots 두 개의 필드로 구성된다. 각 필드는 지금까지 대화에서 발견된 각 슬롯의 값을 수집한다. belief span과 sequicity의 주요 이점은, belief span을 입력 및 출력 시스템 응답으로 취하는 대화 시스템을 학습하기 위해 neural seq2seq의 사용을 용이하게 한다는 것이다. 전통적인 파이프라인 접근 방식에 비해 시스템 설계 및 최적화를 크게 단순화한다.
