
한국형 우울증 딥러닝 예측 모델 및 진단 프로그램 "Kor-DEEPression" 개발 과정 정리 및 회고.
(1) Outline & Introduction (개요 & 서론)
- (1) Outline & Introduction (개요 & 서론)
- (2) Preprocess & Database (전처리 & 데이터베이스 구축)
- (3) EDA & Dashboard (시각화 분석 & 대시보드)
- (4-1) ML / DL Modeling (모델링)
- (4-2) Final Model & Compression (최종모델 및 모델경량화)
- (5) Deployment & Conclusion (프로그램 배포 & 결론)
Kor-DEEPression
- 한국형 우울증 딥러닝 예측 모델 및 진단 프로그램
- Korean Depression Deep-Learning Model and Diagnosis Program

0. Project Outline 개요
Project Information
- 프로젝트명 : Kor-DEEPression
- 한국형 우울증 딥러닝 예측 모델 및 진단 프로그램 개발
- Development of Korean Depression Deep-Learning Model and Diagnosis Program
- Codestates AI Bootcamp CP2 project
- 자유주제 개인 프로젝트
- Full-Stack Deep-Learning Project
- DS (Data Science)
- Machine Learning & Deep Learning 모델링
- 모델 성능 평가 및 모델 개선
- 모델 경량화 (tensorflow-lite)
- DA (Data Analysis)
- EDA 및 시각화 분석
- Trend Dashboard 구현 (Looker-Studio)
- DE (Data Engineering)
- Back-end : Cloud DB 구축, 프로그램 Flask 배포
- Front-end : Web page 제작 (HTML5, CSS3)
- DS (Data Science)
- Tech Stack

Process Pipeline 파이프라인

Project Results 프로젝트 결과물
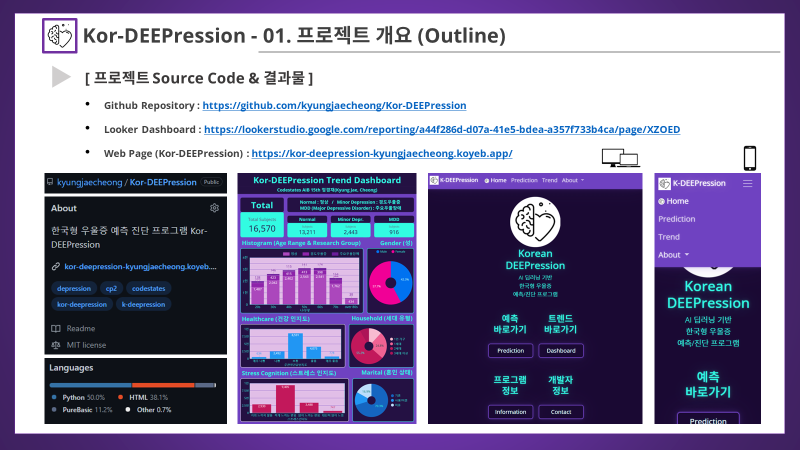
Project Index 프로젝트 목차
(Part1) Introduction 서론
- Depression & MDD
우울증과 주요우울장애 - MDD Diagnostic Criteria
MDD 진단기준 - Necessity of Research
연구 필요성 - Purpose & Benefit
목표 및 기대효과 - Dataset
선정 데이터셋 - Environments setting
개발환경 세팅
(Part2) Database 데이터베이스
- Data Preprocessing
데이터 전처리 - Cloud Database
클라우드 DB 구축 - SQL query
SQL쿼리
(Part3) Trend Analysis 트렌드 분석
- EDA
탐색적 데이터 분석 - Dashboard
대시보드
(Part4) Modeling 모델링
- Preprocessing for Modeling
모델링용 전처리 - Logistic Regression
로지스틱 회귀 - LightGBM
LGBM 모델 - MLP
다층 퍼셉트론 신경망 - 1D-CNN
합성곱층 신경망 - Final Model
최종 모델 선정 - Model Compression
모델 경량화
(Part5) Deployment 배포
- Web page Design
웹페이지 제작 - Flask app Deployment
Flask 앱 배포 - Webpage Screenshots
웹페이지 스크린샷
(Part6) Conclusion 결론
- Key Takeaways
프로젝트 핵심 - My Takeaways
느낀점 회고
1. Introduction 서론
(Part1) Introduction 서론
- Depression & MDD
우울증과 주요우울장애 - MDD Diagnostic Criteria
MDD 진단기준 - Necessity of Research
연구 필요성 - Purpose & Benefit
목표 및 기대효과 - Dataset
선정 데이터셋 - Environments setting
개발환경 세팅
1-1. Depression & MDD 우울증과 주요우울장애

우울증: 침울한 기분이나 의욕 저하가 지속되는 정신 이상 상태를 의미함주요우울장애(MDD): 우울증 상태가 지속적으로 혹은 반복적으로 나타나는 정신장애
- 우울증은 경도우울증, 중증우울증, 고도우울증으로 나뉠 수 있지만, 중증이상의 우울증은 주요우울장애에 해당할 가능성이 매우 높음.
- 따라서 우울증은 크게
경도우울증과주요우울장애두 그룹으로 분류할 수 있고, 본 프로그램 또한 이러한 접근방식으로 우울증을 두 그룹으로 분류하였음.
- 따라서 우울증은 크게
1-2. MDD Diagnostic Criteria MDD 진단기준

- DSM-IV 혹은 DSM-5의 주요우울장애 진단기준 항목을 설문기반으로 검사하는 PHQ-9을 통해 우울증 그룹을 분류하였으며, PHQ-9 합산 점수에 따라
정상군,경도우울증,주요우울장애세 그룹으로 분류하여 진행하였음.
1-3. Necessity of Research 연구 필요성

우울증 고위험군 예측 필요성- 우울증 예측은 우울증 및 자살 예방에 있어서 매우 중요함
우울증 예측모델 개발 필요성- 적절한 치료 시기를 놓치지 않도록 기본 건강 검진에서 실시하는 내용만을 활용한 예측 모델 개발의 필요가 있음
인공지능 예측모델 개발 필요성- 진단시 고려해야할 요인들이 다양하고 많기 때문에, 일반적인 경험적, 통계적 방법으로는 정확하게 판단하기 힘들기 때문에 인공지능을 활용하여 이러한 한계를 극복할 필요가 있음
1-4. Purpose & Benefit 목표 및 기대효과

- 본 프로젝트는 4가지의 목표 및 가설을 가지고 있으며, 각각의 기대효과는 다음과 같음
- Cloud DB 구축 : 다양한 방식으로 필요에 맞게 데이터를 분석하고 모델링 가능
- 시각화 분석 & 대시보드 : 우울증 관련 요인들의 트렌드 파악 가능
- 모델링 & 성능개선 : 우울증 예측 모델을 구현하고 성능을 개선
- 웹페이지 구현 & 배포 : 사용자가 예측과 트렌드 파악을 더욱 편리하게 이용할 수 있도록 웹페이지를 통해 예측모델의 배포를 실시 가능

1-5. Dataset 선정 데이터셋

- 신체검진 자료와 문진 자료 그리고 우울증 관련 데이터로 질병관리본부의 국민건강영양조사 데이터가 가장 적합하다고 판단하여 데이터셋으로 선정함
- PHQ-9 검사가 실시된 것은 2014,2016,2018,2020년 뿐이라서 4개년도에 대한 데이터로 프로젝트를 진행하였음
- 보안서약서를 작성하였으며, 원본데이터 및 가공데이터들에 대한 공개는 보안서약서에 의해
.gitignore를 통해 레포지토리에 공개되지 않도록 조치하였음 - 원본데이터가 SPSS 혹은 SAS 형태 두가지의 형태로만 제공되기 때문에, SPSS 데이터를 다운로드 하였고,
IBM SPSS Statistics프로그램을 통해 csv로 인코딩한 후에 전처리 등 이후 과정들을 수행하였음 - 선정 변수는 Feature와 Target을 고려하여 선정하였고, 자세한 사항은 데이터베이스 파트에서 자세히 다룰 예정임
1-6. Environments setting 개발환경 세팅

- 개발에 앞서 가상환경을 세팅하는 작업을 실시함
- 가상환경은 Anaconda를 통해 세팅하였고, 웹페이지 구현 및 배포는 배포 서비스의 용량 한계로 인해 모델 동작에 필요한 최소한의 라이브러리만 설치하여 세팅하였음.
- 가상환경 1 : 데이터 전처리, DB 구축, 모델링, 시각화 등..
- Python 버전은 3.8로 지정
- 따로 설치한 라이브러리 목록은 다음과 같음
- pandas, numpy, psycopg2-binary, python-dotenv, matplotlib, seaborn, plotly, scikit-learn, lightgbm, tensorflow(2.9.2), keras_tuner
- 가상환경 2 : 웹페이지 구현 및 모델 배포
- Python 버전은 3.8로 지정
- 웹페이지 배포 및 WSGI : Flask, gunicorn
- 예측 모델 실행 : tensorflow-cpu(2.9.2)
- 배포 서비스에선 GPU를 활용하지 않기도 하고, 용량을 최소화 시키기 위해 cpu버전으로 설치를 실시함
- 가상환경 1 : 데이터 전처리, DB 구축, 모델링, 시각화 등..
2~. 이후 과정
본격적인 개발과정은 다음 포스팅부터 자세히 다루어 보도록 하겠음.

일 때문에 포스팅은 잠시 쉬어요 ㅠ // Now. 수학 강사 (광교) // Prev. Machine Learning (AI) Engineer & BackEnd Engineer