SWAGAN: A Style-based WAvelet-driven Generative Model
Abstract
최근 몇 년간 GAN(Generative Adversarial Networks)의 시각적 품질에 상당한 진전이 있었다. 그럼에도 불구하고, 이러한 네트워크들은 여전히 눈에 띄게 편향된 구조와 좋지 않은 손실 함수로 인한 고주파 콘텐츠(high frequency content)의 품질 저하로 어려움을 겪고 있다. 이 문제를 해결하기 위해 주파수 영역(frequency domain)에서 점진적 생성을 구현하는 새로운 범용 스타일과 wavelet 기반의 GAN(SWAGAN)을 제시한다. SWAGAN은 Generator와 Discriminator 구조 전체에 wavelet을 통합하여 모든 단계에서 주파수 인식 잠재 표현(frequency-aware latent representation)을 적용한다. 이 접근 방식은 생성된 이미지의 시각적 품질을 향상시키고 계산 성능을 크게 향상시킨다. SyleGAN2 프레임워크에 통합하고 wavelet 영역에서 content 생성이 더욱 사실적인 고주파 콘텐츠의 고품질 이미지로 이어진다는 것을 확인함으로써 이 방법의 장점을 입증한다. 또한, 저자들은 모델의 잠재 공간에서 StyleGAN이 다수 editing tasks의 기반이 될 수 있는 품질을 유지하고 있는지 확인하고, 주파수 인식 접근 방식이 개선된 downstream visual quality를 유도한다는 것을 보여준다.
 (Figure 1. 이미지나 특징 공간이 아닌 wavelet 영역에서 직접 작업함으로써 신경망의 스펙트럼 편향을 완화하고 다른 모델이 실패하는 고주파 데이터를 성공적으로 생성할 수 있다. 저자들의 모델은 StyleGAN2와 같은 SOTA 모델을 벗어난 패턴을 만들 수 있다. 심지어 Training set이 단일 이미지만 포함하는 over-fitting setup에서도 사용할 수 있다. 저자들은 (왼쪽에서 오른쪽으로) 원본 이미지와 StyleGAN2의 output, SWAGAN의 output을 보여준다. 각 StyleGAN2와 SWAGAN의 output은 해당 이미지에 대해 24시간 동안 학습한 것이다.)
(Figure 1. 이미지나 특징 공간이 아닌 wavelet 영역에서 직접 작업함으로써 신경망의 스펙트럼 편향을 완화하고 다른 모델이 실패하는 고주파 데이터를 성공적으로 생성할 수 있다. 저자들의 모델은 StyleGAN2와 같은 SOTA 모델을 벗어난 패턴을 만들 수 있다. 심지어 Training set이 단일 이미지만 포함하는 over-fitting setup에서도 사용할 수 있다. 저자들은 (왼쪽에서 오른쪽으로) 원본 이미지와 StyleGAN2의 output, SWAGAN의 output을 보여준다. 각 StyleGAN2와 SWAGAN의 output은 해당 이미지에 대해 24시간 동안 학습한 것이다.)
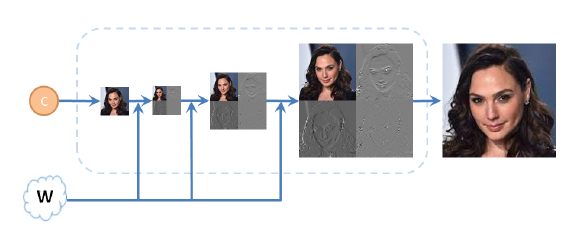 (Figure 2. 저자들의 style 기반 Generator 구조는 증가하는 해상도 스케일에서 wavelet coefficients를 예측한다.)
(Figure 2. 저자들의 style 기반 Generator 구조는 증가하는 해상도 스케일에서 wavelet coefficients를 예측한다.)
Method
1. Wavelet Transform
저자들의 방법의 핵심은 이미지를 일련의 채널로 분해하는 wavelet transform으로, 각각은 서로 다른 범위의 주파수 content를 나타낸다. 저자들은 Haar Wavelets를 변환의 기본 함수로 사용했는데, 이는 다중 주파수 정보를 잘 나타내는 문서화된 능력과 결합된 단순한 특성 때문이다. 이 모델은 1단계 wavelet 분해(decomposition)로 작동하며, 여기서 각 이미지는 LL, LH, HL, HH의 4개 하위 밴드(sub-bands)로 분할된다. 이러한 밴드(band)는 일련의 low-pass와 high-pass wavelet filters를 통해 이미지를 전달함으로써 얻어지며, wavelet coefficients 역할을 한다. 첫 번째 하위 대역인 LL은 저주파 정보에 해당하며, 실제로 입력 이미지의 blurred 버전과 시각적으로 유사하다. 나머지 하위 대역인 LH, HL, HH는 각각 수평, 수직, 대각선 방향의 고주파 content에 해당한다.
2. Network Architecture
저자들의 wavelet-aware 구조는 StyleGAN2의 original implementation을 기반으로 한다. original implementation은 이미지 공간에서 직접 content를 생성하지만, 제안된 구조는 주파수 영역에서 작동한다. 마찬가지로, 저자들의 Discriminator는 이미지의 RGB 공간뿐만 아니라 전체 wavelet 분해까지 고려하도록 설계되었다.
Generator가 wavelet 영역에서 직접 content를 생성하게 함으로써 다음 두 가지 측면에서 이득을 얻을 수 있다. 첫째, 신경망은 저주파 영역에서 학습을 우선시한다. 표현(representation)을 주파수 기반 표현으로 변환함으로써 표현에 대한 저주파수 수정(modifications)을 학습하여 네트워크가 이미지 영역의 고주파수 변화에 영향을 미칠 수 있도록 한다. 이것은 나중에 네트워크가 고주파수를 학습하도록 동기를 제공할 수 있지만, 학습 작업을 더 쉽게 만들지는 않기 때문에 단순한 loss 기반 수정과는 다르다. 둘째, wavelet 분해는 공간적으로 더 촘촘하다. 1단계 wavelet 분해에서 각 2N x 2N 영상은 각각 N x N 계수의 4개 채널로 완전히 표시된다. 이를 통해 추가 filters가 필요한 대신 전체 생성 프로세스 전반에 걸쳐 저해상도 표현에 대한 convolution을 사용할 수 있다. 그러나, 이 trade-off는 인기 있는 딥러닝 프레임워크를 사용할 때 유리할 수 있다.
마찬가지로, Discriminator에 주파수 정보를 제공함으로써 네트워크는 생성된 이미지에서 종종 누락되는 고주파 content를 더 잘 식별할 수 있다. 그 결과, Generator는 그럴듯한 고주파 데이터를 다시 생성하도록 동기를 부여받는다.
제안된 Generator에서 각 해상도 블럭은 입력으로써 전체 wavelet 분해를 받는다. StyleGAN2와 유사한 방식으로 wavelet coefficients는 skip connection을 통해 주파수 영역으로 매핑된 고차원 features set을 사용하여 세분화된다. StyleGAN2에서는 간단한 bilinear up-sampling을 사용하여 블록들 사이에서 이미지 크기가 조정된다. 주파수 영역에서 이 up-sampling을 수행하는 것은 동일한 의미를 갖지 않는다. 대신, 저자들은 자연스러운 대안을 선택하고 역파장 변환(Inverse Wavelet Transform)을 적용하여 wavelet 표현을 이미지 영역으로 다시 변환하고, 이미지를 평소대로 조정한 다음 고해상도 이미지에서 다음 wavelet coefficients set을 예측하여 up-sampling을 수행한다. 네트워크의 output은 마지막 layer의 output에 의해 제공되는 wavelet 분해에 역파장 변환을 적용하여 형성된다. Generator의 구조는 Figure 3.(왼쪽)에 설명되어 있다.
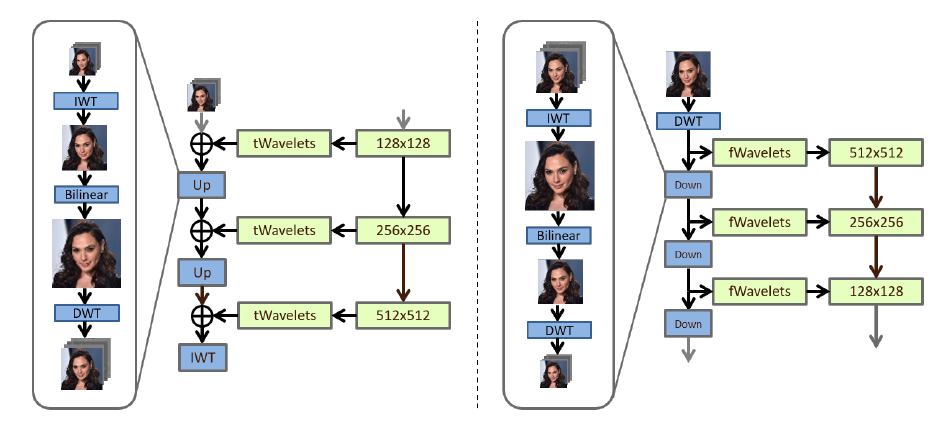 (Figure 3. 저자들의 SWAGAN Generator(왼쪽) 및 Discriminator(오른쪽) 구조이다. 각 ConvBlock은 StyleGAN2 구조의 feature-resolution increasing block과 동일하다. StyleGAN2의 tRGB와 fRGB layer는 tWavelet 분해와 고차원 feature 간의 매핑을 학습하는 데 사용된다. Inverse wavelet transforms는 IWT로 표시되며, 위와 아래는 각각 이미지를 높은 해상도 또는 낮은 해상도의 초기 wavelet 분해로 변환하는 비학습 layer이다.)
(Figure 3. 저자들의 SWAGAN Generator(왼쪽) 및 Discriminator(오른쪽) 구조이다. 각 ConvBlock은 StyleGAN2 구조의 feature-resolution increasing block과 동일하다. StyleGAN2의 tRGB와 fRGB layer는 tWavelet 분해와 고차원 feature 간의 매핑을 학습하는 데 사용된다. Inverse wavelet transforms는 IWT로 표시되며, 위와 아래는 각각 이미지를 높은 해상도 또는 낮은 해상도의 초기 wavelet 분해로 변환하는 비학습 layer이다.)
Discriminator에서 저자들은 유사하게 각 블록에 해당하는 해상도의 wavelet coefficients를 제공한다. 각 해상도 단계에서 skip connection 기반 네트워크는 wavelet 분해에서 feature들을 추출하고 더 높은 해상도 블록에서 파생된 feature 표현으로 병합하는 데 사용된다. 블록 간 이미지를 downscale하기 위해 wavelet coefficient가 역파장 변환(IWT)를 통해 전체 이미지로 다시 결합되고, 이미지가 bilinear하게 downsample이 되며, 저해상도 이미지가 wavelet coefficient로 다시 분해되어 다음 블록으로 전달된다. Discriminator의 첫 번째 블록에 대한 입력은 단순히 모든 이미지(실제 또는 가짜)의 DWT이다. Discriminator의 구조는 Figure 3.(오른쪽)에 설명되어 있다. 위에서 설명한 구조 외에도 동일한 네트워크에서 서로 다른 up-sampling 단계, 이미지와 wavelet domain 생성 단계 혼합 등 다양한 변형을 살펴보았다.
3. Downstream Tasks
스타일 기반 네트워크의 모든 적응은 원본 주위에 구축된 downstream tasks의 backbone으로 사용할 수 없다면 불완전할 것이다. 저자들은 wavelet 기반 네트워크가 여전히 동일한 애플리케이션을 지원할 수 있으며, 경우에 따라서는 더 나은 결과를 얻을 수 있음을 보여준다. 저자들은 Generator가 주어진 소스 이미지의 최상의 근사치를 출력하는 latent space 표현을 찾기 위해 gradient descent를 사용하는 inversion에 대한 최적화 기반 접근 방식을 사용하여 모델을 분석한다. 저자들은 지각 기반 손실(LPIPS)을 최소화하는 대상을 사용하여 스타일 기반 네트워크의 소위 W 공간에서 latent 표현을 찾는 Karas 등의 latent space projector를 사용한다. L2 기반 재구성 대상은 최적화 프로세스에서 불가피하게 고주파 정보를 폐기하기 때문에 나중에는 저자들의 needs에 매우 중요하다.
4. Implementation and Training Details
저자들은 StyleGAN2의 공식적인 텐서플로우 구현을 기반으로 만들었다. 특히, 그들은 skip 기반 Generator 및 Discriminator의 구조를 수정하지만, 그렇지 않을 경우 configuration F 설정으로부터 해당하는 모든 training detail과 parameters를 상속한다. 저자들의 모델은 256 x 256, 1024 x 1024 해상도의 FFHQ와 256 x 256 해상도의 LSUN Churches로 학습되었다. 1024 x 1024 해상도의 FFHQ에서 wavelet 기반 모델의 경우 batch size로 8, StyleGAN2의 경우 batch size로 2를 활용했고, 256 x 256 해상도의 FFHQ는 각각 16과 8의 batch size를 사용했다. 모든 모델은 단일 NVIDIA GeForce RTX 2080 GPU에서 학습되었다. 즉, 시중에서 구할 수 있는, 기업 급이 아닌 컴퓨팅 성능을 사용했다. downsteam tasks에 대한 정량적 평가를 위해 공개적으로 사용 가능한 CelebA dataset을 활용했다.
