
BasicVSR: The Search for Essential Components in Video Super-Resolution and Beyond
Abstract
비디오 초고해상도(VSR) 접근 방식은 추가의 시간적 차원을 이용해야 하기 때문에 이미지 접근 방식보다 더 많은 구성 요소를 갖는 경향이 있다. 복잡한 설계도 흔하지 않다. 본 연구에서는 전파(Propagation), 정렬(Alignment), 집계(Aggregation), 업샘플링(Upsampling)과 같은 네 가지 기본 기능에 의해 안내되는 VSR의 가장 중요한 구성 요소를 재고하고자 한다. 최소한의 재설계로 추가된 일부 기존 구성 요소를 재사용함으로써, 저자들은 많은 최첨단 알고리즘에 비해 속도와 복원 품질 면에서 매력적인 개선을 달성하는 간결한 파이프라인 BasicVSR을 보여준다. 저자들은 어떻게 그러한 이득을 얻을 수 있는지 설명하고 함정에 대해 토론하기 위해 체계적인 분석을 수행한다. 저자들은 또한 정보 집계를 용이하게 하기 위한 정보 리필 메커니즘(information-refill mechanism)과 결합된 전파 체계(coupled propagation scheme)를 제시함으로써 BasicVSR의 확장성을 보여준다. BasicVSR과 이것의 확장자인 IconVSR은 향후 VSR 접근 방식의 강력한 기준선 역할을 할 수 있다.
1. Introduction
업스케일링 작업을 위해 단일 이미지의 고유 속성에 초점을 맞춘 단일 이미지 초해상도와 비교했을 때, 비디오 초해상도(VSR)는 관련성은 높지만 잘못 정렬된 여러 프레임의 정보를 비디오 시퀀스(video sequences)에 집계하는 것을 수반하기 때문에 추가적인 과제를 안고 있다.
이 문제를 해결하기 위해 다양한 접근 방식이 제안되었다. 일부 설계는 매우 복잡할 수 있다. 예를 들어, 대표적인 방법인 EDVR에서는 여러 프레임의 기능을 정렬 및 통합하기 위해 multiscale deformable alignment module과 multiple attention layers가 채택되었다.
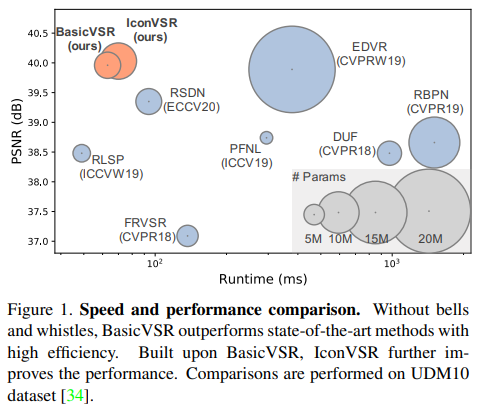 RBPN에서는 여러 개의 투영 모듈을 사용하여 여러 프레임의 기능을 순차적으로 집계한다. 이러한 설계는 효과적이지만 불가피하게 런타임과 모델 복잡성을 증가시킨다(Figure 1 참조). 또한 SISR과 달리 VSR 방법의 잠재적으로 복잡하고 다른 설계는 기존 접근 방식을 구현하고 확장하는데 어려움을 초래하여 재현성과 공정한 비교를 어렵게 만든다. VSR에 대한 보다 일반적이고 효율적이며 구현하기 쉬운 기준선을 찾기 위해 VSR 모델의 다양한 설계를 재고해야 한다. 일반적인 VSR 접근 방식을 기능에 따라 하위 모듈로 분해하여 검색을 시작한다.
RBPN에서는 여러 개의 투영 모듈을 사용하여 여러 프레임의 기능을 순차적으로 집계한다. 이러한 설계는 효과적이지만 불가피하게 런타임과 모델 복잡성을 증가시킨다(Figure 1 참조). 또한 SISR과 달리 VSR 방법의 잠재적으로 복잡하고 다른 설계는 기존 접근 방식을 구현하고 확장하는데 어려움을 초래하여 재현성과 공정한 비교를 어렵게 만든다. VSR에 대한 보다 일반적이고 효율적이며 구현하기 쉬운 기준선을 찾기 위해 VSR 모델의 다양한 설계를 재고해야 한다. 일반적인 VSR 접근 방식을 기능에 따라 하위 모듈로 분해하여 검색을 시작한다.
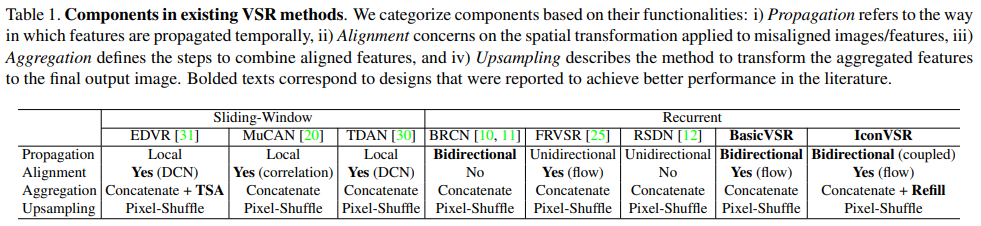 Table 1에 요약된 바와 같이, 대부분의 기존 방법에는 전파(Propagation), 정렬(Alignment), 집계(Aggregation), 업샘플링(Upsampling)과 같은 4가지 상호 관련 요소가 포함된다. 이러한 분해를 통해 각 성분의 다양한 옵션을 체계적으로 연구하여 장단점을 파악할 수 있다.
Table 1에 요약된 바와 같이, 대부분의 기존 방법에는 전파(Propagation), 정렬(Alignment), 집계(Aggregation), 업샘플링(Upsampling)과 같은 4가지 상호 관련 요소가 포함된다. 이러한 분해를 통해 각 성분의 다양한 옵션을 체계적으로 연구하여 장단점을 파악할 수 있다.
광범위한 실험을 통해 기존 옵션을 최소로 재설계하면 멋으로 덧붙이는 부가 기능 없이 VSR의 강력하고 효율적인 기준에 도달할 수 있다는 사실을 발견했다. 본 논문에서는 BasicVSR이라는 이러한 가능성 중 하나를 강조한다. 앞에서 언급한 네 가지 구성요소 중 전파 및 정렬 구성요소를 선택하면 성능과 효율성 측면에서 큰 변화가 일어날 수 있음을 관찰했다. 저자들의 실험은 정보 수집을 최대화하기 위해 양방향 전파 체계(bidirectional propagation scheme) 사용과 feature alignment에 대한 두 인접 프레임 간의 대응성을 추정하기 위해 시각적 흐름 기반 방법(optical flow-based method) 사용을 제안한다. BasicVSR은 일반적으로 채택된 집합을 위한 설계(예: 기능 연결)와 업샘플링(예: 픽셀 셔플)으로 이러한 전파 및 정렬 구성요소를 간소화함으로써 성능(최대 0.61dB)과 효율성(최대 24배 피업) 모두에서 기존 최첨단 기술을 능가한다.
BasicVSR은 단순성과 다양성 덕분에 보다 정교한 네트워크로 확장하기 위한 viable starting point를 제공한다. BasicVSR을 기반으로 하여 집계 및 전파 구성 요소를 개선하기 위한 두 가지 새로운 확장으로 구성된 IconVSR을 제시한다. 첫 번째 확장 이름은 information-refill이다. 이 메커니즘은 추가 모듈을 활용하여 드문드문 선택된 프레임(keyframes)에서 features를 추출한 다음, features를 기본 네트워크에 삽입하여 feature를 개선한다. 두 번째 확장은 정방향 전파 지점과 역방향 전파 지점 간의 정보 교환을 용이하게 하는 coupled propagation scheme이다. 두 모듈은 전파 장애 및 이미지 경계로 인한 전파 중 오류 누적을 줄일 뿐만 아니라 전파가 고품질 기능을 생성하기 위해 전체 정보에 순차적으로 접근할 수 있도록 한다. 이러한 두 가지 새로운 설계를 통해 IconVSR은 최대 0.31dB의 PSNR 개선으로 BasicVSR을 능가한다.
VSR 연구를 중심으로 접근 방식이 증가하고 있다는 점을 감안할 때, 저자들의 작업은 시기적절하다고 생각한다. 강력하고 단순하지만 확장 가능한 기준선이 필요하다. VSR 접근 방식의 주요 기능에 따라 기존 파이프라인의 몇 가지 필수 구성 요소를 재고하고, VSR에 대한 효율적인 기준을 제시한다. 저자들은 간단한 구성 요소가 적절히 통합될 경우 시너지 효과를 발휘하고 최첨단 성능으로 이어질 수 있음을 보여준다. 또한 전파 및 집계 구성 요소를 개선하기 위해 두 개의 새로운 모듈로 BasicVSR을 확장하는 예를 제시한다.
2. Related Work
기존의 VSR 접근 방식은 주로 슬라이딩 윈도우(sliding-window)와 반복(recurrent)의 두 가지 프레임워크로 나눌 수 있다. 슬라이딩 윈도우 프레임워크의 이전 방법은 저해상도(LR) 프레임 사이의 시각적 흐름을 예측하고 정렬을 위한 공간 왜곡을 수행한다. 이후 접근 방식은 암시적 정렬(implicit alignment)의 보다 정교한 접근 방식에 의존한다. 예를 들어, TDAN은 변형 가능한 컨볼루션(DCN)을 채택하여 feature level에서 서로 다른 프레임을 정렬한다. EDVR은 DCN을 다중 스케일 방식으로 사용하여 보다 정확한 정렬을 제공한다. DUF는 동적 업샘플링 필터를 활용하여 동작을 암시적으로 처리한다. 일부 접근 방식은 반복적인 프레임워크를 채택한다. RSDN은 외관 변화와 오류 누적에 대한 견고성을 향상시키기 위해 반복 상세 구조 블록과 숨겨진 상태 적응 모듈을 제안한다. RRN은 identity skip connection이 있는 레이어 간의 잔여 매핑을 채택하여 유연한 정보 흐름을 보장하고, 장기간 texture 정보를 보존한다. 앞서 언급한 연구로 인해 VSR의 전파 및 정렬 문제를 해결하기 위한 새롭고 정교한 구성 요소가 많이 등장했다. 여기서는 일부 구성 요소를 재조사하여 단순한 시각적 흐름 기반 기능 정렬과 결합된 양방향 전파가 많은 최첨단 방법을 능가하기에 충분하다는 것을 알아냈다.
IconVSR의 정보 리필 메커니즘은 간격 기반 처리(interval-based processing) 개념을 연상시킨다. 이러한 방법은 비디오 프레임을 keyframes와 non-keyframes로 구분하는 독립적인 간격으로 나눈다. 그런 다음 keyframes와 non-keyframes는 서로 다른 파이프라인에 의해 처리된다. 예를 들어, FAST는 SRCNN을 super-resolve keyframes에 적용한다. 그런 다음 non-frames는 압축 비디오 코덱에 저장된 확장 keyframes와 모션 벡터를 사용하여 복원된다. IconVSR은 keyfreames의 개념을 계승하지만 간격을 일정하게 처리하는 기존 방법과 달리 전파 분기(propagation branches)를 통해 간격을 연결하여 한 단계 발전시켰다. 이러한 설계를 통해 장기 정보가 상호 연결된 간격으로 전파되어 효율성이 더욱 향상된다.
3. Methodology
비디오 초해상도는 본질적으로 길고 복잡한 처리 파이프라인을 포함한다. 공간 차원뿐만 아니라 시간 차원에서도 정보를 수집해야 하기 때문이다. 기존 연구는 일반적으로 발전을 위한 기능의 한 측면에 초점을 맞추고 있으며, 다양한 구성요소의 시너지를 집단적으로 고려하지 않을 수 있다. 거시적으로 다양한 구성 요소를 다시 살펴보고, 기존 접근 방식의 장점을 계승하는 일반적인 기준선을 찾아야 한다. 본 연구에서는 광범위한 분석을 수행하고, 설계의 유연성이 풍부한 backbone 역할을 할 수 있는 단순하고 강력하며, 다용도의 기준선인 BasicVSR을 제시한다.
3.1 BasicVSR
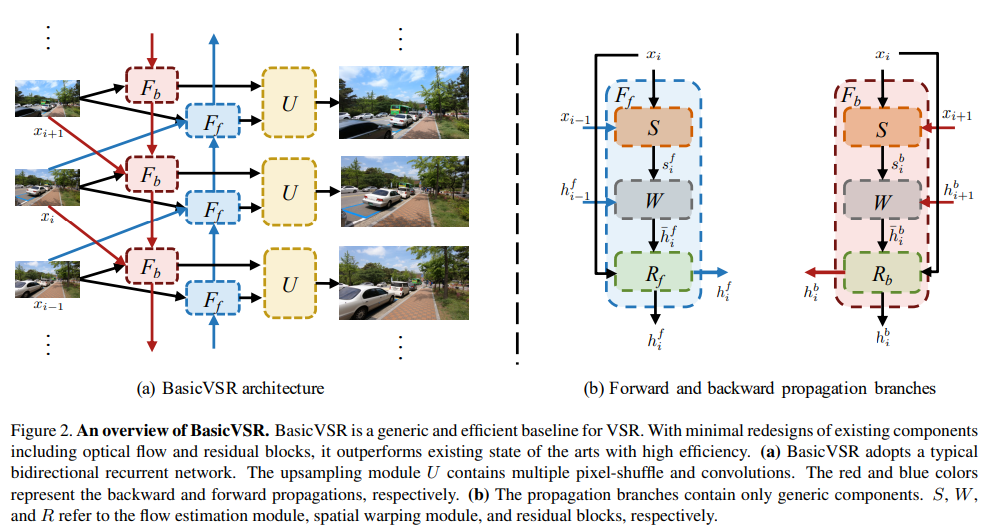
VSR 방법의 분석과 개발을 촉진하기 위한 일반적인 프레임워크를 발견하는 것을 목표로, 저자들은 자신들의 search를 시각적 흐름과 잔여 블록과 같은 일반적으로 채택된 요소로 한정한다. BasicVSR의 개요는 Figure 2에 나와 있다.
Propagation. Propagation은 VSR에서 가장 영향력 있는 구성 요소 중 하나이다. 비디오 시퀀스의 정보를 활용하는 방법을 지정한다. 기존 전파 체계(propagation schemes)는 로컬(local), 단방향(unidirectional), 양방향(bidirectional) 전파의 세 가지 주요 그룹으로 나눌 수 있다. 다음 내용에서는 BasicVSR에서 양방향 전파를 선택한 동기를 부여하는 두 가지 약점에 대해 논의한다.
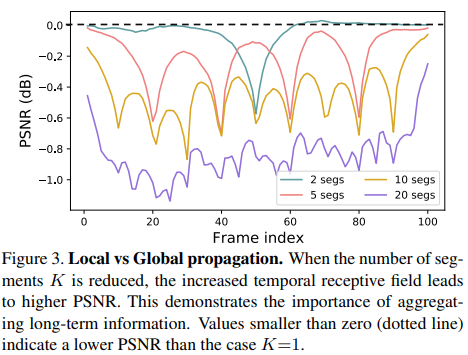
-
Local Propagation. 슬라이딩 윈도우 방법(sliding-window methods)은 로컬 윈도우 내의 LR 이미지를 입력으로 받아들이고, 복원을 위해 로컬 정보를 사용한다. 이 설계에서 접근 가능한 정보는 로컬 지역에서 제한된다. 원거리 프레임의 누락으로 인해 슬라이딩 윈도우 방법의 가능성이 불가피하게 제한된다. 저자들의 주장을 확인하기 위해, 저자들은 (시간적 차원의) 글로벌 수용 장(global receptive field)부터 시작하여 수용 장(receptive field)을 점차 줄여나간다. 테스트 시퀀스를 K 세그먼트로 분리하고, BasicVSR을 사용하여 각 세그먼트를 독립적으로 복원한다. 사례 K=1(global propagation)에 대한 PSNR 차이는 그림 3에 나와 있다.
첫째, 세그먼트 수가 감소하면 PSNR의 차이(즉, 성능 개선)가 감소한다(즉, temporal receptive field 증가). 이는 멀리 떨어진 프레임에 있는 정보가 복구에 유용하며 무시되어서는 안 된다는 것을 의미한다. 둘째, PSNR의 차이는 각 세그먼트의 양쪽 끝에서 가장 크며, 장기 정보를 축적하기 위해 긴 시퀀스를 채택할 필요성을 나타낸다.
-
Unidirectional Propagation. 앞서 언급한 문제는 정보가 첫 번째 프레임에서 마지막 프레임으로 순차적으로 전파되는 단방향 전파(unidirectional propagation)를 채택함으로써 해결할 수 있다. 그러나 이 설정에서는 서로 다른 프레임에서 수신되는 정보가 불균형하다. 특히, 첫 번째 프레임은 자신을 제외하고 비디오 시퀀스로부터 정보를 수신하지 않는 반면, 마지막 프레임은 전체 시퀀스로부터 정보를 수신한다. 따라서 이전 프레임에 대해서는 차선의 결과가 예상된다. 효과를 입증하기 위해 BasicVSR(양방향 전파 사용)을 단방향 변형(비슷한 네트워크 복잡성)과 비교한다. Figure 4에서 단방향 모델이 초기 시간 단계에서 양방향 전파보다 상당히 낮은 PSNR을 얻으며 프레임 수의 증가에 따라 더 많은 정보가 집계될수록 그 차이는 점차 감소한다는 것을 볼 수 있다. 또한, 0.5dB의 일관된 성능 하락은 부분적인 정보만 사용한 상태에서 관찰된다. 이러한 관찰은 단방향 전파의 suboptimality를 보여준다. 시퀀스의 마지막 프레임에서 정보를 다시 전파하여 출력 품질을 향상시킬 수 있다.
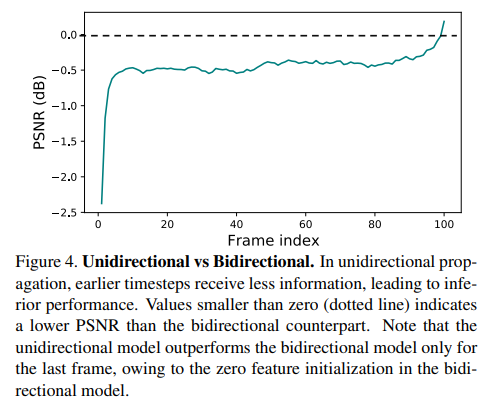
-
Bidirectional Propagation. 위의 두 가지 문제는 양방향 전파를 통해 동시에 해결할 수 있다. 양방향 전파에서는 기능이 시간에 따라 앞뒤로 독립적으로 전파된다. 이에 동기가 부여된 BasicVSR은 일반적인 양방향 전파 체계를 채택한다.
LR 이미지 , 인접 프레임 및 및 인접 프레임에서 전파된 해당 기능( 및 로 표시)을 고려할 때, = , = , 가 있다. 여기서 와 는 각각 후방 및 전방 전파 분기를 나타낸다.
Alignment. 공간 정렬은 VSR에서 중요한 역할을 한다. VSR은 연관성이 높지만 후속 집계를 위해 잘못 정렬된 이미지/features를 정렬한다. 메인스트림 작업은 정렬 없음(without alignment), 이미지 정렬(image alignment), 형상 정렬(feature alignment)의 세 가지 범주로 나눌 수 있다. 이번 섹션에서는 각 범주를 분석하고 선택한 기능 정렬을 검증하기 위한 실험을 수행한다.
- Without Alignment. 기존의 반복 방법은 일반적으로 전파 중에 정렬을 수행하지 않는다. 정렬되지 않은 features/이미지는 집계를 방해하고, 결국 표준 이하의 성능으로 이어진다. 이러한 suboptimality는 BasicVSR에서 공간 정렬 모듈을 제거하는 실험에 반영될 수 있다. 이 경우 non-aligned features를 복원하기 위해 직접 연결한다. 적절한 정렬이 없으면 전파된 기능이 입력 이미지와 공간적으로 정렬되지 않는다. 결과적으로 상대적으로 수용 영역이 작은 컨볼루션과 같은 로컬 운영은 해당 위치에서 정보를 수집하는 데 비효율적이다. PSNR이 1.19dB 정도 떨어짐이 관찰된다. 이러한 결과는 원거리 공간 위치에서 정보를 수집할 수 있을 만큼 수용 범위가 넓은 운영 방식을 채택하는 것이 중요하다는 것을 시사한다.
- Image Alignment. 이전 작업은 복원 전에 시각적 흐름을 계산하고 이미지를 뒤틀어 정렬을 수행한다. 최근 Chan 등은 공간 정렬을 image level에서 feature level로 이동하면 눈에 띄게 개선된다는 것을 보여준다. 본 연구에서는 그들의 주장을 입증하기 위한 실험을 추가로 실시한다. BasicVSR의 변형에서 image warping과 feature warping을 비교한다. 시각적 흐름 추정의 부정확성으로 인해 warped image는 필연적으로 흐릿함과 부정확함에 시달린다. 세부 정보의 손실은 저하된 출력(outputs)으로 이어진다. 본 실험에서 이미지 정렬을 채택할 때 0.17dB의 떨어짐이 관찰된다. 이 관찰을 통해 공간 정렬을 feature level로 이동해야 할 필요성이 확인되었다.
- Feature Alignment. 제거/이미지 정렬 성능이 저조하기 때문에 feature 정렬에 의존하게 된다. 흐름 기반 방법과 유사하게, BasicVSR은 공간 정렬을 위해 시각적 흐름을 채택한다. 하지만 이전 작품에서와 같이 warping 이미지 대신, 성능을 향상시키기 위해 feature에서 warping을 수행한다. 정렬된 features는 세분화를 위해 여러 잔차 블록으로 전달된다. 공식적으로,
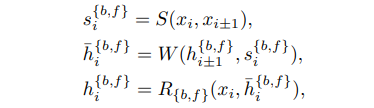 와 = 가 있다. 여기서 와 는 각각 흐름 추정(flow estimation) 및 공간 뒤틀림 모듈(spatial warping modules)을 나타내며, 는 잔차 블록의 stack을 나타낸다.
와 = 가 있다. 여기서 와 는 각각 흐름 추정(flow estimation) 및 공간 뒤틀림 모듈(spatial warping modules)을 나타내며, 는 잔차 블록의 stack을 나타낸다.
Aggregation and Upsampling. BasicVSR은 집계 및 업샘플링을 위한 기본 구성 요소를 채택한다. 특히 중간 features 가 주어지면 output HR 이미지를 생성하기 위해 여러 개의 컨볼루션과 픽셀 셔플로 구성된 업샘플링 모듈을 사용한다.
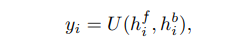 여기서 는 업샘플링 모듈을 나타낸다.
여기서 는 업샘플링 모듈을 나타낸다.
Summary of BasicVSR. 위의 분석은 BasicVSR의 설계 선택에 동기를 부여한다. 전파를 위해 BasicVSR은 장기(long-term) 및 전역(global) 전파에 중점을 둔 양방향 전파를 선택했다. 정렬의 경우 BasicVSR은 단순한 흐름 기반 정렬을 채택하지만 feature level에서 이루어진다. 집계 및 업샘플링의 경우 feature concatenation 및 pixel-shuffle에 대한 일반적인 선택으로 충분하다. 간단하고 간결한 방법임에도 불구하고, BasicVSR은 복원 품질과 효율성 모두에서 뛰어난 성능을 발휘한다. 또한 BasicVSR은 더 어려운 시나리오를 처리하기 위해 추가 구성 요소를 쉽게 수용할 수 있기 때문에 매우 다용도적이다.
3.2. From BasicVSR to IconVSR
BasicVSR을 backbone으로 사용하여 전파 중 오류 누적을 완화하고 정보 집계를 용이하게 하기 위해 Information-Refill 메커니즘과 결합 전파(IconVSR)라는 두 가지 새로운 구성 요소를 도입했다.
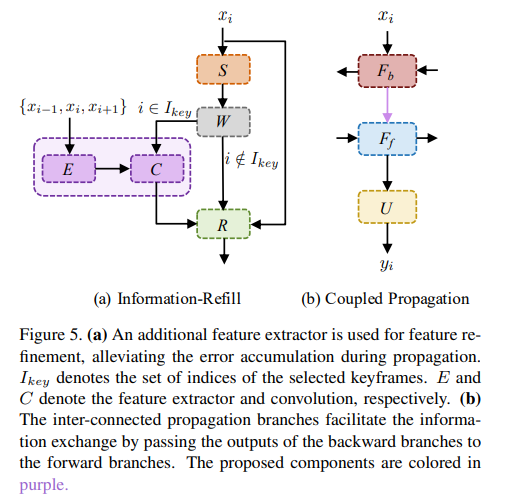 Information-Refill. 가려진 영역과 이미지 경계에서 부정확한 정렬은 특히 프레임워크에서 장기 전파를 채택할 경우 오류 축적을 초래할 수 있는 중요한 과제이다. 이러한 잘못된 features로 인한 바람직하지 않은 영향을 완화하기 위해 feature 개선을 위한 정보 리필 메커니즘(information-refill mechanism)을 제안한다.
Information-Refill. 가려진 영역과 이미지 경계에서 부정확한 정렬은 특히 프레임워크에서 장기 전파를 채택할 경우 오류 축적을 초래할 수 있는 중요한 과제이다. 이러한 잘못된 features로 인한 바람직하지 않은 영향을 완화하기 위해 feature 개선을 위한 정보 리필 메커니즘(information-refill mechanism)을 제안한다.
Figure 5(a)와 같이, 입력 프레임(keyframes)의 하위 집합과 각 이웃에서 deep features를 추출하기 위해 추가적인 feature extractor가 사용된다. 그런 다음 추출된 형상이 컨볼루션으로 정렬된 형상 와 융합된다.
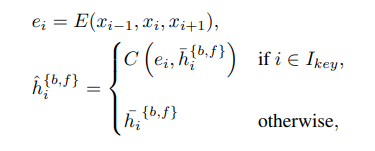 여기서 E와 C는 각각 feature extractor와 컨볼루션에 해당한다. 는 선택한 keyframes의 인덱스 집합을 나타낸다. 그런 다음 정제된 형상이 잔차 블록으로 전달되어 정밀도를 더욱 높인다.
여기서 E와 C는 각각 feature extractor와 컨볼루션에 해당한다. 는 선택한 keyframes의 인덱스 집합을 나타낸다. 그런 다음 정제된 형상이 잔차 블록으로 전달되어 정밀도를 더욱 높인다.
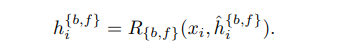 feature extractor와 feature fusion은 드문드문 선택된 keyframes에만 적용된다는 점이 주목할 만하다. 따라서, 정보 리필 메커니즘으로 인한 계산 부담은 미미하다. 정보 리필은 keyframes의 개념을 계승하지만, 독립 처리를 위한 간격을 분리하는 기존의 간격 기반 방법(interval-based methods)과 달리 IconVSR의 간격(keyframkes로 구분)은 전역 정보 전파를 유지하기 위해 연결되어 있다.
feature extractor와 feature fusion은 드문드문 선택된 keyframes에만 적용된다는 점이 주목할 만하다. 따라서, 정보 리필 메커니즘으로 인한 계산 부담은 미미하다. 정보 리필은 keyframes의 개념을 계승하지만, 독립 처리를 위한 간격을 분리하는 기존의 간격 기반 방법(interval-based methods)과 달리 IconVSR의 간격(keyframkes로 구분)은 전역 정보 전파를 유지하기 위해 연결되어 있다.
Coupled Propagation. 양방향 설정에서 featues는 일반적으로 두 개의 반대 방향으로 독립적으로 전파된다. 이 설계에서 각 전파 branch의 features는 이전 프레임 또는 미래 프레임의 부분 정보를 기반으로 계산된다. 시퀀스의 정보를 이용하기 위해, 저자들은 전파 모듈이 상호 연결되는 결합 전파 체계(coupled propagation scheme)를 제안한다. Figure 5(b)에서와 같이, 결합된 전파에서 역방향 전파 는 전방 전파 모듈의 입력으로 사용된다.
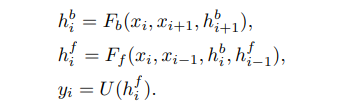 결합된 전파를 통해 정방향 전파 branch는 과거 프레임과 미래 프레임 모두에서 정보를 수신하여 더 높은 품질과 더 나은 출력을 제공한다. 더욱 중요한 것은 결합된 전파는 branch 연결의 변경만 요구하기 때문에 계산 오버헤드(computational overhead)를 유발하지 않고도 성능 향상을 얻을 수 있다는 것이다.
결합된 전파를 통해 정방향 전파 branch는 과거 프레임과 미래 프레임 모두에서 정보를 수신하여 더 높은 품질과 더 나은 출력을 제공한다. 더욱 중요한 것은 결합된 전파는 branch 연결의 변경만 요구하기 때문에 계산 오버헤드(computational overhead)를 유발하지 않고도 성능 향상을 얻을 수 있다는 것이다.
4. Experiments
Datasets and Settings training에 널리 사용되는 두 데이터 세트인 REDS와 Vimeo-90K를 고려한다. REDS의 경우 REDS4 datset을 test set으로 사용한다. 또한 REDsval4를 validation set으로 정의한다. 나머지 clip들은 training용으로 사용된다. Vide4, UDM10, Vimeo-90K-T를 Vimeo-90K와 함께 test set으로 사용한다. 저자들은 바이큐빅(BI)과 블러 다운샘플링(BD)의 두 가지 degradations를 사용하여 4배 다운샘플링을 통해 모델을 테스트한다. 사전 학습된 SPyNet과 EDVR-M4를 각각 흐름 추정 모듈 및 feature extractor로 사용한다. Adam optimizer와 Cosine Annealing 방식을 채택했다. feature extractor와 흐름 추정기의 초기 학습 속도는 각각 와 로 설정된다. 다른 모든 모듈의 학습 속도는 로 설정된다. 총 반복 횟수는 300K이며, feature extractor와 흐름 추정기의 가중치는 처음 5,000회 반복 동안 고정된다. batch size는 8이고, 입력 LR 프레임의 patch size는 64×64이다. outliers를 더 잘 처리하고, 기존의 loss보다 성능을 향상시키므로 Charbonnier loss를 사용한다. 자세한 실험 설정은 부록에 나와 있다.
4.1. Comparisons with State-of-the-Art Methods
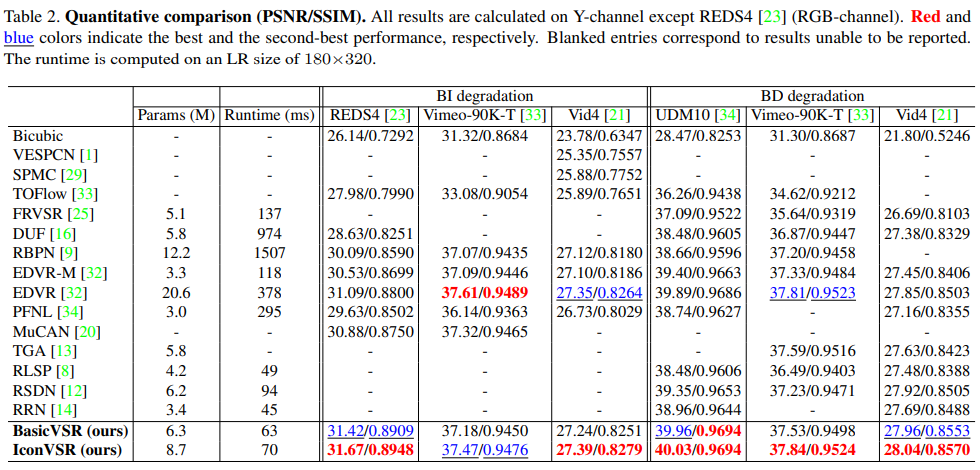
BasicVSR과 IconVSR을 14개 모델(VESPCN, SPMC, TOFlow, FRVSR, DUF, RBPN, EDVR, MuCAN, PFNL, RLSP, TGA, RSD)과 비교하여 종합적인 실험을 수행한다. 정량적 결과는 Table 2에 요약되어 있고, 속도 및 성능 비교는 Figure 1에 나와 있다. BasicVSR과 IconVSR의 파라미터는 시각적 흐름 네트워크인 SPyNet의 파라미터를 포함한다. 그래서 비교는 공정하다.
BasicVSR BasicVSR은 REDS4, UDM10 및 Vid4를 포함한 다양한 dataset에서 기존 SOTA(state of the arts)를 능가한다. BasicVSR은 복원 품질의 향상과 더불어 높은 효율성을 보여준다. Figure 1에서와 같이, BasicVSR은 비슷한 수의 파라미터를 가지면서도 UDM10에서 RSDN을 0.61dB 능가한다. 훨씬 더 큰 복잡성을 가진 EDVR과 비교할 때, BasicVSR은 REDS4에서 0.33dB의 향상된 성능을 얻고, Vimeo-90K-T 및 Vid4에서 경쟁 성능을 발휘한다. Vimeo-90K-T에서 BasicVSR의 성능은 EDVR 및 TGA와 같은 슬라이딩 윈도우 방식으로 달성한 성능보다 약간 낮다. Vimeo-90K T에는 7개의 프레임만 있는 시퀀스가 포함되어 있으며, BasicVSR의 성공은 부분적으로 장기 정보 수집(사실적 가정)에서 비롯되기 때문에 이러한 결과가 예상된다.
IconVSR IconVSR은 약간 더 긴 런타임을 통해 BasicVSR에 비해 최대 0.31dB까지 성능을 향상시킨다. 성능 향상은 Vimeo-90KT 및 REDS4에서 특히 두드러지며, 제안된 결합 전파 및 정보 리필 메커니즘이 장기 정보(Vimeo-90K-T)가 부족한 비디오와 크고 복잡한 동작(REDS4)이 포함된 비디오에서 유용하다. 전반적으로, BasicVSR과 IconVSR 모두 대부분의 SOTA보다 빠르면서도 뛰어난 성능을 달성할 수 있다.
질적 비교는 Figure 11과 12에 나와 있다. BasicVSR 및 IconVSR은 세부 정보와 더 선명한 모서리(shaper edges)를 복구할 수 있다. 예를 들어, BasicVSR과 IconVSR만이 Figure 11의 선명한 정사각형 패턴과 Figure 12의 수직 스트립 패턴(vertical strip patterns)을 성공적으로 복구한다. IconVSR은 제안된 구성 요소를 사용하여 가장자리가 더 선명한 이미지를 재구성할 수 있다. 더 많은 예는 부록에 나와 있다.
5. Ablation Studies
5.1. From BasicVSR to IconVSR
Information-Refill. 우리는 정보 이전과 이후의 특징을 질적으로 시각화하여 메커니즘에 대한 통찰력을 얻는다. Figure 8(a)에서와 같이 정보 리필 전에 warped feature의 경계 픽셀은 존재하지 않는 대응(non-existing correspondences)으로 인해 기본적으로 0이 된다. 정보가 손실되면 불가피하게 feature 품질이 악화되어 이는 저하된 output으로 이어진다. 정보 리필 메커니즘을 사용하면 feature가 제대로 정렬되지 않은 지역에서 손실된 정보를 "리필"하는 데 추가 feature를 사용할 수 있다. 그런 다음 검색된 정보를 다음 feature 세분화 및 전파에 사용할 수 있다.

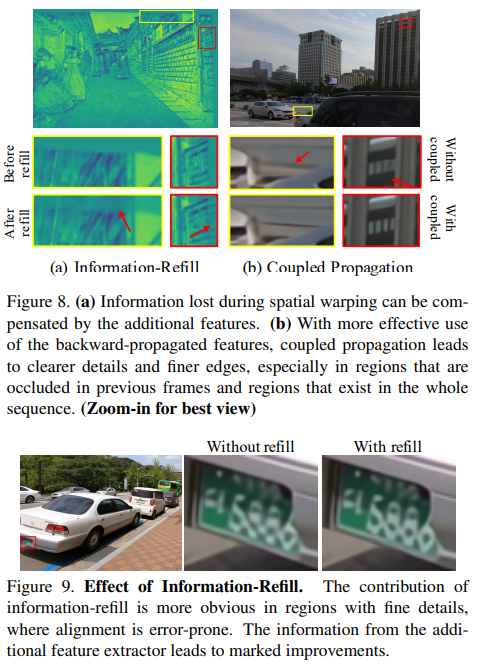
위의 효과는 특히 세부사항이 있는 지역에서 두드러진다. 이러한 영역에서는 정렬 오류로 인해 인접 프레임의 정보를 효과적으로 집계할 수 없어 품질이 저하되는 경우가 많다. 정보 리필을 통해 추가 features는 세부 사항의 복원을 지원하여 품질 향상으로 이어진다. 예를 들어, Figure 9에 표시된 것처럼 차량 번호판 번호는 리필 메커니즘을 통해 더 명확하게 재구성할 수 있다.
Coupled Propagation. 결합된 전파 체계를 줄이기 위해 정보 리필 메커니즘을 비활성화하고 IconVSR을 BasicVSR과 비교한다. Figure 8(b)에서 노란색 상자는 이전 프레임에 가려진 영역을 나타내며, BasicVSR의 전방 전파 branch는 해당 영역의 정보를 수신할 수 없다. 빨간색 상자는 시퀀스의 모든 프레임에 존재하는 영역을 나타내므로 해당 영역의 풍부한 "스냅샷"을 후자 프레임에서 찾을 수 있다. 결합된 전파를 사용하면 역방향 전파 기능이 보다 효과적으로 사용되므로 보다 상세하고 미세한 모서리를 재구성할 수 있다. BasicVSR에 대한 PSNR 개선은 Table 3에 요약되어 있다.
5.2. Tradeoff in IconVSR
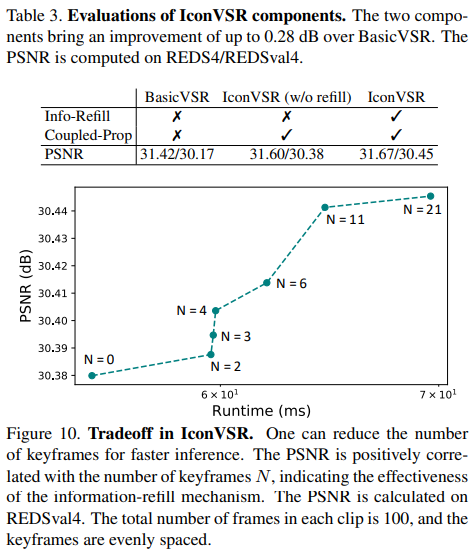
IconVSR은 고정된 키프레임 간격으로 학습되지만, 더 빠른 추론을 위해 keyframes 수를 줄일 수 있다. 서로 다른 수의 keyframe을 사용하는 PSNR은 Figure 10에 나타나 있다. 여기서 PSNR은 keyframe의 수와 긍정적인 상관관계가 있음을 알 수 있으며, 정보 리필 메커니즘의 contributions를 검증한다. keyframe이 없는 극단적인 경우 IconVSR은 반복 네트워크로 퇴보한다. 그럼에도 불구하고, 그것은 여전히 BasicVSR보다 0.21dB 높은 REDsval4에서 30.38dB의 PSNR을 달성한다. 이는 추가적인 계산 오버헤드를 도입하지 않고도 사용할 수 있는 결합된 전파 체계의 효과를 보여준다.
6. Conclusion
이 작업은 VSR 접근 방식의 분석 및 확장을 용이하게 하기 위해 일반적이고 효율적인 VSR 기준선을 검색하는 데 집중한다. 기존 요소의 분해 및 분석을 통해 기존 SOTA를 높은 효율로 능가하는, 단순하면서도 효과적인 네트워크인 BasicVSR을 제안한다. 저자들은 BasicVSR을 기반으로 하며 성능을 더욱 향상시키기 위해 두 가지 새로운 구성 요소를 가진 IconVSR을 제안한다. BasicVSR 및 IconVSR은 향후 작업의 강력한 기준 역할을 할 수 있으며, 아키텍처 설계에 대한 발견은 잠재적으로 비디오 디블러링, 노이즈 제거 및 컬러화와 같은 다른 low level 비전 작업으로 확장될 수 있다.
