
🚨 본 프로젝트의 저작권은 코드스테이츠에 귀속되어 있습니다.
코드스테이츠 프로젝트 CP1 DS트랙 - 0과 1을 분류하는 인공신경망 프로그래밍 과정 정리 및 회고
- Github Repository 바로가기 : Binary_ANN_Programming (클릭)
- Google Colaboratory 바로가기 : 정경재_CP1_DS.ipynb(클릭)
📝 DS트랙 - 0과 1을 분류하는 인공신경망 프로그래밍
- 제한된 라이브러리로 0과 1을 분류하는 인공신경망(ANN)을 직접 구현하는 프로젝트
- Tech Stack

0. 프로젝트 목차
- Introduction (서론)
- 🎯프로젝트 개요 (주제, 목표, 절차)
- 💻수행절차 (파이프라인) 시각화
- Programming (프로그래밍)
- 💡프로젝트 필요조건
- 💻프로그래밍 기능 구성 목록
- 💾라이브러리 및 데이터 불러오기
- 🛠️데이터 전처리 및 분리 기능
- ⚙️인공신경망 연산 기능
- 🧠인공신경망 (순전파, 예측, 검증)
- 🧠인공신경망 (역전파, 학습)
- 💽전체 기능 동작 기능
- Conclusion (결론)
- 🏆프로젝트 핵심 요약 (Key Takeaways)
- 🍷느낀 점 (My Takeaways)
1. Introduction (서론)
1-1. 🎯프로젝트 개요 (주제, 목표, 절차)
- 코드스테이츠에서 지정한 주제로 진행하는 개인프로젝트
- DA / DE / DS 트랙중 하나를 선택 : DS 트랙 (Data Scientist)
- DS트랙은 단일 주제로써 인공신경망(ANN)을 구현하는 프로젝트를 수행
- 데이터 또한 지정된 데이터를 이용하여 진행
- DS트랙 목표 : 지정된 조건을 모두 만족하는 이진판단 인공신경망을 프로그래밍
- DA / DE / DS 트랙중 하나를 선택 : DS 트랙 (Data Scientist)
- 반드시 포함되어야할 내용
- 프로그램에 대한 전체 파이프라인의 시각적 표현, 글을 통한 충분한 설명
- AI 모델에 대한 연산 방식의 정확한 이해 및 코드 구현
- AI 모델 성능 측정 방식에 대한 정확한 이해 및 코드 구현
- 데이터에 대한 정제(분리)작업 수행 및 코드 구현
- 발표 대상은 DS 전문지식이 있는 사람 대상이라 가정하여 보고서 작성
- 기업 제출용 포트폴리오를 보는 사람은 주로 기술 팀장 혹은 해당 기능 개발 담당자가 보기 때문이라고 함

- 프로젝트 주제 : 0과 1을 분류하는 인공신경망 프로그래밍
- 프로젝트 목표 : 제시된 조건들을 모두 만족하며 이진 판단을 수행하는 인공신경망을 프로그래밍 하는 것 (제시 조건은 뒤에서 자세히 다룰 예정)
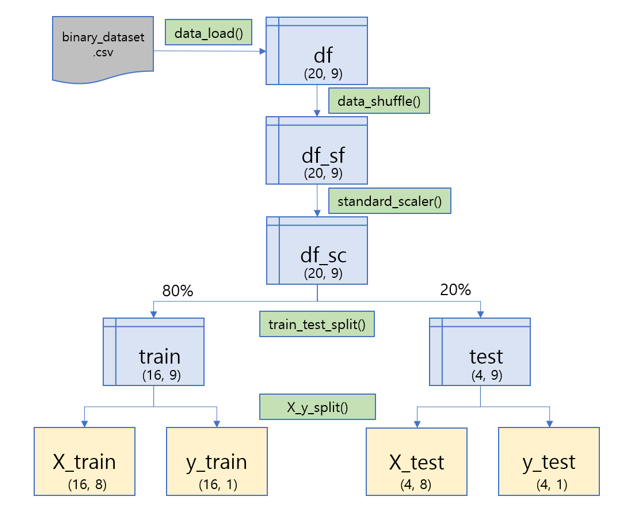
1-2. 💻수행절차 (파이프라인) 시각화

- 라이브러리 및 데이터 불러오기
data_load()
- 데이터 전처리 및 분리
data_shuffle()standard_scaler()train_test_split()X_y_split()
- 인공신경망 연산 기능 구현
initialization_parameter()weights_plot()get_batch_data()sigmoid()sigmoid_crossentropy_logits()sigmoid_crossentropy_logits_prime()accuracy_score()
- 인공신경망 Class 구현
NeuralNetwork()NeuralNetwork_additional()plot_history()
- 전체 기능 동작 기능 main함수 구현, 테스트
main()main_additional()
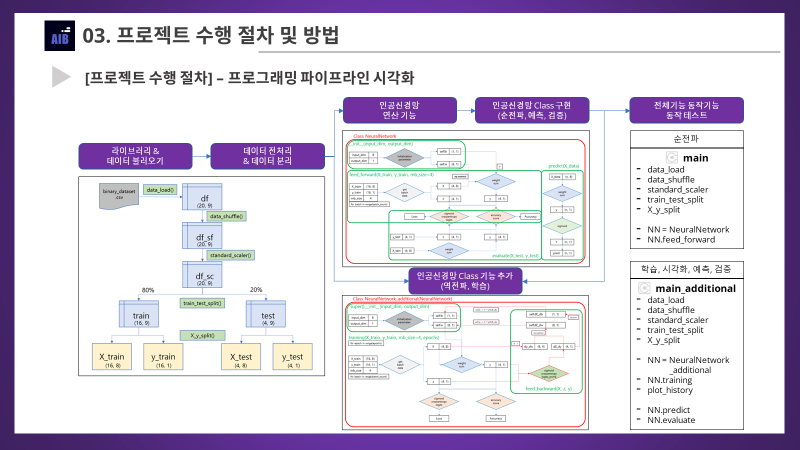
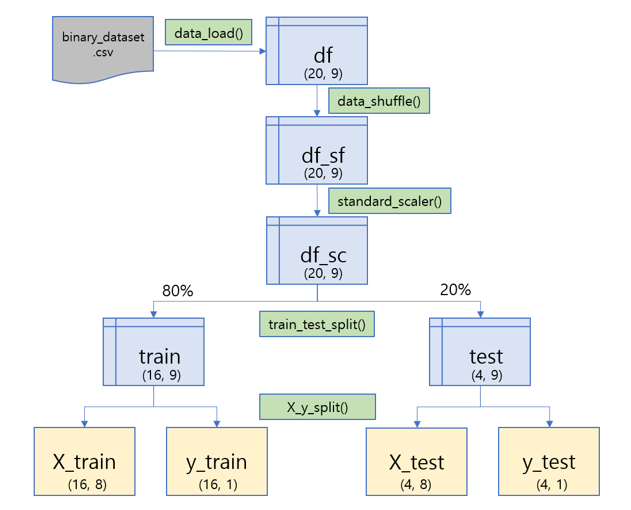
- 파이프라인 시각화 1. 데이터 불러오기, 전처리, 분리
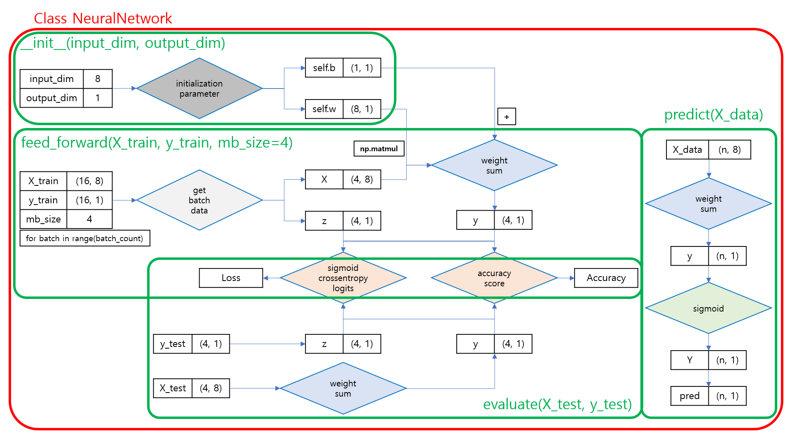
- 파이프라인 시각화 2. 인공신경망 (순전파, 예측, 검증)
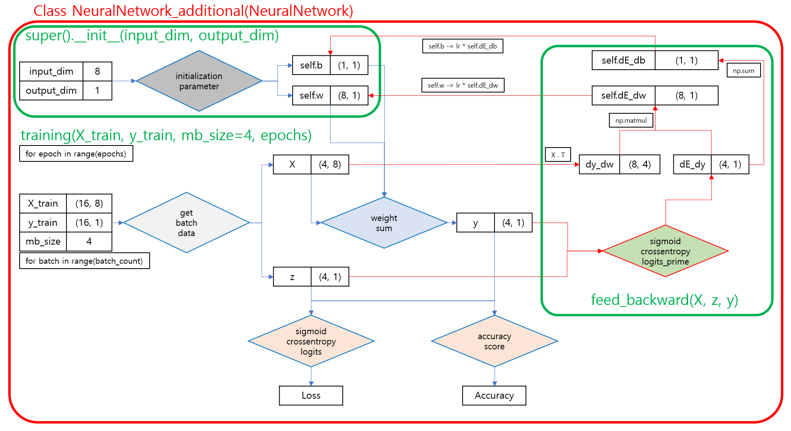
- 파이프라인 시각화 3. 인공신경망 (역전파, 학습)
- 세부내용들은 뒤에서 단계별로 자세히 다룰 예정
2. Programming (프로그래밍)
2-1. 💡프로젝트 필요조건
- 충족해야하는 조건은 크게 4가지로 분류할 수 있음
- 조건1. 실습환경 및 라이브러리
- 조건2. 데이터
- 조건3. 인공신경망 프로그래밍
- 조건4. 필수 프로그래밍 기능 목록

- 조건1. 실습환경 및 라이브러리
- 실습환경은 Google Colab
- Google Colaboratory 바로가기 : 정경재_CP1_DS.ipynb(클릭)
- 그러나 본인은 local 환경인 VSCode가 더 편하고 익숙해서 우선 VSCode로 프로그램을 코딩하고 테스트를 마친 뒤에 정리된 코드들을 Colab으로 코드를 정리하고 주석을 추가하는 방식으로 프로젝트를 진행하였음
- 제한 라이브러리
numpypandascsvmatplotlib.pyplot
- 위 4가지 라이브러리와
파이썬 기본 내장함수이외엔 사용해선 안됨- 즉 기초적인 라이브러리를 통해 인공신경망을 직접 구현하는 것이 목표
- 파이썬 기본 내장함수(링크)
- 실습환경은 Google Colab
- 조건2. 데이터
- 데이터 다운로드 링크는 저작권 침해 우려가 있어 링크를 블로그에는 공유하진 않겠음
- 데이터 개요 : 9개의 columns, 21개의 rows
- column : 첫 열부터 8번째 열에는 독립변수(x1~x8), 마지막 열은 종속변수(y)
- row : 첫 행은 변수이름, 나머지 20개의 행에는 변수에 대한 값이 기록되어 있음
- 학습 및 테스트 데이터 분리 기준
- 학습 데이터 (80%, 16개)
- 테스트 데이터 (20%, 4개)
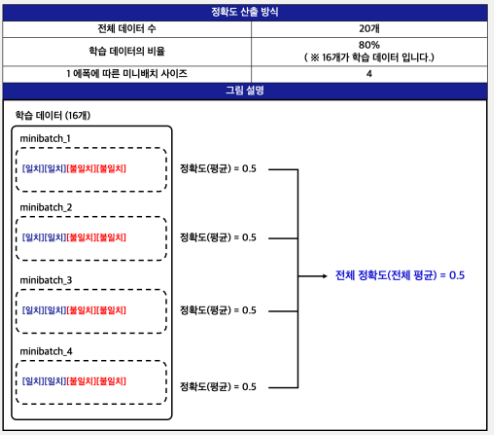
- 미니 배치 (Mini-Batch) 기준
- 하나의 미니배치에 4개의 학습데이터로 구성
- 본 과제에서는 총 4개의 미니배치가 생성된다


- 조건3. 인공신경망 프로그래밍
- 입력계층의 노드 수는 독립변수 개수인 8개로 설정
- 출력계층의 노드 수는 종속변수 개수인 1개로 설정
- 활성화 함수는 sigmoid로써 예측에 대한 확률값(0.0~1.0)을 반환
- 손실 함수는 이진교차엔트로피(binary cross entropy)로 설정
- 분류 평가지표는 정확도(Accuracy)이며, 각 미니배치의 정확도를 평균내어 전체 정확도를 구하는 방식으로 구현 (결국은 전체 평균 정확도와 마찬가지이긴 함)
- 모든 기능들은 재사용이 가능한 메서드(함수) 형태로 구현해야 함
- 이에 따라 전체 기능이 순차적으로 동작하는main()함수를 정의하고 실행시켜야 함
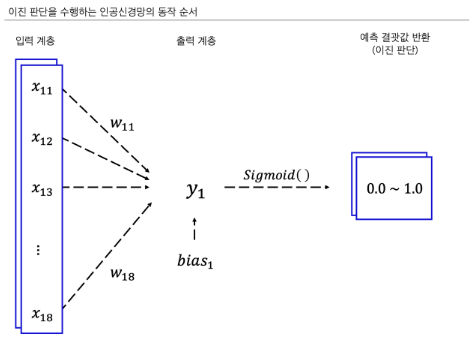
- 조건4. 인공신경망 필수 기능 목록
- 전체 기능 동작 기능 :
main() - 데이터 처리 기능 :
불러오기,뒤섞기,학습 및 테스트 분리 - 인공신경망 기능 :
파라미터 및 편향 생성,신경망 연산,손실 및 정확도
- 전체 기능 동작 기능 :
2-2. 💻프로그래밍 기능 구성 목록

- 위에서 파이프라인을 소개할 때 언급된 함수들로 기능들을 구현하였으며, 각 기능에 대한 세부사항들은 아래에서 단계별로 자세히 다루도록 하겠음
2-3. 💾라이브러리 및 데이터 불러오기
💾 Library Import & Drive Mount
- 제한 조건에 따라 Library는
numpy,pandas,csv,matplotlib만 Import
# Library Import
import numpy as np
import pandas as pd
import csv
import matplotlib.pyplot as plt
# matplotlib minus표시 설정
plt.rcParams['axes.unicode_minus'] = False- Google Drive에 저장해 놓은 다운로드 데이터를 불러오기 위한 마운팅 실시
- Colab에서만 수행한 기능이며, VSCode로 작업할때는 수행하지 않고 건너뜀
# Google Drive Mount
from google.colab import drive
drive.mount('/content/drive')- csv file에 대한 directory를 변수로써 저장하기
- VSCode에서는
.ipynb파일과 같은 폴더에 데이터를 저장하여 경로를 저장함
- VSCode에서는
# Colab
csv_dir = "/content/drive/MyDrive/AI/CP1/binary_dataset.csv"# Local(VSCode)
csv_dir = './binary_dataset.csv'⚙️ 기능 1-1. 데이터 불러오기 : data_load()

- csv 모듈로 데이터를 불러옴
- 첫 row는 column 이름으로 쓰기위해 따로 저장함
- 나머지 row은 data로 쓰기위해 리스트로 저장함
- 데이터 전처리를 원활하게 하기위해
pandas로 DataFrame으로 만들고 출력함- 그대로 만들게되면 데이터가 문자열로 저장되기 때문에 dtype변환도 실시함
# 데이터 불러오기 기능
def data_load(filepath):
'''
입력값 정보
filepath : csv 파일 디렉토리
'''
# open 함수로 파일을 열기 (처리가 끝나면 파일을 닫도록 with문 활용)
with open(file=filepath) as csv_file:
# csv 모듈로 파일을 읽기 (reader)
csv_reader = csv.reader(csv_file)
# 첫 열 따로 저장
row0 = next(csv_reader)
# 두번째 열부터 데이터를 list로 저장
data = list(csv_reader)
# pandas로 DataFrame 생성 (column : row0)
dataframe = pd.DataFrame(data=data, columns=row0)
# 독립변수(x1~x8)는 float로, 종속변수(y)는 int로 변환
dataframe = dataframe.astype(float).astype({'y':int})
# 출력 : DataFrame
return dataframe- 데이터 불러오기 기능 동작 테스트
# data_load() 실행 (filepath : csv file의 directory)
df = data_load(filepath=csv_dir)
# df의 column확인
print(f"List of columns : {list(df.columns)}")
# df의 shape확인
print(f"DataFrame shape : {df.shape}")
'''
List of columns : ['x1', 'x2', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8', 'y']
DataFrame shape : (20, 9)
'''# df의 일부분만 출력해보기
display(df.head(10))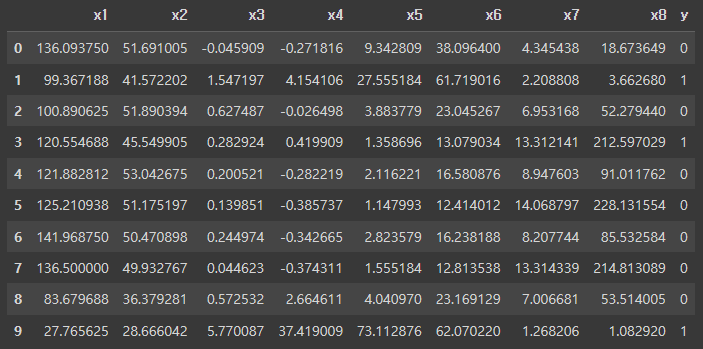
# df.info()로 결측치 및 dtype확인
print(df.info())
'''
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 20 entries, 0 to 19
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 x1 20 non-null float64
1 x2 20 non-null float64
2 x3 20 non-null float64
3 x4 20 non-null float64
4 x5 20 non-null float64
5 x6 20 non-null float64
6 x7 20 non-null float64
7 x8 20 non-null float64
8 y 20 non-null int64
dtypes: float64(8), int64(1)
memory usage: 1.5 KB
None
'''2-4. 🛠️데이터 전처리 및 분리 기능
⚙️ 기능 2-1. 데이터 뒤섞기 기능 : data_shuffle()

numpy로 뒤섞을 인덱스 번호 array를 생성- 동일한 결과가 나오도록 하기 위해 random seed를 지정함(기본값=2023)
pandas를 통해 DataFrame의 행 순서를 뒤섞기.reindex를 통해 행 순서를 array에 따라 뒤섞음.reset_index옵션을 추가해 뒤섞은 데이터의 인덱스를 초기화할지 결정하도록 함
# 데이터 뒤섞기 기능
def data_shuffle(data, reset_index=True, seed=2023):
'''
입력값 정보
data : 뒤섞을 데이터(DataFrame)
reset_index : 기본값 True, 뒤섞인 index를 재설정할지 여부
seed : 기본값 2023, numpy.random.seed 값
'''
# 데이터 길이를 data_length변수에 저장
data_length = data.shape[0]
# index 초기값 : 0 ~ n-1
shuffle_idx = np.arange(data_length)
# seed 설정 (기본값은 2023)
np.random.seed(seed)
# index array 뒤섞기
np.random.shuffle(shuffle_idx)
# index를 초기화하지 않을 경우
if reset_index==False:
# shuffle_idx로 reindex만 실시
df = data.reindex(index=shuffle_idx)
# index를 초기화할 경우(기본값으로 설정되어있음)
elif reset_index==True:
# shuffle_idx로 reindex 실시 + reset_index도 실시
df = data.reindex(index=shuffle_idx).reset_index(drop=True)
# 출력 : 뒤섞인 dataframe
return df- 데이터 뒤섞기 기능 동작 테스트
# data_shuffle()실행 (reset_index=False)
df_sf0 = data_shuffle(df, reset_index=False)
# data_shuffle()실행 (reset_index=True)
df_sf = data_shuffle(df)
# 함수 실행 결과 출력
print("Shuffled DataFrame (not reset index)")
display(df_sf0.head(10))
print("\nShuffled DataFrame (reset index)")
display(df_sf.head(10))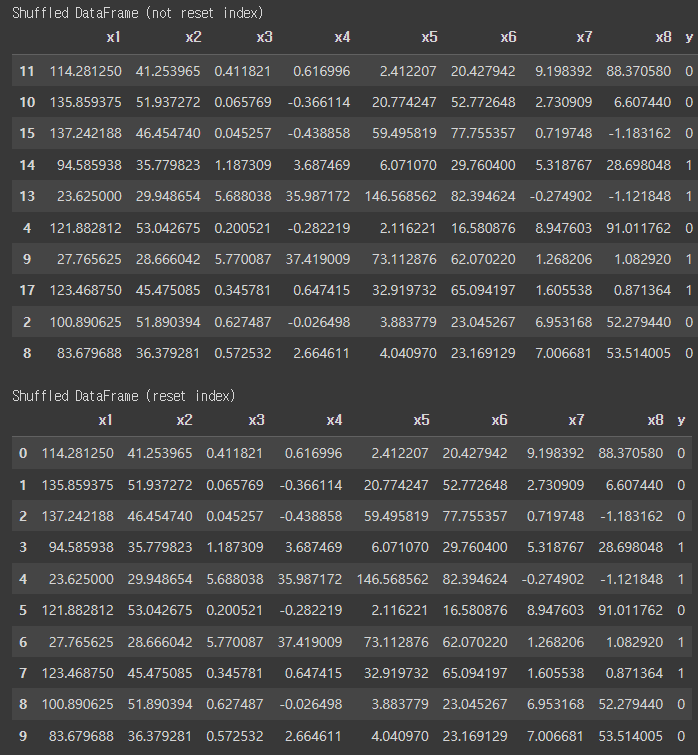
# 데이터 분포를 확인하기
display(df_sf.describe())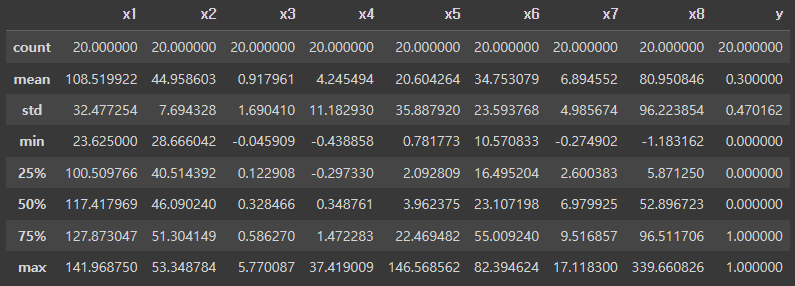
⚙️ 기능 2-2. 데이터 표준화 기능 : standard_scaler()
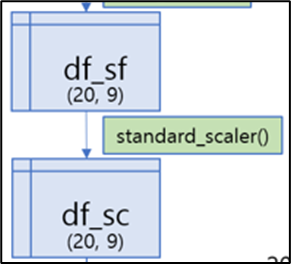
- 데이터의 feature들의 평균과 표준편차가 제각각이므로 데이터의 분포를 맞추기 위해 표준화 기능을 추가적으로 구현함
- 표준화 방식은 음수 데이터들도 포함되어 있기 때문에 standard scaling 방식으로 표준화를 진행함 (평균0, 표준편차1)
pandas를 이용한 column단위의 표준화 진행- X, y를 먼저 분리한다음, X에대한 표준화 진행 후 다시 y와 병합하는 방식으로 구현함
# 데이터 표준화 기능
def standard_scaler(data, output_dim):
'''
입력값 정보
data : 표준화시킬 데이터(DataFrame)
output_dim : 출력층의 노드 수(종속변수 수)
'''
# X와 y를 일단 분리시키도록 함
X = data.iloc[:,:-output_dim]
y = data.iloc[:,-output_dim:]
# pandas연산에 의해 column 별로 연산이 진행된다(평균값을 빼고 표준편차로 나누기)
std_scale_X = (X-X.mean()) / X.std()
# 표준화한 X를 y와 concat하여 다시 DataFrame을 정의
df = pd.concat([std_scale_X, y], axis = 1)
# 출력 표준화를 마친 dataframe
return df- 데이터 표준화 기능 동작 테스트
# standard_scaler 함수 실행
df_sc = standard_scaler(df_sf, output_dim=1)
# 표준화를 거친 dataframe 확인
print(f"Scaled DataFrame shape : {df.shape}")
display(df_sc.head(10))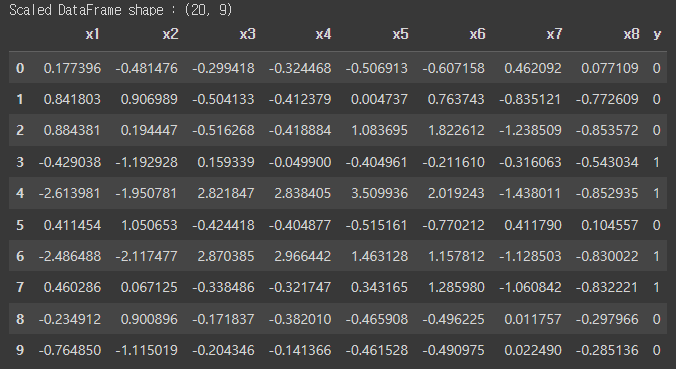
# 데이터 분포를 확인하기
display(df_sc.describe().round(6))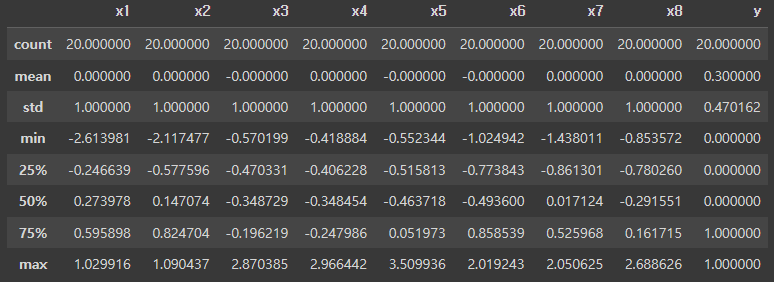
⚙️ 기능 2-3. 학습 및 테스트 데이터 분리 기능 : train_test_split()

pandas를 활용한 학습 및 테스트 데이터 분리 기능- 학습데이터 : 테스트데이터 = 0.8 : 0.2
- 미니배치 사이즈 : 4
# 학습 및 테스트 데이터 분리 기능
def train_test_split(data, train_ratio, batch_size):
'''
입력값 정보
data : 분리할 데이터(DataFrame)
trian_ratio : 훈련 데이터 비율 ( 0 ~ 1 )
batch_size : mini-batch size (integer)
'''
# 데이터의 행 갯수를 data_size로 지정
data_size = data.shape[0]
# train_ratio를 곱한 값을 배치사이즈로 나누어 batch데이터의 갯수를 구함
batch_count = int(data_size*train_ratio) // batch_size
# bacth데이터 갯수와 사이즈를 곱한 값이 test 데이터의 시작 인덱스가 됨
test_1st_idx = batch_count*batch_size
# train, test 데이터 분리(pandas)
train = data.iloc[:test_1st_idx,:]
test = data.iloc[test_1st_idx:,:]
# 출력 : train, test dataframe
return train, test- 학습 및 테스트 데이터 분리 기능 동작 테스트
# train_test_split() 실행(ratio는 0.8, batch_size는 4)
train, test = train_test_split(df_sc, train_ratio=0.8, batch_size=4)
# train, test 출력해보기
print(f"train dataset : {train.shape}")
display(train)
print(f"\ntest dataset : {test.shape}")
display(test)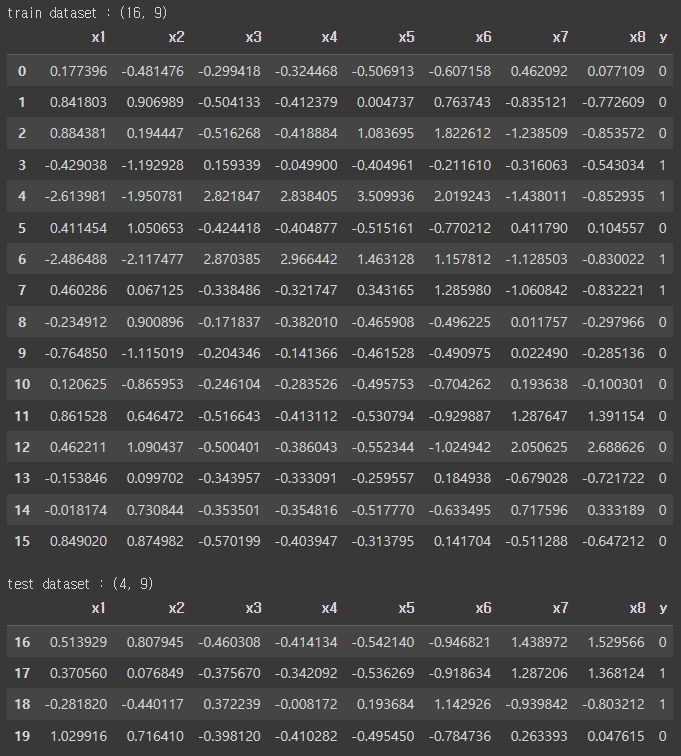
⚙️ 기능 2-4. 독립변수 및 종속변수 분리 기능 : X_y_split()
pandas와numpy를 활용해 독립변수(x1~x8)와 종속변수(y)로 분리하는 기능- 출력층 노드수에 따라 데이터를 X 와 y로 분리함
- 출력은 행렬 연산을 수월하게 하기 위해 ndarray로 출력함
- 본 데이터에선 y가 하나뿐이어서 output_dim이 1인데, 이때 형태를
(n, )혹은(n, 1)로 맞춰 줄 수 있다.- 그런데
(n,1)로 맞춰줘야만 행렬 연산에 오류가 발생하지 않으므로 주의
- 그런데
# 독립변수 및 종속변수 분리
def X_y_split(data, output_dim):
'''
입력값 정보
data : 분리할 데이터 (DataFrame)
output_dim : 출력층 노드 수 (종속변수 수)
'''
# X는 뒤에서 부터 output_dim직전까지의 column 데이터
X = np.array(data.iloc[:,:-output_dim])
# y는 뒤에서부터 output_dim이후의 column데이터 (끝에 : 를 꼭 붙여주자)
y = np.array(data.iloc[:,-output_dim:])
# 출력 : X, y ndarray
return X, y- 독립변수 및 종속변수 분리 기능 동작 테스트
# X_y_split()함수 실행하여 X, y array를 저장 (output_dim = 1)
X_train, y_train = X_y_split(train, output_dim=1)
X_test, y_test = X_y_split(test, output_dim=1)
# 분리 전 데이터 shape 출력
print("Data Shape (Before)")
print(f"train : {train.shape}")
print(f"test : {test.shape}")
# 분리 후 데이터 shape 출력
print("\nData Shape (Splited)")
print(f"X_train : {X_train.shape}")
print(f"y_train : {y_train.shape}")
print(f"X_test : {X_test.shape}")
print(f"y_test : {y_test.shape}")
'''
Data Shape (Before)
train : (16, 9)
test : (4, 9)
Data Shape (Splited)
X_train : (16, 8)
y_train : (16, 1)
X_test : (4, 8)
y_test : (4, 1)
'''2-5. ⚙️인공신경망 연산 기능

- 인공신경망 연산 기능들을 정리하기에 앞서 인공신경망 프로그래밍에 대해 먼저 설명할 필요가 있어서 내용을 추가함

- 입력층 8개, 출력층1개인 1차원적 인공신경망을 구현함
- 구현한 인공신경망은 총 2종류이며,
Class로 구현하였음NeuralNetwork()- 순전파, 예측, 검증 기능NeuralNetwork_additional()- 역전파, 학습 기능을 추가 구현
- 인공신경망 프로그래밍은 다음과 같은 단계로 진행함
- 신경망 연산에 쓰일 기능들을 정의하고 테스트
- 정의된 연산기능들을 활용해
순전파 인공신경망 Class를 정의하고 테스트 - 순전파 인공신경망을 상속받아
역전파 및 학습 Class를 정의하고 테스트 - 학습에 대한 Epoch별 손실 및 정확도를 시각화하는 학습곡선 기능 구현
⚙️ 기능 3-1. 가중치, 편향 생성 기능 : initialization_parameter()

numpy의random모듈을 통해 가중치 및 편향에 대한 난수를 생성- 분포를 데이터와 맞춰주기 위해
.randn으로 평균0, 표준편차1인 난수들로 생성함 - 동일한 결과를 낼 수 있도록 random seed를 설정 (기본값은 2023)
- 분포를 데이터와 맞춰주기 위해
- 인공신경망에서 init함수 (초기함수)에서 사용될 예정
# 가중치, 편향 생성 기능
def initialization_parameter(input_dim, output_dim, seed=2023):
'''
입력값 정보
input_dim : 입력층 노드수
output_dim : 출력층 노드수
seed : 기본값은 2023, numpy.random.seed값
'''
# seed 설정 (기본값은 2023으로 설정)
np.random.seed(seed)
# weight ndarray생성, shape : (input_dim,output_dim)
weights = np.random.randn(input_dim,output_dim)
# bias ndarray생성, shape : (output_dim,)
bias = np.random.randn(output_dim)
# 출력 : weights, bias
return weights, bias- 가중치 및 편향 생성 기능 동작 테스트
# initialization_parameter 함수 실행
weights, bias = initialization_parameter(input_dim=8, output_dim=1)
# weight 출력해보기
print(f"input dimension : {len(weights)}")
print(f"\nweights :\n{weights}")
# bias 출력해보기
print(f"\noutput dimension : {len(bias)}")
print(f"\nbias : {bias}")
'''
input dimension : 8
weights :
[[ 0.71167353]
[-0.32448496]
[-1.00187064]
[ 0.23625079]
[-0.10215984]
[-1.14129263]
[ 2.65440726]
[ 1.44060519]]
output dimension : 1
bias : [0.09890227]
'''📊 기능 3-2. 가중치 시각화 기능 : weights_plot()
- 출력층이 1개뿐이므로 가중치들에 대한 시각화할 수 있을 것이라 판단해 기능을 추가 구현하였음
- 그러나
numpy의.reshape을 통해 형태를 변환하기 때문에 출력 계층 개수에 상관없이 시각화는 가능함 (다만 해석이 조금 복잡해질뿐...)
- 그러나
- 인공신경망 class에도 포함시켜서 학습 전후로 가중치 변화가 있는지 확인하는 용도로 쓰일 예정
matplotlib을 활용한 가중치에대한 bar plot을 생성
# 가중치 시각화 기능
def weights_plot(weights):
'''
입력값 정보
weights : 가중치 (ndarray)
'''
# 가중치 ndarray -> pandas Series로 변환(인덱싱이 더 편해짐)
weights_series = pd.Series(np.reshape(weights,(-1)))
# plot 크기를 6x6으로 지정
plt.figure(figsize=(6,6))
# barplot 생성
weights_bar = plt.bar(weights_series.index, weights_series, color = 'pink')
# 각 bar 마다 값 text가 위쪽에 표시되도록 해보기
for rect in weights_bar:
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width()/2.0, height, '%.3f' % height,
ha='center', va='bottom', size=8)
# x값의 순서의 의미가 있는 건 아니라서 x축은 표시되지 않도록 설정
plt.gca().axes.xaxis.set_visible(False)
# barplot 출력
plt.title("Barplot of weights")
plt.show()- 가중치 시각화 기능 동작 테스트
# global 변수에 저장되어있는 weights의 분포를 시각화 해보기
weights_plot(weights)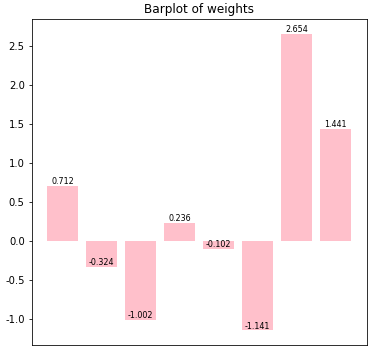
⚙️ 기능 3-3. 배치데이터 얻는 함수 : get_batch_data()

- 순전파 및 학습을 진행할때 배치를 고려하여 연산을 진행할 예정이기 때문에, 배치데이터를 얻는 함수를 정의함
- 인공신경망 class에서 for문을 통해서 배치별로 반복을 수행할때 쓰일 예정
# 배치데이터 얻는 기능
def get_batch_data(X, y, size, n):
'''
입력값정보
X : 독립변수(x1~x8)
y : 종속변수(y)
size : mini-batch 크기
n : 0 ~ (batch수 - 1) - for 문을 통해 입력받을 값임
'''
X_batch = X[size*n : size*(n+1)]
y_batch = y[size*n : size*(n+1)]
# 출력 : 인덱스 batch크기*n부터 batch크기 만큼의 데이터
return X_batch, y_batch- 배치데이터 얻는 함수 동작 테스트 (출력에선 간단하게 y에 대해서만 확인해보도록 하겠음)
# batch size는 4로 설정
batch_size = 4
# train data 의 배치 수를 얻기
batch_count = int(X_train.shape[0]) // batch_size
print(f"batch_size = {batch_size}, batch_count = {batch_count}")
# for 문을 통해 batch를 분리
for batch in range(batch_count):
X, y = get_batch_data(X_train, y_train, batch_size, batch)
# 간단하게 확인하기 위해 종속변수(y)만 확인해보도록 하겠음
print(f"\nBatch{batch+1}")
print(y)
'''
batch_size = 4, batch_count = 4
Batch1
[[0]
[0]
[0]
[1]]
Batch2
[[1]
[0]
[1]
[1]]
Batch3
[[0]
[0]
[0]
[0]]
Batch4
[[0]
[0]
[0]
[0]]
'''⚙️ 기능 3-4. 활성화함수 : sigmoid()
- 인공신경망에서 활성화 함수 역할을 하는 함수를 정의, 본 과제의 조건에 따라
sigmoid를 활성화함수로 사용 sigmoid공식- 인공신경망에서는 특히 예측 기능에서 주요하게 쓰일 예정이고, 손실함수의 편미분 계산에서도 쓰일 예정
# 활성화함수 : sigmoid (y : logits)
def sigmoid(y):
'''
입력값 정보
y : 가중치와 편향으로 연산된 logits
'''
Y = 1 / (1 + np.exp(-y))
# 출력값 Y : 활성화함수를 거친 최종 확률값
return Y- 활성화 함수 동작 테스트
# 활성화 함수의 입력값은 가중치와 편향으로 연산된 logits
example_y = np.matmul(X_train, weights) + bias
# sigmoid 함수를 통해 활성화된 값 (y -> Y)
example_Y = sigmoid(example_y)
example_Y
'''
array([[9.36261105e-01],
[3.25912897e-02],
[3.59524073e-03],
[2.09300382e-01],
[1.68039415e-05],
[9.27956277e-01],
[1.47634941e-04],
[7.76953393e-03],
[4.84303536e-01],
[5.85196546e-01],
[8.66369531e-01],
[9.99424567e-01],
[9.99983740e-01],
[5.71237392e-02],
[9.63730717e-01],
[1.78848448e-01]])
'''⚙️ 기능 3-5. 손실함수 : sigmoid_crossentropy_logits()
- 순전파, 검증, 학습에서 쓰일 손실함수를 정의함
- 손실함수는 과제 조건에 따라
이진 교차 엔트로피(binary cross entropy)로 정의
- 손실함수는 과제 조건에 따라
- 가중합 연산을 통해 얻은
logits로 활성화함수 적용과 손실값 계산은 한번에 처리함- 여기서
logits란 활성화함수를 거치지 않은 Raw Output을 의미함 - 활성화 함수를 거친 확률값으로 손실값을 계산하는 경우
- 순전파과정까진 문제가 없음
- 그러나 학습과정에서 파이썬에서 허용하는 연산의 범위를 초과해버리기 때문에
logit을 통해 구하는 방식을 채택하는게 좋음
- 이러한 계산 방식은 tensorflow에도 구현되고 권장하는 계산방법임
- tf.nn.sigmoid_cross_entropy_with_logits
- https://www.tensorflow.org/api_docs/python/tf/nn/sigmoid_cross_entropy_with_logits
- 여기서
sigmoid_cross_entropy_with_logits공식 유도- cross_entropy :
- 엔트로피
- label의 추정 확률
- logit y에 대응하는 예측확률
binary_cross_entropy:- 정답 label값 :
- 가중합 연산에 의한 logit :
- 엔트로피
- label의 추정 확률
binary: 참일확률 , 거짓일확률
- logit y에 대응하는 예측확률
binary: 참 , 거짓
- cross_entropy :
sigmoid_crossentropy_logits최종 공식
# 손실 함수 기능 (from_logits=True, 활성화 기능과 손실함수 기능을 한번에 실시함)
def sigmoid_crossentropy_logits(z, y):
'''
입력값 정보
z : 정답 data (Label data)
y : 가중치와 편향으로 연산된 logits
'''
E = y*(1-z) + np.log(1 + np.exp(-y))
# 출력값 E : 손실값
return E- 손실함수 동작 테스트
# 손실함수로 계산된 손실값 (z,y -> E)
example_E = sigmoid_crossentropy_logits(y_train, example_y)
example_E
'''
array([[2.75296031e+00],
[3.31342149e-02],
[3.60171914e-03],
[1.56398482e+00],
[1.09938971e+01],
[2.63048208e+00],
[8.82076795e+00],
[4.85754510e+00],
[6.62236934e-01],
[8.79950475e-01],
[2.01267698e+00],
[7.46038778e+00],
[1.10267942e+01],
[5.88202237e-02],
[3.31678409e+00],
[1.97047592e-01]])
'''⚙️ 기능 3-6. 손실함수 편미분함수 : sigmoid_crossentropy_logits_prime()
- 역전파 과정에서 쓰일 편미분 함수를 정의함
- 앞서서
logit으로 활성화와 손실계산을 한번에 연산했기 때문에 편미분 또한 이와 동일하게 입력값으로label과logit을 입력하여 연산을 진행함 dE/dY*dY/dy두 계산 단계를dE/dy로 바로 처리할 수 있으므로 연산 속도면에서도 훨씬 괜찮은 방식임
- 앞서서
- 즉
logit (y)로 편미분하여logit에대한 순간 기울기를 구할 수 있고, 이를X(=dy/dw)와 행렬 곱해주면 가중치를 업데이트 할 수 있으며, 편향 또한dE/dy의 합으로써 업데이트 해줄 수 있게 된다 dE/dy편미분 공식 유도sigmoid_crossentropy_logits_prime최종 공식
# 역전파를 위한 손실함수 편미분함수(logit값으로 바로 편미분하여 활성화함수의 편미분 단계를 건너뜀)
def sigmoid_crossentropy_logits_prime(z, y):
'''
입력값 정보
z : 정답 data (Label data)
y : 가중치와 편향으로 연산된 logits
'''
dE_dy = -z + sigmoid(y)
# 출력값 dE_dy : 손실값 E를 logit값 y로 편미분하여 얻어낸 기울기값
return dE_dy- 손실함수 편미분 함수 동작 테스트
# 손실값 E를 logit값 y로 편미분하여 얻어낸 기울기값 (z,y -> dE/dy)
example_dE_dy = sigmoid_crossentropy_logits_prime(y_train, example_y)
example_dE_dy
'''
array([[ 0.9362611 ],
[ 0.03259129],
[ 0.00359524],
[-0.79069962],
[-0.9999832 ],
[ 0.92795628],
[-0.99985237],
[-0.99223047],
[ 0.48430354],
[ 0.58519655],
[ 0.86636953],
[ 0.99942457],
[ 0.99998374],
[ 0.05712374],
[ 0.96373072],
[ 0.17884845]])
'''⚙️ 기능 3-7. 정확도 연산 기능 : accuracy_score()

numpy의 기능들을 활용하여 정확도를 계산하는 함수를 정의0(False),1(True)로 이뤄진 Boolean을 계산하는 방식으로 연산 과정을 간단하게 수행함
- 입력은 손실함수와 마찬가지로
logit과label값을 입력함
# 정확도 연산 기능
def accuracy_score(z, y):
'''
입력값 정보
z : 정답 data (Label data)
y : 가중치와 편향으로 연산된 logits
'''
# pred : logit의 부호에 따라서 boolean으로 반환 (0이하는 False(0), 0초과는 True(1))
pred = np.greater(y, 0)
# real : 0과 1로 이뤄진 label data를 boolean으로 반환 (0은 False(0), 1은 True(1))
real = np.greater(z, 0.5)
# correct : 예측이 label과 같은 경우 True(1)로 반환
correct = np.equal(pred, real)
# accuracy : correct를 평균내면 Boolean이 int로 연산되어 정확도가 바로 구해진다
accuracy = np.mean(correct)
# 출력값 : accuracy
return accuracy- 정확도 연산 기능 동작 테스트
accuracy_score(y_train, example_y)
'''
0.3125
'''2-6. 🧠인공신경망 (순전파, 예측, 검증)
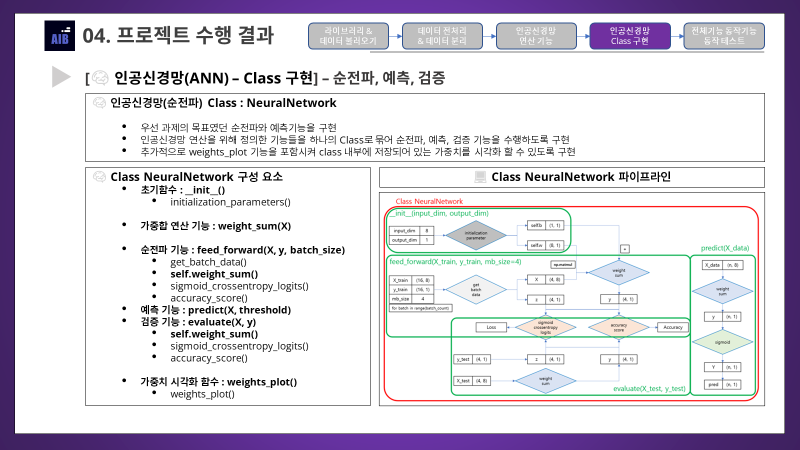
- 우선 과제에서 제시한 목표인 순전파와 예측기능을 구현하고, 검증 또한 순전파만 진행하므로 함께 구현함
순전파 인공신경망 클래스(Class)구성요소- 초기함수(
__init__)- 입력값 :
input_dim(입력층 노드수),output_dim(출력층 노드수) - 가중치, 편향 생성 기능인
initialization_parameter함수를 이용 - class에서 전역적으로 사용하도록
self.w,self.b로 저장한다
- 입력값 :
- 가중합 연산 기능 :
weight_sum(X)- 가중치와 편향에대한 연산 결과 값(
logit)을 얻어내는 기능 X값을 입력받아 가중치와 행렬곱을 하고 편향을 더해y값(logit값)을 출력한다
- 가중치와 편향에대한 연산 결과 값(
- 순전파 기능 :
feed_forward(X, y, batch_size, verbose)batch size를 고려해get_batch_data함수를 이용해 mini-batch 데이터를 얻어냄- batch별로 연산을 반복적으로 수행하고, 평균 손실값과 평균 정확도를 출력한다
verbose옵션을 통해 출력을 하지 않을지, batch별 결과까지 출력할지 결정한다
- 예측 기능 :
predict(X, threshold)X값을 입력 받고 순전파와 활성화 함수를 거친 뒤에 확률값을threshold를 기준으로0과1로 반환한다numpy.where함수를 이용함
- 검증 기능 :
evaluate(X, y)X값과label값을 입력받아서 순전파를 진행하고 손실과 정확도를 출력하는 함수- test data를 입력하여 일반화 가능성을 확인하는 용도
- 가중치 시각화 함수 :
weights_plot()- 이전에 정의한
weights_plot함수를 그대로 실행함 - 입력값은 class에 전역적으로 저장되어있는
self.w
- 이전에 정의한
- 초기함수(
# 순전파까지만 Class로 구현해보기(이후 추가기능들은 상속을 통해 추가할 예정)
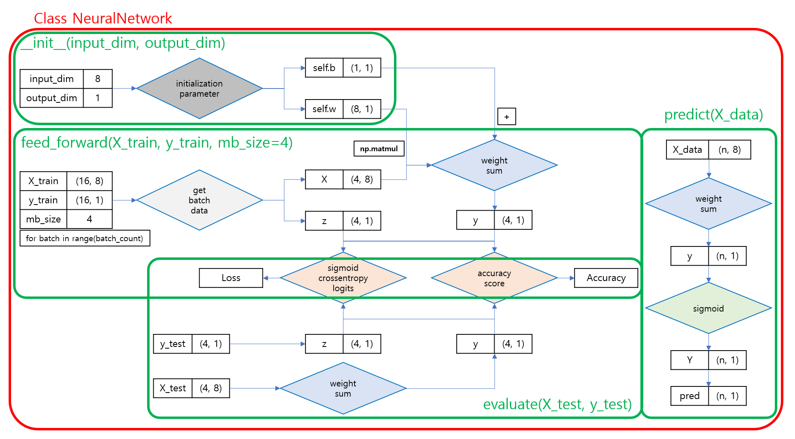
class NeuralNetwork:
# 초기함수(Class 선언시 실행되는 초기 함수)
def __init__(self, input_dim, output_dim):
'''
입력값 정보
input_dim : 입력층 노드 수
output_dim : 출력층 노드 수
'''
# initialization_parameter 함수를 실행시켜 초기 가중치와 편향을 저장
self.w, self.b = initialization_parameter(input_dim, output_dim)
# 가중합 함수 (가중치와 편향에대한 연산 결과 값(logit)을 얻어내는 기능)
def weight_sum(self, X):
'''
입력값 정보
X : 독립변수(x1~x8)
'''
# y : X와 가중치행렬(self.w)의 행렬곱 + 편향값
y = np.matmul(X, self.w) + self.b
return y
# 순전파 기능(학습과정이 아닌 단순 순전파 기능)
def feed_forward(self, X_data, y_data, mb_size, verbose=1):
'''
입력값 정보
X_data : input 변수(x1~x8), X_train
y_data : label 변수(y), y_train
mb_size : Mini-Batch 크기
verbose : 기본값은 1, 훈련 결과를 출력 할지 여부를 결정함
verbose = 0 : 출력안함
verbose = 1 : 1 epoch에 대한 평균 loss와 accuracy출력
verbose = 2 : batch별 데이터까지 함께 출력
'''
# Batch 갯수를 계산
batch_count = int(X_data.shape[0]) // mb_size
# 손실과 정확도를 담을 빈 리스트를 생성
losses, accs = [], []
# for 문으로 batch 연산을 반복함
for batch in range(batch_count):
# X(input), z(label)를 get_batch_data 함수로부터 얻어냄
X, z = get_batch_data(X_data, y_data, size=mb_size, n=batch)
# X(input) -> y(가중합) 연산
y = self.weight_sum(X=X)
# 각 값들의 손실값(E) 연산
E = sigmoid_crossentropy_logits(z=z, y=y)
# loss : 미니배치의 평균 손실값
loss = np.mean(E)
# accuracy : 미니배치의 정확도값
accuracy = accuracy_score(z=z, y=y)
# 손실값과 정확도를 리스트에 append하기(소수점 셋째자리로 반올림)
losses.append(round(loss, 3))
accs.append(round(accuracy, 3))
# verbose 기능(기본값은 1)
if verbose in [1,2]:
# 평균 loss와 평균 accuracy를 출력(소수점 셋째자리로 반올림)
print("[Epoch 1] TrainData - Loss = {:.3f}, Accuracy = {:.3f}"
.format(np.mean(losses), np.mean(accs)))
if verbose == 2:
# 각 배치별 loss와 accuracy를 확인하기 위한 출력(verbose==2로 설정해야 보임)
print(f"\tBatch Size : {mb_size}\n\tMini-Batches : {batch_count}\
\n\tLoss : {losses}\n\tAccuracy : {accs}")
elif verbose == 0:
# verbose = 0 으로 주어지면 출력안하고 pass함
pass
# 예측 기능(prediction, ndarray로 반환함)
def predict(self, X_data, threshold=0.5):
'''
입력값 정보
X_data : input 변수(x1~x8)
threshold : 기본값은 0.5, 0과 1을 구분할 임계치(기준선)
'''
# 가중합 연산
y = self.weight_sum(X_data)
# 활성화 함수를 거쳐 확률값을 얻음
Y = sigmoid(y)
# Threshold보다 작으면 0으로 예측, 크거나 같으면 1로 예측
pred = np.where(Y < threshold, 0, 1)
# 출력 : 예측값(ndarray)
return pred
# 검증 기능(evaluation, 테스트 데이터에 대한 순전파 결과를 바로 출력)
def evaluate(self, X_data, y_data):
'''
입력값 정보
X_data : input 변수(x1~x8), X_test
y_data : label 변수(y), y_test
'''
# X(input), z(label) 정의
X, z = X_data, y_data
# 가중합(logits) 연산
y = self.weight_sum(X_data)
# 평균 loss값 연산
loss = np.mean(sigmoid_crossentropy_logits(z=z, y=y))
# 평균 accuracy 연산
accuracy = accuracy_score(z=z, y=y)
# 검증 결과 출력하기 (소수점 셋째자리로 반올림)
print("[Evaluation] TestData - Loss = {:.3f}, Accuracy = {:.3f}".format(loss, accuracy))
# 가중치 시각화 함수(가중치 변화를 확인해보기 위해 class내부에 포함시켰음)
def weights_plot(self):
# self.w로 저장되어있는 가중치를 bar plot으로 시각화함
weights_plot(self.w)- 순전파 인공신경망 동작 테스트
# 인공신경망 인스턴스 생성(class 선언)
NN_1 = NeuralNetwork(input_dim=8, output_dim=1)
# 초기 가중치와 편향을 확인하기
print(f"weights\n{NN_1.w}")
print(f"\nbias : {NN_1.b}")
'''
weights
[[ 0.71167353]
[-0.32448496]
[-1.00187064]
[ 0.23625079]
[-0.10215984]
[-1.14129263]
[ 2.65440726]
[ 1.44060519]]
bias : [0.09890227]
'''# 가중치 시각화
NN_1.weights_plot()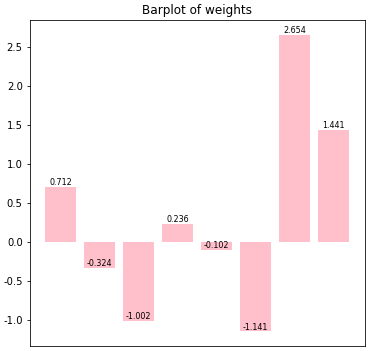
# Batch size 4로 설정해 순전파를 진행해본다
NN_1.feed_forward(X_train, y_train, mb_size=4)
'''
[Epoch 1] TrainData - Loss = 3.579, Accuracy = 0.312
'''# verbose기능 테스트(verbose=2)
NN_1.feed_forward(X_train, y_train, mb_size=4, verbose=2)
'''
[Epoch 1] TrainData - Loss = 3.579, Accuracy = 0.312
Batch Size : 4
Mini-Batches : 4
Loss : [1.088, 6.826, 2.754, 3.65]
Accuracy : [0.5, 0.0, 0.25, 0.5]
'''# predict 기능 테스트
pred_train = NN_1.predict(X_train)
print(pred_train)
print('Accuracy : {:.3f}'.format(accuracy_score(y_train, pred_train)))
'''
[[1]
[0]
[0]
[0]
[0]
[1]
[0]
[0]
[0]
[1]
[1]
[1]
[1]
[0]
[1]
[0]]
Accuracy : 0.312
'''# test data로 evaluation 테스트 해보기
NN_1.evaluate(X_test, y_test)
'''
[Evaluation] TestData - Loss = 3.932, Accuracy = 0.250
'''2-7. 🧠인공신경망 (역전파, 학습)

- 추가적으로 기존 순전파 인공신경망을 상속받아서 역전파, 학습 기능을 추가해본다
- 학습 인공신경망 클래스(Class) 구성 요소
- 초기함수(
__init__)- 순전파 함수의 초기함수를
super()로 가져와서 그대로 실행함 - 초기 가중치와 편향이
self.w,self.b에 저장된다
- 순전파 함수의 초기함수를
- 역전파 기능 :
feed_backward(X,z,y)입력층(X),label(z),logit(y)을 입력받고 가중치와 편향의 순간기울기를 구한다dE/dy는sigmoid_crossentropy_logits_prime함수로 구함dE/dw는X의 역행렬(dy/dw)과dE/dy의 행렬곱으로 구함dE/db는dE/dy의 열방향(axis=0) 합계로 구함dE/dw와dE/db는 클래스에서 전역적으로 사용되도록self.dE_dw,self.dE_db로 저장한다
- 학습기능 :
training(X, y, batch_size, epoch, learning_rate, verbose)- 지정한
epoch 수만큼 순전파, 역전파, 가중치편향 업데이트를 수행한다 - 배치를 고려해
미니배치로 연산을 진행하고, 손실값과 정확도를 구한다 X값(입력),z값(label),y값(logit값)으로 역전파를 진행하고 가중치와 편향을 학습률과 곱해서 업데이트를 진행한다- 한 epoch가 끝나면 평균 손실값과 정확도를
self.history딕셔너리에 저장해두고 다음 epoch로 반복을 실시한다 verbose을 통해 출력을 하지 않을지, 배치별 데이터까지 모두 확인할지 결정한다
- 지정한
- 초기함수(

# 이전에 정의한 NeuralNetwork class를 상속받고 추가적으로 역전파와 학습기능을 구현하기
class NeuralNetwork_additional(NeuralNetwork):
# 초기함수(Class 선언시 실행되는 초기함수 : 상속받아서 그대로 사용함)
def __init__(self, input_dim, output_dim):
'''
입력값 정보
input_dim : 입력층 노드 수
output_dim : 출력층 노드 수
'''
# super()를 통해서 self.w, self.b 변수정보를 그대로 받아와서 실행함
super().__init__(input_dim, output_dim)
# 역전파 기능 (활성화 단계도 함께 계산하는 sigmoid_crossentropy_with_logits 방식 사용)
def feed_backward(self, X, z, y):
'''
입력값 정보
X : input 변수(x1~x8), X_train
z : label 변수(y), y_train
y : 가중합 연산을 통해 얻은 logits
'''
# dE/dy 연산 (sigmoid_crossentropy_logits_prime)
dE_dy = sigmoid_crossentropy_logits_prime(z=z, y=y)
# dy/dw = X의 역행렬(transpose)
dy_dw = X.T
# dE/dw 가중치 기울기값 연산 (matmul을 통한 행렬곱)
self.dE_dw = np.matmul(dy_dw, dE_dy)
# dE/db 편향 기울기값 연산 (dE/dy의 합), bias와 형태 맞추기위해 axis=0으로 설정(열 방향)
self.dE_db = np.sum(dE_dy, axis=0) # (4x1) -> (1x1)
# 학습 기능 (Epoch별 batch를 고려한 학습을 진행)
def training(self, X_data, y_data, mb_size, epochs, learning_rate=1, verbose=1):
'''
입력값 정보
X_data : input 변수(x1~x8), X_train
y_data : label 변수(y), y_train
mb_size : Mini-Batch 크기
epochs : Epoch 수
learning_rate : 기본값은 1로 설정함, 학습률
verbose : 기본값은 1, 훈련 결과를 출력 할지 여부를 결정함
verbose = 0 : 출력안함
verbose = 1 : 1 epoch에 대한 평균 loss와 accuracy출력
verbose = 2 : batch별 데이터까지 함께 출력
'''
# learning_rate를 lr로 저장함
lr = learning_rate
# Batch 갯수를 계산
batch_count = int(X_data.shape[0]) // mb_size
# Epoch별 손실과 정확도 리스트를 담을 history 딕셔너리를 지정
self.history = {'Loss': [], 'Accuracy': []}
# 지정한 epoch 수에 따라서 반복을 진행
for epoch in range(epochs):
# 손실과 정확도를 담을 빈 리스트 지정(epoch마다 초기화됨)
losses, accs = [], []
# batch 단위로 반복을 진행함
for batch in range(batch_count):
# X(input), z(label)를 get_batch_data 함수로부터 얻어냄
X, z = get_batch_data(X_data, y_data, size=mb_size, n=batch)
# X(input) -> y(가중합) 연산
y = self.weight_sum(X=X)
# 각 값들의 손실값(E) 연산
E = sigmoid_crossentropy_logits(z=z, y=y)
# loss : 미니배치의 평균 손실값
loss = np.mean(E)
# accuracy : 미니배치의 정확도값
accuracy = accuracy_score(z=z, y=y)
# 손실값과 정확도값을 append (소수점 셋째자리로 반올림)
losses.append(round(loss, 3))
accs.append(round(accuracy, 3))
# 역전파 실시(self.dE_dw, self.dE_db가 업데이트 됨)
self.feed_backward(X=X, z=z, y=y)
# 가중치 업데이트 실시
self.w -= lr*self.dE_dw
# 편향 업데이트 실시
self.b -= lr*self.dE_db
# epoch당 평균 loss와 평균 accuracy를 딕셔너리의 리스트에 append (소수점 셋째자리로 반올림)
self.history['Loss'].append(round(np.mean(losses), 3))
self.history['Accuracy'].append(round(np.mean(accs), 3))
# verbose 기능(기본값은 1)
if verbose in [1,2]:
# 평균 loss와 평균 accuracy를 출력(소수점 셋째자리로 반올림)
print("\n[Epoch {}/{}] TrainData - Loss = {:.3f}, Accuracy = {:.3f}"
.format(epoch+1, epochs, np.mean(losses), np.mean(accs)))
if verbose == 2:
# 각 배치별 loss와 accuracy를 확인하기 위한 출력(verbose==2로 설정해야 보임)
print(f"\tBatch Size : {mb_size}\n\tMini-Batchs : {batch_count}\
\n\tLoss : {losses}\n\tAccurracy : {accs}")
elif verbose == 0:
# verbose = 0 으로 주어지면 출력안하고 pass함
pass- 추가구현된 학습 인공신경망 동작 테스트
# 인공신경망 인스턴스 생성(class 선언)
NN_2 = NeuralNetwork_additional(input_dim=8, output_dim=1)
# 초기 가중치와 편향을 확인하기
print(f"weights\n{NN_2.w}")
print(f"\nbias : {NN_2.b}")
'''
weights
[[ 0.71167353]
[-0.32448496]
[-1.00187064]
[ 0.23625079]
[-0.10215984]
[-1.14129263]
[ 2.65440726]
[ 1.44060519]]
bias : [0.09890227]
'''# 초기 가중치 시각화
NN_2.weights_plot()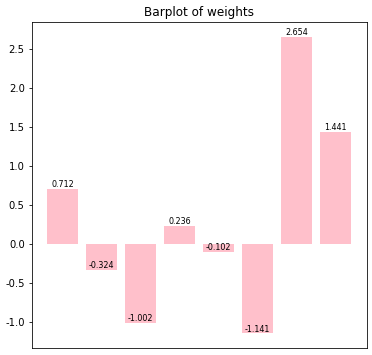
# 학습 테스트
NN_2.training(X_train, y_train, mb_size=4, epochs=10, learning_rate=0.1)
'''
[Epoch 1/10] TrainData - Loss = 2.815, Accuracy = 0.312
[Epoch 2/10] TrainData - Loss = 0.757, Accuracy = 0.562
[Epoch 3/10] TrainData - Loss = 0.408, Accuracy = 0.812
[Epoch 4/10] TrainData - Loss = 0.322, Accuracy = 0.875
[Epoch 5/10] TrainData - Loss = 0.294, Accuracy = 0.875
[Epoch 6/10] TrainData - Loss = 0.281, Accuracy = 0.875
[Epoch 7/10] TrainData - Loss = 0.272, Accuracy = 0.812
[Epoch 8/10] TrainData - Loss = 0.265, Accuracy = 0.812
[Epoch 9/10] TrainData - Loss = 0.260, Accuracy = 0.812
[Epoch 10/10] TrainData - Loss = 0.256, Accuracy = 0.812
'''# 학습 후 가중치 변화 확인
NN_2.weights_plot()
- 학습 인공신경망 추가 테스트
# verbose = 2로 설정해서 테스트 진행(학습률과 epoch도 조절해봄)
NN_3 = NeuralNetwork_additional(input_dim=8, output_dim=1)
NN_3.training(X_train, y_train, mb_size=4, epochs=5, learning_rate=1, verbose=2)
'''
[Epoch 1/5] TrainData - Loss = 1.396, Accuracy = 0.562
Batch Size : 4
Mini-Batchs : 4
Loss : [1.088, 2.995, 1.432, 0.07]
Accurracy : [0.5, 0.0, 0.75, 1.0]
[Epoch 2/5] TrainData - Loss = 0.830, Accuracy = 0.812
Batch Size : 4
Mini-Batchs : 4
Loss : [2.333, 0.292, 0.691, 0.005]
Accurracy : [0.75, 0.75, 0.75, 1.0]
[Epoch 3/5] TrainData - Loss = 0.658, Accuracy = 0.812
Batch Size : 4
Mini-Batchs : 4
Loss : [1.398, 0.978, 0.256, 0.002]
Accurracy : [0.75, 0.75, 0.75, 1.0]
[Epoch 4/5] TrainData - Loss = 0.589, Accuracy = 0.875
Batch Size : 4
Mini-Batchs : 4
Loss : [0.909, 1.303, 0.143, 0.001]
Accurracy : [0.75, 0.75, 1.0, 1.0]
[Epoch 5/5] TrainData - Loss = 0.495, Accuracy = 0.875
Batch Size : 4
Mini-Batchs : 4
Loss : [0.484, 1.37, 0.125, 0.001]
Accurracy : [0.75, 0.75, 1.0, 1.0]
'''📈 기능3-8. 학습 곡선 시각화 기능 : plot_history()
- Class 내부에서 저장했었던 self.history 딕셔너리를 시각화하여 epoch에 따른 손실함수 및 정확도의 변화를 시각화한다
- matplotlib을 활용하여 시각화 진행
# 학습 곡선 시각화 기능
def plot_history(NN, key, show_value=False, show_xticks=False):
'''
입력값 정보
NN : NeuralNetwork 인스턴스
key : history변수의 key값, 'Loss' or 'Accuracy'
show_value : 그래프에 값을 표시할지 여부 (기본값은 False로 설정)
show_xticks : 그래프에 x축 값을 표시할지 여부 (기본값은 False로 설정)
'''
# 그래프 y 값 : key에 해당하는 리스트
y = NN.history[key]
# 그래프 x 값 : epoch(1 ~ y길이)
x = np.arange(len(y))+1
# 그래프 크기를 6x6으로 설정
plt.figure(figsize=(6,6))
# 선그래프 plot ('o-': 점표시)
plt.plot(y, 'o-', color='orange')
if show_xticks == True:
# x축 눈금 설정
plt.xticks(np.arange(len(y)), labels=x)
elif show_xticks == False:
plt.xticks([])
# y축 범위 설정
ylim = [0 , np.trunc(max(y)+1)]
plt.ylim(ylim)
# 축 이름, 제목 설정
plt.xlabel("Epoch")
plt.ylabel(f"{key}")
plt.title(f'History of "{key}" in Neural Network')
if show_value == True:
# 그래프에 데이터 값을 표시하기
for i in range(len(x)):
height = y[i]
plt.text(x[i]-1, height + ylim[1]/100, '%.3f' % height,
ha='center', va='bottom', size = 8)
plt.show()- 학습곡선 동작 테스트 1
# 테스트용 ANN 새로 지정
NN_4 = NeuralNetwork_additional(input_dim=8, output_dim=1)
# 학습 진행 (verbose=0으로 출력 안함)
NN_4.training(X_train, y_train, mb_size=4, epochs=50, learning_rate=0.05, verbose=0)
# 학습 그래프 확인
plot_history(NN_4, key = "Loss")
plot_history(NN_4, key = "Accuracy")
- 학습곡선 동작 테스트 2
# 테스트용 ANN 새로 지정
NN_5 = NeuralNetwork_additional(input_dim=8, output_dim=1)
# 학습 진행
NN_5.training(X_train, y_train, mb_size=4, epochs=10, learning_rate=0.5, verbose=0)
# history 출력
print(NN_5.history)
'''
{'Loss': [1.727, 0.42, 0.362, 0.337, 0.324, 0.314, 0.304, 0.294, 0.285, 0.277],
'Accuracy': [0.562, 0.812, 0.812, 0.812, 0.812, 0.875, 0.875, 0.875, 0.875, 0.875]}
'''# 학습 그래프 확인
plot_history(NN_5, key = "Loss", show_xticks=True, show_value=True)
plot_history(NN_5, key = "Accuracy", show_xticks=True, show_value=True)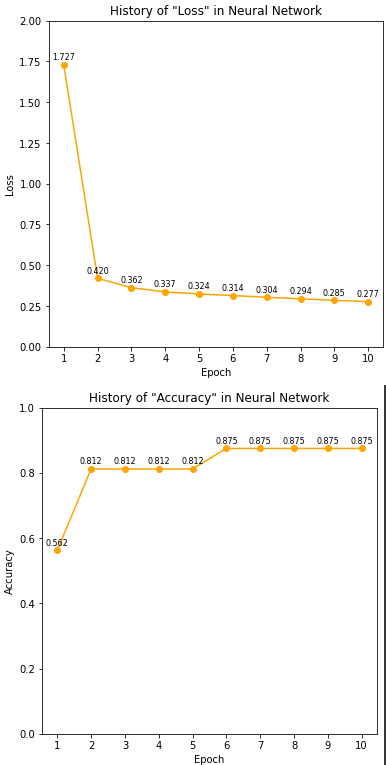
2-8. 💽전체 기능 동작 기능
💽 기능 4-1. 전체 기능 동작 기능(순전파) : main()
def main():
# 1-1. 데이터 불러오기 기능
df = data_load(filepath=csv_dir)
# 2-1. 데이터 뒤섞기 기능
df_sf = data_shuffle(df)
# 2-2. 데이터 표준화 기능
df_sc = standard_scaler(df_sf, output_dim=1)
# 2-3. 학습 및 테스트 데이터 분리 기능
train, test = train_test_split(df_sc, train_ratio=0.8, batch_size=4)
# 2-4. 독립변수 및 종속변수 분리
X_train, y_train = X_y_split(train, output_dim=1)
X_test, y_test = X_y_split(test, output_dim=1)
# 3. 인공신경망(ANN) - 순전파 (가중치 편향 생성 기능 포함)
NN = NeuralNetwork(input_dim=8, output_dim=1)
NN.feed_forward(X_train, y_train, mb_size=4, verbose=1)# main 함수 실행
main()
'''
[Epoch 1] TrainData - Loss = 3.579, Accuracy = 0.312
'''💽 기능 4-2. 전체 기능 동작 기능(학습, 시각화, 예측, 검증) : main_additional()

def main_additional():
# 1-1. 데이터 불러오기 기능
df = data_load(filepath=csv_dir)
# 2-1. 데이터 뒤섞기 기능
df_sf = data_shuffle(df)
# 2-2. 데이터 표준화 기능
df_sc = standard_scaler(df_sf, output_dim=1)
# 2-3. 학습 및 테스트 데이터 분리 기능
train, test = train_test_split(df_sc, train_ratio=0.8, batch_size=4)
# 2-4. 독립변수 및 종속변수 분리
X_train, y_train = X_y_split(train, output_dim=1)
X_test, y_test = X_y_split(test, output_dim=1)
# 3-1. 인공신경망(ANN) - 역전파, 학습 추가 구현
NN = NeuralNetwork_additional(input_dim=8, output_dim=1)
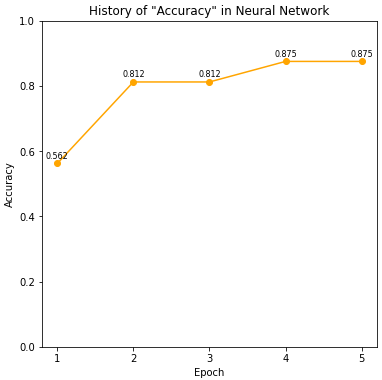
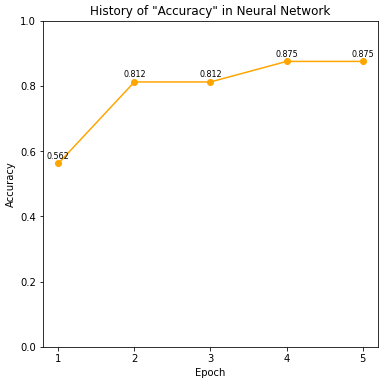
NN.training(X_train, y_train, mb_size=4, epochs=5, learning_rate=1, verbose=2)
# 3-2. 학습곡선 시각화
plot_history(NN, key='Accuracy', show_value=True, show_xticks=True)
# 3-3. TestData 예측
print(f"[Label_data] TestData\n{y_test}\n")
y_pred = NN.predict(X_test)
print(f"[Prediction] TestData\n{y_pred}\n")
# 3-4. TestData 검증
NN.evaluate(X_test, y_test)main_additional()'''
[Epoch 1/5] TrainData - Loss = 1.396, Accuracy = 0.562
Batch Size : 4
Mini-Batchs : 4
Loss : [1.088, 2.995, 1.432, 0.07]
Accurracy : [0.5, 0.0, 0.75, 1.0]
[Epoch 2/5] TrainData - Loss = 0.830, Accuracy = 0.812
Batch Size : 4
Mini-Batchs : 4
Loss : [2.333, 0.292, 0.691, 0.005]
Accurracy : [0.75, 0.75, 0.75, 1.0]
[Epoch 3/5] TrainData - Loss = 0.658, Accuracy = 0.812
Batch Size : 4
Mini-Batchs : 4
Loss : [1.398, 0.978, 0.256, 0.002]
Accurracy : [0.75, 0.75, 0.75, 1.0]
[Epoch 4/5] TrainData - Loss = 0.589, Accuracy = 0.875
Batch Size : 4
Mini-Batchs : 4
Loss : [0.909, 1.303, 0.143, 0.001]
Accurracy : [0.75, 0.75, 1.0, 1.0]
[Epoch 5/5] TrainData - Loss = 0.495, Accuracy = 0.875
Batch Size : 4
Mini-Batchs : 4
Loss : [0.484, 1.37, 0.125, 0.001]
Accurracy : [0.75, 0.75, 1.0, 1.0]
'''
'''
[Label_data] TestData
[[0]
[1]
[1]
[0]]
[Prediction] TestData
[[0]
[0]
[1]
[0]]
[Evaluation] TestData - Loss = 3.746, Accuracy = 0.750
'''💽 기능 4-번외. 테스트용 ipynb로부터 동일하게 함수를 실행시켜보기

- test용 파일에는 함수들만 그대로 담아두고 테스트를 진행해본다
- test용 파일에서는 어떠한 global변수도 저장하지 않았기 때문에, main함수가 함수 내부적으로 제대로 동작하는 것인지를 확인해보기 위함임
- 또한 test용 파일에서는 drive mount를 진행하지 않았기 때문에 csv파일 경로는 본 과제 파일에서 정의된 csv_dir가 이용됨
- test file 링크 : https://colab.research.google.com/drive/1hsjVs4NRumW0Nu240adbwJKIZ5o8IZja?usp=sharing
# CP1_DS_test.ipynb 파일 실행시켜 함수들을 가져오기
%run /content/drive/MyDrive/AI/CP1/CP1_DS_test.ipynb# test file에서는 main_test()함수에 main()함수의 코드를 그대로 담았음
# 본 과제 파일에서는 main_test()가 정의되어 있지 않지만, test file의 함수가 동작하는 것을 확인할 수 있음
main_test()
'''
[Epoch 1] TrainData - Loss = 3.579, Accuracy = 0.312
'''# test file에서는 main_additional_test()함수에 main_additional()함수의 코드를 그대로 담았음
# 본 과제 파일에서는 main_additional_test()가 정의되어 있지 않음,
# 그래도 test file의 함수가 동작하는 것을 확인할 수 있음
main_additional_test()'''
[Epoch 1/5] TrainData - Loss = 1.396, Accuracy = 0.562
Batch Size : 4
Mini-Batchs : 4
Loss : [1.088, 2.995, 1.432, 0.07]
Accurracy : [0.5, 0.0, 0.75, 1.0]
[Epoch 2/5] TrainData - Loss = 0.830, Accuracy = 0.812
Batch Size : 4
Mini-Batchs : 4
Loss : [2.333, 0.292, 0.691, 0.005]
Accurracy : [0.75, 0.75, 0.75, 1.0]
[Epoch 3/5] TrainData - Loss = 0.658, Accuracy = 0.812
Batch Size : 4
Mini-Batchs : 4
Loss : [1.398, 0.978, 0.256, 0.002]
Accurracy : [0.75, 0.75, 0.75, 1.0]
[Epoch 4/5] TrainData - Loss = 0.589, Accuracy = 0.875
Batch Size : 4
Mini-Batchs : 4
Loss : [0.909, 1.303, 0.143, 0.001]
Accurracy : [0.75, 0.75, 1.0, 1.0]
[Epoch 5/5] TrainData - Loss = 0.495, Accuracy = 0.875
Batch Size : 4
Mini-Batchs : 4
Loss : [0.484, 1.37, 0.125, 0.001]
Accurracy : [0.75, 0.75, 1.0, 1.0]
'''
'''
[Label_data] TestData
[[0]
[1]
[1]
[0]]
[Prediction] TestData
[[0]
[0]
[1]
[0]]
[Evaluation] TestData - Loss = 3.746, Accuracy = 0.750
'''3. Conclusion (결론)
3-1. 🏆프로젝트 핵심 요약 (Key Takeaways)
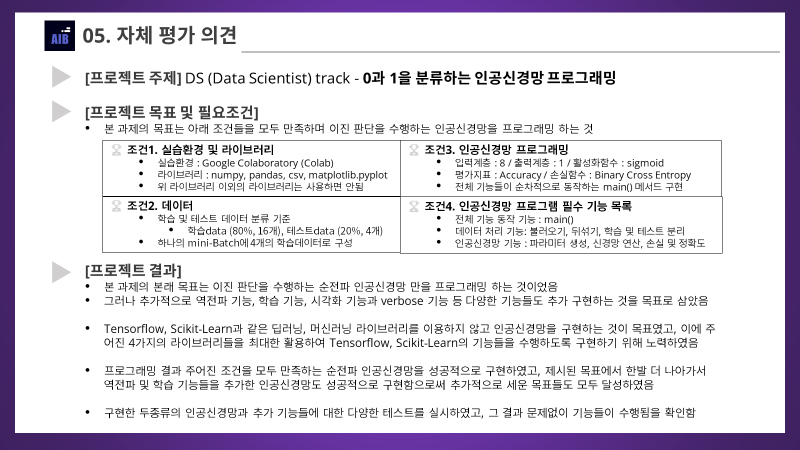
-
프로젝트 주제 : DS (Data Scientist) track - 0과 1을 분류하는 인공신경망 프로그래밍
-
프로젝트 결과
-
본 과제의 본래 목표는 이진 판단을 수행하는 순전파 인공신경망 만을 프로그래밍 하는 것이었음
-
그러나 추가적으로 역전파 기능, 학습 기능, 시각화 기능과 verbose 기능 등 다양한 기능들도 추가 구현하는 것을 목표로 삼았음
-
Tensorflow, Scikit-Learn과 같은 딥러닝, 머신러닝 라이브러리를 이용하지 않고 인공신경망을 구현하는 것이 목표였고, 이에 주어진 4가지의 라이브러리들을 최대한 활용하여 Tensorflow, Scikit-Learn의 기능들을 수행하도록 구현하기 위해 노력하였음
-
프로그래밍 결과 주어진 조건을 모두 만족하는 순전파 인공신경망을 성공적으로 구현하였고, 제시된 목표에서 한발 더 나아가서 역전파 및 학습 기능들을 추가한 인공신경망도 성공적으로 구현함으로써 추가적으로 세운 목표들도 모두 달성하였음
-
구현한 두종류의 인공신경망과 추가 기능들에 대한 다양한 테스트를 실시하였고, 그 결과 문제없이 기능들이 수행됨을 확인함
-
3-2. 🍷느낀점, 회고 (My Takeaways)

-
좋았던 점
-
제한된 라이브러리를 통해 Tensorflow, Scikit-Learn의 기능들을 수행하도록 구현해야 했기 때문에 해당 기능들의 작동 방식에 대한 기초적인 이해가 필요했고, 이에 그동안 배웠던 개념들을 복습하면서 정리해 볼 수 있었던 유용한 시간이었음
-
각각의 기능들을 정의하고 이러한 기능들을 한데 묶어 구현함으로써 객체 지향 프로그래밍에 대한 이해가 더 깊어진 것 같고, 앞으로 어떠한 부분들을 공부해 가면 좋을지 감이 잡히는 것 같아서 좋았음
-
프로그래밍 과정에서 크고 작은 오류들을 경험하고 이를 해결하기 위해 노력하였고, 발생가능한 예외 상황들을 최대한 반영하기 위해 예외처리를 하는 과정을 수행함으로써 결과적으로는 완성도가 높은 프로그램이 완성된 것 같아서 비교적 만족스러웠음
-
구현에 필요한 수학 공식들을 다시 증명해보고 복습해보면서 개인적으로 즐거움과 성취감을 느낄 수 있었고, 이러한 감정들을 통해서 데이터 사이언스(DS)가 개인적인 적성과 가장 잘 맞는 것을 다시 한번 확인 해 볼 수 있어서 좋았음
-
-
아쉬운 점
-
주어진 데이터가 아닌 다른 데이터로 테스트할 만큼의 시간적 여유는 없어서 그런지 다른 일반적인 데이터에도 기능들을 일반화 시켜서 이용할 수 있을지 확인해보지 못한 점이 아쉬움으로 남아있음
-
준비한 자료들을 하나의 ppt에 모두 담아내려 하다 보니 ppt 디자인이 전반적으로 복잡하게 구성되었는데, 좀 더 깔끔하게 정리하지 못한 점이 아쉬움으로 남아있음
-
만약 데이터가 방대한 경우에도 오류 없이 동작하는지, 수행속도면에서도 효율적인지 확인해보지 못한점이 아쉬움으로 남아있음
-
프로젝트 회고
-
Section5까지의 교육과정을 끝낸뒤에 프로젝트 기간에 실시된 첫번째 프로젝트가 무사히 끝났다. 포기않고 마무리한 내 자신에게 스스로 쓰담쓰담 해줘야겠다.
-
2주동안 진행되는 줄 알고 주제가 상당히 어려울 것이라 예상했었는데, 막상 프로젝트는 제한시간이 일주일 밖에 되지 않았고, 그래도 주제는 어렵지는 않아서 무리없이 진행할 수 있었고 그래도 어찌저찌 ppt와 블로그 정리까지 무사히 마칠 만큼 시간적 여유가 있긴 했었다.
-
사실 코드스테이츠에서 제시한 기존 목표였던 순전파 프로그래밍의 경우 프로젝트 주제가 정해지고 프로젝트를 시작하고서 단 하루도 지나지 않아 구현을 성공하긴 했었다. 다만 인공신경망에 대해 제대로 이해하기 위해선 역전파 과정과 학습 과정이 더 중요하다고 생각했기 때문에 추가적으로 역전파와 학습을 구현하기로 목표를 세우고 프로젝트를 다시 진행하게 되었다.
-
하루만에 코딩을 마쳤던 순전파 과정과는 달리 역전파와 학습의 경우 고려해야할 사항들이 많았고 무작정 코딩을 진행하다보니 수많은 오류들을 접하면서 난관에 봉착하긴 했었다. 그래서 차분하게 기초 공식들부터 복습하고 증명해보면서 오류들의 원인 파악과 더 효율적인 프로그래밍이 가능했던 것 같다.
-
Colab으로 정리하기 이전에는 VSCode로 일단 코딩을 진행했었기 때문에 디버깅을 수행하면서 어떠한 기능 때문에 오류가 발생했는지, 그에 따라 어떠한 기능의 코드를 수정해야 오류가 해결될지 알 수 있었고, 다소 코드가 길어지고 복잡해지긴 했지만, 성공적으로 역전파와 학습 기능을 추가한 인공신경망을 구현할 수 있었다.
-
코드스테이츠 AI 부트캠프 이전에 모교에서 데이터 사이언티스트 기초과정을 수료하기도 했었고, 그에따라 AI 부트캠프를 시작할 때부터 희망 직군을 데이터 사이언티스트(DS)로 정하고 시작하기도 했지만 다른 직군에 대한 가능성을 최대한 열어두면서 Section5까지 학습을 진행해 왔었다. 하지만 이번 프로젝트에서 데이터 분석가(DA)트랙이나 데이터 엔지니어(DE)트랙의 주제들을 보고나니 내 적성에 맞는 직무는 역시나 데이터 사이언티스트(DS)라는 것을 다시한번 깨달을 수 있었다.
-
코드스테이츠 AI 부트캠프에 대한 회고를 좀 더 깊게 해보자면, 이번 프로젝트를 계기로 Section1부터 Section5까지 다양한 수업들을 들으며 언제 내가 가장 흥미를 느끼고 잘해왔는지를 돌이켜볼 수 있었다. Section1에선 통계학과 선형대수학, Section2에선 머신러닝, Section3에선 데이터엔지니어링, Section4에선 딥러닝, Section5에선 컴퓨터공학 이론들을 배웠었다.
-
돌이켜보면 Section4 딥러닝 파트에서 가장 많은 스트레스를 받았었고 데이터사이언스에 대한 진로를 포기해야할까 생각도 들기도 했었다. 하지만 아무리 생각해봐도 코드스테이츠 커리큘럼과 코치들의 문제가 상당히 심각했던 Section이었기 때문이라 생각이 든다. Section3는 프론트엔드와 백엔드를 접할 수 있어서 흥미롭긴 했지만 진로를 그 쪽으로 정할 만큼은 아니었었다. 그래서 Section1, Section2, Section5가 개인적으로는 스트레스를 상대적으로 덜 받았던 것 같은데, 그 중에서도 가장 즐겁게 공부했던 Section은 Section1이었고, 프로젝트 성과가 가장 좋았던 Section은 Section2였다. 왜 그랬을까 생각해보면 아무래도 통계학이나 선형대수학에 대한 흥미가 가장 높았고 적성에도 맞았다 생각이 들었기 때문인 것 같고, 이번 프로젝트를 수행하면서도 딥러닝에서의 선형대수학 이론들을 다시 공부하면서 내 적성에 잘 맞는 것 같다고 느껴지기도해서 그런것 같기도 하다.
-
아무튼 돌고돌아서 이번 프로젝트를 통해서 희망 데이터 직군을 데이터 사이언티스트로 확실하게 결정할 수 있었던 점과 앞으로는 딥러닝 분야 쪽으로도 흥미와 관심이 다시 생겼던 점이 가장 고무적인 것 같다. 다음 프로젝트는 본격적으로 DS직무로써 기업협업 프로젝트가 진행 되는데, 어떤 기업의 데이터로 프로젝트를 진행하게 될지 기대가 된다. 한달 남짓 남은 부트캠프기간 마지막까지 힘을 내서 최선을 다해야겠다고 다짐해본다. 아자아자 파이팅 !
