
본 시리즈는 프로그래밍 자료구조의 개념을 정리하고 실습을 진행해보는 시리즈입니다.
- 실습은 다음과 같은 개발환경 및 버전에서 진행하였습니다.
- IDE : IntelliJ IDEA (Ultimate Edition)
- Java : JDK 21 (corretto-21)
- Python : 3.9 (conda env)
자료구조 - Hashtable (Part 2-2)
이번 포스팅에서는 지난 포스팅에서 다룬 Hashtable이 Python에서 어떻게 활용되는지를 구체적으로 다루어 보고자합니다.
그래서 Python의 해시테이블들의 특징 및 동작 원리를 살펴보고 Dict와 Set 자료형을 다루어볼 예정입니다.
0. 서론 : Hashing 개념의 간단한 복습
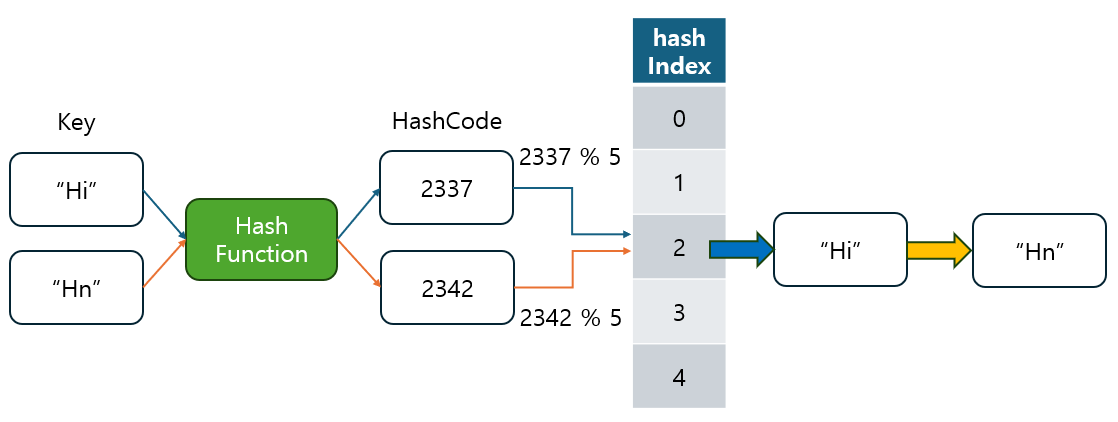
지난 포스팅에서는 해시 함수(Hash Function)의 개념과, 해시 코드(Hash Code)가 어떻게 생성되는지를 살펴보았습니다.
- 해시 함수는 데이터를 고정된 크기의 숫자로 변환하여 빠르고 효율적인 데이터 검색과 저장을 가능하게 해주는 중요한 도구입니다.
- 그러나 해시 함수를 통해 생성된 여러 값들이 서로 충돌하는 해시 충돌(Hash Collision)이 발생할 가능성도 확인했었습니다.
- 그래서 이 문제를 해결하기 위한 방법으로 Separate Chaining(체이닝 방식)과 Open Addressing(개방 주소 방식)과 같은 기법들을 다뤘습니다.
이번 포스팅에서는 이러한 해싱(Hashing) 개념이 Python에서 어떻게 적용되고 구현되는지를 좀 더 구체적으로 살펴보도록 합시다!
1. Python의 해시테이블 - 개요
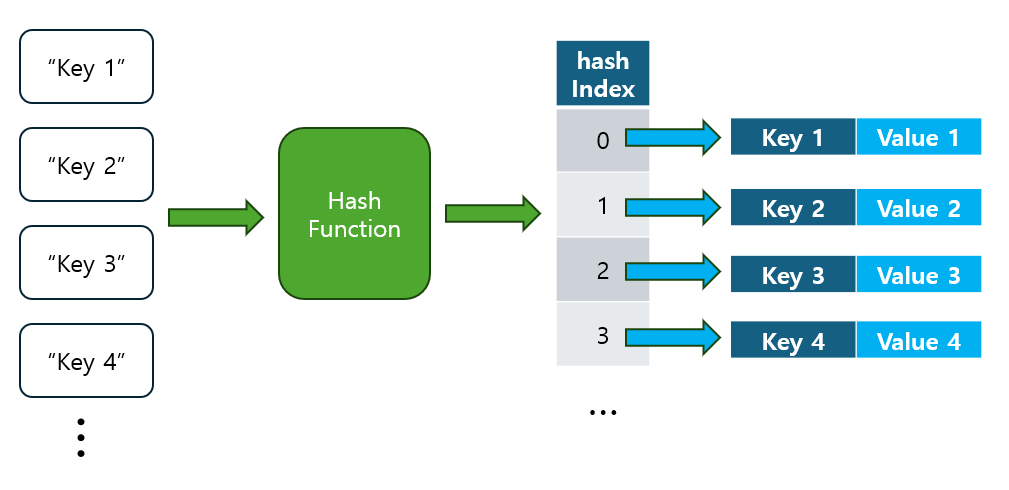
Python에서는 딕셔너리(Dictionary)와 집합(Set) 자료형이 해시 테이블을 기반으로 구현되어 있습니다.
- 이 두 자료구조는 해시 함수를 이용하여 데이터를 빠르게 검색, 추가, 삭제할 수 있는 특징을 가지고 있으며, Python의 핵심적인 데이터 구조로 자주 사용됩니다.
1.1 Dictionary (Dict)
딕셔너리는 키-값 쌍(Key-Value Pair)으로 데이터를 저장하는 자료구조로, 각 키(Key)는 고유하며 해시 함수를 통해 해시 인덱스로 변환됩니다.
- 이 해시 인덱스를 기반으로 해시 테이블의 적절한 위치에 키-값 쌍이 저장됩니다.
- Python의 딕셔너리는 해시 테이블 구조 덕분에 상수 시간(O(1))에 데이터에 접근할 수 있습니다.
특징
- 키는 고유하며, 값은 중복을 허용합니다.
- 순서를 유지: Python 3.7부터는 딕셔너리가 삽입된 순서를 유지합니다.
- 이전 버전에서는 순서가 보장되지 않았습니다.
- 해시 함수를 사용하여 키를 해시 인덱스로 변환하고, 그 인덱스에 값을 저장합니다.
기본 동작 예시
my_dict = {
'apple': 1,
'banana': 2,
'orange': 3
}
print(my_dict['apple']) # 1 출력
my_dict['grape'] = 4 # 새로운 키-값 추가
print(my_dict) # {'apple': 1, 'banana': 2, 'orange': 3, 'grape': 4}
1.2 Set
집합(Set)은 중복 없는 데이터를 저장하는 자료구조입니다.
- 내부적으로 해시 테이블을 사용하여 각 값의 고유성을 유지하며, 빠른 검색 및 추가가 가능합니다.
- Set은 해시 함수를 사용하여 각 요소를 해시 테이블의 특정 인덱스에 저장하므로, 중복된 값이 자동으로 제거됩니다.
특징
- 중복을 허용하지 않으며, 순서가 없는 자료구조입니다.
- Python의 set도 해시 함수를 사용하여 O(1) 시간 복잡도로 요소를 추가, 제거, 검색할 수 있습니다.
기본 동작 예시
my_set = {1, 2, 3, 4}
print(my_set) # {1, 2, 3, 4}
my_set.add(5) # 요소 추가
my_set.add(3) # 중복된 값은 추가되지 않음
print(my_set) # {1, 2, 3, 4, 5}1.3 해시 함수와 해시 충돌
Python의 딕셔너리와 집합은 해시 함수를 사용하여 데이터를 저장하므로, 해시 충돌이 발생할 수 있습니다.
- 해시 충돌이란, 서로 다른 키가 동일한 해시 값을 가질 때 발생하는 문제입니다.
- Python에서는 이러한 해시 충돌을 해결하기 위해 Open Addressing 방식을 사용합니다.
- 충돌이 발생하면, 해시 테이블의 빈 공간을 찾아 데이터를 저장하는 방식으로 해결합니다.
- Python의 dict는 Open Addressing 방식 중 이차 탐사(quadratic probing)와 유사한 perturb 탐사법을 사용하여 충돌을 해결합니다.
다음 섹션에서는 Python의 충돌 해결법을 통해 딕셔너리와 집합의 동작 원리를 살펴보도록 하겠습니다.
2. Python 해시테이블의 충돌 해결 원리
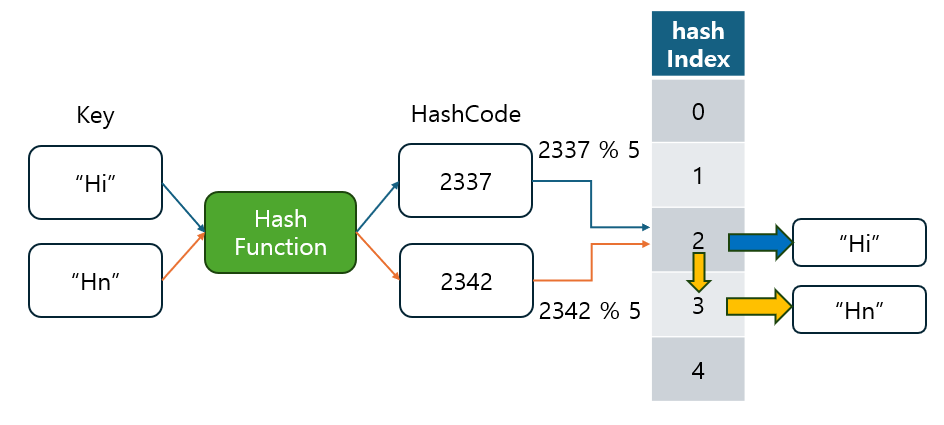
Python의 딕셔너리와 집합(set) 자료구조는 Open Addressing 방식을 사용하여 해시 충돌을 해결합니다.
- 특히 perturb 탐사법을 사용하며, 이것은 이차 탐사(quadratic probing)와 유사한 방식입니다.
- perturb 탐사법은 이차 탐사와는 조금 다르게 작동하는 특정한 형태의 탐사 기법으로, perturb 값을 사용하여 충돌을 해결합니다.
우선 Open Addressing의 일반적인 방법들에 대해서 간략하게 정리한 뒤에, Python의 perturb 탐사법을 살펴보도록 하겠습니다.
2.1 Open Addressing의 일반적인 방법들
Open Addressing은 해시 테이블에서 충돌이 발생했을 때, 데이터를 다른 빈 공간에 저장하는 방식입니다.
- 해시 테이블이 가득 차지 않았을 때 빈 슬롯을 찾아 데이터를 저장하는 방식으로, 일반적으로 세 가지 방법이 많이 사용됩니다: 선형탐사, 이차탐사, 이중해싱
선형 탐사(Linear Probing)
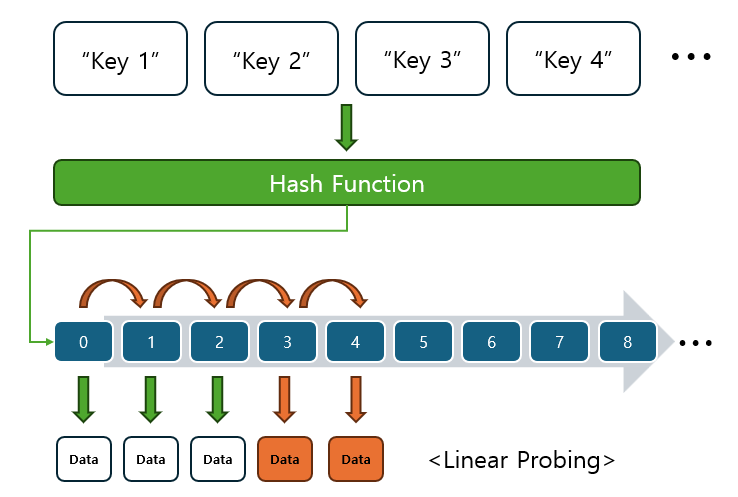
충돌이 발생했을 때, 고정된 간격(일반적으로 1)으로 다음 슬롯을 탐색합니다. 즉, 충돌이 발생하면 인덱스를 1씩 증가시키며 빈 슬롯을 찾습니다. (i, i+1, i+2, ...)
- 장점: 구현이 간단하고, 작은 해시 테이블에 적합합니다.
- 단점: 클러스터링 문제가 발생할 수 있습니다. 즉, 충돌이 연속으로 발생하면 빈 슬롯을 찾기 어려워지고, 성능이 저하됩니다.
이차 탐사(Quadratic Probing)
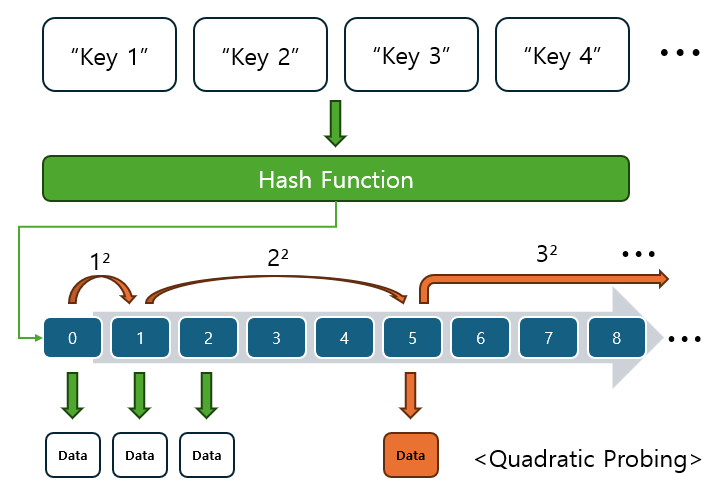
선형 탐사의 단점을 보완한 방법으로, 거리가 제곱수로 증가합니다. 즉, 첫 번째 충돌이 발생하면 i, i+1^2, i+2^2, i+3^2, ... 이런 식으로 인덱스를 계산하여 탐색합니다.
- 장점: 선형 탐사보다 클러스터링 문제를 줄일 수 있습니다.
- 단점: 충돌이 빈번한 경우 성능이 저하될 수 있습니다.
이중 해싱(Double Hashing)
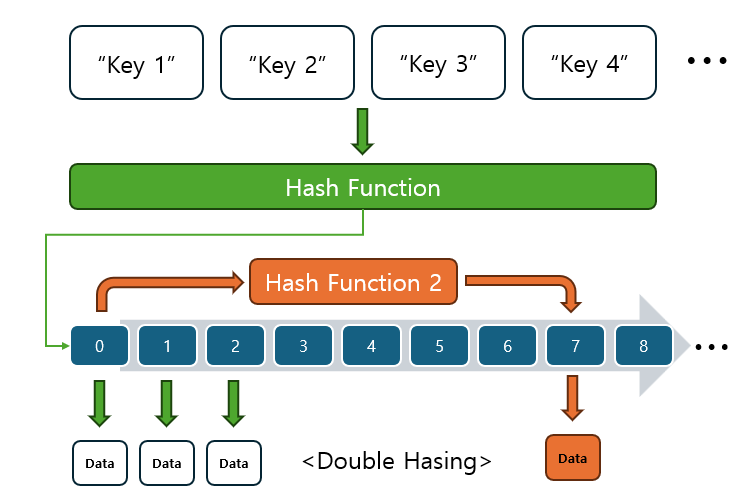
충돌이 발생할 경우 다른 해시 함수를 사용하여 새로운 해시 값을 계산한 뒤, 해당 인덱스를 따라 빈 슬롯을 탐색합니다.
- 장점: 해시 함수에 따라 더 균일한 분포를 만들 수 있습니다.
- 단점: 두 개의 해시 함수를 구현해야 하므로 복잡도가 증가합니다.
2.2 Python의 perturb 탐사법
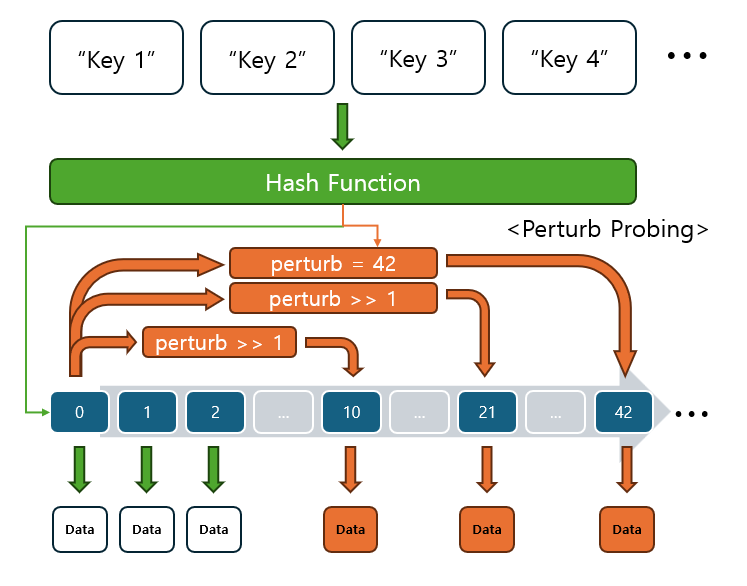
Python은 Open Addressing 방식 중에서 perturb 탐사법을 사용하여 충돌을 해결합니다.
- 이 방법은 이차 탐사와 유사하지만, perturb 값을 사용하여 탐사 위치를 더 복잡하게 계산함으로써 충돌을 해결합니다.
- perturb 탐사법은 Python이 충돌을 처리할 때 사용하는 고유한 방식입니다.
- 기본 해시 값에서 perturb 값을 조정하며 새로운 인덱스를 계산하고, 이 값을 기반으로 탐색 위치를 변경합니다.
perturb 탐사법의 동작 원리
-
첫 번째 시도:
해시 함수로부터 계산된 해시 값을 사용해 첫 번째 해시 인덱스를 계산합니다. 충돌이 없으면 데이터를 해당 인덱스에 저장합니다. -
충돌 발생 시:
만약 충돌이 발생하면, perturb 값을 이용하여 다음 탐사 위치를 계산합니다. perturb 값은 해시 값을 기반으로 계산되며, 충돌이 발생할 때마다 점진적으로 감소시킵니다. -
다음 위치 계산:
perturb 값을 사용해 새로운 인덱스를 계산하고, 이 값을 사용해 탐사 위치를 변경합니다. 탐사 위치는 계속 변하며, 충돌이 계속되면 테이블의 빈 슬롯을 찾아 데이터를 저장합니다. -
탐사 반복:
perturb 값은 충돌이 발생할 때마다 5비트씩 오른쪽으로 이동(>>5)시켜 값을 줄이고, 이를 기반으로 새로운 탐사 위치를 계속 계산합니다.
위 그림은 perturb 탐사법의 과정을 시각화한 것입니다.
- 해시 함수로부터 처음 해시 값을 계산하고, 충돌이 발생할 경우 perturb 값을 감소시키며 새로운 탐사 위치를 찾아가는 과정을 보여줍니다.
- 여기선 첫 해시값이
42라 가정했고, perturb 값은 2로 나누는>> 1연산을 예시로 사용했습니다- 실제론
2^5씩 감소하고 인덱스는 나머지 연산을 통해 계산됩니다.- 위 그림에서 perturb 값이 42에서 시작해 충돌이 발생할 때마다 값이 감소하면서, 새로운 인덱스가 계산되는 방식임을 알 수 있습니다.
perturb 탐사법 코드 예시
def perturb_probing(hash_value, table_size):
perturb = hash_value
index = hash_value % table_size
while True:
yield index
index = (5 * index + 1 + perturb) % table_size
perturb >>= 5 # perturb 값을 줄여가며 새로운 인덱스 탐사이 예시는 perturb 값을 사용해 충돌이 발생할 때마다 새로운 탐색 인덱스를 계산하여 반환하는 과정입니다.
perturb 탐사법의 장점
- 효율적인 충돌 처리:
- perturb 탐사법은 해시 충돌이 발생할 때 매우 효율적으로 빈 슬롯을 찾아낼 수 있습니다.
- 이는 이차 탐사보다 더 복잡한 방식으로 충돌을 해결하면서도 메모리 사용을 최소화하고 성능을 유지합니다.
- 리사이징(Resizing):
- 충돌이 빈번해지면 해시 테이블은 리사이징(Resizing)을 수행합니다.
- 해시 테이블의 크기를 늘려서 새로운 슬롯을 더 많이 할당하고, 기존의 데이터를 재배치(rehashing)하여 충돌을 최소화합니다.
이 방식 덕분에 Python의 딕셔너리와 집합은 데이터의 개수가 많아지더라도 상수 시간(O(1))에 가까운 성능을 유지할 수 있습니다.
2.3 Python의 충돌 처리 성능
Python의 perturb 탐사법은 충돌 처리 성능을 높이는 데 중요한 역할을 합니다.
- 이 방법은 단순한 탐사 기법보다 더 복잡하지만, 그만큼 충돌을 효과적으로 줄여주고, 큰 데이터셋에서도 성능을 유지할 수 있습니다.
다음 파트에서는 Python 해시 테이블의 성능 최적화와 리사이징에 대해 살펴보겠습니다.
3. Python 해시 테이블의 성능 최적화
Python의 해시 테이블 구조는 매우 효율적으로 설계되어 있어, 일반적으로 상수 시간(O(1))에 데이터를 추가, 삭제, 검색할 수 있습니다.
- 하지만 데이터 양이 많아지고 해시 충돌이 빈번해지면 성능이 저하될 수 있습니다. 이러한 문제를 해결하기 위해 Python은 몇 가지 최적화 기법을 적용합니다.
3.1 리사이징(Resizing)
Python의 딕셔너리와 집합은 해시 테이블의 크기가 일정 임계치에 도달하면 자동으로 크기를 조정하는 기능을 가지고 있습니다.
- 이를 리사이징(Resizing)이라고 하며, 이는 성능 최적화를 위한 중요한 단계입니다.
리사이징 시점: 해시 테이블의 사용된 슬롯의 비율이 특정 값을 넘으면(일반적으로 load factor가 기준) 테이블의 크기를 늘리고, 모든 항목을 재배치(rehashing) 합니다.
- Python 딕셔너리의 기본 Load Factor는
2/3입니다. - 즉, 전체 슬롯의
66.7%가 사용되면 테이블 크기를 두 배로 확장하고, 기존 데이터를 새로운 해시 인덱스에 맞춰 재배치합니다.
재해싱(Rehashing): 테이블의 크기가 확장되면 기존 항목들을 새로운 해시 테이블로 다시 분배해야 합니다. 이 과정을 재해싱이라고 합니다.
- Python에서는 새로운 테이블 크기에 맞춰 모든 항목의 해시 값을 다시 계산하고, 충돌을 피할 수 있도록 새로운 위치에 저장합니다.
my_dict = {
'apple': 1,
'banana': 2,
'cherry': 3
}
# 데이터가 증가하면서 일정 임계점에 도달하면 해시 테이블 크기 증가 및 리사이징 발생
my_dict['date'] = 4
my_dict['elderberry'] = 5
# Load Factor가 임계치를 넘으면 자동으로 리사이징 및 재해싱 발생리사이징의 장점
- 충돌 감소: 해시 테이블의 크기를 확장함으로써 슬롯이 더 많아지고, 충돌이 줄어듭니다.
- 성능 유지: 리사이징을 통해 해시 테이블의 밀도가 낮아지므로, 데이터 접근 속도는 O(1)에 가깝게 유지됩니다.
리사이징의 단점
- 비용: 리사이징 및 재해싱 과정은 상당한 비용이 발생할 수 있습니다. 테이블을 확장하는 동안 모든 데이터를 새로 해시해야 하기 때문에, 이 시점에서는 O(n)의 시간이 소요될 수 있습니다.
- 메모리 사용량 증가: 테이블 크기를 두 배로 확장하므로 메모리 사용량이 늘어날 수 있습니다.
3.2 해시 함수의 품질
해시 함수의 품질은 Python의 해시 테이블 성능에 중요한 영향을 미칩니다. 좋은 해시 함수는 충돌을 최소화하고 데이터를 균일하게 분배해야 합니다.
- Python의 해시 함수는 각 객체에 대해 고유한 해시 값을 생성하며, 충돌을 줄이기 위해 해시 값 계산 방식에 여러 최적화 기법을 적용하고 있습니다.
- 예를 들어,
str타입의 해시 계산에서는 문자열의 길이와 각 문자에 대한 계산을 포함하여 충돌을 최소화합니다.
- 예를 들어,
해시 함수의 기본 예시
hash("apple") # 문자열 'apple'의 해시 값을 반환
hash(42) # 정수 42의 해시 값을 반환Python의 해시 함수는 객체의 데이터 타입에 따라 다르게 작동하며, 정수, 문자열, 튜플 등 다양한 데이터 유형에 대해 최적화된 해시 알고리즘을 제공합니다.
- 이 해시 함수는 가능한 한 충돌을 줄이고 데이터를 균일하게 분포시키는 것을 목표로 합니다.
문자열(String)의 해시 함수
Python에서 문자열의 해시 값은 문자열의 길이와 각 문자의 값을 기반으로 계산됩니다.
- Python의 기본 해시 함수는 각 문자의 유니코드 코드 포인트를 사용하여 해시 값을 계산합니다.
- 이 과정에서 문자열의 길이가 길어지면 해시 충돌이 증가할 가능성이 있으므로, Python은 해시 값을 계산할 때 문자열의 각 문자를 서로 다른 비율로 가중치를 적용하여 충돌을 줄입니다.
# 문자열의 해시 값 생성
string_hash = hash("apple")
print(string_hash) # 각 실행마다 다른 해시 값이 생성될 수 있음 (hash randomization)정수(Integer)의 해시 함수
정수형 데이터의 해시 함수는 매우 단순합니다. 정수 값 자체가 해시 값으로 사용됩니다.
- 이 방식은 충돌이 거의 발생하지 않으며, 해시 테이블에서 매우 빠르게 접근할 수 있는 이점이 있습니다.
# 정수의 해시 값 생성
int_hash = hash(42)
print(int_hash) # 정수 42의 해시 값은 그 자체로 해시 값으로 사용커스텀 객체에서의 해시 함수 구현
사용자 정의 객체에서도 __hash__() 메서드를 통해 고유한 해시 함수를 정의할 수 있습니다.
- 이는 커스텀 객체를 해시 테이블 기반 자료구조에서 사용할 때 중요합니다.
- 해시 함수는
__eq__()메서드와 일관되게 작동해야 합니다. - 즉, 두 객체가 같다면 동일한 해시 값을 반환해야 하며, 서로 다른 객체는 가능한 다른 해시 값을 반환해야 합니다.
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def __hash__(self):
# 문자열 해시와 정수 해시를 조합하여 해시 값을 생성
return hash(self.name) ^ hash(self.age)
def __eq__(self, other):
return self.name == other.name and self.age == other.age
# 커스텀 객체의 해시 값 사용 예시
p1 = Person("Alice", 30)
p2 = Person("Bob", 25)
print(hash(p1)) # 커스텀 해시 값을 반환
print(hash(p2)) # p1과 다른 해시 값을 반환
해시 함수의 설계 원칙
- 일관성: 같은 객체에서
hash()를 여러 번 호출해도 항상 같은 값을 반환해야 합니다. - 충돌 최소화: 서로 다른 객체들은 가능한 한 다른 해시 값을 가져야 합니다.
- 효율성: 해시 함수는 계산이 간단하고 빠르게 실행되어야 합니다.
3.3 해시 랜덤화(Hash Randomization)
Python 3.3 이후 버전에서는 해시 랜덤화가 기본적으로 활성화되어 있습니다.
- 이는 해시 함수의 결과를 실행할 때마다 다른 해시 값을 생성하여, 해시 공격을 방지하기 위한 중요한 보안 기능입니다.
해시 랜덤화의 필요성
해시 기반 자료구조(예: 딕셔너리, 집합)는 빠른 검색과 삽입을 제공하지만, 해시 충돌이 많이 발생하면 성능이 급격히 저하될 수 있습니다.
- 특히, 해시 충돌을 의도적으로 유도하는 공격(DoS 공격)이 가능한데, 악의적인 사용자가 해시 테이블을 비효율적으로 만들어 성능을 저하시킬 수 있습니다.
이러한 상황을 방지하기 위해 Python은 해시 랜덤화를 도입하여, 같은 키라도 실행할 때마다 다른 해시 값이 생성되도록 했습니다. 이렇게 함으로써 고정된 해시 패턴을 악용하는 공격을 차단할 수 있습니다.
해시 랜덤화의 동작 방식
프로세스마다 다른 해시 시드 값이 생성되며, 이 시드를 사용해 해시 값을 랜덤하게 변형합니다.
- 해시 랜덤화는 문자열(str) 및 bytes 타입에 적용됩니다. 따라서 같은 문자열이라도 실행할 때마다 다른 해시 값이 생성됩니다.
# 같은 문자열이라도 실행마다 다른 해시 값이 생성
print(hash("apple"))위 코드에서 "apple"의 해시 값은 Python이 실행될 때마다 다르게 나올 수 있습니다. 이는 해시 테이블의 구조를 악용한 공격을 방어하는 중요한 기법입니다.
해시 랜덤화의 영향
- 보안 강화: 해시 충돌을 의도적으로 발생시키는 공격을 방어할 수 있어, 특히 웹 애플리케이션이나 네트워크 관련 시스템에서 유용합니다.
- 일관성 없는 해시 값: 문자열과 같은 해시 값이 실행할 때마다 달라지기 때문에, 개발 과정에서 디버깅이나 테스트할 때 예상하지 못한 해시 값이 발생할 수 있습니다. 그러나 이는 일반적으로 보안 강화의 장점이 더 크기 때문에 문제가 되지 않습니다.
해시 랜덤화 비활성화
특정 상황에서는 해시 값의 일관성이 필요할 수 있습니다.
- 예를 들어, 테스트 환경에서 해시 값이 동일하게 나오길 원할 때는 해시 랜덤화를 비활성화할 수 있습니다.
- 이를 위해 Python을 실행할 때
PYTHONHASHSEED환경 변수를 사용할 수 있습니다.
# 해시 랜덤화 비활성화
PYTHONHASHSEED=0 python my_script.py위와 같이 실행하면, 해시 랜덤화가 비활성화되고 모든 실행에서 동일한 해시 값을 사용하게 됩니다.
4. Python의 다양한 해시 테이블 구현체
Python에서는 해시 테이블의 개념이 여러 내장 자료구조에 적용됩니다.
- 특히 딕셔너리(Dictionary)와 집합(Set)이 대표적인 해시 테이블 기반 자료구조입니다.
- 이들 자료구조는 상수 시간(O(1))에 데이터를 삽입하고 검색하는 데 특화되어 있으며, 다양한 용도에 맞게 설계되었습니다.
아래 표는 Python의 주요 해시 테이블 기반 자료구조들의 특성과 용도, 시간 복잡도를 정리한 것입니다.
4.1 주요 구현체 비교표
| 자료구조 | 설명 | 중복 허용 | 순서 보장 | 시간 복잡도 (삽입,삭제,검색) | 용도 |
|---|---|---|---|---|---|
| Dict | 키-값 쌍으로 데이터를 저장하는 해시 테이블 | 키는 중복 불가 값은 중복 허용 | Python 3.7 이후 삽입 순서 유지 | O(1), O(1), O(1) | 키-값을 빠르게 저장, 검색할 때 |
| Set | 중복 없는 값을 저장하는 자료구조 | 중복 불가 | X | O(1), O(1), O(1) | 중복 없는 값의 집합을 저장할 때 |
| frozenset | 불변(immutable)한 집합 자료구조 | 중복 불가 | X | O(1), O(1), O(1) | 불변 데이터를 사용할 때, 해시 가능 |
| defaultdict | 기본값을 가지는 딕셔너리 | 키는 중복 불가 값은 중복 허용 | Python 3.7 이후 삽입 순서 유지 | O(1), O(1), O(1) | 초기 값이 없는 키에 대해 기본값 제공 |
| OrderedDict | 순서가 있는 딕셔너리 | 키는 중복 불가 값은 중복 허용 | 삽입 순서 유지 | O(1), O(1), O(1) | 순서를 보존하며 키-값을 저장할 때 |
| Counter | 요소의 개수를 저장하는 딕셔너리 | 중복 허용 (값의 개수 저장) | X | O(1), O(1), O(1) | 요소의 빈도를 계산할 때 |
4.2 각 구현체의 특징
- Dict: Python의 기본 딕셔너리 구현으로, 키-값 쌍으로 데이터를 저장합니다.
Python 3.7 이후부터 삽입된 순서를 유지하는 특성을 가집니다.
- 용도: 빠른 키-값 저장 및 검색을 요하는 경우.
- Set: 중복 없는 데이터를 저장하는 해시 테이블 기반 자료구조입니다.
순서는 보장되지 않으며, Python의set은 매우 빠른 시간 안에 데이터를 삽입하고 검색할 수 있습니다.
- 용도: 유일한 값의 집합을 저장하거나, 교집합, 합집합 등의 집합 연산이 필요할 때 사용.
- frozenset: 불변 집합 자료구조로,
set과 유사하지만 변경할 수 없습니다.
frozenset은 해시가 가능하여 set의 요소로 사용할 수 있습니다.
- 용도: 불변 집합으로 데이터를 다룰 때.
- defaultdict: 기본값을 제공하는 딕셔너리로, 키가 없을 때 자동으로 기본값을 생성해주는 기능이 있습니다.
- 용도: 딕셔너리에서 키가 없을 때 기본값을 자동으로 처리하고 싶을 때 사용.
- OrderedDict: Python 3.6 이전에 삽입 순서를 유지하기 위한 딕셔너리였습니다.
현재는 기본 dict가 순서를 유지하지만, 특정한 상황에서는OrderedDict를 명시적으로 사용할 수 있습니다.
- 용도: 순서가 중요한 경우 키-값을 저장하고 싶을 때.
- Counter: 데이터의 빈도를 계산하는 데 사용되는 딕셔너리.
각 값이 몇 번 등장했는지 세고 저장합니다.
- 용도: 데이터의 등장 횟수를 셀 때 유용하며, 텍스트 분석 등에서 자주 사용됩니다.
마무리
이번 포스팅에서는 Python의 해시 테이블 기반 자료구조인 딕셔너리(Dict)와 집합(Set)을 중심으로 그 동작 원리와 충돌 해결 방식에 대해 살펴보았습니다.
- 특히, perturb 탐사법을 통해 Python이 해시 충돌을 어떻게 효율적으로 해결하는지에 대해 중점적으로 다루었으며, 이를 통해 Python의 해시 테이블이 어떻게 빠른 성능을 유지할 수 있는지 이해할 수 있었습니다.
또한, Python의 해시 테이블 성능 최적화를 위한 리사이징(Resizing)과 해시 함수 품질의 중요성, 그리고 해시 랜덤화를 통한 보안 강화 방식을 설명했습니다.
마지막으로, Python에서 제공하는 다양한 해시 테이블 기반 자료구조들을 표로 정리하여 각각의 특성과 용도, 시간 복잡도를 비교해 보았습니다.
Python의 해시 테이블은 일상적인 프로그래밍에서 매우 자주 사용되는 자료구조로, 그 특성과 성능 최적화를 잘 이해하면 더 효율적으로 데이터를 처리할 수 있습니다.
