1. Introduction
대화형 AI는 자연스러운 사용자 인터페이스의 기본이다. 자연어 처리(NLP), 정보 검색(IR) 및 기계 학습(ML) 커뮤니티에서 많은 연구자를 끌어들이고 있는 빠르게 성장하는 분야이다.
- dialogue tasks를 소개하고, open-domain dialogue가 최적의 decision making process로 공식화 되었다고 통일된 관점을 제공
- 2장에서는 기본적인 수학적 도구와 기계 학습 개념을 소개하고 신경 대화 에이전트 개발에 기본이 되는 딥 러닝 및 강화 학습 기술의 최근 진행 상황을 검토
- 3장에서는 knowledge-base QA와 machine reading comprehension(MRC)를 위한 신경 모델에 중점을 둔 QA agent에 대해 설명
- 4장에서는 eep reinfocement learning을 적용한 dialogue management에 초점을 두어 task-oriented dialogue agents를 설명
- 5장에서는 conversational responses의 end-to-end generation의 fully data-driven neural 접근에 초점을 두어 social chatbot에 대해 설명
- 6장에서는 산업에서의 여러 대화 시스템에 대해 간단하게 검토
- 7장에서는 연구 동향에 대한 논의로 마침
Dialogue: What Kinds of Problems?
- question answering : 다양한 데이터 자원에서 끌어온 풍부한 지식을 기반으로 사용자의 query에 대해 간결하고 직접적인 답변을 제공
- task completion : user task를 수행
- social chat : agent는 튜링 테스트처럼 사람같이 user와 원활하고 적절하게 대화하며 유용한 추천(권장사항)을 제공
user가 특정 작업을 달성하는데 도움이 되도록 대화가 수행되는지 여부에 따라 task-oriented와 chitchat 두 카테고리로 그룹화 됌
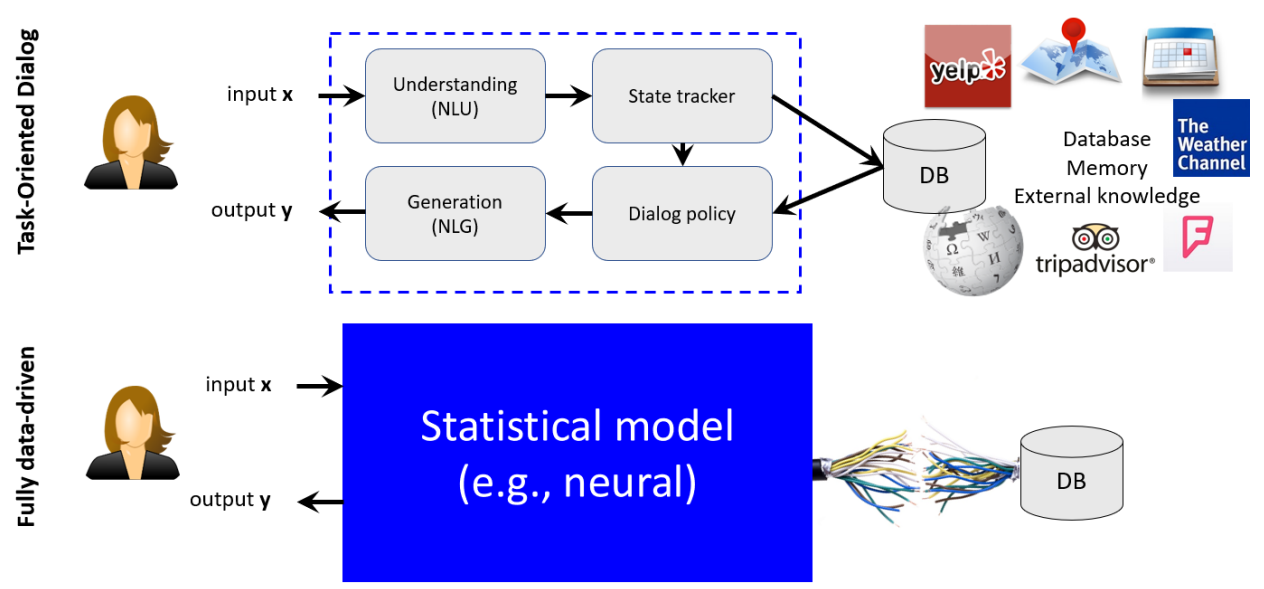
task-oriented agent
전형적으로 4가지 module로 구성
- 사용자 의도를 식별하고 관련 정보를 추출하기 위한 Natural Language Understanding(NLU)
- 지금까지 대화의 모든 중요한 정보를 캡처하는 대화 상태를 추적하기 위한 State Tracker(ST)
- 현재 상태를 기반으로 다음 action을 선택하는 Dialogue Policy(DP)
- 에이전트 action을 자연어 응답으로 변환하기 위한 Natural Language Generatoin(NLG)
최근에는 사용자 입력을 에이전트 출력에 직접 매핑하는 심층 신경망을 사용하여 이러한 모듈을 통합하여 fully data-driven system을 개발하는 경향이 있음
대부분의 task-oriented bot은 모듈식 시스템을 사용하고, bot은 종종 작업을 수행하기 위해 정보를 문의하는 외부 데이터베이스에 액세스할 수 있음
chitchat agent
unitary (non-modular) system 즉 단일(비모듈)
주요 목표는 작업 수행이 아닌, 감정적인 연결을 통해 사람의 AI 동반자가 되는것
많은 양의 사람-사람 대화 데이터를 훈련시킨 DNN-based response generation model을 통해 사람의 대화를 흉내내는 방법으로 개발.
최근에서야 대화를 더 contentful하고 흥미롭게 하기 위해 world knowledge와 이미지에 기반을 둔 방법을 탐구하기 시작함
A Unified View: Dialogue as Optimal Decision Making
의사 결정 process는 계층 구조를 가진다. (top-level process는 특정 subtask에 대해 활성화할 agent를 선택하고, low-level process는 selected agent에게 컨트롤되어 subtask를 수행하기 위한 기본 action들을 선택)
이러한 hierarchical decision making processes는 Markov Decision Processes(MDPs)의 수학적 프레임워크 options에 의해 선택되며 options는 기본 action을 high-level action으로 일반화한다. 기존 MDP setting에서 agnet는 각 시간 step마다 기본 action을 선택한다. option으로, agent는 subtask를 완료하기 위한 기본 작업 스퀀스와 같이 “multi-step” action을 선택한다.
각 option을 action으로 본다면, top 또는 low level process 둘 다 강화학습 framework로 포착할 수 있다. 대화 agent는 개별 단계 시퀀스를 통해 환경과 상호작용하며 MDP안에서 탐색한다. 각 단계에서 agent는 현재 상태를 관찰하고 정책에 따라 action을 선택한다. 그 다음 agent는 보상을 받고 새 상태를 관찰하며 종료할때까지 cycle을 카운트한다. dialogue learning의 목표는 기대 보상을 최대화하는 최적의 policy를 찾는 것이다.
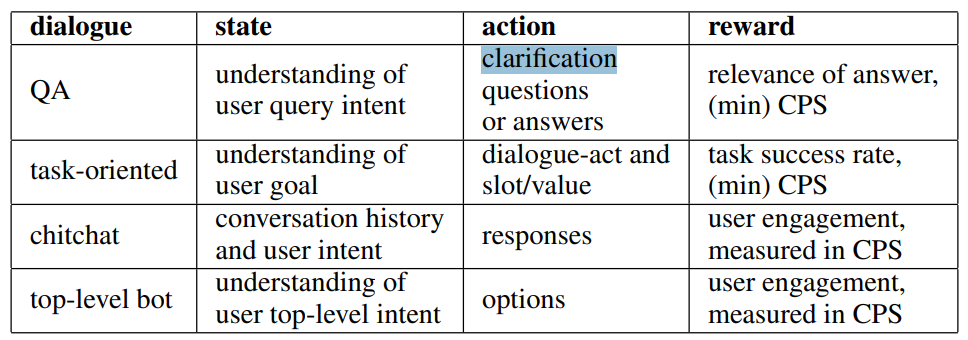
* CPS(=Conversation-turns Per Session = average number of conversation-turns)
dialogue agent가 RL를 사용했을 때, state-action이 문제의 복잡성을 특성 짓고 보상은 최적화된 목적 함수이다.
계층적 MDPs는 large-scale open-domain dialogue system에서 이미 적용되고 있다 : 전반적 대화 과정을 관리하는 master(top-level)와 여러 종류의 대화 요소(subtask)을 다루는 collection of skills(low-level)
CPS에서 모순처럼 보이는(효율적 task completion에서는 CPS를 최소화해야하지만 improving user engagement에서는 CPS를 최대화해야함) 보상 함수는 dailogue system을 개발할때 long-term과 short-term gain을 조절해야함을 알려준다. 예를 들어 XiaoIce는 기대 CPS를 long term으로 최적화한다. task-oriented와 QA 기술을 통합하면 CPS를 최소화해서 사용자들이 task를 보다 효율적으로 달성할 수 있도록 하기 때문에 short-term에서 CPS를 줄일수 있지만, 이 새로운 기술들은 long run에서 XiaoIce를 효율적이고 신뢰할 수 있는 개인 비서로 설정하여 인간 사용자와의 정서적 유대를 강화한다.
RL을 적용하려면 실제 user와 상호작용해서 agent를 교육해야하며 이는 비용이 많이 든다. 따라서, 실제로는 여러 ML 방법의 장점을 결합하여 하이브리드 접근을 한다. 예를 들어 계속 개선하기 위해 RL을 적용하기 전에 imitation과 supervised learning 방법을 사용해서 합리적으로 좋은 agent를 얻는다.
The Transition of NLP to Neural Approaches
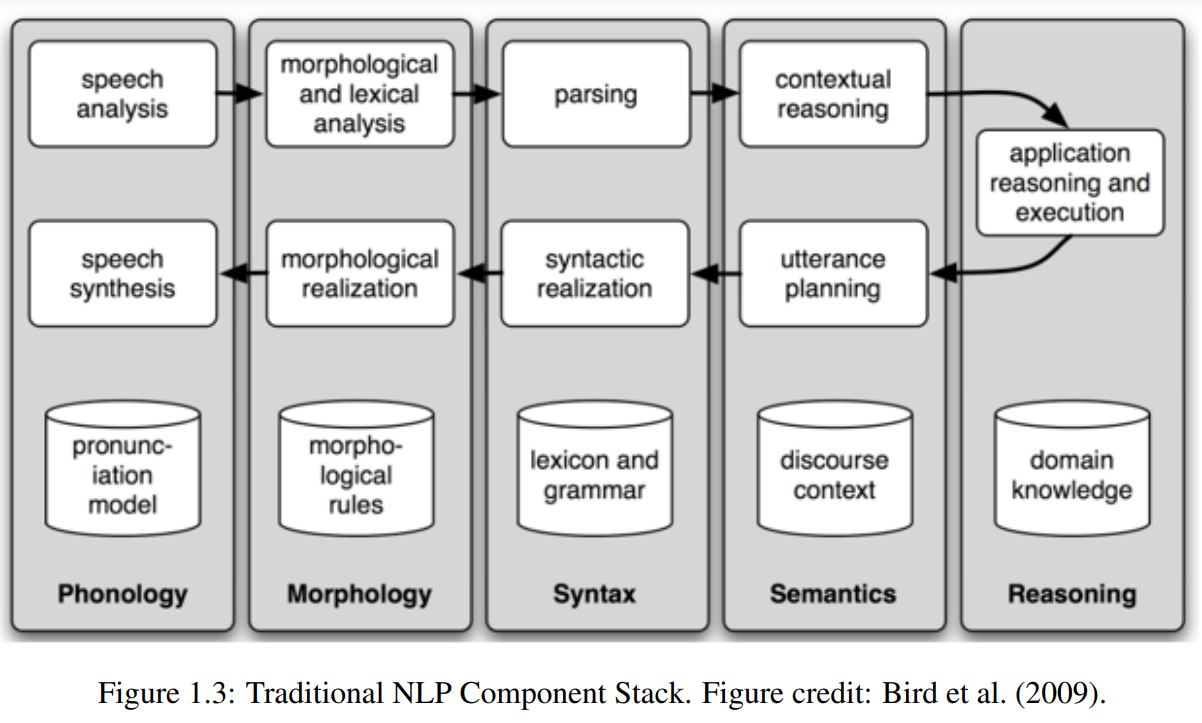
NLP 분야는 과거 대부분 위의 구조를 중심으로 조직되었는데 morphological analysis/parsing과 같은 자연어의 모호함 또는 다양성을, 자연어를 Part-Of-Speech(POS) 태그, context free grammar, fist-order predicate calculus처럼 사람이 정의한 명확하고 상징적인 표현으로 매핑하는 방법들로 해결해왔다. 데이터 기반과 통계학적 접근이 떠오르면서 이러한 요소들은 다양한 machine learning model에 넣을 엔지니어적 자료들로 남고 채택되었다.
신경망적 접근은 사람이 정의한 상징적 표현에 의존하지 않고 특정 작업 지식이 낮은 차원의 연속적 벡터로 의미론적 개념이 명확하게 표현된 특정 작업의 신경망 공간에서 배운다.
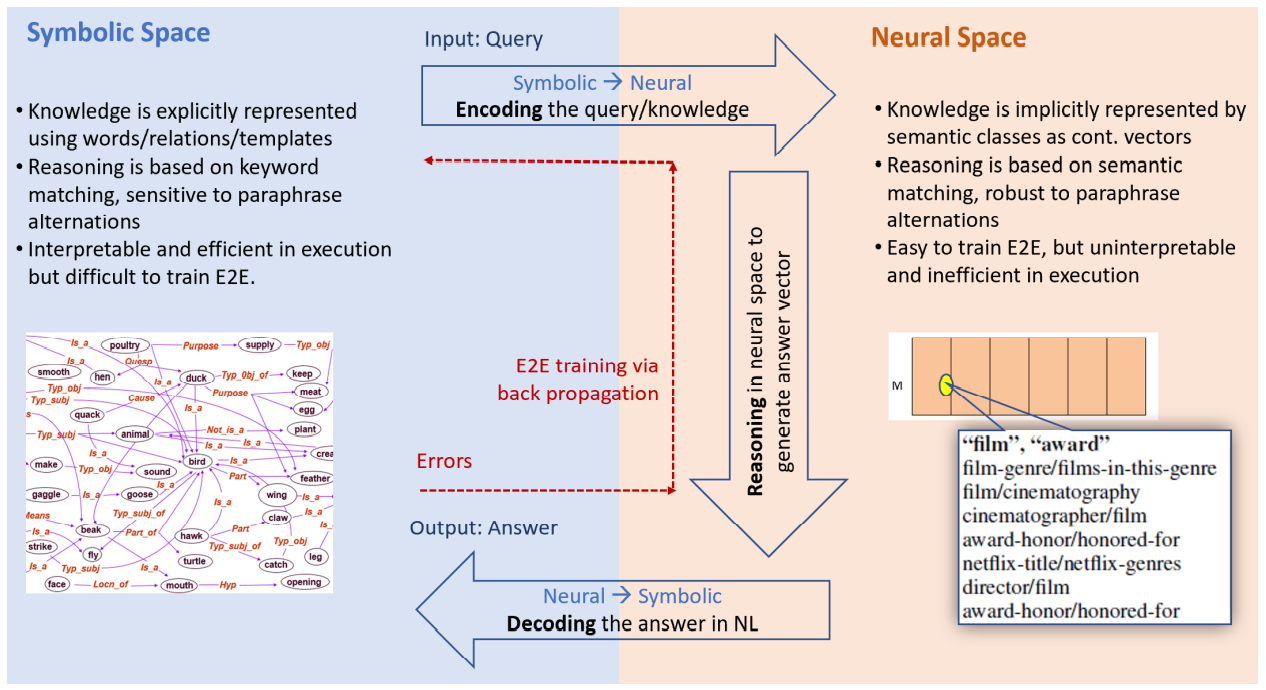
NLP의 신경망 방법은 주로 세가지 단계를 갖는다.
- symbolic user input과 지식을 의미론적으로 연관되거나 비슷한 개념들이 서로 가까운 vector로 표현되는 neural semantic 표현으로 encoding하기
- neural space에서 reasoning(추론)하여 input과 시스템 상태에 기초한 시스템의 response를 생성해내기
- 시스템 response를 symbolic space의 자연어 출력값으로 decoding
인코딩, 추론 및 디코딩은 서로 다른 아키텍처의 신경망으로 구현되며, 모두 back-propagation을 통해 end-to-end fashion으로 훈련된 심층 신경망에 스택된다
end-to-end 훈련은 마지막 응용 시스템과 신경망 구조를 더 탄탄하게 결합하게 해서 morphological(형태학적)분석과 파싱과 같은 NLP 구성 요소간의 경계의 필요성을 줄인다. 이는 아까와 같은 구조를 flatten하고 feature engineering의 필요성을 줄인다. 대신, 초점은 신경망의 더 복잡해지는 구조를 최종 응용 시스템에 맞게 조정하는 것으로 옮겨간다.
신경 접근 방식은 최근에서야, 기존의 구성 요소 기반의 경계를 없애고 좋은 결과를 나타내는 것이 발견되었다. 신경 접근 방식은 동일한 모델 구조에서 언어 및 비언어(이미지, 비디오) feature를 잡아내어 많은 양식에 대해 일관된 표현을 제공한다.
neural과 symbolic 접근 방식의 장점을 모두 결합한 hybrid 방법도 있다. 신경 접근은 end-to-end 방식으로 훈련되고 paraphrase(의역) alternations(교대)에 강건하지만 실행 효율성과 명시적 해석에 약하다. Symbolic 접근은 반대로 훈련이 어렵고 paraphrase alternation에 민감하지만 더 해석 가능하며 실행에 효율적이다.
