코드스테이츠 AI Bootcamp Section2에서 자유주제로 진행한 Machine Learning 개인프로젝트 내용 정리 및 회고. (2) 모델링 및 모델 하이퍼파라미터 튜닝
- (1) 서론과 데이터준비 과정
- (2) 모델링 및 모델 하이퍼파라미터 튜닝
- (3) Model 해석, 결론, 회고
- Github Repository 바로가기 : Project-Hypertension-Predictive-Model (클릭)
한국형 고혈압 예측 모델 개발 (Hypertension Predictive Model)
- 고혈압 진단기준에 따른 차이가 있을까?

- Tech Stack

00. 프로젝트 개요
필수 포함 요소
자유 주제로 직접 선택한 데이터셋을 사용머신러닝 예측 모델을 통한성능 및 인사이트를 도출/공유- 데이터셋
전처리/EDA부터모델을 해석하는 과정까지 수행 - 발표를 듣는 사람은
비데이터 직군이라 가정
프로젝트 목차
-
Introduction
서론- Hypertension
고혈압 - Diagnotic Criteria
고혈압 진단기준 - Problems & Goals
문제정의 및 목표 - Dataset
선정 데이터셋 - Target & Features
타겟과 특성
- Hypertension
-
Data Preparation
데이터 준비- Data Pre-processing
데이터 전처리 - Final Data
최종데이터
- Data Pre-processing
-
Modeling
모델링- Data split
데이터 분리 - Baseline & Metrics
기준모델 및 평가지표 - Modeling(default)
기본값으로 모델링 - Hyperparameter Tuning
모델 튜닝 - Final Model & Test
최종모델 및 테스트
- Data split
-
Interpretation
해석- Feature Importance (MDI)
특성중요도 - Permutation Importance
순열중요도 - Feature Analysis (PDP)
특성 분석
- Feature Importance (MDI)
-
Conclusion
결론- Summary
요약 - Conclusion & Limitation
결론 및 한계점 - Retrospective
회고
- Summary
03. Modeling 모델링
3-0. Library & Data Import
- 이번에도 진행과정에서는 pandas_profiling을 이용했지만, Github 출력문제로 비활성화시킴
Library import
import pandas as pd
# from pandas_profiling import ProfileReport
import numpy as np
import scipy as sp
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'Malgun Gothic'
plt.rcParams['axes.unicode_minus'] = False
import seaborn as sns
#머신러닝 패키지
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import accuracy_score, roc_auc_score, roc_curve, confusion_matrix
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import MinMaxScaler
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier
from sklearn.model_selection import cross_val_score, cross_val_predict, KFoldData import
df0 = pd.read_csv('data/KNHANES_8th_final2.csv')
#ID, year column 제외
df1 = df0.iloc[:,2:]
df1.info()
#output
'''
RangeIndex: 11422 entries, 0 to 11421
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sex 11422 non-null int64
1 age 11422 non-null int64
2 heavy_drink 11422 non-null int64
3 smoke 11422 non-null int64
4 genetic_hbp 11422 non-null float64
5 BMI 11422 non-null float64
6 diabetes 11422 non-null int64
7 hyper_chol 11422 non-null int64
8 triglycerides 11422 non-null float64
9 HBP_US 11422 non-null int64
10 HBP_EU 11422 non-null int64
dtypes: float64(3), int64(8)
memory usage: 981.7 KB
'''3-1. Data Split 데이터 분리
- Data Leakage를 방지하기 위해 훈련데이터와 테스트데이터를
8:2비율로 분리하였음. - 모델의 예측 신뢰성을 높이기 위해 훈련데이터에 대한 Cross-Validation(교차검증)을 진행하였고, K값(CV값)은 모두
5로 통일하여 진행하였음.
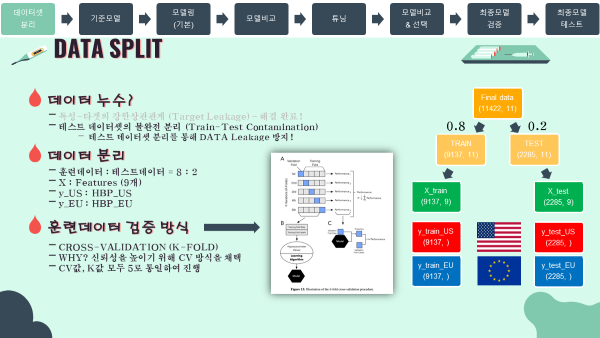
- 훈련, 테스트 데이터 분리
train, test = train_test_split(df1,test_size=0.2,random_state=42)
#출력
print('분리전 : {}\n'.format(df1.shape))
print('훈련&검증데이터 : {}'.format(train.shape))
print('테스트데이터 : {}'.format(test.shape))
#output
'''
분리전 : (11422, 11)
훈련&검증데이터 : (9137, 11)
테스트데이터 : (2285, 11)
'''- 특성(X), 타겟(y_US, y_EU) 분리
#특성, 타겟 지정
features = df1.drop(columns=['HBP_US','HBP_EU']).columns
target_us = 'HBP_US'
target_eu = 'HBP_EU'
#훈련 및 검증 데이터
X_train = train[features]
y_train_us = train[target_us]
y_train_eu = train[target_eu]
#테스트 데이터
X_test = test[features]
y_test_us = test[target_us]
y_test_eu = test[target_eu]
#출력
print('X y 분리 후 shape\n')
print('X_train : {}'.format(X_train.shape))
print('y_train(US) : {}'.format(y_train_us.shape))
print('y_train(EU) : {}\n'.format(y_train_eu.shape))
print('X_test : {}'.format(X_test.shape))
print('y_test(US) : {}'.format(y_test_us.shape))
print('y_test(EU) : {}'.format(y_test_eu.shape))
#output
'''
X y 분리 후 shape
X_train : (9137, 9)
y_train(US) : (9137,)
y_train(EU) : (9137,)
X_test : (2285, 9)
y_test(US) : (2285,)
y_test(EU) : (2285,)
'''3-2. Baseline & Metrics 기준모델 및 평가지표
- 모델 평가의 기준이 되는 기준점(Baseline)은 분류문제이므로 타겟의 최빈 클래스로 지정하였음.
- 평가지표는 데이터 불균형이 심하지 않다고 판단하여 Accuarcy(정확도)와 ROC_AUC score로 선정하였음.
- 미국과 유럽 두 진단기준을 비교할 때는 기준점 점수가 0.5로 같은 ROC_AUC 점수를 기준으로 비교분석을 주로 진행하였음.
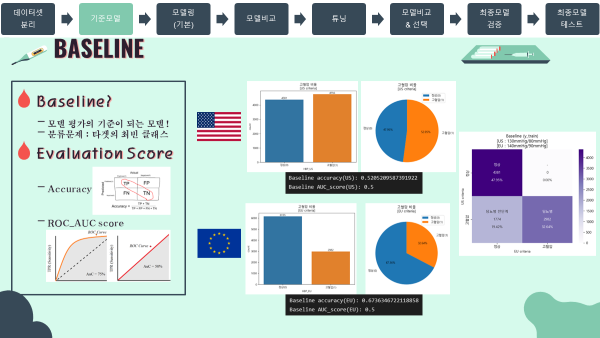
- 미국 진단기준 baseline
base_us = y_train_us.mode()[0]
baseline_us = [base_us]*len(y_train_us)
print("Baseline accuracy(US): {}".format(
accuracy_score(y_train_us, baseline_us)))
print("Baseline AUC_score(US): {}".format(
roc_auc_score(y_train_us, baseline_us)))
#output
'''
Baseline accuracy(US): 0.5205209587391922
Baseline AUC_score(US): 0.5
'''- 유럽 진단기준 baseline
base_eu = y_train_eu.mode()[0]
baseline_eu = [base_eu]*len(y_train_eu)
print("Baseline accuracy(EU): {}".format(
accuracy_score(y_train_eu, baseline_eu)))
print("Baseline AUC_score(EU): {}".format(
roc_auc_score(y_train_eu, baseline_eu)))
#output
'''
Baseline accuracy(EU): 0.6736346722118858
Baseline AUC_score(EU): 0.5
'''- 미국 & 유럽 진단기준 Baseline heatmap (sklearn matplotlib seaborn)
cfm_baseline_us = confusion_matrix(y_train_us,y_train_eu)
group_names_baseline_us = ['정상','-','당뇨병 전단계','당뇨병']
group_counts_baseline_us = ['{0:0.0f}'.format(value) for value in cfm_baseline_us.flatten()]
group_percentages_baseline_us = ['{0:.2%}'.format(value) for value in cfm_baseline_us.flatten()/np.sum(cfm_baseline_us)]
labels_baseline_us = [f'{v1}\n\n{v2}\n\n{v3}' for v1,v2,v3 in zip(group_names_baseline_us,group_counts_baseline_us,group_percentages_baseline_us)]
labels_baseline_us = np.asarray(labels_baseline_us).reshape(2,2)
tick_baseline_us = ['정상','고혈압']
sns.heatmap(cfm_baseline_us, annot=labels_baseline_us, fmt='',cmap='Purples',xticklabels=tick_baseline_us,yticklabels=tick_baseline_us)
plt.xlabel('EU criteria')
plt.ylabel('US criteria')
plt.title('Baseline (y_train)\n[US : 130mmHg/80mmHg]\n[EU : 140mmHg/90mmHg]')
plt.show()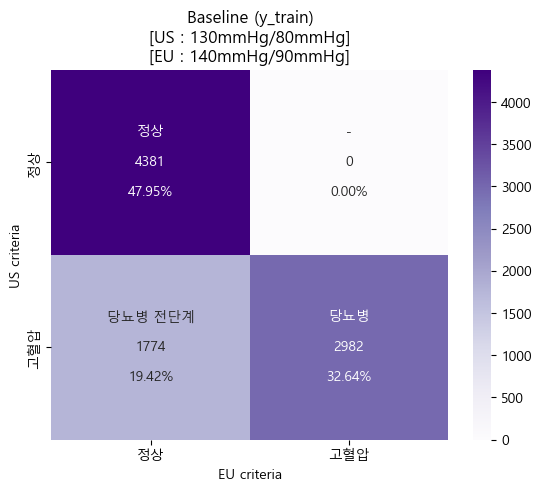
3-3. Modeling(default) 기본값으로 모델링
- 우선 설정값을 거의 건드리지 않은 기본값으로 모델링을 진행하였음.
- 진행한 모델들은 다음과 같음
- 선형모델 : Logistic Regression
- 트리모델 : Decision Tree
- 앙상블모델(배깅) : Random Forest
- 앙상블모델(부스팅) : XG Boost
-
선형모델의 경우 분포가 치우치지 않도록 하는 것이 중요하기 때문에, 별도의 전처리 과정을 진행한 데이터를 이용하였음.
-
연속형 변수 분포 확인 (matplotlib seaborn)
num_feat = ['BMI','triglycerides']
sns.pairplot(X_train[num_feat])
plt.show()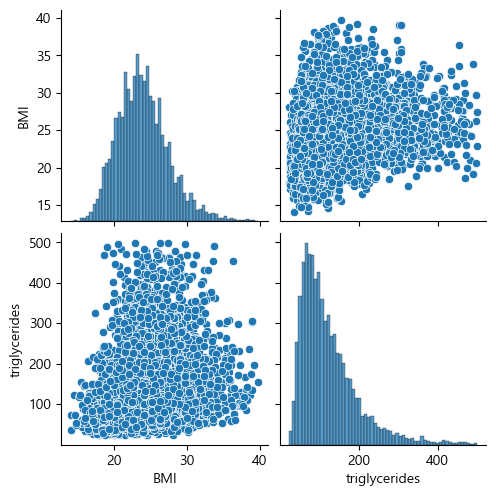
- 분포가 치우쳐져있는 중성지방 column에 대해서만 Log Transformation을 진행해 분포를 맞추어 주었음.
log_cols = ['triglycerides']
X_train_log = X_train.copy()
X_train_log[log_cols] = np.log(X_train_log[log_cols])
X_test_log = X_test.copy()
X_test_log[log_cols] = np.log(X_test_log[log_cols])
sns.pairplot(X_train_log[num_feat])
plt.show()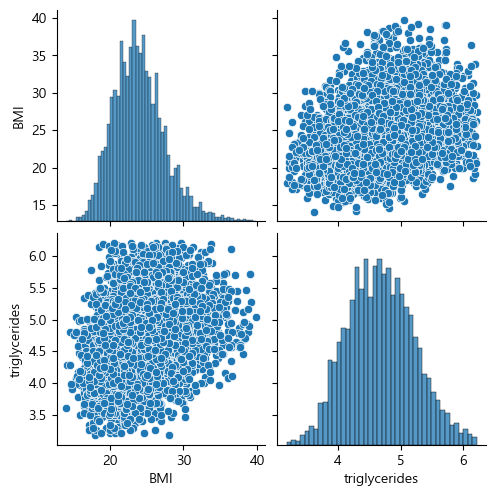
Logistic Regression (default)
- log transformation을 거친 데이터로 훈련 및 검증 진행
- 범주형 변수, 연속형 변수 모두 분포를 0과 1로 맞추기 위해 MinMaxScaler로 전처리하는 파이프라인을 구성함
미국 진단기준 (130mmHg/80mmHg)
- 미국 진단기준 파이프라인 & fit
pipe_logis_us = make_pipeline(
MinMaxScaler(),
LogisticRegression()
)
pipe_logis_us.fit(X_train_log,y_train_us)
#output
'''
Pipeline(steps=[('minmaxscaler', MinMaxScaler()),
('logisticregression', LogisticRegression())])
'''- 미국 진단기준 confusion matrix (cv=5)
#교차검증 결과
CV_pred_logis_us = cross_val_predict(pipe_logis_us,X_train_log,y_train_us,cv=5,n_jobs=-1)
#heatmap
cfm_logis_us = confusion_matrix(y_train_us,CV_pred_logis_us)
group_names_logis_us = ['True Negative','False Positive','False Negative','True Positive']
group_counts_logis_us = ['{0:0.0f}'.format(value) for value in cfm_logis_us.flatten()]
group_percentages_logis_us = ['{0:.2%}'.format(value) for value in cfm_logis_us.flatten()/np.sum(cfm_logis_us)]
labels_logis_us = [f'{v1}\n\n{v2}\n\n{v3}' for v1,v2,v3 in zip(group_names_logis_us,group_counts_logis_us,group_percentages_logis_us)]
labels_logis_us = np.asarray(labels_logis_us).reshape(2,2)
tick_logis_us = ['정상','고혈압']
sns.heatmap(cfm_logis_us, annot=labels_logis_us, fmt='',cmap='Reds',xticklabels=tick_logis_us,yticklabels=tick_logis_us)
plt.xlabel('Predicted(예측)')
plt.ylabel('Real(실제)')
plt.title('Confusion matrix of LogisticRegression\n[US criteria] (CV=5)')
plt.show()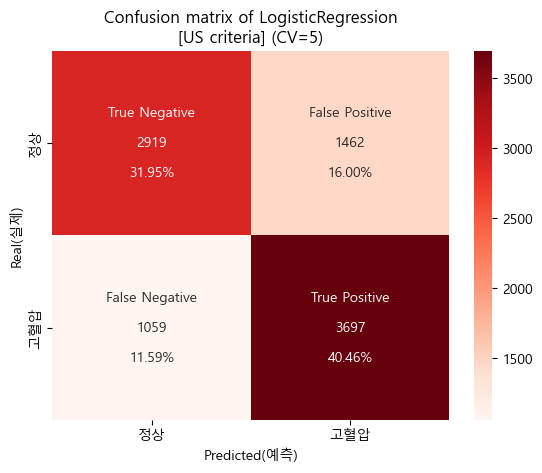
- 미국 진단기준 ROC_AUC curve (cv=5)
kf_5 = KFold(n_splits=5,shuffle=True,random_state=42)
tprs_logis_us = []
base_fpr_logis_us = np.linspace(0,1,300)
for train_idx, val_idx in kf_5.split(X_train_log):
X_train_cv, X_val_cv = X_train_log.iloc[train_idx], X_train_log.iloc[val_idx]
y_train_us_cv, y_val_us_cv = y_train_us.iloc[train_idx], y_train_us.iloc[val_idx]
pipe_logis_us.fit(X_train_cv,y_train_us_cv)
y_val_us_prob = pipe_logis_us.predict_proba(X_val_cv)[:,1]
FPR_logis_us, TPR_logis_us, _ = roc_curve(y_val_us_cv,y_val_us_prob)
plt.plot(FPR_logis_us,TPR_logis_us,alpha=.25)
tpr_us = np.interp(base_fpr_logis_us,FPR_logis_us,TPR_logis_us)
tpr_us[0] = 0.0
tprs_logis_us.append(tpr_us)
tprs_logis_us = np.array(tprs_logis_us)
mean_tprs_logis_us = tprs_logis_us.mean(axis=0)
plt.plot(base_fpr_logis_us,mean_tprs_logis_us,label='LogisticRegression(CV=5)',color='red')
plt.plot([0,1],[0,1],label='Baseline',color='black',linestyle='--',alpha=.5)
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC_curve of LogisticRegression\n[US criteria] (CV=5)')
plt.legend(loc='lower right')
plt.show()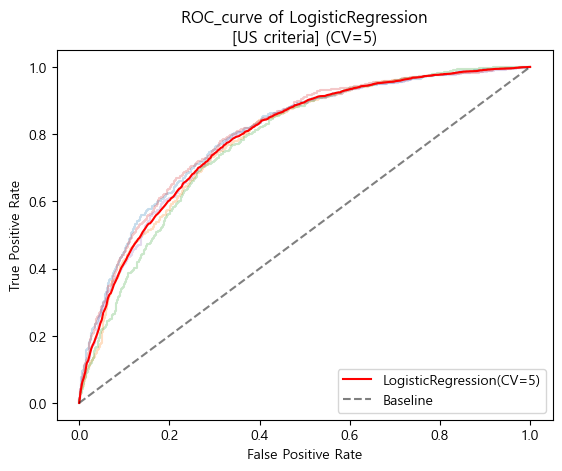
- 미국 진단기준 검증 Score
#accuracy
CV_score_accuracy_logis_us = cross_val_score(pipe_logis_us,X_train_log,y_train_us,cv=5,n_jobs=-1,scoring='accuracy')
print('[US criteria]')
print("Baseline accuracy(US): {}".format(accuracy_score(y_train_us, baseline_us)))
print('LogisticRegression accuracy(US): {}'.format(CV_score_accuracy_logis_us.mean()))
#output
'''
[US criteria]
Baseline accuracy(US): 0.5205209587391922
LogisticRegression accuracy(US): 0.7240900832276369
'''#AUC score
CV_score_auc_logis_us = cross_val_score(pipe_logis_us,X_train_log,y_train_us,cv=5,n_jobs=-1,scoring='roc_auc')
print('[US criteria]')
print("Baseline AUC_score(US): {}".format(roc_auc_score(y_train_us, baseline_us)))
print('LogisticRegression AUC_score(US) : {}'.format(CV_score_auc_logis_us.mean()))
#output
'''
[US criteria]
Baseline AUC_score(US): 0.5
LogisticRegression AUC_score(US) : 0.7911785348771734
'''유럽 진단기준 (140mmHg/90mmHg)
- 유럽 진단기준 파이프라인 & fit
pipe_logis_eu = make_pipeline(
MinMaxScaler(),
LogisticRegression()
)
pipe_logis_eu.fit(X_train_log,y_train_eu)
#output
'''
Pipeline(steps=[('minmaxscaler', MinMaxScaler()),
('logisticregression', LogisticRegression())])
'''- 유럽 진단기준 confusion matrix (cv=5)
#교차검증 결과
CV_pred_logis_eu = cross_val_predict(pipe_logis_eu,X_train_log,y_train_eu,cv=5,n_jobs=-1)
#heatmap
cfm_logis_eu = confusion_matrix(y_train_eu,CV_pred_logis_eu)
group_names_logis_eu = ['True Negative','False Positive','False Negative','True Positive']
group_counts_logis_eu = ['{0:0.0f}'.format(value) for value in cfm_logis_eu.flatten()]
group_percentages_logis_eu = ['{0:.2%}'.format(value) for value in cfm_logis_eu.flatten()/np.sum(cfm_logis_eu)]
labels_logis_eu = [f'{v1}\n\n{v2}\n\n{v3}' for v1,v2,v3 in zip(group_names_logis_eu,group_counts_logis_eu,group_percentages_logis_eu)]
labels_logis_eu = np.asarray(labels_logis_eu).reshape(2,2)
tick_logis_eu = ['정상','고혈압']
sns.heatmap(cfm_logis_eu, annot=labels_logis_eu, fmt='',cmap='Blues',xticklabels=tick_logis_eu,yticklabels=tick_logis_eu)
plt.xlabel('Predicted(예측)')
plt.ylabel('Real(실제)')
plt.title('Confusion matrix of LogisticRegression\n[EU criteria] (CV=5)')
plt.show()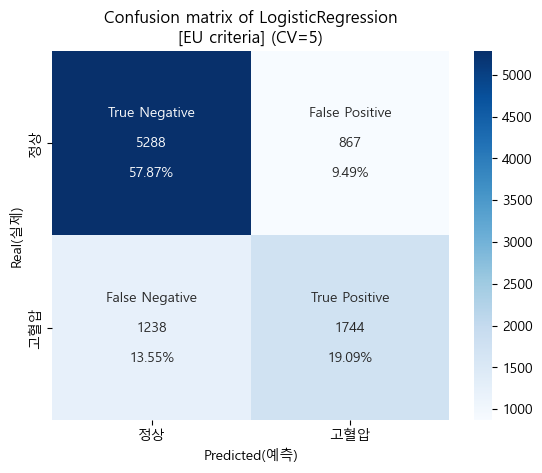
- 유럽 진단기준 ROC_AUC curve (cv=5)
tprs_logis_eu = []
base_fpr_logis_eu = np.linspace(0,1,300)
for train_idx, val_idx in kf_5.split(X_train_log):
X_train_cv, X_val_cv = X_train_log.iloc[train_idx], X_train_log.iloc[val_idx]
y_train_eu_cv, y_val_eu_cv = y_train_eu.iloc[train_idx], y_train_eu.iloc[val_idx]
pipe_logis_eu.fit(X_train_cv,y_train_eu_cv)
y_val_eu_prob = pipe_logis_eu.predict_proba(X_val_cv)[:,1]
FPR_logis_eu, TPR_logis_eu, _ = roc_curve(y_val_eu_cv,y_val_eu_prob)
plt.plot(FPR_logis_eu,TPR_logis_eu,alpha=.25)
tpr_eu = np.interp(base_fpr_logis_eu,FPR_logis_eu,TPR_logis_eu)
tpr_eu[0] = 0.0
tprs_logis_eu.append(tpr_eu)
tprs_logis_eu = np.array(tprs_logis_eu)
mean_tprs_logis_eu = tprs_logis_eu.mean(axis=0)
plt.plot(base_fpr_logis_eu,mean_tprs_logis_eu,label='LogisticRegression(CV=5)',color='blue')
plt.plot([0,1],[0,1],label='Baseline',color='black',linestyle='--',alpha=.5)
plt.title('ROC_curve of LogisticRegression\n[EU criteria] (CV=5)')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.legend(loc='lower right')
plt.show()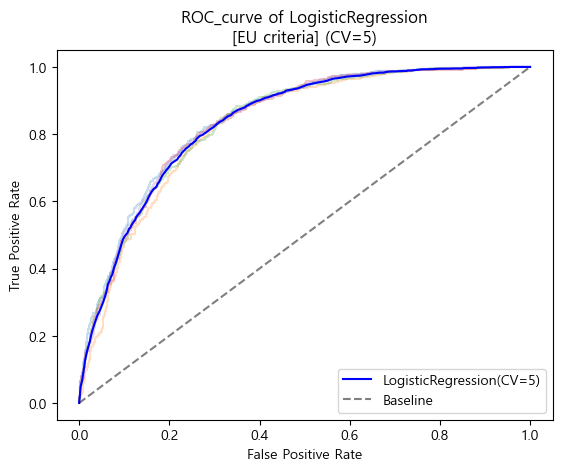
- 유럽 진단기준 검증 Score
#accuracy
CV_score_accuracy_logis_eu = cross_val_score(pipe_logis_eu,X_train_log,y_train_eu,cv=5,n_jobs=-1,scoring='accuracy')
print('[EU criteria]')
print("Baseline accuracy(EU): {}".format(accuracy_score(y_train_eu, baseline_eu)))
print('LogisticRegression accuracy(EU): {}'.format(CV_score_accuracy_logis_eu.mean()))
#output
'''
[EU criteria]
Baseline accuracy(EU): 0.6736346722118858
LogisticRegression accuracy(EU): 0.7696176606913798
'''#AUC score
CV_score_auc_logis_eu = cross_val_score(pipe_logis_eu,X_train_log,y_train_eu,cv=5,n_jobs=-1,scoring='roc_auc')
print('[EU criteria]')
print("Baseline AUC_score(EU): {}".format(roc_auc_score(y_train_eu, baseline_eu)))
print('LogisticRegression AUC_score(EU) : {}'.format(CV_score_auc_logis_eu.mean()))
#output
'''
[EU criteria]
Baseline AUC_score(EU): 0.5
LogisticRegression AUC_score(EU) : 0.8377120074901867
'''US vs EU 비교
- Accuracy barplot (matplotlib)
df_accuacy_logis = pd.DataFrame({'US criteria':[CV_score_accuracy_logis_us.mean()]
,'EU criteria':[CV_score_accuracy_logis_eu.mean()]},
index=['Accuracy'])
ax = sns.barplot(data=df_accuacy_logis,palette=['red','blue'])
ax.bar_label(ax.containers[0])
plt.title('Accuracy of LogisticRegression\n[ US vs EU ] (CV=5)')
plt.ylim(0,1)
plt.show()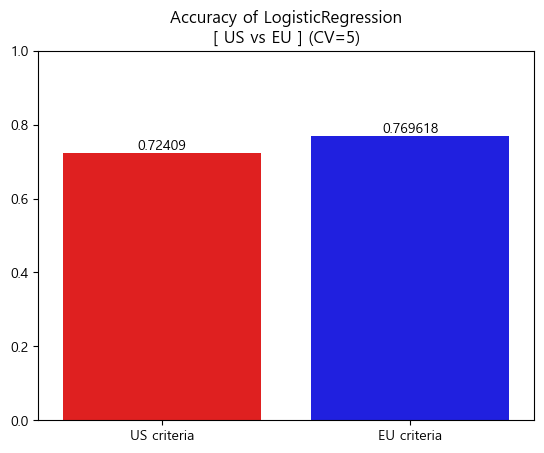
- ROC curve (matplotlib)
plt.plot(base_fpr_logis_eu,mean_tprs_logis_eu,label='LogisticRegression(CV=5) EU',color='blue')
plt.plot(base_fpr_logis_us,mean_tprs_logis_us,label='LogisticRegression(CV=5) US',color='red')
plt.plot([0,1],[0,1],label='Baseline',color='black',linestyle='--',alpha=0.5)
plt.title('ROC_curve of LogisticRegression\n[ US vs EU ] (CV=5)')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.legend(loc='lower right')
plt.show()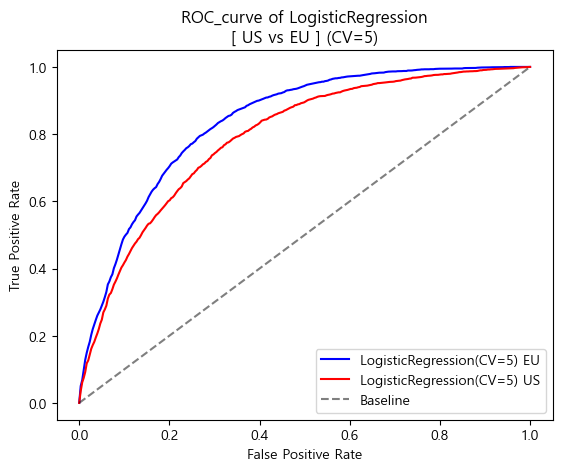
- Accuracy & AUC Score
print('[Accuracy]')
print('LogisticRegression accuracy(US): {}'.format(CV_score_accuracy_logis_us.mean()))
print('LogisticRegression accuracy(EU): {}'.format(CV_score_accuracy_logis_eu.mean()))
print('[AUC_score]')
print('LogisticRegression AUC_score(US) : {}'.format(CV_score_auc_logis_us.mean()))
print('LogisticRegression AUC_score(EU) : {}'.format(CV_score_auc_logis_eu.mean()))
#output
'''
[Accuracy]
LogisticRegression accuracy(US): 0.7240900832276369
LogisticRegression accuracy(EU): 0.7696176606913798
[AUC_score]
LogisticRegression AUC_score(US) : 0.7911785348771734
LogisticRegression AUC_score(EU) : 0.8377120074901867
'''Decision Tree (default)
- 트리기반 모델이기 때문에 전처리를 거치지 않은 데이터를 그대로 이용하였음.
- 처음 모델링 과정을 제외하고 나머지 그래프 소스코드는 위에 소개한 선형회귀와 거의 동일하기 때문에 코드는 따로 첨부하지 않고, output과 그래프 이미지만 표시하도록 하겠음.

미국 진단기준 (130mmHg/80mmHg)
- 미국 진단기준 모델 & fit
dtc_us = DecisionTreeClassifier(random_state=42)
dtc_us.fit(X_train,y_train_us)
#output
'''
DecisionTreeClassifier(random_state=42)
'''-
미국 진단기준 confusion matrix (cv=5)
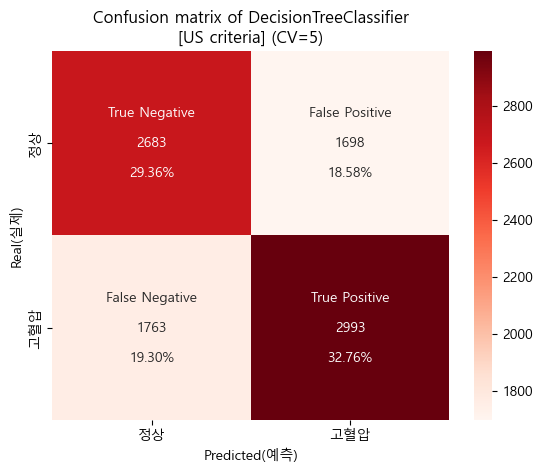
-
미국 진단기준 ROC_AUC curve (cv=5)
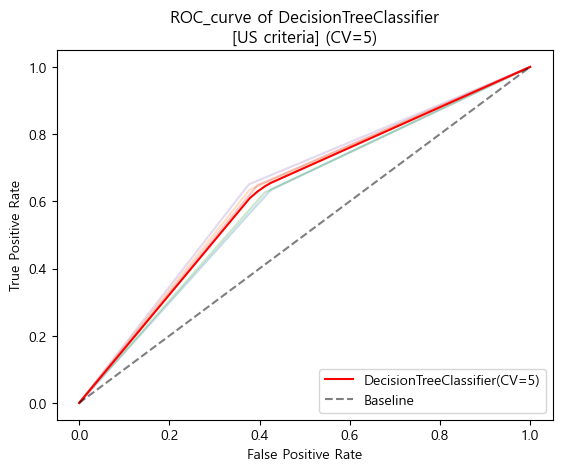
-
미국 진단기준 검증 Score
'''
[US criteria]
Baseline accuracy(US): 0.5205209587391922
DecisionTreeClassifier accuracy(US): 0.6212123879708578
''''''
[US criteria]
Baseline AUC_score(US): 0.5
DecisionTreeClassifier AUC_score(US) : 0.6209983430921373
'''유럽 진단기준 (140mmHg/90mmHg)
- 유럽 진단기준 모델 & fit
dtc_eu = DecisionTreeClassifier(random_state=42)
dtc_eu.fit(X_train,y_train_eu)
#output
'''
DecisionTreeClassifier(random_state=42)
'''-
유럽 진단기준 confusion matrix (cv=5)
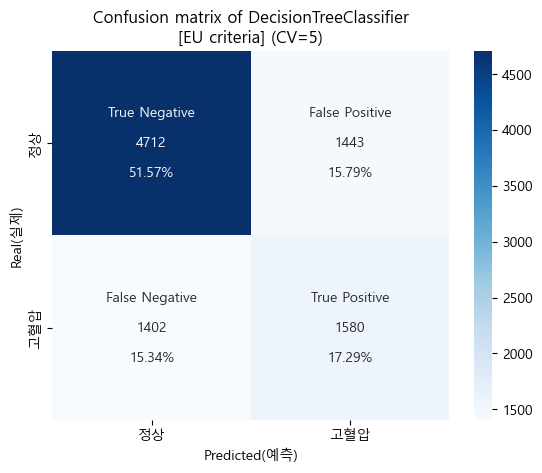
-
유럽 진단기준 ROC_AUC curve (cv=5)
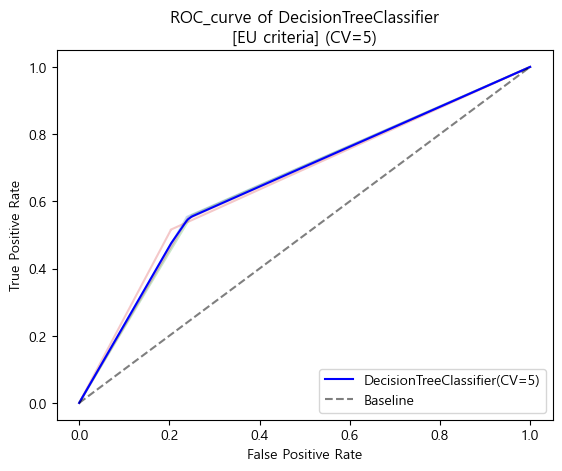
-
유럽 진단기준 검증 Score
'''
[EU criteria]
Baseline accuracy(EU): 0.6736346722118858
DecisionTreeClassifier accuracy(EU): 0.6886283908165747
''''''
[EU criteria]
Baseline AUC_score(EU): 0.5
DecisionTreeClassifier AUC_score(EU) : 0.64779191985238
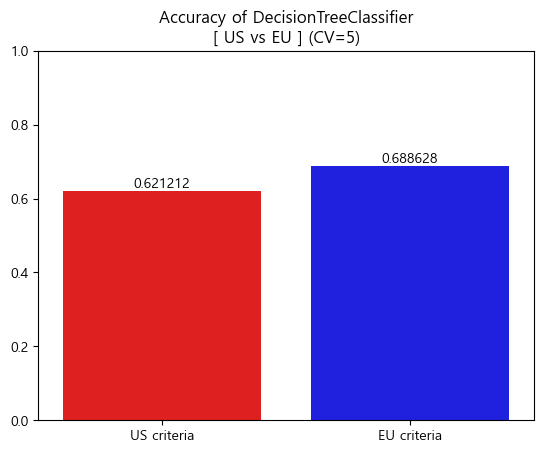
'''US vs EU 비교
-
Accuracy barplot (matplotlib)
-
ROC curve (matplotlib)
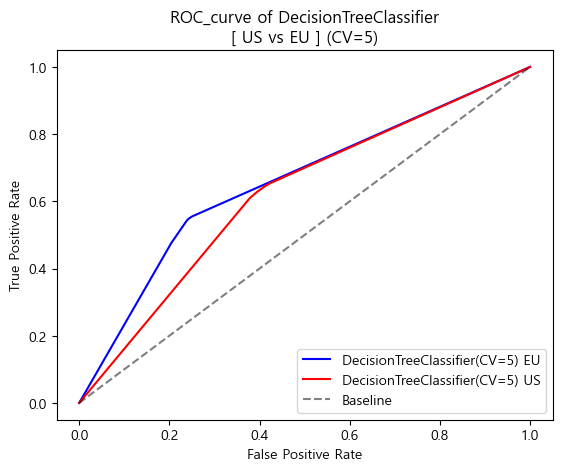
-
Accuracy & AUC Score
'''
[Accuracy]
DecisionTreeClassifier accuracy(US): 0.6212123879708578
DecisionTreeClassifier accuracy(EU): 0.6886283908165747
[AUC_score]
DecisionTreeClassifier AUC_score(US) : 0.6209983430921373
DecisionTreeClassifier AUC_score(EU) : 0.64779191985238
'''Random Forest (default)
- 트리기반 모델이기 때문에 전처리를 거치지 않은 데이터를 그대로 이용하였음.
- 처음 모델링 과정을 제외하고 나머지 그래프 소스코드는 위에 소개한 선형회귀와 거의 동일하기 때문에 코드는 따로 첨부하지 않고, output과 그래프 이미지만 표시하도록 하겠음.
미국 진단기준 (130mmHg/80mmHg)
- 미국 진단기준 모델 & fit
rfc_us = RandomForestClassifier(random_state=42,n_jobs=-1)
rfc_us.fit(X_train,y_train_us)
#output
'''
RandomForestClassifier(n_jobs=-1, random_state=42)
'''-
미국 진단기준 confusion matrix (cv=5)
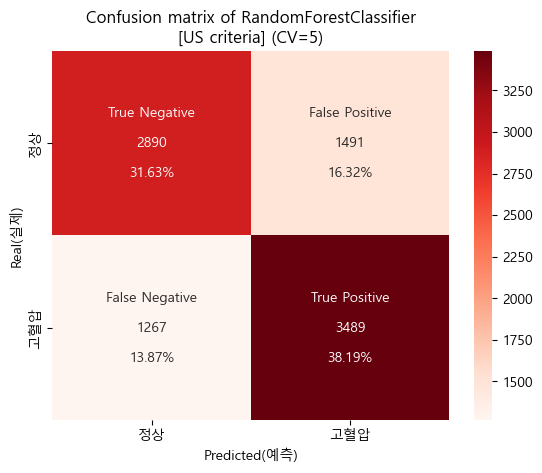
-
미국 진단기준 ROC_AUC curve (cv=5)
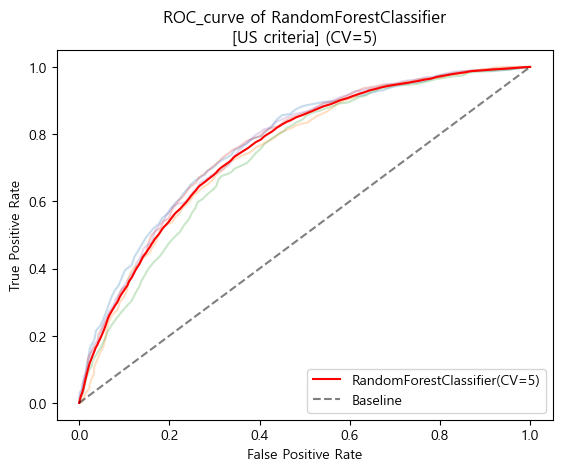
-
미국 진단기준 검증 Score
'''
[US criteria]
Baseline accuracy(US): 0.5205209587391922
RandomForestClassifier accuracy(US): 0.6981511224173264
''''''
[US criteria]
Baseline AUC_score(US): 0.5
RandomForestClassifier AUC_score(US) : 0.7607686634978762
'''유럽 진단기준 (140mmHg/90mmHg)
- 유럽 진단기준 모델 & fit
rfc_eu = RandomForestClassifier(random_state=42,n_jobs=-1)
rfc_eu.fit(X_train,y_train_eu)
#output
'''
RandomForestClassifier(n_jobs=-1, random_state=42)
'''-
유럽 진단기준 confusion matrix (cv=5)
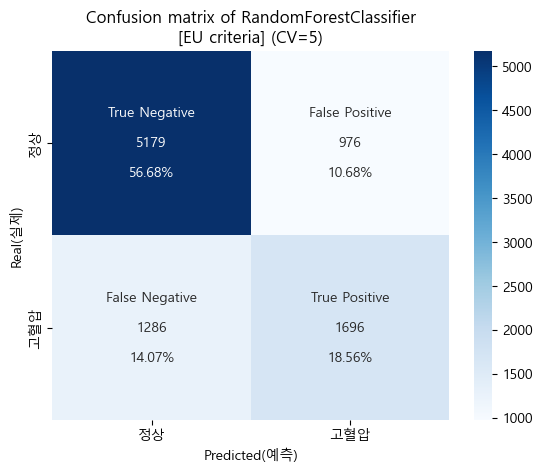
-
유럽 진단기준 ROC_AUC curve (cv=5)
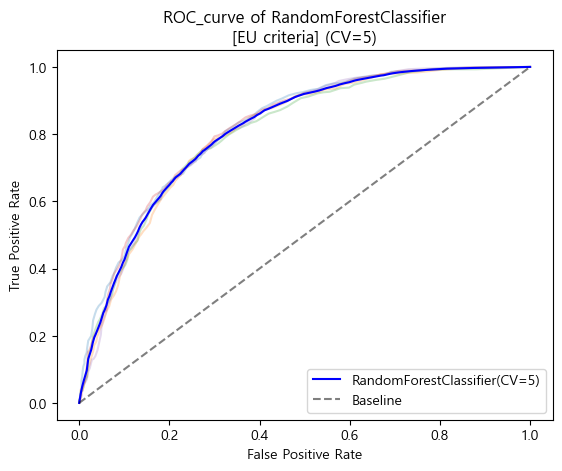
-
유럽 진단기준 검증 Score
'''
[EU criteria]
Baseline accuracy(EU): 0.6736346722118858
RandomForestClassifier accuracy(EU): 0.7524362857645888
''''''
[EU criteria]
Baseline AUC_score(EU): 0.5
RandomForestClassifier AUC_score(EU) : 0.8098342494013966
'''US vs EU 비교
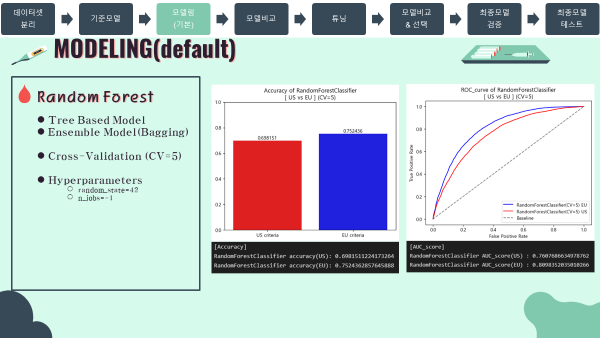
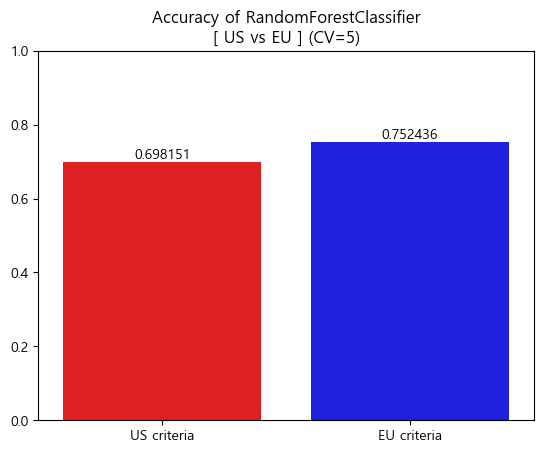
-
Accuracy barplot (matplotlib)
-
ROC curve (matplotlib)
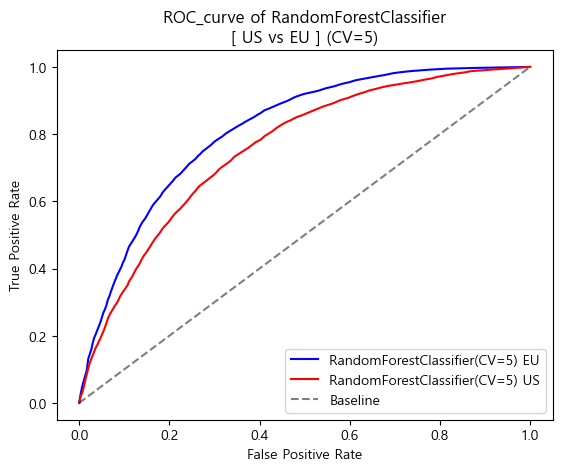
-
Accuracy & AUC Score
'''
[Accuracy]
RandomForestClassifier accuracy(US): 0.6981511224173264
RandomForestClassifier accuracy(EU): 0.7524362857645888
[AUC_score]
RandomForestClassifier AUC_score(US) : 0.7607686634978762
RandomForestClassifier AUC_score(EU) : 0.8098342494013966
'''XG Boost (default)
- 트리기반 모델이기 때문에 전처리를 거치지 않은 데이터를 그대로 이용하였음.
- 처음 모델링 과정을 제외하고 나머지 그래프 소스코드는 위에 소개한 선형회귀와 거의 동일하기 때문에 코드는 따로 첨부하지 않고, output과 그래프 이미지만 표시하도록 하겠음.
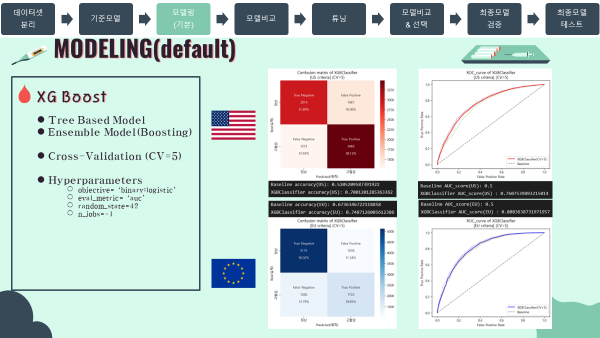
미국 진단기준 (130mmHg/80mmHg)
- 미국 진단기준 모델 & fit
xgb_us = XGBClassifier(objective='binary:logistic',
eval_metric='auc',
random_state=42,n_jobs=-1)
xgb_us.fit(X_train,y_train_us)
#output
'''
XGBClassifier(base_score=0.5, booster='gbtree', callbacks=None,
colsample_bylevel=1, colsample_bynode=1, colsample_bytree=1,
early_stopping_rounds=None, enable_categorical=False,
eval_metric='auc', gamma=0, gpu_id=-1, grow_policy='depthwise',
importance_type=None, interaction_constraints='',
learning_rate=0.300000012, max_bin=256, max_cat_to_onehot=4,
max_delta_step=0, max_depth=6, max_leaves=0, min_child_weight=1,
missing=nan, monotone_constraints='()', n_estimators=100,
n_jobs=-1, num_parallel_tree=1, predictor='auto', random_state=42,
reg_alpha=0, reg_lambda=1, ...)
'''-
미국 진단기준 confusion matrix (cv=5)
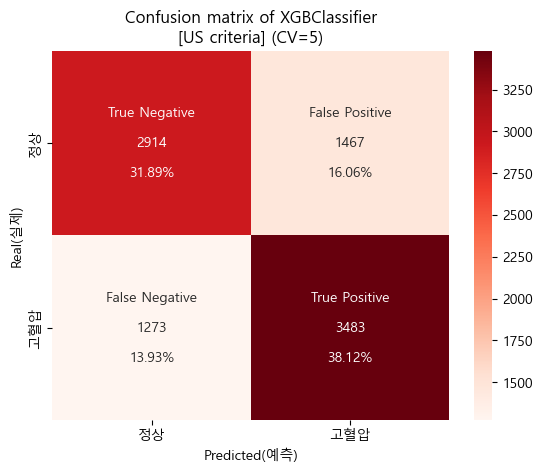
-
미국 진단기준 ROC_AUC curve (cv=5)
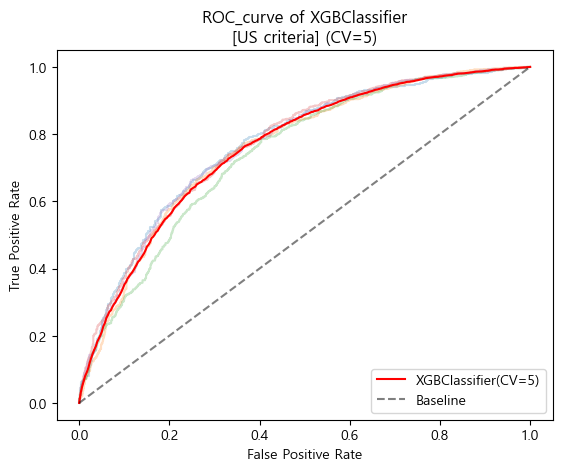
-
미국 진단기준 검증 Score
'''
[US criteria]
Baseline accuracy(US): 0.5205209587391922
XGBClassifier accuracy(US): 0.7001201285363362
''''''
[US criteria]
Baseline AUC_score(US): 0.5
XGBClassifier AUC_score(US) : 0.7607539893215014
'''유럽 진단기준 (140mmHg/90mmHg)
- 유럽 진단기준 모델 & fit
xgb_eu = XGBClassifier(objective='binary:logistic',
eval_metric='auc',
random_state=42,n_jobs=-1)
xgb_eu.fit(X_train,y_train_eu)
#output
'''
XGBClassifier(base_score=0.5, booster='gbtree', callbacks=None,
colsample_bylevel=1, colsample_bynode=1, colsample_bytree=1,
early_stopping_rounds=None, enable_categorical=False,
eval_metric='auc', gamma=0, gpu_id=-1, grow_policy='depthwise',
importance_type=None, interaction_constraints='',
learning_rate=0.300000012, max_bin=256, max_cat_to_onehot=4,
max_delta_step=0, max_depth=6, max_leaves=0, min_child_weight=1,
missing=nan, monotone_constraints='()', n_estimators=100,
n_jobs=-1, num_parallel_tree=1, predictor='auto', random_state=42,
reg_alpha=0, reg_lambda=1, ...)
'''-
유럽 진단기준 confusion matrix (cv=5)
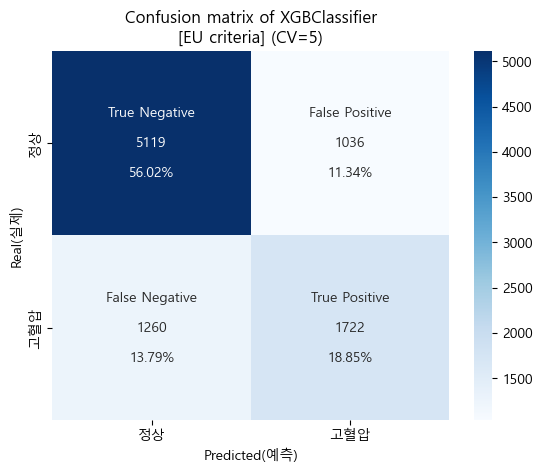
-
유럽 진단기준 ROC_AUC curve (cv=5)
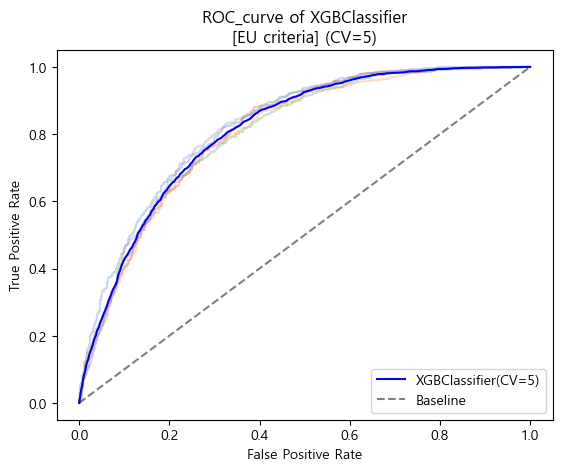
-
유럽 진단기준 검증 Score
'''
[EU criteria]
Baseline accuracy(EU): 0.6736346722118858
XGBClassifier accuracy(EU): 0.7487126005612386
''''''
[EU criteria]
Baseline AUC_score(EU): 0.5
XGBClassifier AUC_score(EU) : 0.8083638731971957
'''US vs EU 비교
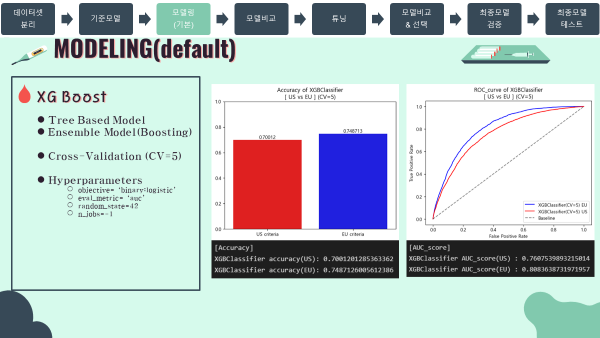
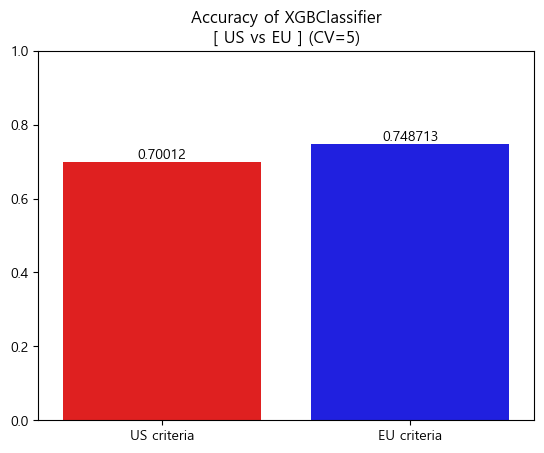
-
Accuracy barplot (matplotlib)
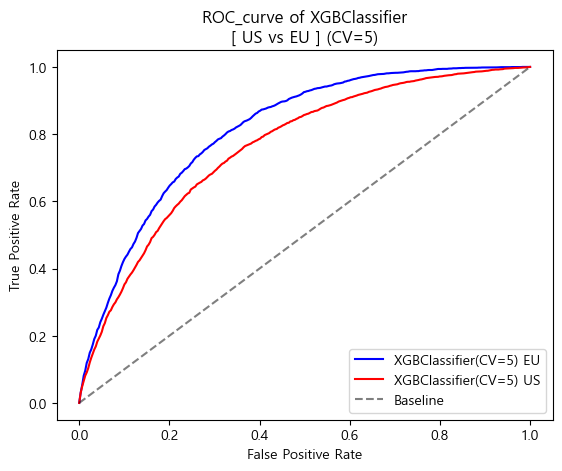
-
ROC curve (matplotlib)
-
Accuracy & AUC Score
'''
[Accuracy]
XGBClassifier accuracy(US): 0.7001201285363362
XGBClassifier accuracy(EU): 0.7487126005612386
[AUC_score]
XGBClassifier AUC_score(US) : 0.7607539893215014
XGBClassifier AUC_score(EU) : 0.8083638731971957
'''모델 비교 (default)
- 현재까지 진행한 모델들을 한곳에 모아 검증점수를 비교하였음.
- Decision Tree만 유독 낮은 검증 스코어를 보임
- 따라서 Decision Tree를 제외한 나머지 모델들로 튜닝을 진행하기로 결정하였음.
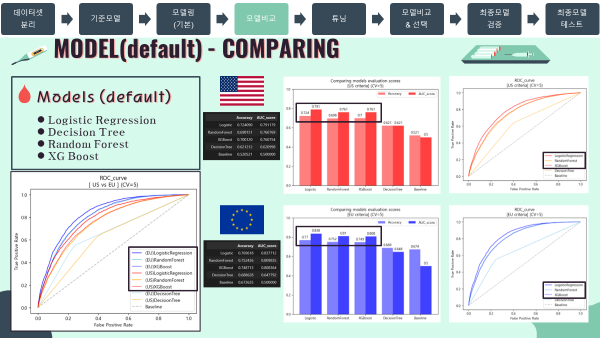
미국 진단기준 (130mmHg/80mmHg)
- 검증 스코어 DataFrame
df_score_us = pd.DataFrame({'Accuracy':[accuracy_score(y_train_us, baseline_us),
CV_score_accuracy_logis_us.mean(),
CV_score_accuracy_dtc_us.mean(),
CV_score_accuracy_rfc_us.mean(),
CV_score_accuracy_xgb_us.mean()],
'AUC_score':[roc_auc_score(y_train_us, baseline_us),
CV_score_auc_logis_us.mean(),
CV_score_auc_dtc_us.mean(),
CV_score_auc_rfc_us.mean(),
CV_score_auc_xgb_us.mean()]},
index = ['Baseline','Logistic','DecisionTree','RandomForest','XGBoost']).sort_values(by='AUC_score',ascending=False)
df_score_us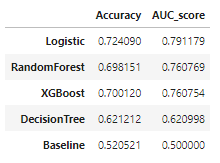
- 검증 스코어 barplot
x = np.arange(5)
width = 0.4
fig, ax = plt.subplots()
rect1 = ax.bar(x-width/2, df_score_us.Accuracy.round(3), width, label='Accuracy',color='red',alpha=0.5)
rect2 = ax.bar(x+width/2, df_score_us.AUC_score.round(3), width, label='AUC_score',color='red',alpha=0.75)
ax.set_title('Comparing models evaluation scores\n[US criteria] (CV=5)')
ax.set_xticks(x, df_score_us.index)
ax.bar_label(rect1, padding=3)
ax.bar_label(rect2, padding=3)
fig.tight_layout()
plt.ylim([0,1])
plt.legend(ncol=2)
plt.show()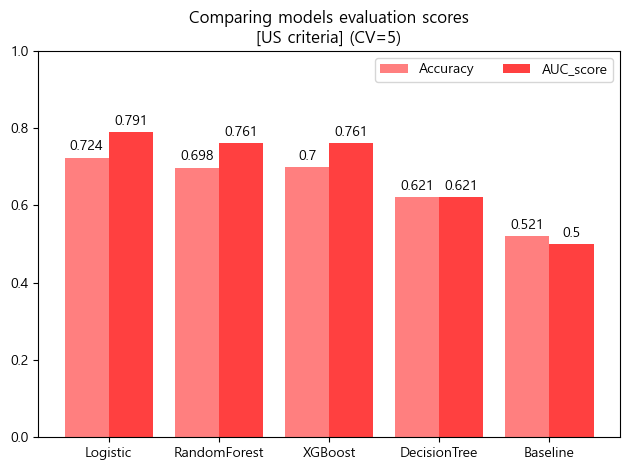
- ROC curve
plt.plot(base_fpr_logis_us,mean_tprs_logis_us,label='LogisticRegression',color='red',alpha=0.75)
plt.plot(base_fpr_rfc_us,mean_tprs_rfc_us,label='RandomForest',color='orange',alpha=0.75)
plt.plot(base_fpr_xgb_us,mean_tprs_xgb_us,label='XGBoost',color='red',alpha=0.5)
plt.plot(base_fpr_dtc_us,mean_tprs_dtc_us,label='DecisionTree',color='orange',alpha=0.5)
plt.plot([0,1],[0,1],label='Baseline',color='gray',linestyle='--',alpha=0.5)
plt.title('ROC_curve\n[US criteria] (CV=5)')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.legend(loc='lower right')
plt.show()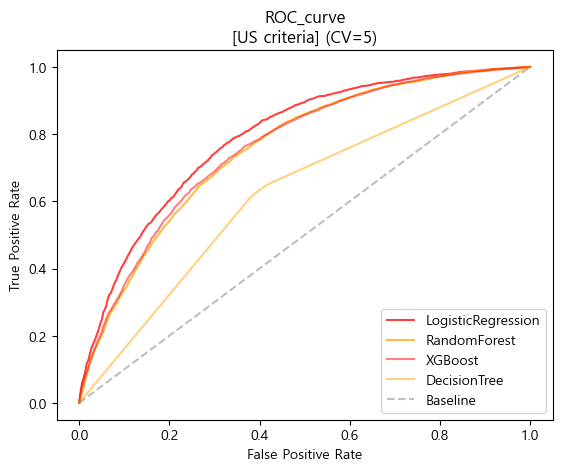
유럽 진단기준 (140mmHg/90mmHg)
- 검증 스코어 DataFrame
df_score_eu = pd.DataFrame({'Accuracy':[accuracy_score(y_train_eu, baseline_eu),
CV_score_accuracy_logis_eu.mean(),
CV_score_accuracy_dtc_eu.mean(),
CV_score_accuracy_rfc_eu.mean(),
CV_score_accuracy_xgb_eu.mean()],
'AUC_score':[roc_auc_score(y_train_eu, baseline_eu),
CV_score_auc_logis_eu.mean(),
CV_score_auc_dtc_eu.mean(),
CV_score_auc_rfc_eu.mean(),
CV_score_auc_xgb_eu.mean()]},
index = ['Baseline','Logistic','DecisionTree','RandomForest','XGBoost']).sort_values(by='AUC_score',ascending=False)
df_score_eu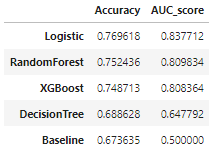
- 검증 스코어 barplot
x = np.arange(5)
width = 0.4
fig, ax = plt.subplots()
rect1 = ax.bar(x-width/2, df_score_eu.Accuracy.round(3), width, label='Accuracy',color='blue',alpha=0.5)
rect2 = ax.bar(x+width/2, df_score_eu.AUC_score.round(3), width, label='AUC_score',color='blue',alpha=0.75)
ax.set_title('Comparing models evaluation scores\n[EU criteria] (CV=5)')
ax.set_xticks(x, df_score_eu.index)
ax.bar_label(rect1, padding=3)
ax.bar_label(rect2, padding=3)
fig.tight_layout()
plt.ylim([0,1])
plt.legend(ncol=2)
plt.show()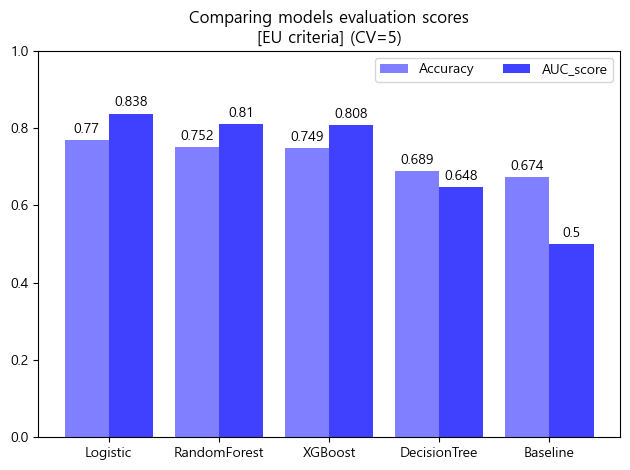
- ROC curve
plt.plot(base_fpr_logis_eu,mean_tprs_logis_eu,label='LogisticRegression',color='blue',alpha=0.75)
plt.plot(base_fpr_rfc_eu,mean_tprs_rfc_eu,label='RandomForest',color='skyblue',alpha=1)
plt.plot(base_fpr_xgb_eu,mean_tprs_xgb_eu,label='XGBoost',color='blue',alpha=0.5)
plt.plot(base_fpr_dtc_eu,mean_tprs_dtc_eu,label='DecisionTree',color='skyblue',alpha=0.75)
plt.plot([0,1],[0,1],label='Baseline',color='gray',linestyle='--',alpha=0.5)
plt.title('ROC_curve\n[EU criteria] (CV=5)')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.legend(loc='lower right')
plt.show()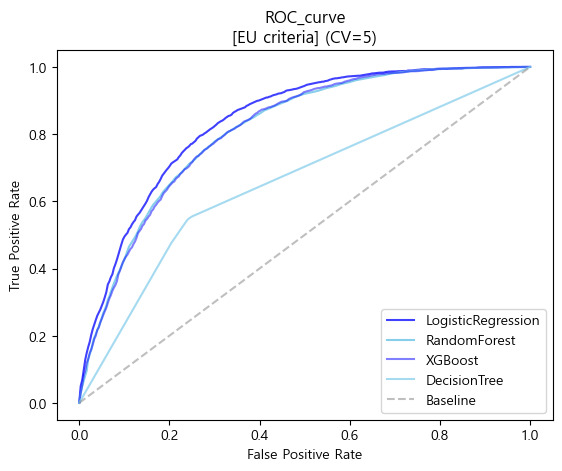
US & EU
- ROC curve
plt.plot(base_fpr_logis_eu,mean_tprs_logis_eu,label='(EU)LogisticRegression',color='blue',alpha=0.75)
plt.plot(base_fpr_rfc_eu,mean_tprs_rfc_eu,label='(EU)RandomForest',color='skyblue',alpha=1)
plt.plot(base_fpr_xgb_eu,mean_tprs_xgb_eu,label='(EU)XGBoost',color='blue',alpha=0.5)
plt.plot(base_fpr_logis_us,mean_tprs_logis_us,label='(US)LogisticRegression',color='red',alpha=0.75)
plt.plot(base_fpr_rfc_us,mean_tprs_rfc_us,label='(US)RandomForest',color='orange',alpha=0.75)
plt.plot(base_fpr_xgb_us,mean_tprs_xgb_us,label='(US)XGBoost',color='red',alpha=0.5)
plt.plot(base_fpr_dtc_eu,mean_tprs_dtc_eu,label='(EU)DecisionTree',color='skyblue',alpha=0.5)
plt.plot(base_fpr_dtc_us,mean_tprs_dtc_us,label='(US)DecisionTree',color='orange',alpha=0.5)
plt.plot([0,1],[0,1],label='Baseline',color='gray',linestyle='--',alpha=0.5)
plt.title('ROC_curve\n[ US vs EU ] (CV=5)')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.legend(loc='lower right')
plt.show()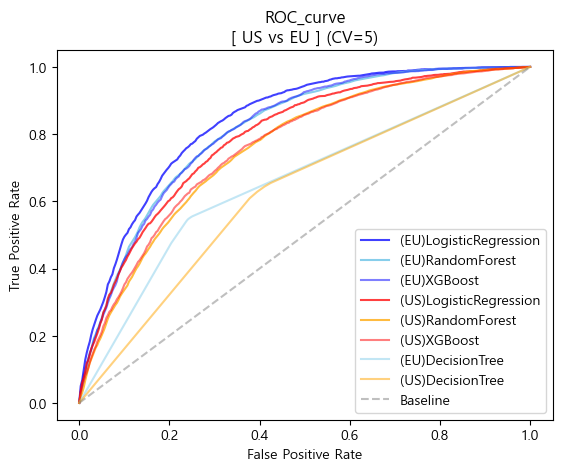
3-4. Hyperparameter Tuning 모델 튜닝
- Hyperparameter Tuning은 모두 sklearn의 GridSearchCV 모듈을 통해서 진행하였음.
Logistic Regression
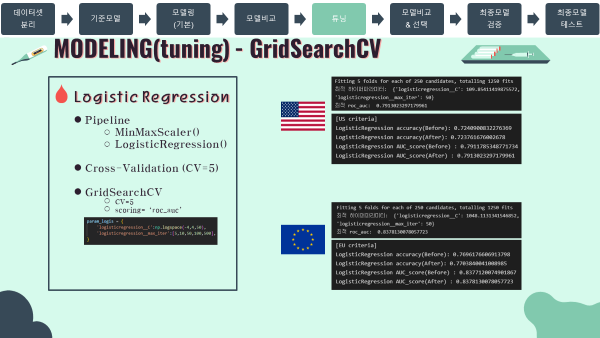
- 탐색 파라미터 목록
param_logis = {
'logisticregression__C':np.logspace(-4,4,50),
'logisticregression__max_iter':[5,10,50,100,500],
}- 최적 파라미터 및 최적 AUC score
gs_logis_us = GridSearchCV(estimator=pipe_logis_us,
param_grid=param_logis,
scoring='roc_auc',
cv=5,
verbose=1,
n_jobs=-1)
gs_logis_us.fit(X_train_log,y_train_us)
print("최적 하이퍼파라미터: ", gs_logis_us.best_params_)
print("최적 roc_auc: ", gs_logis_us.best_score_)
#output
'''
Fitting 5 folds for each of 250 candidates, totalling 1250 fits
최적 하이퍼파라미터: {'logisticregression__C': 109.85411419875572, 'logisticregression__max_iter': 50}
최적 roc_auc: 0.7913023297179961
'''gs_logis_eu = GridSearchCV(estimator=pipe_logis_eu,
param_grid=param_logis,
scoring='roc_auc',
cv=5,
verbose=1,
n_jobs=-1)
gs_logis_eu.fit(X_train_log,y_train_eu)
print("최적 하이퍼파라미터: ", gs_logis_eu.best_params_)
print("최적 roc_auc: ", gs_logis_eu.best_score_)
#output
'''
Fitting 5 folds for each of 250 candidates, totalling 1250 fits
최적 하이퍼파라미터: {'logisticregression__C': 1048.1131341546852, 'logisticregression__max_iter': 50}
최적 roc_auc: 0.8378130078057723
'''- 튜닝 후 모델링
pipe_logis_us_tun = make_pipeline(
MinMaxScaler(),
LogisticRegression(C=109.85411419875572,
max_iter=50)
)
pipe_logis_us_tun.fit(X_train_log,y_train_us)
#output
'''
Pipeline(steps=[('minmaxscaler', MinMaxScaler()),
('logisticregression',
LogisticRegression(C=109.85411419875572, max_iter=50))])
'''pipe_logis_eu_tun = make_pipeline(
MinMaxScaler(),
LogisticRegression(C=1048.1131341546852,
max_iter=50)
)
pipe_logis_eu_tun.fit(X_train_log,y_train_eu)
#output
'''
Pipeline(steps=[('minmaxscaler', MinMaxScaler()),
('logisticregression',
LogisticRegression(C=1048.1131341546852, max_iter=50))])
'''- 튜닝 전후 검증 스코어
CV_score_accuracy_logis_us_tun = cross_val_score(pipe_logis_us_tun,X_train_log,y_train_us,cv=5,n_jobs=-1,scoring='accuracy')
CV_score_auc_logis_us_tun = cross_val_score(pipe_logis_us_tun,X_train_log,y_train_us,cv=5,n_jobs=-1,scoring='roc_auc')
print('[US criteria]')
print('LogisticRegression accuracy(Before): {}'.format(CV_score_accuracy_logis_us.mean()))
print('LogisticRegression accuracy(After): {}'.format(CV_score_accuracy_logis_us_tun.mean()))
print('LogisticRegression AUC_score(Before) : {}'.format(CV_score_auc_logis_us.mean()))
print('LogisticRegression AUC_score(After) : {}'.format(CV_score_auc_logis_us_tun.mean()))
#output
'''
[US criteria]
LogisticRegression accuracy(Before): 0.7240900832276369
LogisticRegression accuracy(After): 0.723761676002678
LogisticRegression AUC_score(Before) : 0.7911785348771734
LogisticRegression AUC_score(After) : 0.7913023297179961
'''CV_score_accuracy_logis_eu_tun = cross_val_score(pipe_logis_eu_tun,X_train_log,y_train_eu,cv=5,n_jobs=-1,scoring='accuracy')
CV_score_auc_logis_eu_tun = cross_val_score(pipe_logis_eu_tun,X_train_log,y_train_eu,cv=5,n_jobs=-1,scoring='roc_auc')
print('[EU criteria]')
print('LogisticRegression accuracy(Before): {}'.format(CV_score_accuracy_logis_eu.mean()))
print('LogisticRegression accuracy(After): {}'.format(CV_score_accuracy_logis_eu_tun.mean()))
print('LogisticRegression AUC_score(Before) : {}'.format(CV_score_auc_logis_eu.mean()))
print('LogisticRegression AUC_score(After) : {}'.format(CV_score_auc_logis_eu_tun.mean()))
#output
'''
[EU criteria]
LogisticRegression accuracy(Before): 0.7696176606913798
LogisticRegression accuracy(After): 0.7703840041008985
LogisticRegression AUC_score(Before) : 0.8377120074901867
LogisticRegression AUC_score(After) : 0.8378130078057723
'''Random Forest
- 소드코드는 대부분 위에서 실시한 로지스틱회귀와 비슷하므로 출력값 위주로 작성하겠음.
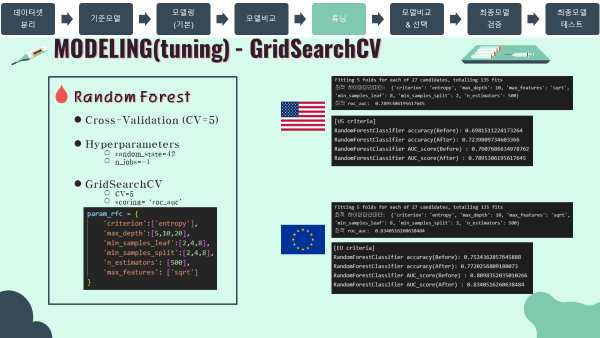
- 탐색 파라미터 목록
param_rfc = {
'criterion':['entropy'],
'max_depth':[5,10,20],
'min_samples_leaf':[2,4,8],
'min_samples_split':[2,4,8],
'n_estimators': [500],
'max_features': ['sqrt']
}- 최적 파라미터 및 최적 AUC score
#US
'''
Fitting 5 folds for each of 27 candidates, totalling 135 fits
최적 하이퍼파라미터: {'criterion': 'entropy', 'max_depth': 10, 'max_features': 'sqrt', 'min_samples_leaf': 8, 'min_samples_split': 2, 'n_estimators': 500}
최적 roc_auc: 0.7895306195617645
'''#EU
'''
Fitting 5 folds for each of 27 candidates, totalling 135 fits
최적 하이퍼파라미터: {'criterion': 'entropy', 'max_depth': 10, 'max_features': 'sqrt', 'min_samples_leaf': 8, 'min_samples_split': 2, 'n_estimators': 500}
최적 roc_auc: 0.8340516260638484
'''- 튜닝 후 모델링
rfc_us_tun = RandomForestClassifier(
n_jobs=-1,
random_state=42,
criterion='entropy',
max_depth=10,
max_features='sqrt',
min_samples_leaf=8,
min_samples_split=2,
n_estimators=500,
)
rfc_us_tun.fit(X_train,y_train_us)
#output
'''
RandomForestClassifier(criterion='entropy', max_depth=10, max_features='sqrt',
min_samples_leaf=8, n_estimators=500, n_jobs=-1,
random_state=42)
'''rfc_eu_tun = RandomForestClassifier(
n_jobs=-1,
random_state=42,
criterion='entropy',
max_depth=10,
max_features='sqrt',
min_samples_leaf=8,
min_samples_split=2,
n_estimators=500,
)
rfc_eu_tun.fit(X_train,y_train_eu)
#output
'''
RandomForestClassifier(criterion='entropy', max_depth=10, max_features='sqrt',
min_samples_leaf=8, n_estimators=500, n_jobs=-1,
random_state=42)
'''- 튜닝 전후 검증 스코어
#output
'''
[US criteria]
RandomForestClassifier accuracy(Before): 0.6981511224173264
RandomForestClassifier accuracy(After): 0.7239809734603366
RandomForestClassifier AUC_score(Before) : 0.7607686634978762
RandomForestClassifier AUC_score(After) : 0.7895306195617645
'''#output
'''
[EU criteria]
RandomForestClassifier accuracy(Before): 0.7524362857645888
RandomForestClassifier accuracy(After): 0.7720256809180073
RandomForestClassifier AUC_score(Before) : 0.8098342494013966
RandomForestClassifier AUC_score(After) : 0.8340516260638484
'''XGBoost
- 소드코드는 대부분 위에서 실시한 로지스틱회귀와 비슷하므로 출력값 위주로 작성하겠음.
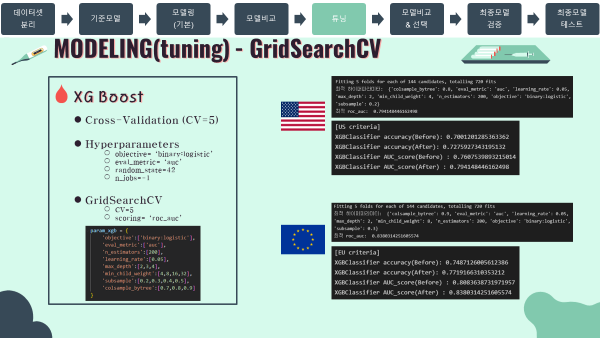
- 탐색 파라미터 목록
param_xgb = {
'objective':['binary:logistic'],
'eval_metric':['auc'],
'n_estimators':[200],
'learning_rate':[0.05],
'max_depth':[2,3,4],
'min_child_weight':[4,8,16,32],
'subsample':[0.2,0.3,0.4,0.5],
'colsample_bytree':[0.7,0.8,0.9]
}- 최적 파라미터 및 최적 AUC score
#US
'''
Fitting 5 folds for each of 144 candidates, totalling 720 fits
최적 하이퍼파라미터: {'colsample_bytree': 0.8, 'eval_metric': 'auc', 'learning_rate': 0.05, 'max_depth': 2, 'min_child_weight': 4, 'n_estimators': 200, 'objective': 'binary:logistic', 'subsample': 0.2}
최적 roc_auc: 0.794148446162498
'''#EU
'''
Fitting 5 folds for each of 144 candidates, totalling 720 fits
최적 하이퍼파라미터: {'colsample_bytree': 0.9, 'eval_metric': 'auc', 'learning_rate': 0.05, 'max_depth': 2, 'min_child_weight': 8, 'n_estimators': 200, 'objective': 'binary:logistic', 'subsample': 0.3}
최적 roc_auc: 0.8380314251605574
'''- 튜닝 후 모델링
xgb_us_tun = XGBClassifier(
n_jobs = -1,
random_state = 42,
objective = 'binary:logistic',
eval_metric = 'auc',
n_estimators = 200,
learning_rate = 0.05,
max_depth = 2,
min_child_weight = 4,
subsample = 0.2,
colsample_bytree = 0.8
)
xgb_us_tun.fit(X_train,y_train_us)
#output
'''
XGBClassifier(base_score=0.5, booster='gbtree', callbacks=None,
colsample_bylevel=1, colsample_bynode=1, colsample_bytree=0.8,
early_stopping_rounds=None, enable_categorical=False,
eval_metric='auc', gamma=0, gpu_id=-1, grow_policy='depthwise',
importance_type=None, interaction_constraints='',
learning_rate=0.05, max_bin=256, max_cat_to_onehot=4,
max_delta_step=0, max_depth=2, max_leaves=0, min_child_weight=4,
missing=nan, monotone_constraints='()', n_estimators=200,
n_jobs=-1, num_parallel_tree=1, predictor='auto', random_state=42,
reg_alpha=0, reg_lambda=1, ...)
'''xgb_eu_tun = XGBClassifier(
n_jobs = -1,
random_state = 42,
objective = 'binary:logistic',
eval_metric = 'auc',
n_estimators = 200,
learning_rate = 0.05,
max_depth = 2,
min_child_weight = 8,
subsample = 0.3,
colsample_bytree = 0.9
)
xgb_eu_tun.fit(X_train,y_train_eu)
#output
'''
XGBClassifier(base_score=0.5, booster='gbtree', callbacks=None,
colsample_bylevel=1, colsample_bynode=1, colsample_bytree=0.9,
early_stopping_rounds=None, enable_categorical=False,
eval_metric='auc', gamma=0, gpu_id=-1, grow_policy='depthwise',
importance_type=None, interaction_constraints='',
learning_rate=0.05, max_bin=256, max_cat_to_onehot=4,
max_delta_step=0, max_depth=2, max_leaves=0, min_child_weight=8,
missing=nan, monotone_constraints='()', n_estimators=200,
n_jobs=-1, num_parallel_tree=1, predictor='auto', random_state=42,
reg_alpha=0, reg_lambda=1, ...)
'''- 튜닝 전후 검증 스코어
#output
'''
[US criteria]
XGBClassifier accuracy(Before): 0.7001201285363362
XGBClassifier accuracy(After): 0.7275927343195132
XGBClassifier AUC_score(Before) : 0.7607539893215014
XGBClassifier AUC_score(After) : 0.794148446162498
'''#output
'''
[EU criteria]
XGBClassifier accuracy(Before): 0.7487126005612386
XGBClassifier accuracy(After): 0.7719166310353212
XGBClassifier AUC_score(Before) : 0.8083638731971957
XGBClassifier AUC_score(After) : 0.8380314251605574
'''모델 비교 (튜닝)
- 튜닝을 진행한 세가지 모델을 비교 해본 결과, AUC score 기준으로 XGBoost 성능이 가장 좋게 나타났으므로, 최종모델은 튜닝을 거친
XGBoost모델로 선정
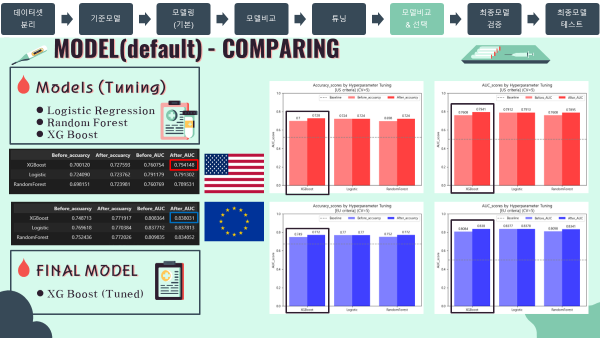
미국 진단기준 (130mmHg/80mmHg)
- 검증 스코어 DataFrame
df_score_us_tun = pd.DataFrame({'Before_accuarcy':[CV_score_accuracy_logis_us.mean(),
CV_score_accuracy_rfc_us.mean(),
CV_score_accuracy_xgb_us.mean()],
'After_accuarcy':[CV_score_accuracy_logis_us_tun.mean(),
CV_score_accuracy_rfc_us_tun.mean(),
CV_score_accuracy_xgb_us_tun.mean()],
'Before_AUC':[CV_score_auc_logis_us.mean(),
CV_score_auc_rfc_us.mean(),
CV_score_auc_xgb_us.mean()],
'After_AUC':[CV_score_auc_logis_us_tun.mean(),
CV_score_auc_rfc_us_tun.mean(),
CV_score_auc_xgb_us_tun.mean()]},
index = ['Logistic','RandomForest','XGBoost']).sort_values(by='After_AUC',ascending=False)
df_score_us_tun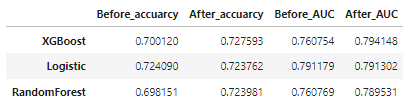
- Accuracy barplot (matplotlib)
x = np.arange(3)
width = 0.4
fig, ax = plt.subplots()
rect1 = ax.bar(x-width/2, df_score_us_tun.Before_accuarcy.round(3), width, label='Before_accuarcy',color='red',alpha=0.5)
rect2 = ax.bar(x+width/2, df_score_us_tun.After_accuarcy.round(3), width, label='After_accuarcy',color='red',alpha=0.75)
ax.set_title('Accuracy_scores by Hyperparameter Tuning\n[US criteria] (CV=5)')
ax.set_xticks(x, df_score_us_tun.index)
ax.bar_label(rect1, padding=3)
ax.bar_label(rect2, padding=3)
fig.tight_layout()
plt.axhline(accuracy_score(y_train_us, baseline_us),color='gray',linestyle='--',label='Baseline')
plt.ylabel('AUC_score')
plt.ylim([0,1])
plt.legend(ncol=3)
plt.show()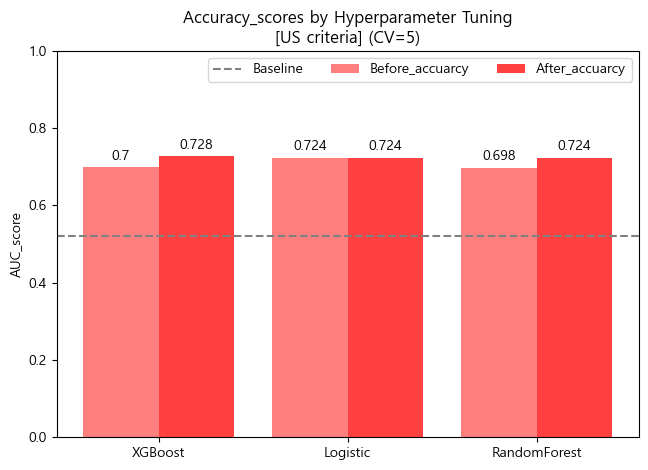
- ROC_AUC barplot (matplotlib)
x = np.arange(3)
width = 0.4
fig, ax = plt.subplots()
rect1 = ax.bar(x-width/2, df_score_us_tun.Before_AUC.round(4), width, label='Before_AUC',color='red',alpha=0.5)
rect2 = ax.bar(x+width/2, df_score_us_tun.After_AUC.round(4), width, label='After_AUC',color='red',alpha=0.75)
ax.set_title('AUC_scores by Hyperparameter Tuning\n[US criteria] (CV=5)')
ax.set_xticks(x, df_score_us_tun.index)
ax.bar_label(rect1, padding=3)
ax.bar_label(rect2, padding=3)
fig.tight_layout()
plt.axhline(.5,color='gray',linestyle='--',label='Baseline')
plt.ylabel('AUC_score')
plt.ylim([0,1])
plt.legend(ncol=3)
plt.show()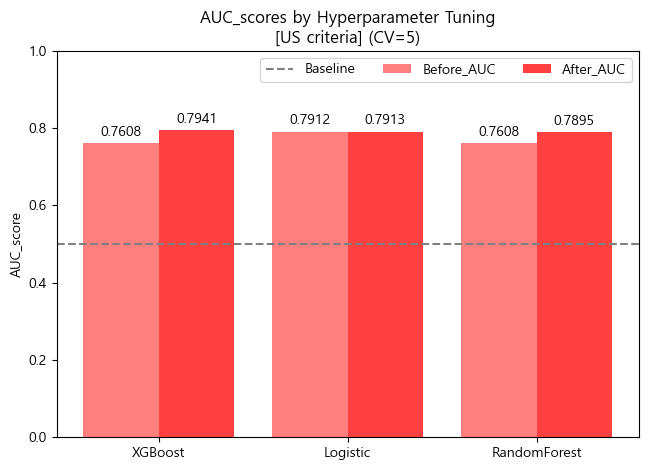
유럽 진단기준 (140mmHg/90mmHg)
- 검증 스코어 DataFrame
df_score_eu_tun = pd.DataFrame({'Before_accuarcy':[CV_score_accuracy_logis_eu.mean(),
CV_score_accuracy_rfc_eu.mean(),
CV_score_accuracy_xgb_eu.mean()],
'After_accuarcy':[CV_score_accuracy_logis_eu_tun.mean(),
CV_score_accuracy_rfc_eu_tun.mean(),
CV_score_accuracy_xgb_eu_tun.mean()],
'Before_AUC':[CV_score_auc_logis_eu.mean(),
CV_score_auc_rfc_eu.mean(),
CV_score_auc_xgb_eu.mean()],
'After_AUC':[CV_score_auc_logis_eu_tun.mean(),
CV_score_auc_rfc_eu_tun.mean(),
CV_score_auc_xgb_eu_tun.mean()]},
index = ['Logistic','RandomForest','XGBoost']).sort_values(by='After_AUC',ascending=False)
df_score_eu_tun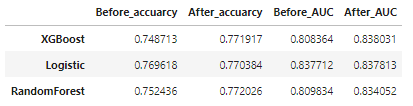
- Accuracy barplot (matplotlib)
x = np.arange(3)
width = 0.4
fig, ax = plt.subplots()
rect1 = ax.bar(x-width/2, df_score_eu_tun.Before_accuarcy.round(3), width, label='Before_accuarcy',color='blue',alpha=0.5)
rect2 = ax.bar(x+width/2, df_score_eu_tun.After_accuarcy.round(3), width, label='After_accuarcy',color='blue',alpha=0.75)
ax.set_title('Accuracy_scores by Hyperparameter Tuning\n[EU criteria] (CV=5)')
ax.set_xticks(x, df_score_eu_tun.index)
ax.bar_label(rect1, padding=3)
ax.bar_label(rect2, padding=3)
fig.tight_layout()
plt.axhline(accuracy_score(y_train_eu, baseline_eu),color='gray',linestyle='--',label='Baseline')
plt.ylabel('AUC_score')
plt.ylim([0,1])
plt.legend(ncol=3)
plt.show()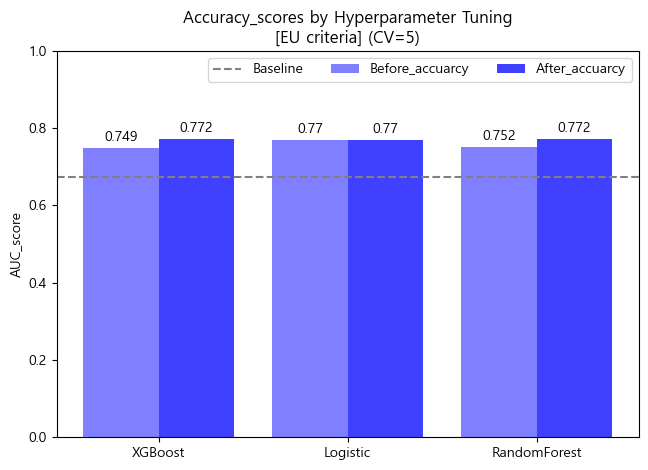
- ROC_AUC barplot (matplotlib)
x = np.arange(3)
width = 0.4
fig, ax = plt.subplots()
rect1 = ax.bar(x-width/2, df_score_eu_tun.Before_AUC.round(4), width, label='Before_AUC',color='blue',alpha=0.5)
rect2 = ax.bar(x+width/2, df_score_eu_tun.After_AUC.round(4), width, label='After_AUC',color='blue',alpha=0.75)
ax.set_title('AUC_scores by Hyperparameter Tuning\n[EU criteria] (CV=5)')
ax.set_xticks(x, df_score_eu_tun.index)
ax.bar_label(rect1, padding=3)
ax.bar_label(rect2, padding=3)
fig.tight_layout()
plt.axhline(.5,color='gray',linestyle='--',label='Baseline')
plt.ylabel('AUC_score')
plt.ylim([0,1])
plt.legend(ncol=3)
plt.show()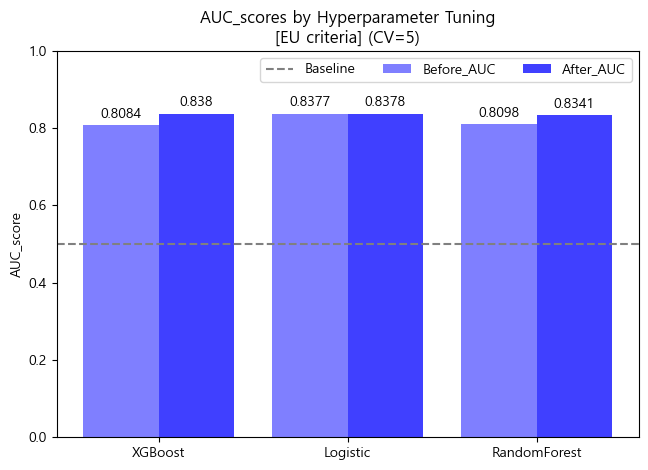
3-5. Final Model & Test 최종모델 및 테스트
최종모델 훈련 및 검증
- 최종 모델에 대한 테스트에 앞서 검증을 실시하였음.
- 위에서 실시했던 default model 과정과 소스코드가 거의 동일하기 때문에 output위주로 작성하겠음.
미국 진단기준 (130mmHg/80mmHg)
- 최종모델 fit
xgb_us_tun.fit(X_train,y_train_us)
#output
'''
XGBClassifier(base_score=0.5, booster='gbtree', callbacks=None,
colsample_bylevel=1, colsample_bynode=1, colsample_bytree=0.8,
early_stopping_rounds=None, enable_categorical=False,
eval_metric='auc', gamma=0, gpu_id=-1, grow_policy='depthwise',
importance_type=None, interaction_constraints='',
learning_rate=0.05, max_bin=256, max_cat_to_onehot=4,
max_delta_step=0, max_depth=2, max_leaves=0, min_child_weight=4,
missing=nan, monotone_constraints='()', n_estimators=200,
n_jobs=-1, num_parallel_tree=1, predictor='auto', random_state=42,
reg_alpha=0, reg_lambda=1, ...)
'''-
confusion matrix (sklearn matplotlib seaborn)
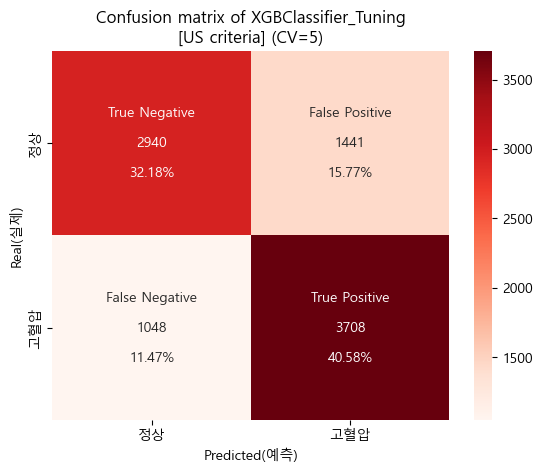
-
ROC curve (matplotlib)
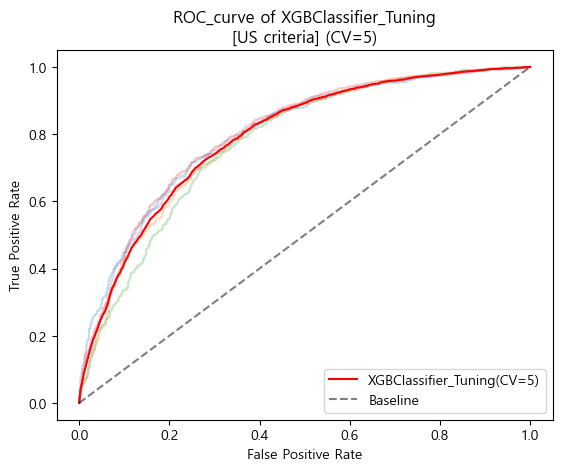
-
검증 스코어
'''
[US criteria]
Baseline accuracy(US): 0.5205209587391922
XGBClassifier_Tuning accuracy(US): 0.7275927343195132
[US criteria]
Baseline AUC_score(US): 0.5
XGBClassifier_Tuning AUC_score(US) : 0.794148446162498
'''유럽 진단기준 (140mmHg/90mmHg)
- 최종모델 fit
xgb_eu_tun.fit(X_train,y_train_eu)
#output
'''
XGBClassifier(base_score=0.5, booster='gbtree', callbacks=None,
colsample_bylevel=1, colsample_bynode=1, colsample_bytree=0.9,
early_stopping_rounds=None, enable_categorical=False,
eval_metric='auc', gamma=0, gpu_id=-1, grow_policy='depthwise',
importance_type=None, interaction_constraints='',
learning_rate=0.05, max_bin=256, max_cat_to_onehot=4,
max_delta_step=0, max_depth=2, max_leaves=0, min_child_weight=8,
missing=nan, monotone_constraints='()', n_estimators=200,
n_jobs=-1, num_parallel_tree=1, predictor='auto', random_state=42,
reg_alpha=0, reg_lambda=1, ...)
'''-
confusion matrix (sklearn matplotlib seaborn)
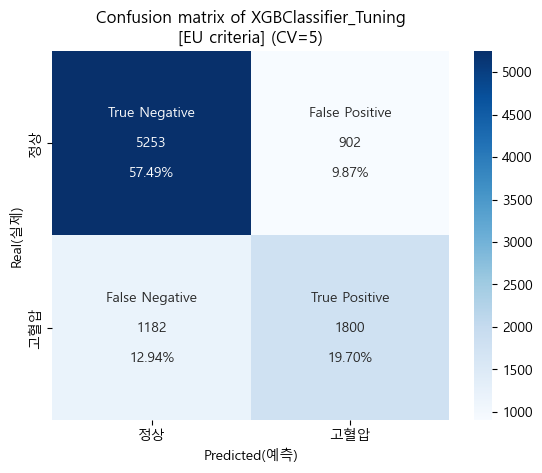
-
ROC curve (matplotlib)
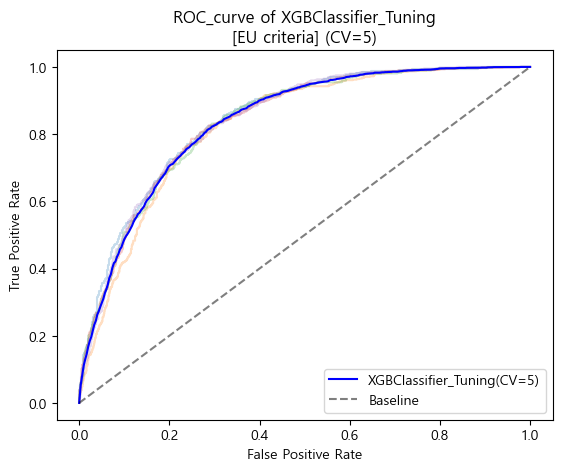
-
검증 스코어
'''
[EU criteria]
Baseline accuracy(EU): 0.6736346722118858
XGBClassifier_Tuning accuracy(EU): 0.7719166310353212
[EU criteria]
Baseline AUC_score(EU): 0.5
XGBClassifier_Tuning AUC_score(EU) : 0.8380314251605574
'''미국 vs 유럽
- 최종모델에서도 유럽진단기준이 미국 진단기준보다 높은 성능을 나타냄
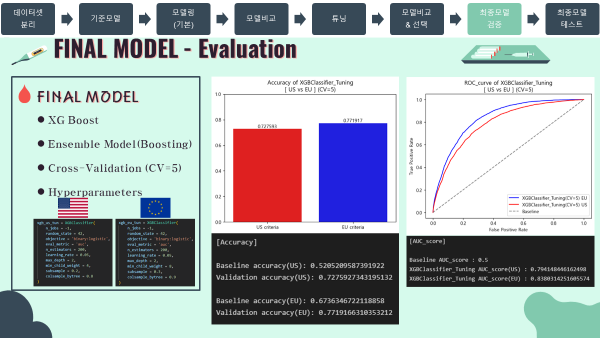
-
Accuracy Barplot (matplotlib seaborn)
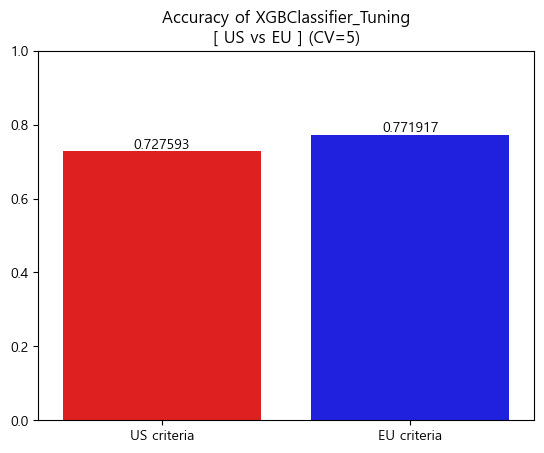
-
ROC curve (matplotlib)
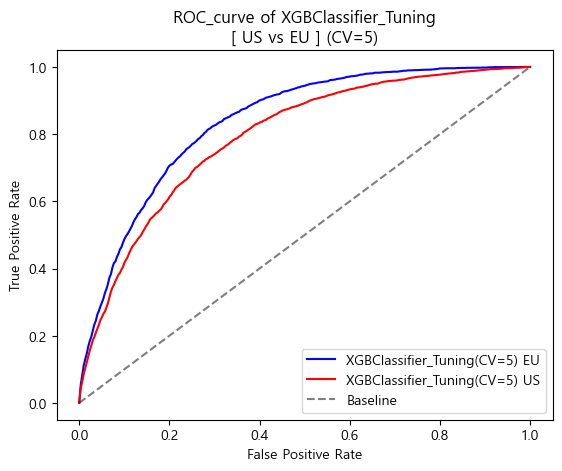
-
검증 스코어
print('[Accuracy]\n')
print("Baseline accuracy(US): {}".format(accuracy_score(y_train_us, baseline_us)))
print('Validation accuracy(US): {}\n'.format(CV_score_accuracy_final_us.mean()))
print("Baseline accuracy(EU): {}".format(accuracy_score(y_train_eu, baseline_eu)))
print('Validation accuracy(EU): {}\n'.format(CV_score_accuracy_final_eu.mean()))
print('[AUC_score]\n')
print('Baseline AUC_score : 0.5')
print('XGBClassifier_Tuning AUC_score(US) : {}'.format(CV_score_auc_final_us.mean()))
print('XGBClassifier_Tuning AUC_score(EU) : {}'.format(CV_score_auc_final_eu.mean()))
#output
'''
[Accuracy]
Baseline accuracy(US): 0.5205209587391922
Validation accuracy(US): 0.7275927343195132
Baseline accuracy(EU): 0.6736346722118858
Validation accuracy(EU): 0.7719166310353212
[AUC_score]
Baseline AUC_score : 0.5
XGBClassifier_Tuning AUC_score(US) : 0.794148446162498
XGBClassifier_Tuning AUC_score(EU) : 0.8380314251605574
'''최종모델 테스트 (일반화가능성확인)
미국 진단기준 (130mmHg/80mmHg)
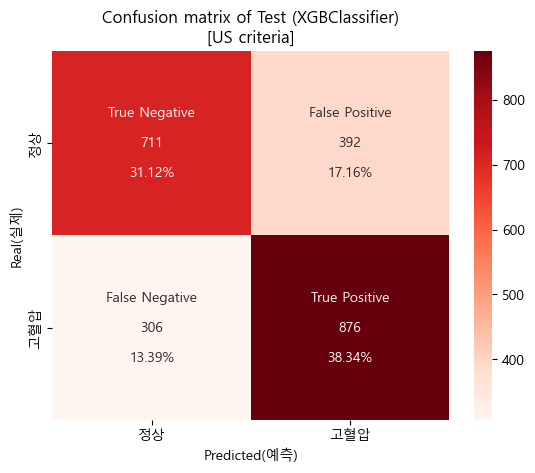
- 테스트 결과
y_pred_test_us = xgb_us_tun.predict(X_test)
df_test_us = pd.DataFrame(data={'y_real_us':y_test_us,
'y_pred_us':y_pred_test_us})
table_test_us = pd.crosstab(df_test_us['y_real_us'],df_test_us['y_pred_us'])
display(table_test_us)
-
Confusion matrix (sklearn matplotlib seaborn)
-
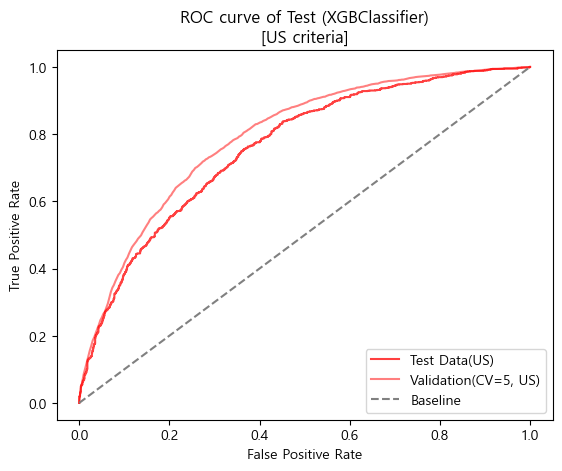
ROC curve (matplotlib)
-
테스트 스코어
'''
[US criteria]
Baseline accuracy(US): 0.5205209587391922
Validation accuracy(US, CV=5): 0.7275927343195132
Test accuracy(US): 0.6945295404814005
[US criteria]
Baseline AUC_score(US): 0.5
Validation AUC_score(US, CV=5): 0.794148446162498
Test AUC_score(US): 0.7608080868512732
'''유럽 진단기준 (140mmHg/90mmHg)
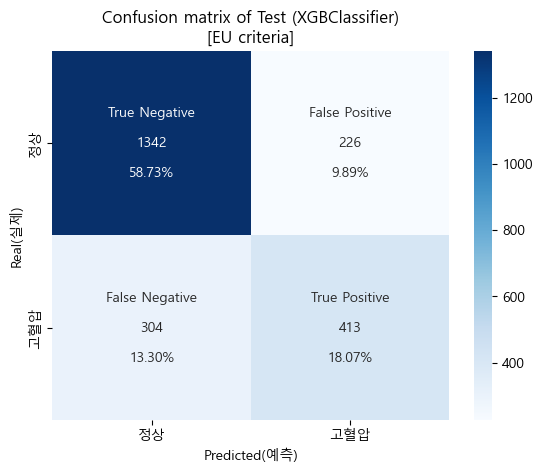
- 테스트 결과
y_pred_test_eu = xgb_eu_tun.predict(X_test)
df_test_eu = pd.DataFrame(data={'y_real_eu':y_test_eu,
'y_pred_eu':y_pred_test_eu})
table_test_eu = pd.crosstab(df_test_eu['y_real_eu'],df_test_eu['y_pred_eu'])
display(table_test_eu)
-
Confusion matrix (sklearn matplotlib seaborn)
-
ROC curve (matplotlib)
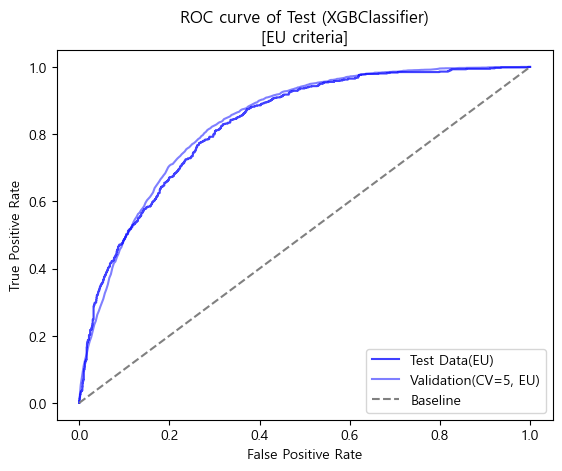
-
테스트 스코어
'''
[EU criteria]
Baseline accuracy(EU): 0.6736346722118858
Validation accuracy(EU, CV=5): 0.7719166310353212
Test accuracy(EU): 0.7680525164113785
[EU criteria]
Baseline AUC_score(EU): 0.5
Validation AUC_score(EU): 0.8380314251605574
Test AUC_score(EU): 0.8300106915150998
'''미국 vs 유럽
- 종합해 보았을때 성능과 일반화 가능성 모두 유럽의 진단기준이 더 좋다고 판단됨.
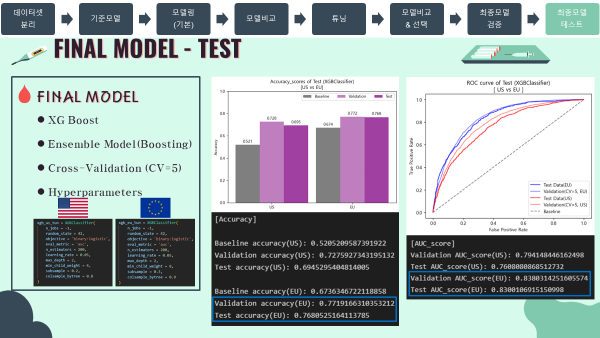
- Accuracy score
print('[Accuracy]')
print('Validation accuracy(US): {}'.format(CV_score_accuracy_final_us.mean()))
print('Test accuracy(US): {}'.format(score_accuracy_test_us))
print('Validation accuracy(EU): {}'.format(CV_score_accuracy_final_eu.mean()))
print('Test accuracy(EU): {}'.format(score_accuracy_test_eu))
'''
[Accuracy]
Validation accuracy(US): 0.7275927343195132
Test accuracy(US): 0.6945295404814005
Validation accuracy(EU): 0.7719166310353212
Test accuracy(EU): 0.7680525164113785
'''- Accuracy barplot (matplotlib)
df_accuracy_test = pd.DataFrame({'Baseline':[accuracy_score(y_train_us, baseline_us),
accuracy_score(y_train_eu, baseline_eu)],
'Validation':[CV_score_accuracy_final_us.mean(),
CV_score_accuracy_final_eu.mean()],
'Test':[score_accuracy_test_us,
score_accuracy_test_eu]},
index=['US','EU'])
x = np.arange(2)
width = 0.3
fig, ax = plt.subplots()
rect1 = ax.bar(x-width, df_accuracy_test.Baseline.round(3), width, label='Baseline',color='black',alpha=0.5)
rect2 = ax.bar(x, df_accuracy_test.Validation.round(3), width, label='Validation',color='purple',alpha=0.5)
rect3 = ax.bar(x+width, df_accuracy_test.Test.round(3), width, label='Test',color='purple',alpha=0.75)
ax.set_title('Accuracy_scores of Test (XGBClassifier)\n[US vs EU]')
ax.set_xticks(x, df_accuracy_test.index)
ax.bar_label(rect1, padding=3)
ax.bar_label(rect2, padding=3)
ax.bar_label(rect3, padding=3)
fig.tight_layout()
plt.ylabel('Accuracy')
plt.ylim([0,1])
plt.legend(ncol=3)
plt.show()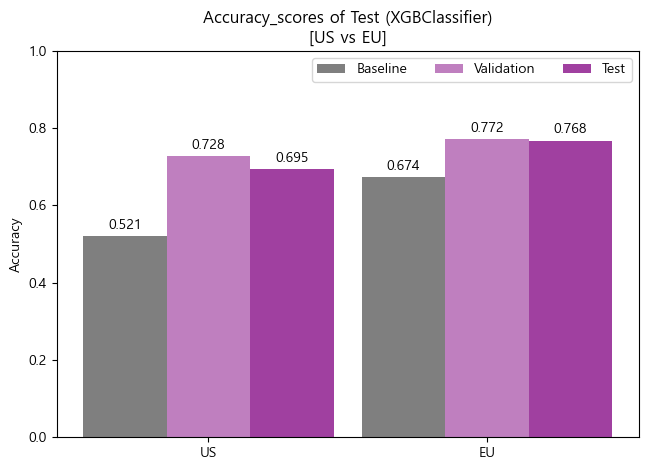
- AUC score
print('[AUC_score]')
print('Validation AUC_score(US): {}'.format(CV_score_auc_final_us.mean()))
print('Test AUC_score(US): {}'.format(score_auc_test_us))
print('Validation AUC_score(EU): {}'.format(CV_score_auc_final_eu.mean()))
print('Test AUC_score(EU): {}'.format(score_auc_test_eu))
'''
[AUC_score]
Validation AUC_score(US): 0.794148446162498
Test AUC_score(US): 0.7608080868512732
Validation AUC_score(EU): 0.8380314251605574
Test AUC_score(EU): 0.8300106915150998
'''- ROC curve (matplotlib)
plt.plot(FPR_test_eu,TPR_test_eu,label='Test Data(EU)',color='blue',alpha=0.75)
plt.plot(base_fpr_final_eu,mean_tprs_final_eu,label='Validation(CV=5, EU)',color='blue',alpha=0.5)
plt.plot(FPR_test_us,TPR_test_us,label='Test Data(US)',color='red',alpha=0.75)
plt.plot(base_fpr_final_us,mean_tprs_final_us,label='Validation(CV=5, US)',color='red',alpha=0.5)
plt.plot([0,1],[0,1], linestyle='--', label='Baseline', color = 'gray')
plt.title('ROC curve of Test (XGBClassifier)\n[ US vs EU ]')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.legend(loc='lower right')
plt.show()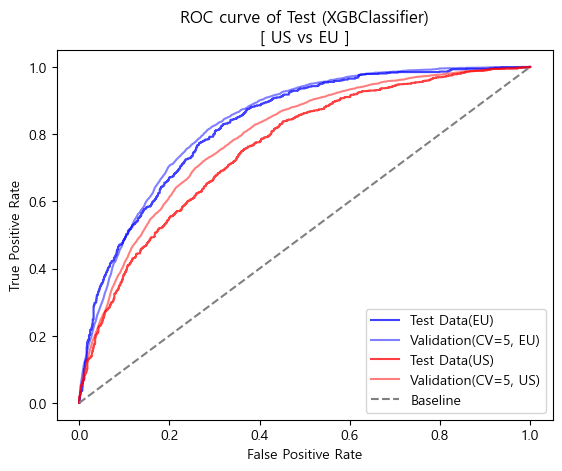
04~. 이후 과정은 다음 포스팅에서!
- 내용이 너무 길어지는 관계로 이후 모델해석과 결론은 다음 포스팅에서 이어서 다루도록 하겠음.
