단일 video로의 확장
매 frame마다 단일 image에서의 3D human pose estiamtor를 inference?
- motion blur가 심할때는 어려움
단일 image에서는 주변 frame의 정보를 활용할 수 없음 (depth ambiguity, motion blur 등)
⇒ temporal module(LSTM, GRU, GraphCNN, Transformer..) 즉 여러 시간대에서 오는 정보를 조합해주는 모듈
- 단일 frame + 추가적으로 주변 frame의 정보 활용
- 모든 frame을 GPU에 올려야해서 GPU 메모리 부족
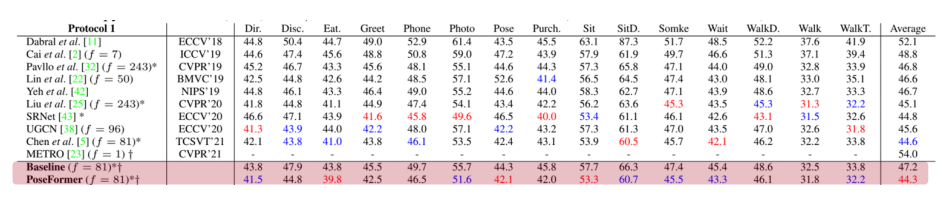
같은 training 데이터 셋을 사용할 경우 video 기반 방법들이 성능이 더 좋음
in-the-wild video 데이터 셋(annotation이 어려워 데이터 셋이 거의 없음, posetrack instavariety)
Input을 2D pose sequence로
- GPU 메모리 부족 문제로 input을 image가 아닌 2D pose로
- 2D pose는 test 단계에서 비교적 정확한 값을 얻을 수 있으며 GPU 메모리 요구량도 image보다 적음
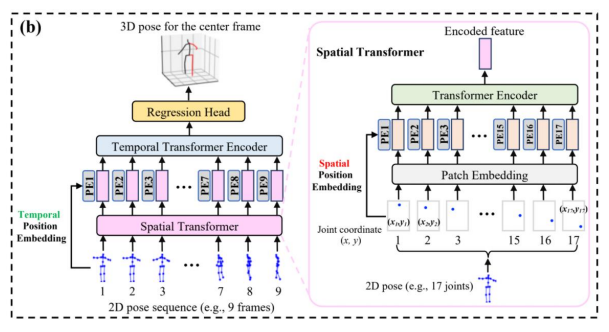
보통 E2E 학습이 가능한 video 기반 3D pose estimation 모델은 input을 2D pose sequence로 받게됨
Input을 image feature vector로
- image feature vector를 단일 image용 pre-trained 3D human pose estimator로 미리 추출하고 저장해둠
- video에서의 3D human pose estimation은 미리 저장해둔 image feature vector를 입력으로 해서 train/test 진행
- 입력이 image feature vector이므로 메모리 문제는 해결하지만 E2E 학습이 불가함

단일 image 기반의 3d pose estimation network를 단일 image dataset에 미리 pre-train해두고, video에 단일 image 3d pose estimation network를 돌려서 image feature를 얻어놓고(예를 들어 Resnet이라면 global average pooling을 통해) vector화 시킴 그 vector를 저장해두고, 그걸 입력으로 사용
단 단일 image 기반의 3d pose estimation network의 backbone은 freezing 되어있음 image feature vector는 이미 추출해두었으니까 ⇒ E2E, data augmentation 불가
