[Computer Vision] MobileStyleGAN
Super Resolution
 MobileStyleGAN: A Lightweight Convolutional Neural Network for
MobileStyleGAN: A Lightweight Convolutional Neural Network for
High-Fidelity Image Synthesis
1. MobileStyleGAN (feat. StytleGAN2)
- StyleGAN2 구조를 baseline으로 한 스타일 기반의 생성 모델
- 계산적으로 효율적인 합성 네트워크(Synthesis Network)의 설계에 초점을 맞춘 StyleGAN2로부터 매핑 네트워크(Mapping Network)를 채택하였다.

1.1 Image Representation Revisited
-
DWT (Discrete Wavelet Transform)
2D 이미지에 적용 시, DWT는 더 낮은 공간의 해상도와 다른 주파수 밴드를 가진 4개의 같은 사이즈의 채널로 변형시킨다. -
IDWT (Inverse Discrete Wavelet Transform)
웨이블릿 영역(wavelet domain)으로부터 픽셀 기반의 묘사(representation)로 복원시킨다.
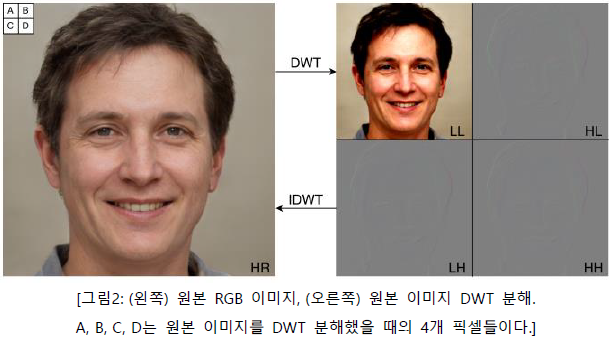
-
이미지의 묘사 형태의 장점
- 웨이블릿 기반 이미지 묘사(wavelet-based image representation)는 픽셀 기반 접근(pixel-based approaches) 보다 더 많은 구조적 정보를 포함하기 때문에 정확도 손실 없이 저해상도 feature map을 사용해서 고화질 이미지를 생성할 수 있다.
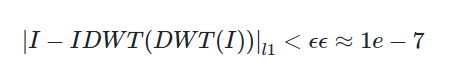
- DWT와 IDWT를 위해 filter bank로 Haar wavelets을 사용했는데, Haar wavelets를 사용한 IDWT는 곱셈 없이 효과적으로 실행될 수 있다. (그림1 참고)
- 이미지의 고주파 디테일 생성은 복잡한 문제이다. StyleGAN의 latent space가 저주파에서는 매끄럽지만 고주파에서는 거칠다. StyleGAN과 같은 픽셀 기반 접근과는 대조적으로, 주파수 기반 이미지 묘사를 사용하면 바로 신호의 고주파 요소에 정규화를 추가할 수 있는데, 이는 저주파와 고주파 모두에서 매끄러운 latent space를 만든다.
1.2 Progressive Growing Revisited
StyleGAN2는 skip-generator를 사용하여 동일한 이미지의 여러 해상도에서 나온 RGB 값들을 합산함으로써 output 이미지를 형성한다. 저자들은 wavelet 영역에서 이미지를 예측할 때 skip connection 기반의 prediction head가 생성된 이미지의 품질에 특별한 기여를 하지 않는다는 것을 발견했다. 이에 따라 계산 복잡도를 낮추기 위해 저자들은 네트워크의 마지막 block에서 skip-generator를 single prediction head로 바꾸었다. 그러나 중간 block에서 target 이미지를 예측하는 것은 이미지 합성을 안정화시키는 데 있어서 중요하다. 따라서 저자들은 공간 해상도에 따라 target 이미지를 예측하기 위해 중간 block 마다 auxiliary prediction head를 추가했다.
- StyleGAN2와 MobileStyleGAN prediction heads 간의 차이점
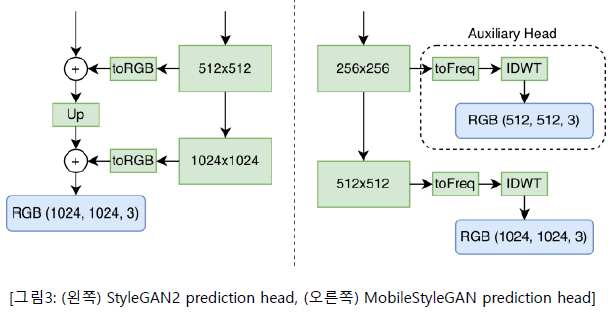
1.3 Depthwise Separable Modulated Convolution
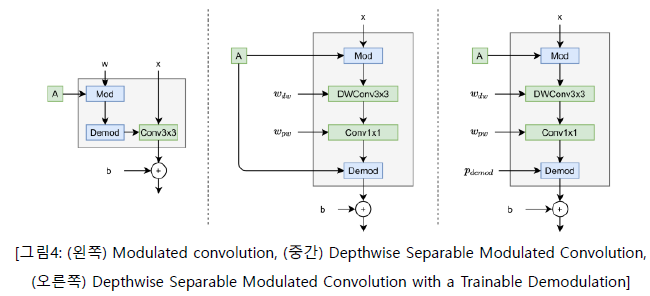
MobileNet에서 영감을 받은 MobileStyleGAN은 보통의 convolution을 3x3 depthwise convolution과 pointwise convolution이라 불리는 1x1 convolution으로 구성된 depthwise separable convolution을 기반으로 한다. Modulated convolution과 Depthwise Separable Modulated Convolution 모두 modulation, convolution, normalization으로 구성되어 있다. 이러한 작업 순서를 통해 Depthwise Separable Modulated Convolution을 쉽게 설명할 수 있다.
1.4 Demodulation Fusion
Batch Normalization fusion은 추론 시간(Inference Time)에서 convolution 네트워크의 계산 복잡도를 낮추는 유명한 기술이다. 이 기술은 두 선형 연산을 하나로 병합할 수 있다. Demodulation 메커니즘은 Batch Normalization과 유사하지만 추론 시간에서 정수가 되지 못해 선형 연산하지는 못한다. Demodulation 정수를 만들기 위해 저자들은 스타일 계수(style coefficients)를 학습 가능한 파라미터(trainable parameters)로 바꾸었다. 따라서 Demodulation은 추론 시간에서 정수가 되고, pixelwise convolution weights로 병합될 수 있다. 저자들은 이 기술이 생성된 이미지의 품질에 부정적인 영향을 미치지 않는다는 것을 발견했다.
1.5 Upscale Revisited
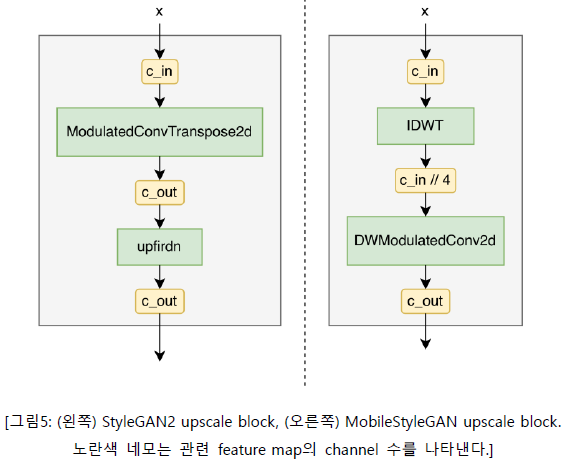
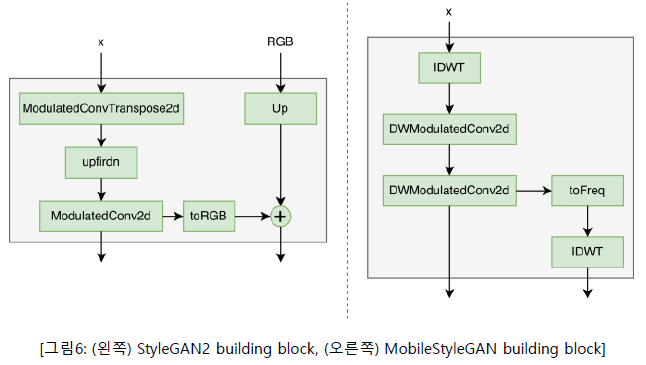
StyleGAN2 building block이 input feature maps를 upscale하기 위해 ConvTranspose를 사용하는 반면, 저자들은 MobileStyleGAN의 building block에서 upscale 기능으로써 IDWT를 사용한다. IDWT는 학습 가능한 파라미터를 포함하지 않기 때문에 저자들은 IDWT layer 후에 추가 Depthwise Separable Modulated Convolution을 더해준다.
2. Training Framework
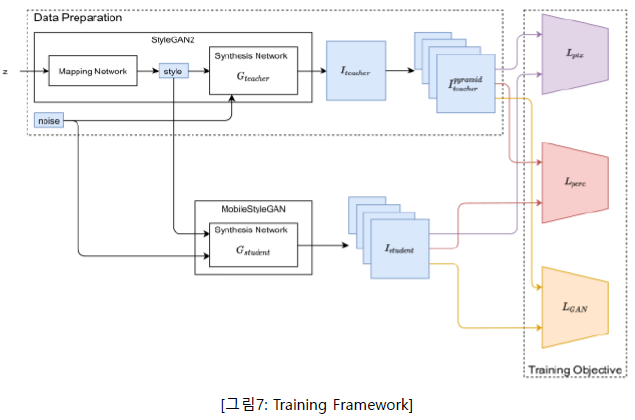
저자들의 Training framework는 Knowledge Distillation 기술에 기반한 것이다. StylgeGAN2가 Teacher Network로 주어지면, MobileStyleGAN은 Student Network로서 그 기능을 모방하도록 학습한다.
2.1 Data Preparation
Original StyleGAN2의 generator가 주어지면, unpaired learning을 paired setting으로 변환할 수 있다. 이렇게 하기 위해서 저자들은 Triplet data(Style, Noise, Teacher(I))를 준비했는데, Style은 주어진 noise vector ‘z’에 대한 mapping network의 output이고, Noise는 teacher와 student network 사이에서 공유되는 noise, Teacher(I)는 주어진 style에 대한 teacher network의 output이다.
앞서 언급했듯이, MobileStyleGAN의 각 block은 공간 크기에 따라 output 이미지를 예측한다. 따라서 Teacher(I) 대신 저자들은 Pyramid Teacher(I)를 ground-truth로 사용한다. Pyramid Teacher(I)는 Teacher(I)로부터 만들어진 이미지 pyramid이다. 따라서 저자들의 학습된 데이터 Triplet data는 Style, Noise, Pyramid Teacher(I)라 할 수 있다.
Overfitting을 방지하기 위해 저자들은 preprocessed data를 사용하지 않았고, 대신 학습 절차 중에 데이터를 즉시 생성했다. 또한, 학습 과정에서 메모리 소모를 줄이기 위해 실제 데이터는 사용하지 않고 StyleGAN2에서 생성한 인공 샘플만 사용했다.
2.2 Training Objective
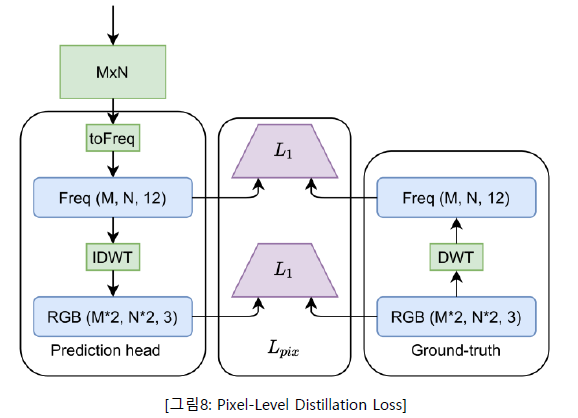
-
Pixel-Level Distillation Loss
MobileStyleGAN은 wavelet 영역에서 target 이미지를 예측하는 것을 목표로 하며, StyleGAN2의 기능을 모방하는 단순 방법은 StyleGAN2에 의해 생성된 이미지의 wavelet 변환과 MobileStyleGAN의 output 사이의 pixel-level 거리를 최소화하는 것이다. 또한 저자들은 pixel 기반 영역에서 자신들의 Ground Truth와 예측된 이미지 간의 pixel-level 거리를 최소화하는 정규화를 추가했다. 저자들은 정규화가 서로 협력하여 다른 주파수들을 학습할 수 있도록 한다는 것을 발견했다. 저자들의 네트워크는 각 공간 크기에 따라 output 이미지를 예측하므로 pixel 기반의 distillation loss는 각 scale에서 적용되었다. -
Perceptual Loss
앞에서 설명한 pixel-level loss는 output과 ground-truth 이미지 간의 지각적 차이(Perceptual Differences)를 포착하지 못한다. 이 문제를 해결하기 위해 저자들은 objective로써 perceptual loss를 사용한다. 저자들의 perceptual loss는 VGG16 features 기반으로 한다. 저자들은 perceptual loss를 오직 MobileStyleGAN에 의해 생성된 output 이미지에만 적용했다. -
GAN Loss (=Binary cross-entropy loss)
pixel-level과 perceptual loss만 사용하는 것은 흐릿한 이미지 생성으로 이끌 수 있다. 생성된 이미지를 선명하게 하기 위해서 저자들은 pipeline에 Discriminator Network를 포함시켰다. 그리고 Generator와 Discriminator Network에 GAN loss를 사용했다.

안녕하세요. 현재 자율주행 로봇의 SLAM 알고리즘을 개발하는 업무를 하고 있는 개발자입니다.
MobileStyleGan에 관련된 내용을 공유해주셔서 감사합니다~!
블로그의 다른 글들을 살펴보니 로봇 개발에 관심이 많으신 것 같아 로봇교육에 대한 간단한 대화(30~40분)를 나누고 싶어 이메일을 남깁니다.
irobou0915@gmail.com
오늘도 좋은 하루 보내세요!