HPE(human pose estimation)은 딥러닝에 의해 크게 발전되었으며 ‘in the wild’ 작업이 소개되고 있다. 동시에 네트워크 구조와 실험들 역시 복잡해지고 있다. 이에 대해 ‘how good could a simple method be?’라는 질문을 던진다.
ResNet은 이미지 feature 추출을 위한 가장 일반적인 backbone 네트워크이다. C5라고 하는 ResNet의 마지막 convolution 단계의 몇 개의 deconvolution layer를 추가한다.
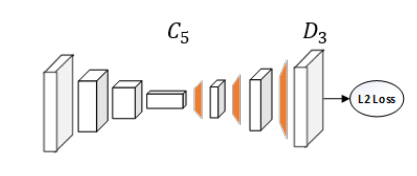
batch normalizatoin과 ReLU activation이 있는 deconvolution layer 3개를 사용한다. 각 layer는 4X4 kernel이 있는 256 filter가 있다. stride는 2이다. 모든 k 키포인트에서 히트맵 {H1 … Hk} 예측을 생성하기 위해 마지막에 1X1 convolutional layer가 더해진다.
예측한 히트맵과 타겟 히트맵 사이 loss를 계산하기 위해 MSE(mean squared error)가 사용된다. 관절 k를 위한 타겟 히트맵 H^k는 k번째 관절의 GT 위치 가운데에 2D gaussian을 더하여 생성한다.
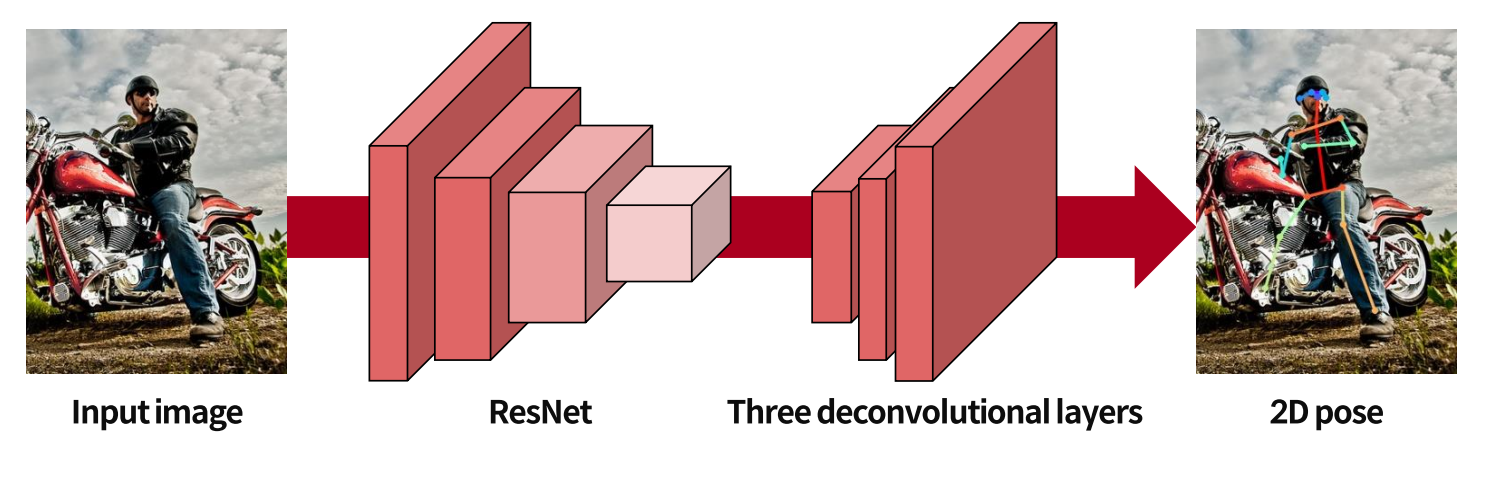
입력 image가 들어가고
ResNet에서 image feature 추출
- 32배 줄어듬
3개의 deconvolutional layers
- (2^3)8배 upsampling하므로
- 4배 줄어드는 걸로 바뀜
포즈 추정
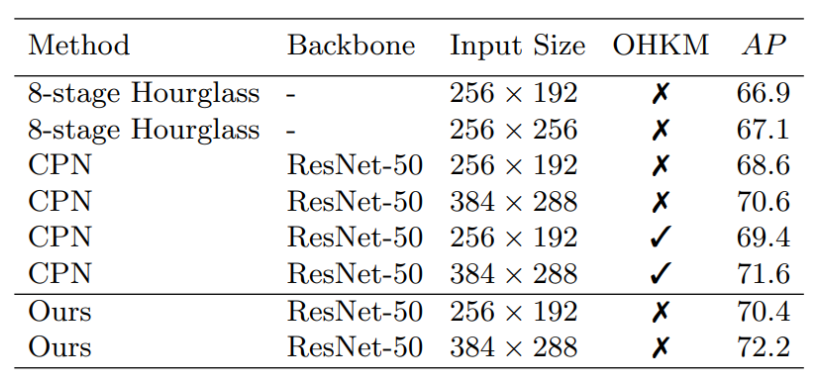
OHKM
- 학습 샘플 마이닝
- training에서 어렵다고 느껴지는 sample의 loss를 크게 줘서 모델이 어려운 case에 집중하게 하는 테크닉
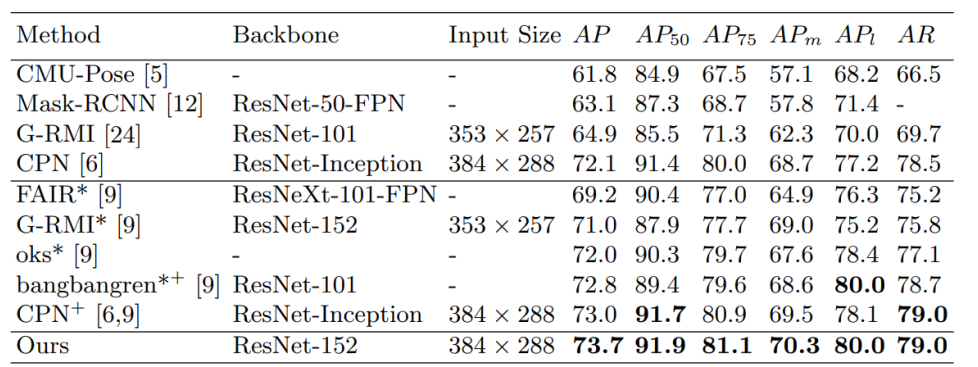
매우 무거운 모델인 CPN보다 높은 성능
기존의 human pose estimation을 위한 backbones(ResNet 등)은 input image를 32배 downsampling
- 예를들어 256x256 image는 8x8 feature map
이러한 downsampling은 저해상도 feature map을 초래함
저해상도 feature map
- 작은 부분들 ( 손목, 발목)이 downsampling으로 인해 없어짐
- Discretization problem(불연속)
- 즉 8x8 feature map의 첫 pixel은 256x256 image에서 1~32번째 픽셀에 해당 ⇒ 1 pixel만 틀려도 32개 pixel이 다 틀리게 됌
