뇌 MRI이미지로 알츠하이머와 경도인지장애를 진단하는 CNN 딥러닝 모델 개발과정 정리 및 회고.
(3) 예측 및 결론
- Github Repository 바로가기 : Alzheimer_MCI-CNN_Classifier(클릭)

딥러닝 기반 알츠하이머 및 경도인지장애 진단모델
Deep Learning based Alzheimer and MCI Diagnosis Model
- 합성곱 신경망(CNN)을 통해 Brain MRI 이미지를 알츠하이머와 경도인지장애(MCI)로 분류하는 딥러닝 모델 개발

0. 프로젝트 개요
필수 포함 요소
자유주제(의료/헬스케어)- 설정한
데이터 직무 포지션에서 풀고자하는 문제 정의 - 적합한
데이터셋선정 및 선정 이유 딥러닝 파이프라인구축- 딥러닝 모델
학습 및 검증 한계점과추후 발전 방향
프로젝트 목차
(Part1) Intro & Metadata
- Introduction
서론- Position & Intention
포지션설정, 기획의도 - Alzheimer Dementia, MCI
알츠하이머치매와 경도인지장애 - Necessity of Research
연구의 필요성 - Purposes
목표 및 가설
- Position & Intention
- Dataset & Metadata
데이터셋 및 메타데이터- ADNI dataset
데이터셋 소개 - Data Preparation
데이터 준비 - Metadata Analysis
메타데이터 분석 - Metadata EDA Dashboard
대시보드
- ADNI dataset
(Part2) Modeling
- Modeling
모델링- Overview & Structure
개요 및 구조 - Data Import & Split
데이터 로딩 및 분리 - Preprocessing Layer
전처리 레이어 - Vanilla CNN Model
기본 CNN 모델
- Overview & Structure
- Model Improvement
모델 성능 개선- Transfer Learning
전이학습 - Negative Transfer
네거티브 전이 - Hyperparameter Tuning
하이퍼파라미터 튜닝 - Final Model & Evaluation
최종 모델 학습 및 검증
- Transfer Learning
(Part3) Prediction & Conclusion
- Prediction & Comparing
예측 및 비교분석- Test Dataset
테스트 데이터셋 - Prediction & Confidence
예측 및 신뢰도 - Metrics & Confusion Matrix
평가지표 및 혼동행렬
- Test Dataset
- Conclusion
결론- Overall Summary
요약 - Limitations & Further Research
한계와 추후 발전방향 - Takeaways
핵심과 소감
- Overall Summary
Deep Learning Pipeline

(Part3) Prediction & Conclusion

5. Prediction & Comparing 예측 및 비교분석
- 로컬 환경에서 작업을 진행하였음
- 노트 링크 : Plotting_Prediction.ipynb
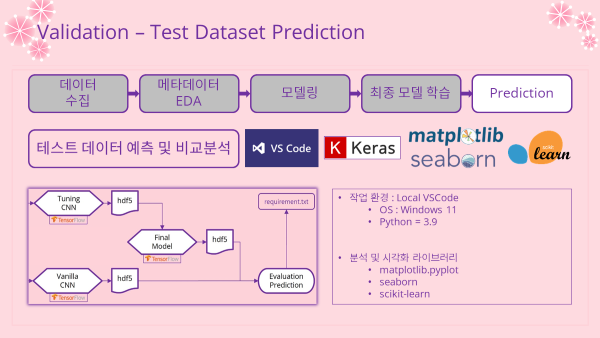
5-1. Test Dataset 테스트 데이터셋
- 테스트 데이터셋을 준비 (이전 모델들과 동일한 방식으로 진행)
Library import
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['axes.unicode_minus'] = False
import seaborn as sns
from sklearn.metrics import classification_report, confusion_matrix
import tensorflow as tf
from tensorflow.keras.utils import image_dataset_from_directory
from tensorflow.keras.models import load_modelDirectory 지정 & 폴더 확인
base_dir = "./imagedata/"
data_dir = base_dir + "Axial"
os.listdir(data_dir)
'''
['AD', 'CN', 'MCI']
'''- Global 변수 지정
CLASSES = ['CN', 'MCI', 'AD']
IMG_SIZE = 256
BATCH_SIZE = 32
SEED = 42이미지 Data 불러오기
dataset = image_dataset_from_directory(
data_dir,
shuffle=True,
class_names=CLASSES,
batch_size=BATCH_SIZE,
image_size=(IMG_SIZE, IMG_SIZE),
seed=SEED
)
print(dataset.class_names)
'''
Found 5154 files belonging to 3 classes.
['CN', 'MCI', 'AD']
'''이미지 데이터 수 확인 (전체데이터)
number_of_images = {}
for class_name in CLASSES:
number_of_images[class_name] = len(os.listdir(data_dir+"/"+class_name))
image_count_df = pd.DataFrame(number_of_images.values(),
index=number_of_images.keys(),
columns=["Number of Images"])
display(image_count_df)
print("\nSum of Images: {}".format(image_count_df.sum()[0]))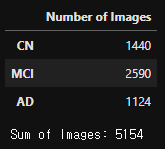
ax = sns.barplot(data=image_count_df.T)
for p in ax.patches:
ax.annotate("%.0f" % p.get_height(), (p.get_x() + p.get_width()/2., p.get_height()-200),
ha='center', va='center', fontsize=10, color='black',xytext=(0,10),
textcoords='offset points')
plt.title('Number of Images')
plt.show()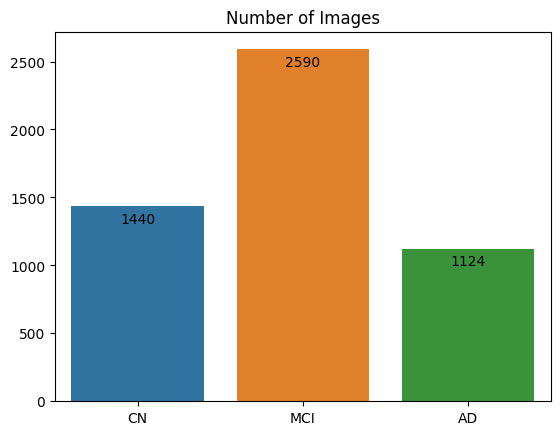
explode = np.repeat(0.025,3)
wedgeprops = {'width': 0.5, 'edgecolor': 'w', 'linewidth': 1.5}
textprops={'size':12}
icd = image_count_df.reset_index(drop=False)
icd.columns = ['Group', 'Counts']
plt.figure(figsize=(8,8))
plt.pie(icd.Counts,labels=icd.Group,
labeldistance=0.725,startangle=0,autopct='%.1f%%',
explode=explode,wedgeprops=wedgeprops,textprops=textprops)
plt.legend(loc='center')
plt.title('Percentage of Images')
plt.show()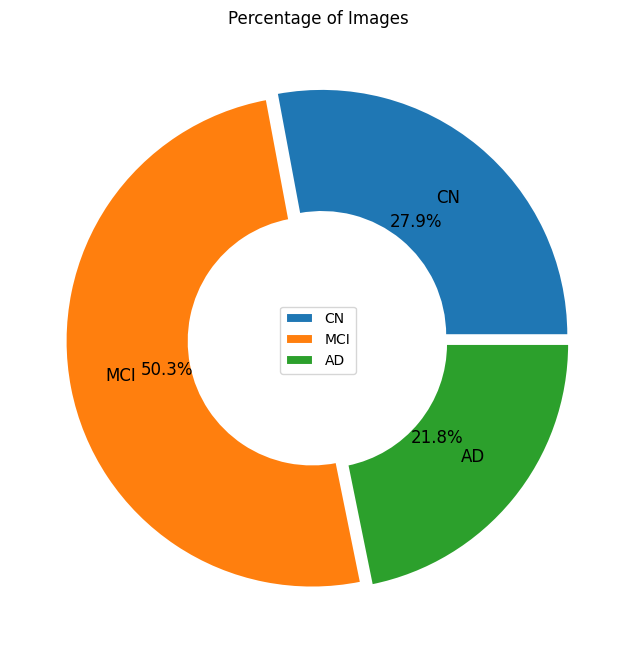
데이터 확인 (예측 전)
- Batch 하나만 뽑아서 형태 및 label확인
for img_batch, label_batch in dataset.take(1):
print(img_batch.shape)
print(label_batch.numpy())
print(label_batch.shape)
break
'''
(32, 256, 256, 3)
[2 2 1 1 1 1 1 2 1 0 1 1 1 0 1 0 0 1 0 1 1 1 1 0 1 1 0 2 1 0 0 0]
(32,)
'''- Label 값 확인
print(np.unique(label_batch))
print(dataset.class_names)
class_dict = dict(zip(np.unique(label_batch),dataset.class_names))
class_dict
'''
[0 1 2]
['CN', 'MCI', 'AD']
{0: 'CN', 1: 'MCI', 2: 'AD'}
'''- plot images
plt.figure(figsize=(12,12))
plt.suptitle(f"Alzheimer MRI Images\n{class_dict}", fontsize=24)
for i in range(16):
ax = plt.subplot(4,4,i+1)
img_arr = img_batch[i].numpy()
plt.imshow(img_arr.astype("uint8"))
plt.axis("off")
plt.title("Class : {}".format(CLASSES[label_batch[i].numpy()]))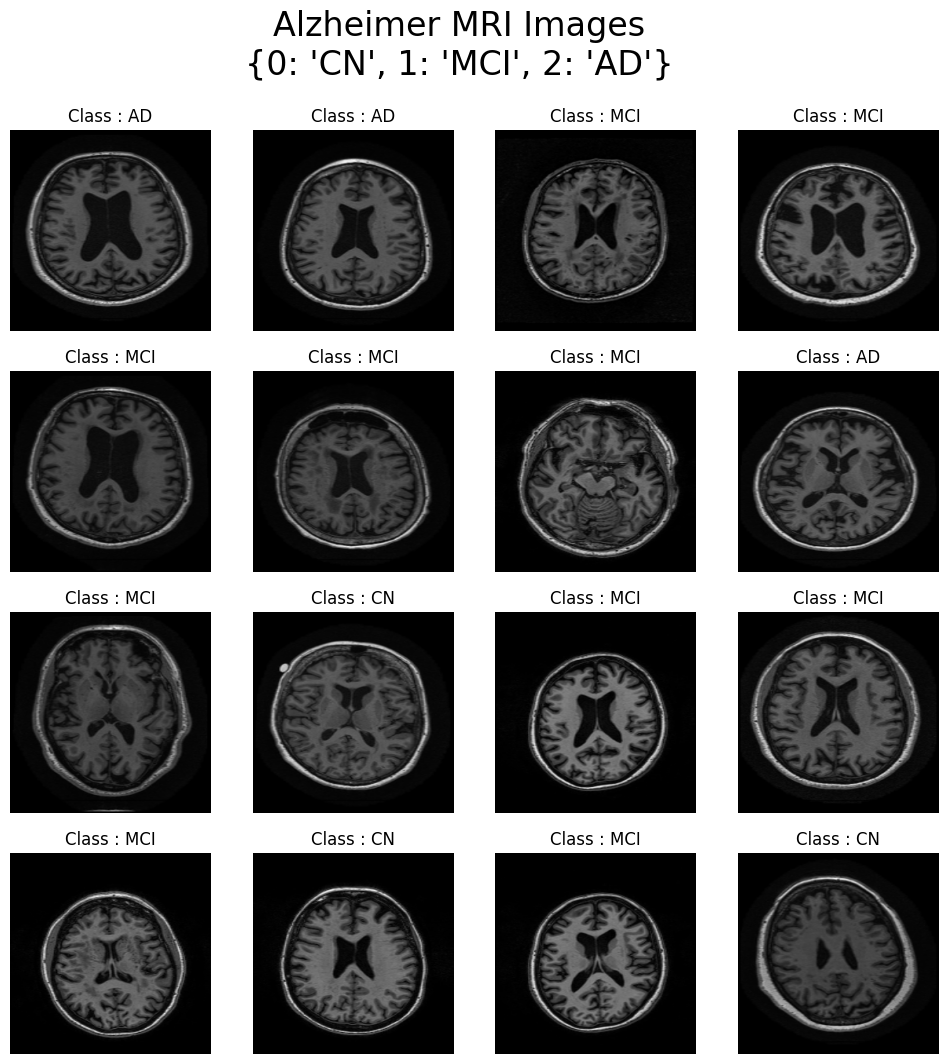
- 인사이트
- 육안으로는 구별하기 힘들 것으로 보임
- 딥러닝의 필요성을 다시금 확인하였음!
데이터 분리 Split
def dataset_split(ds, tr=0.8, val=0.1, test=0.1, shuffle=True, buf_size=10000, SEED=42):
ds_size = len(ds)
if shuffle:
ds = ds.shuffle(buf_size,seed=SEED)
train_size = int(ds_size*tr)
val_size = int(ds_size*test)
train = ds.take(train_size)
test0 = ds.skip(train_size)
val = test0.take(val_size)
test = test0.skip(val_size)
return train,val,test
train_ds, val_ds, test_ds = dataset_split(dataset)
print("Split전 Batched data 개수")
print(f"Dataset : {len(dataset)}")
print("\nSplit후 Batched data 개수")
print(f"Train : {len(train_ds)}")
print(f"Validation : {len(val_ds)}")
print(f"Test : {len(test_ds)}")
'''
Split전 Batched data 개수
Dataset : 162
Split후 Batched data 개수
Train : 129
Validation : 16
Test : 17
'''Model 불러오기
- model1 = 튜닝을 거치지 않은 Vanilla CNN model
model1_path = base_dir + "model1.hdf5"
model1 = load_model(filepath=model1_path)
model1.summary()
'''
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
sequential (Sequential) (None, 256, 256, 3) 0
sequential_1 (Sequential) (None, 256, 256, 3) 0
conv2d (Conv2D) (None, 256, 256, 32) 896
max_pooling2d (MaxPooling2D (None, 128, 128, 32) 0
)
conv2d_1 (Conv2D) (None, 128, 128, 64) 18496
max_pooling2d_1 (MaxPooling (None, 64, 64, 64) 0
2D)
flatten (Flatten) (None, 262144) 0
dense (Dense) (None, 64) 16777280
dense_1 (Dense) (None, 3) 195
=================================================================
Total params: 16,796,867
Trainable params: 16,796,867
Non-trainable params: 0
_________________________________________________________________
'''- 튜닝 전 모델 evaluation
model1.evaluate(test_ds, verbose=1)
'''
17/17 [==============================] - 7s 114ms/step - loss: 0.2975 - acc: 0.8934
[0.2974990904331207, 0.8933823704719543]
'''- final_model = 튜닝을 거친 후 학습된 CNN model
final_model_path = base_dir + "best_model.hdf5"
final_model = load_model(filepath=final_model_path)
final_model.summary()
'''
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
sequential (Sequential) (None, 256, 256, 3) 0
sequential_1 (Sequential) (None, 256, 256, 3) 0
conv2d_4 (Conv2D) (32, 256, 256, 16) 448
max_pooling2d_4 (MaxPooling (32, 128, 128, 16) 0
2D)
conv2d_5 (Conv2D) (32, 128, 128, 16) 2320
max_pooling2d_5 (MaxPooling (32, 64, 64, 16) 0
2D)
flatten_2 (Flatten) (32, 65536) 0
dense_4 (Dense) (32, 320) 20971840
dense_5 (Dense) (32, 3) 963
=================================================================
Total params: 20,975,571
Trainable params: 20,975,571
Non-trainable params: 0
_________________________________________________________________
'''- 최종 모델 evaluation
final_model.evaluate(test_ds, verbose=1)
'''
17/17 [==============================] - 5s 62ms/step - loss: 0.0443 - acc: 0.9853
[0.04426185041666031, 0.9852941036224365]
'''Test Dataset 살펴보기
- Test Data Label, 각 모델별 predicted Label array 생성
# Test Data Label, 각 모델별 predicted Label array 생성
real_label = np.array([])
pred_model1 = np.array([])
pred_final_model = np.array([])
for imgs, labels in test_ds:
real_label = np.concatenate([real_label, labels.numpy()])
pred_model1 = np.concatenate([pred_model1, np.argmax(model1(imgs), axis=-1)])
pred_final_model = np.concatenate([pred_final_model, np.argmax(final_model(imgs), axis=-1)])
# DataFrame으로 만들기
label_df = pd.DataFrame(zip(real_label, pred_model1, pred_final_model),
columns = ['True_Label', 'Pred_Vanilla', 'Pred_Tuned'])
label_df2 = label_df.replace(class_dict)
label_df2.head(10)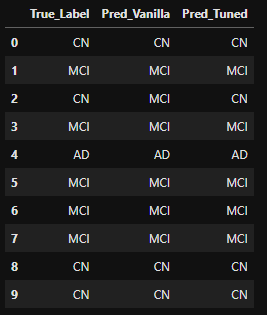
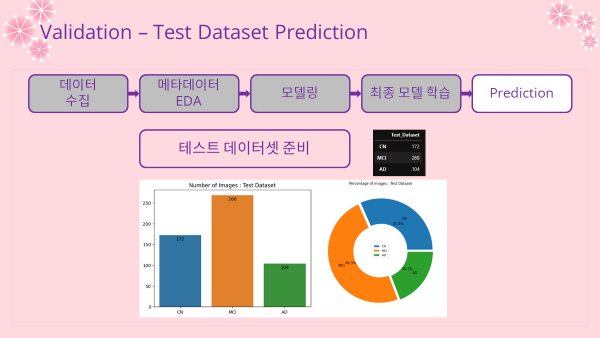
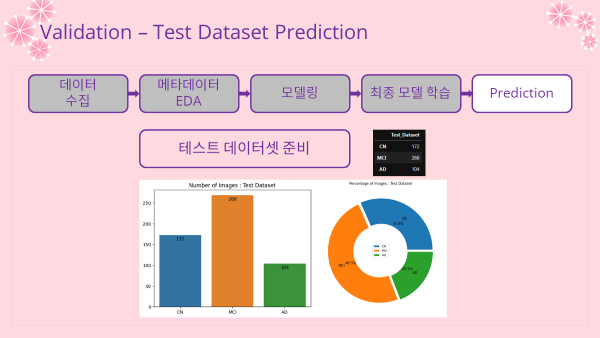
- 테스트 데이터셋 비율 확인
count_label = label_df2['True_Label'].value_counts()
label_dict = {}
for class_name in CLASSES:
label_dict[class_name] = count_label.loc[class_name]
print(f"Label Counts : {label_dict}")
image_count_test = pd.DataFrame(label_dict.values(),
index = label_dict.keys(),
columns=["Test_Dataset"])
display(image_count_test)
print("Sum of Images : {}".format(image_count_test.sum()[0]))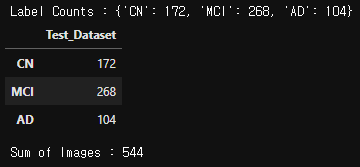
# Test data count barplot
ax2 = sns.barplot(data=image_count_test.T)
for p2 in ax2.patches:
ax2.annotate("%.0f" % p2.get_height(), (p2.get_x() + p2.get_width()/2., p2.get_height()-20),
ha='center', va='center', fontsize=10, color='black',xytext=(0,10),
textcoords='offset points')
plt.title('Number of Images : Test Dataset')
plt.show()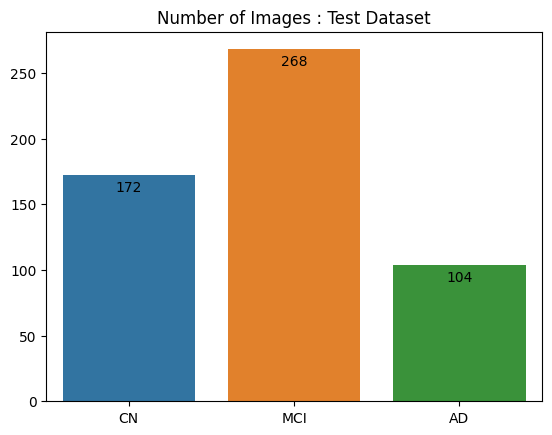
# Test data pie plot
explode = np.repeat(0.025,3)
wedgeprops = {'width': 0.5, 'edgecolor': 'w', 'linewidth': 1.5}
textprops={'size':12}
ict = image_count_test.reset_index(drop=False)
ict.columns = ['Group', 'Counts']
plt.figure(figsize=(8,8))
plt.pie(ict.Counts,labels=ict.Group,
labeldistance=0.725,startangle=0,autopct='%.1f%%',
explode=explode,wedgeprops=wedgeprops,textprops=textprops)
plt.legend(loc='center')
plt.title('Percentage of Images : Test Dataset')
plt.show()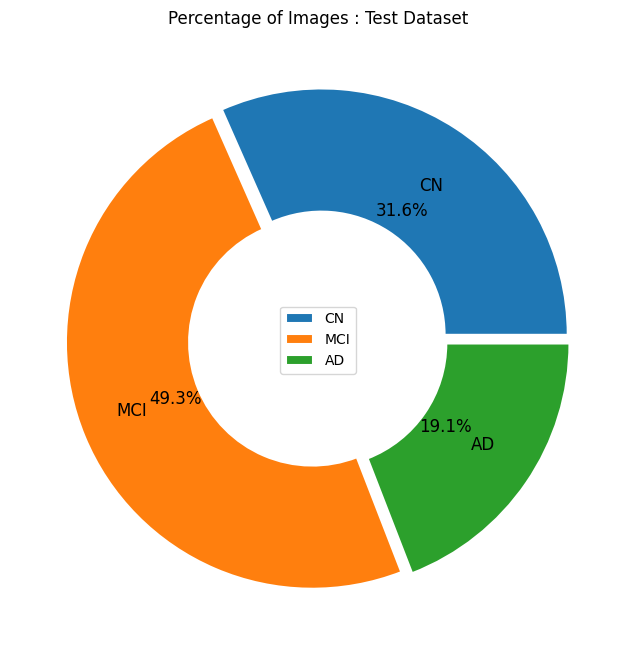
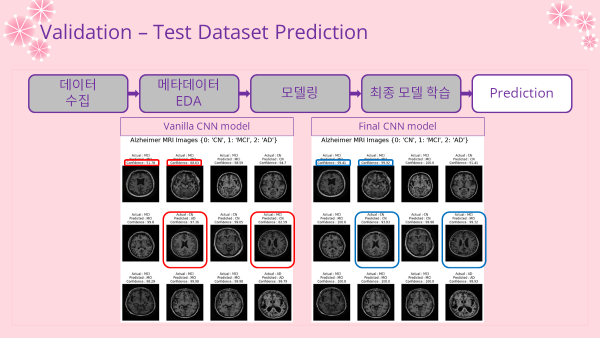
5-2. Prediction & Confidence 예측 및 신뢰도
- 테스트 데이터에서 12개의 이미지를 시각화하여 비교분석
- Confidence : 모델이 얼마나 확신을 가지고 예측 값을 판단했는지 알 수 있는 점수, 신뢰도
Batch 하나 뽑기
for image_test, label_test in test_ds.take(1):
print(image_test.shape)
print(label_test.numpy())
print(label_test.shape)
break
'''
(32, 256, 256, 3)
[1 1 1 0 1 0 0 1 1 1 1 2 1 2 2 2 1 1 2 0 1 2 0 1 1 1 1 1 1 0 0 0]
(32,)
'''이미지 시각화 함수 정의
# 예측값, Confidence값
def prediction(model, img):
img_array = tf.keras.preprocessing.image.img_to_array(img)
img_array = tf.expand_dims(img_array, axis=0)
predictions = model.predict(img_array, verbose=0)
predicted_class = CLASSES[np.argmax(predictions[0])]
confidence = round(100*(np.max(predictions[0])), ndigits=2)
return predicted_class, confidence
# 시각화 함수
def pred_plot(model):
plt.figure(figsize=(12,12))
plt.suptitle(f"Alzheimer MRI Images {class_dict}", fontsize=24)
for i in range(12):
ax = plt.subplot(3,4,i+1)
plt.imshow(image_test[i].numpy().astype("uint8"))
predicted_class, confidence = prediction(model, image_test[i].numpy())
label_true = CLASSES[label_test[i].numpy()]
plt.title("Actual : {}\nPredicted : {}\nConfidence : {}".format(label_true, predicted_class, confidence))
plt.axis("off")Prediction
- 튜닝을 거치지 않은 Vanilla CNN 모델
- 인사이트
- 군데군데 예측을 잘못한 이미지가 보임
- 예측을 올바르게 해도 판단에대한 신뢰도(confidence)가 상대적으로 낮은 이미지들도 나타남
pred_plot(model1)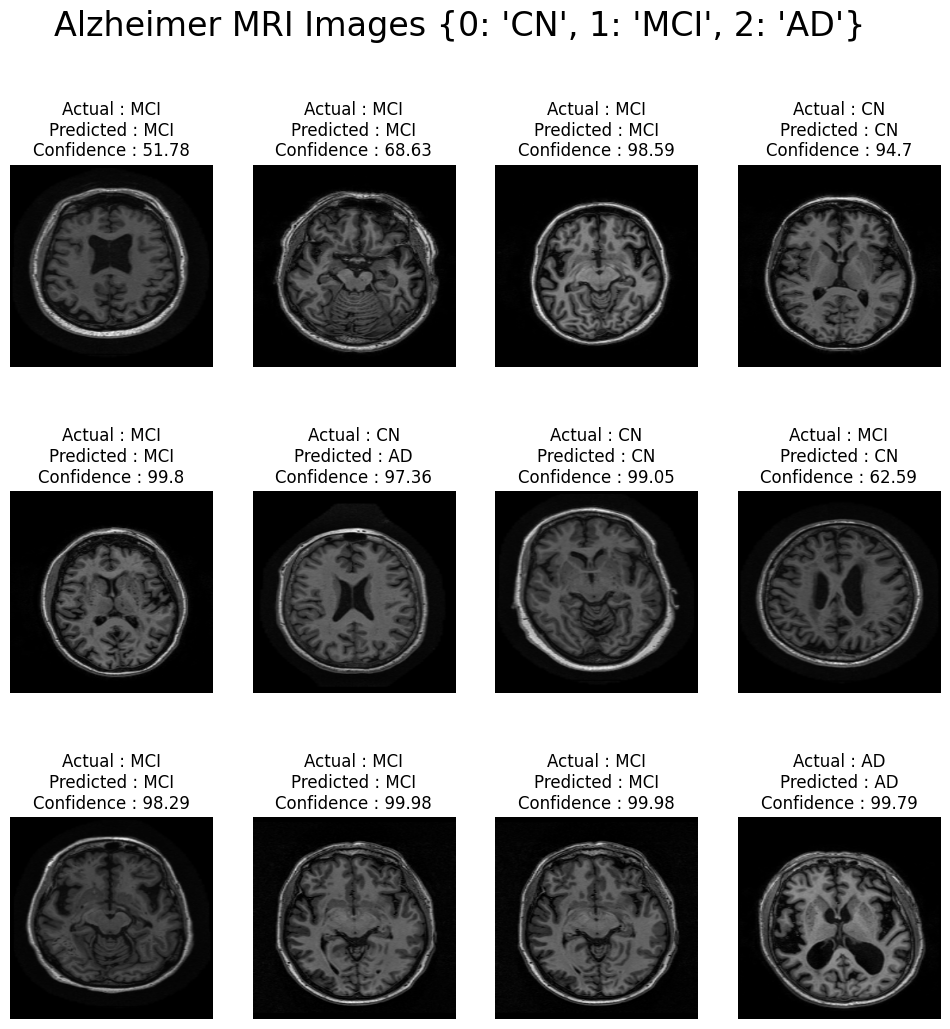
- 튜닝을 거친 후 학습을 진행한 최종 CNN 모델
- 인사이트
- vanilla CNN보다 향상된 예측 성능을 보임
- 예측에 대한 confidence도 상대적으로 훨씬 높았음
pred_plot(final_model)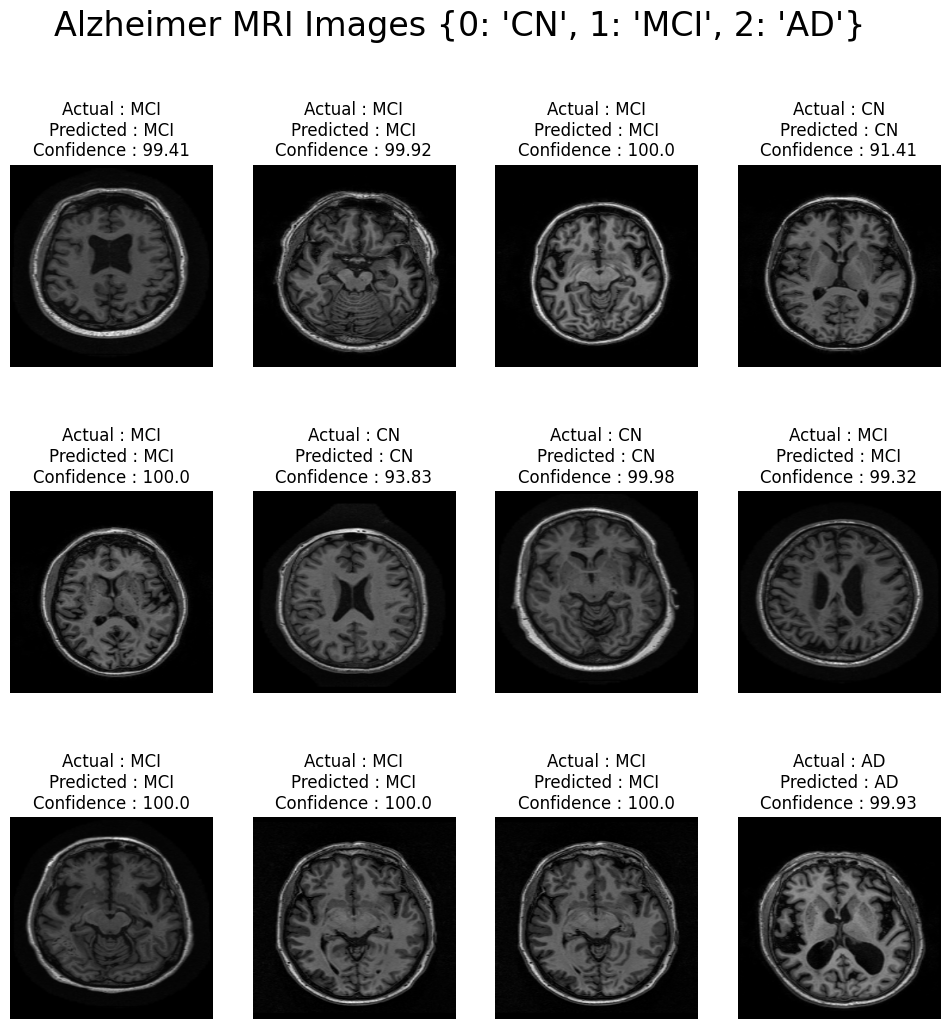
5-3. Metrics & Confusion Matrix 평가지표 및 혼동행렬
- sciket-learn의 기능을 이용하여 테스트 데이터셋 전체에 대한 예측 결과를 비교분석
- Classcification Report, Confusion Matrix 함수 정의
def report_matrix(y_real, pred_label, subtitle):
print(classification_report(y_real, pred_label, target_names=CLASSES))
cm = confusion_matrix(y_real, pred_label)
plt.figure(figsize=(8,6), facecolor='w', edgecolor='k')
ax = sns.heatmap(data=cm, cmap='Greens', annot=True, fmt='d',
xticklabels=CLASSES, yticklabels=CLASSES)
plt.title(f"Confusion Matrix of Alzheimer-MCI Prediction\nModel : {subtitle}")
plt.xlabel('Prediction')
plt.ylabel('True(Real)')
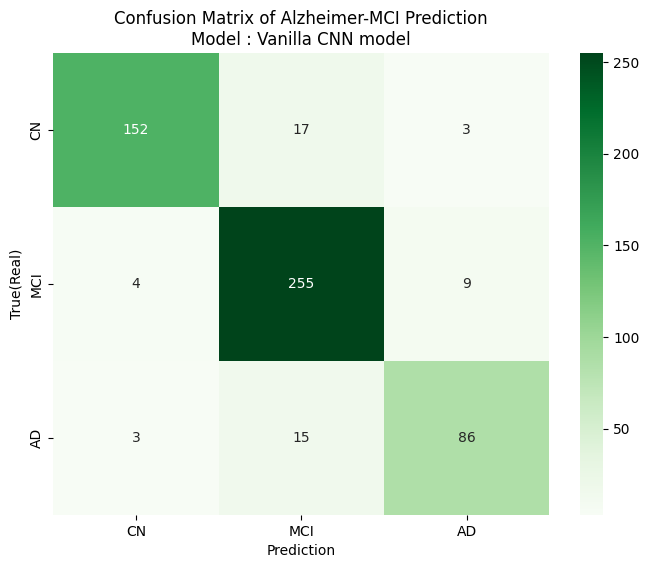
plt.show(ax)튜닝을 거치지 않은 Vanilla CNN 모델
report_matrix(real_label, pred_model1, subtitle='Vanilla CNN model')
'''
precision recall f1-score support
CN 0.96 0.88 0.92 172
MCI 0.89 0.95 0.92 268
AD 0.88 0.83 0.85 104
accuracy 0.91 544
macro avg 0.91 0.89 0.90 544
weighted avg 0.91 0.91 0.91 544
'''
튜닝을 거친 후 학습을 진행한 최종 CNN 모델
report_matrix(real_label, pred_final_model, subtitle='Hyperparameter Tuned CNN model')
'''
precision recall f1-score support
CN 0.97 0.98 0.98 172
MCI 0.99 0.97 0.98 268
AD 0.97 0.99 0.98 104
accuracy 0.98 544
macro avg 0.98 0.98 0.98 544
weighted avg 0.98 0.98 0.98 544
'''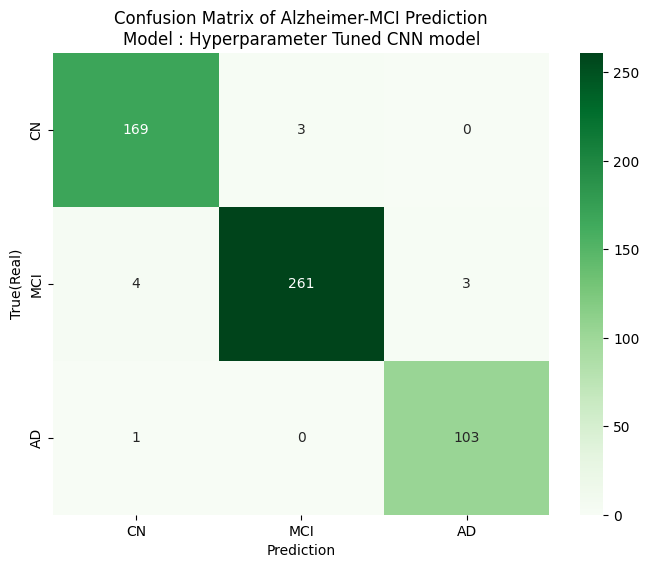
- 인사이트
- Classification Report : 모든 평가지표에서 최종 모델이 더 좋은 성능을 보임
- Confusion Matrix : 최종 모델에서 성능이 개선되었음을 확인할 수 있었음
6. Conclusion 결론

6-1. Overall Summary 요약

- 서론에서 프로젝트의 4가지 필요성에 대해 살펴보았었음
- 고령화 -> 치매 유병률 지속적 상승 -> 치매 연구 필요성
- 경도인지장애(치매 고위험군) -> 치매 예방 효과 -> 경도인지장애 예측 필요성
- 뇌촬영 검사 -> 치매 진단에 결정적 -> 영상이미지 분석 필요성
- 일반 통계 및 머신러닝의 한계 -> 딥러닝(CNN) 모델의 필요성
- 데이터는 ADNI Baseline 데이터로 분석실시
- 메타데이터 : ADNI에서 직접 다운로드 -> 대시보드로 제작 및 배포
- 이미지데이터 : Kaggle에서 다운로드
- 모델링
- CNN으로 모델링 실시
- 3way Hold-Out으로 훈련, 검증, 예측 실시
- Vanilla CNN, ResNet50V2, HyperparamerTuning
- 전이학습모델(ResNet50V2)에서 Negative Tranfer 발생
- 검증 및 예측
- 최종모델의 만족스러운 성능 및 높은 일반화가능성
6-2. Limitations & Further Research 한계와 추후 발전방향

- Alzheimer
- 경도인지장애에대한 애매한 진단기준
- 후속연구 필요성
- 알츠하이머병에 국한된 프로젝트
- 다른 치매유발 요인들(70가지정도로 알려져있음) 추가분석
- 경도인지장애에대한 애매한 진단기준
- Dataset
- ADNI Baseline
- Longitudinal Data도 활용한 추가분석
- MRI images
- Axial 범위 확대
- Coronal, Sagittal로 분석범위 확대
- ADNI Baseline
- Modeling
- 데이터증강(Augmentation)
- RandomFlip, RandomRotation 이외의 다른 증강기법도 적용하여 추가분석
- Negative Transfer
- ResNet계열 이외의 사전학습 모델로 추가분석
- 데이터증강(Augmentation)
- Prediction
- 테스트 데이터셋으로 예측진행
- 외부 MRI 이미지 데이터로도 일반화가 되는지 확인하여 일반화 가능성 확인 가능
- 테스트 데이터셋으로 예측진행
6-3. Takeaways 핵심과 소감

- Key Takeaway (핵심)
- 의료영상이미지(MRI)를 알츠하이머병(AD), 경도인지장애(MCI), 정상(CN)으로 분류하는 딥러닝 진단모델 개발
- 프로젝트 기대효과
- 경도인지장애에 대한 예측에 활용
- 적극적인 치매 예방을 실시 할 수 있을 것으로 전망
- 딥러닝 모델을 통한 진단
- 더 정확한 진단을 위한 근거로써 사용할 수 있을 것으로 전망
- 경도인지장애에 대한 예측에 활용
- My Takeaways (소감)
- 좋았던 점
- 프로젝트를 통해 직접 구현해보면서 다양한 시도들을 할 수 있었음
- 이를 통해 많은 것을 배울 수 있어서 뿌듯했음
- 생각보다 성능이 높아서 만족스러웠음
- 아쉬운 점
- 컴퓨터 사양의 한계로 Colab으로 진행
- Colab이 생각외로 신경써야할게 많아서 불편했음
- 컴퓨터 사양이 좋았더라면 좀 더 쾌적한 로컬 환경에서 진행할 수 있었을 것 같음
- 좋았던 점

회고
- 본 프로젝트는 코드스테이츠 AI 부트캠프 Section4 딥러닝 프로젝트로써 자유주제로 협업없이 진행한 개인프로젝트임.
- 이번 프로젝트는 Section4를 마무리하고 Section5를 시작하기 전에 정리해 볼 수 있어 Section4를 마무리하는 느낌이 들어 마음 편히 다음 섹션을 준비할 수 있을 듯함.
- 이번 프로젝트에서는 구상 및 모델링 과정에서는 최대한 간단하게 구성하여 진행했다고 생각했지만, 막상 발표를 위한 ppt를 제작하는 과정에서 준비된 내용이 너무 많아서 추려내는데 애를 먹었음...
- 주제 및 데이터 구축이 자유로웠던 만큼 관심도메인이었던 헬스케어 분야를 이번에도 다룰 수 있어서 비교적 즐겁게 프로젝트를 수행할 수 있었음.
- 구현 과정에서 생각보다 다양한 오류를 접하게 되고 해결하면서 많은 것들을 배울 수 있었고, 구현한 모델의 성능이 생각보단 굉장히 좋게 나와서 다행이라 생각함.
- 프로젝트를 정리하면서 그동안 배웠던 내용들을 복습하는데에도 도움이 되어 유의미한 시간이었다 생각하고, 진행과정과 코드는 생각보다 잘 정리가 되진 않은 느낌이라 아쉽긴 했음...
- 코치진으로부터 피드백은 한달 뒤쯤 받을 예정이라 어떠한 피드백을 받게 될지는 모르겠지만, 어떠한 피드백을 받더라도 겸허히 받아들여야겠음...
- 예상되는 피드백은 너무 많은 것을 담으려 했다는 점일듯하고, 그래도 발표에서는 자세히 설명하지 못했던 부분들을 블로그를 통해서라도 할 수 있어 좋았음.
- 교육 섹션이 총 5개인데 벌써 네번째 섹션이 끝나니 이제서야 끝이 보이는 느낌이긴함... 다음 섹션에서는 컴퓨터공학에 대해 배우는데, 적어도 이번 섹션만큼은 힘들진 않을 것으로 예상됨.
- 정말 우여 곡절이 많았던 이번 섹션이 그래도 무사히 끝나서 후련하긴하지만, 아직은 명확하게 이해하지 못하고 넘어간 부분들도 꽤 있어서 한편으로는 찝찝하기도함...
- 그래도 여태까지 잘 해온 만큼 남은 기간도 힘내서 잘 마무리할 수 있기를 다짐하고 바래보겠음!
- 아자아자 파이팅!

일 때문에 포스팅은 잠시 쉬어요 ㅠ // Now. 수학 강사 (광교) // Prev. Machine Learning (AI) Engineer & BackEnd Engineer