
본 시리즈는 프로그래밍 자료구조의 개념을 정리하고 실습을 진행해보는 시리즈입니다.
- 실습은 다음과 같은 개발환경 및 버전에서 진행하였습니다.
- IDE : IntelliJ IDEA (Ultimate Edition)
- Java : JDK 21 (corretto-21)
- Python : 3.9 (conda env)
트리(Tree) - Trie
일반적인 Tree에 대한 전반적인 내용들은 다음 포스팅에서 확인하실 수 있습니다.
1. Trie란?
Trie(트라이)는 주로 문자열을 저장하고 검색하는 데 특화된 트리 기반의 자료구조입니다.
- 각 노드는 문자열의 문자 하나를 나타내며, 문자열의 공통 접두사를 공유하는 방식으로 저장하여 효율적인 검색과 삽입을 가능하게 합니다.
- 이 구조는 특히 사전(dictionary) 형태의 데이터를 처리하거나 문자열 검색, 자동 완성 등의 기능에 유리합니다.
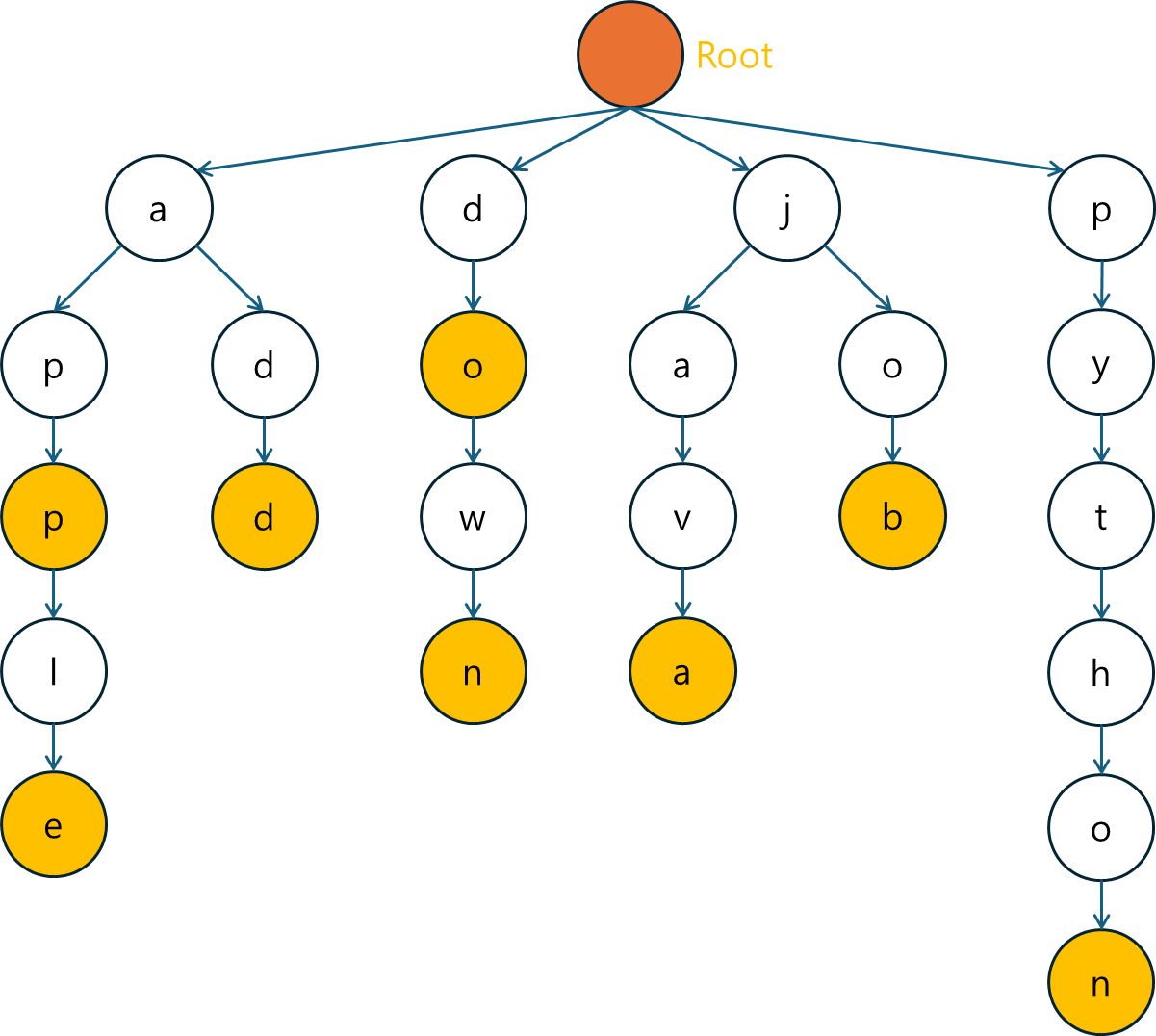
1.1 Trie의 주요 특징
-
노드 구조:
- 각 노드는 문자열의 문자를 저장하며, 경로를 따라가면 문자열을 완성할 수 있습니다.
- 루트 노드는 공백이며, 각 자식 노드는 해당 문자로 이어지는 경로를 나타냅니다.
-
공통 접두사 공유:
- 동일한 접두사를 가지는 문자열들이 트리의 공통 경로를 공유합니다.
- 이는 공간 효율성을 높이는 데 기여합니다.
-
시간 복잡도:
- 문자열의 길이에 따라 검색, 삽입, 삭제가 O(L) 시간 안에 수행됩니다.
- 여기서
L은 문자열의 길이입니다.
-
문자열 단위의 중복 불가:
- 중복된 문자열을 허용하지 않으며, 각 문자열은 고유하게 저장됩니다.
1.2 Trie의 주요 용도
- 문자열 검색:
Trie는 문자열 검색에 매우 효율적이며, 특히 접두사 기반 검색(Prefix Search)에 강점을 가집니다. - 자동 완성: 입력된 접두사를 기반으로 가능한 모든 문자열을 빠르게 찾을 수 있어 자동 완성 기능에 자주 사용됩니다.
- 사전 구축:
Trie는 효율적인 사전(dictionary)을 구축하는 데 유용하며, 대규모의 단어 목록을 처리하는 데 적합합니다.
1.3 Trie의 장점과 단점
장점:
- 접두사 검색이 빠르며, 검색, 삽입, 삭제의 시간 복잡도가 문자열 길이에 비례하므로 매우 효율적입니다.
해시테이블과는 달리 충돌을 걱정할 필요가 없습니다.
단점:
- 많은 노드를 사용하므로 공간 복잡도가 높을 수 있으며, 특히 자식 노드가 많은 경우 메모리 사용량이 커질 수 있습니다.
- 구현이 다소 복잡할 수 있습니다.
2. Trie 구현 - Java
- Java에서는
Trie자료구조만을 위한 별도의 클래스는 없기 때문에, 직접 구현해서 사용하셔야합니다.
구현 및 테스트 코드의 전체 코드는 다음과 같습니다.
import java.util.HashMap;
import java.util.Map;
public class Trie {
// Trie Node 정의
static class TrieNode {
Map<Character, TrieNode> children = new HashMap<>();
boolean isEndOfWord = false; // 해당 노드가 단어의 끝을 나타내는지 여부
}
private final TrieNode root;
// 생성자: Trie 초기화
public Trie() {
root = new TrieNode();
}
// 단어 삽입
public void insert(String word) {
TrieNode node = root;
for (char c : word.toCharArray()) {
node = node.children.computeIfAbsent(c, k -> new TrieNode());
}
node.isEndOfWord = true;
}
// 단어 검색
public boolean search(String word) {
TrieNode node = root;
for (char c : word.toCharArray()) {
node = node.children.get(c);
if (node == null) {
return false; // 해당 경로에 문자가 없으면 단어가 존재하지 않음
}
}
return node.isEndOfWord;
}
// 접두사 검색
public boolean startsWith(String prefix) {
TrieNode node = root;
for (char c : prefix.toCharArray()) {
node = node.children.get(c);
if (node == null) {
return false; // 접두사가 존재하지 않음
}
}
return true;
}
// 테스트용 메인 메소드
public static void main(String[] args) {
Trie trie = new Trie();
// 단어 삽입
trie.insert("apple");
trie.insert("app");
trie.insert("banana");
// 단어 검색
System.out.println(trie.search("apple")); // true
System.out.println(trie.search("app")); // true
System.out.println(trie.search("ban")); // false
// 접두사 검색
System.out.println(trie.startsWith("app")); // true
System.out.println(trie.startsWith("ban")); // true
System.out.println(trie.startsWith("can")); // false
}
}그럼 각 단계별로 나누어서 구현 과정을 자세히 살펴보도록 하겠습니다.
2.1 TrieNode 정의
Trie 자료구조에서 각 노드는 하나의 문자를 나타내며, 자식 노드와 단어의 끝을 표시하는 플래그가 필요합니다. 이를 위해 TrieNode 정적 클래스를 정의합니다.
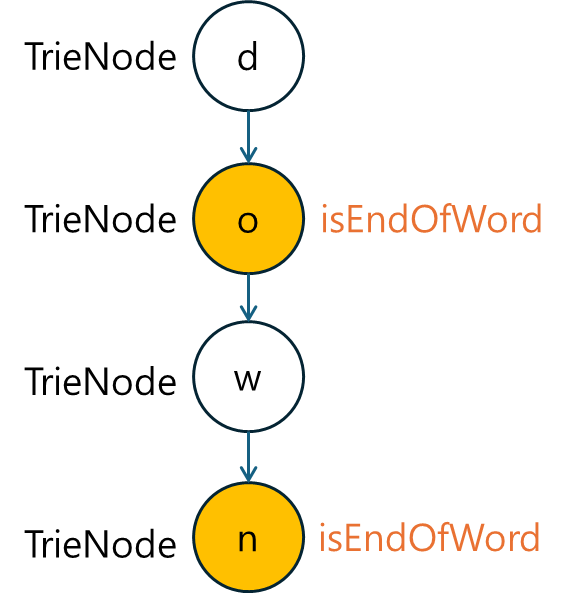
static class TrieNode {
Map<Character, TrieNode> children = new HashMap<>();
boolean isEndOfWord = false; // 단어의 끝을 나타냄
}
children: 각 노드는 자식 노드를 가질 수 있으며, 각 자식은 현재 노드에서 이어지는 문자에 해당합니다.- 보다 편리하게 관리하기 위해
HashMap을 활용합니다.
- 보다 편리하게 관리하기 위해
isEndOfWord: 이 플래그는 현재 노드가 하나의 단어의 끝을 나타내는지 여부를 나타냅니다.
2.2 Trie 클래스 생성
이제 Trie 클래스의 기본 구조를 정의하고, 루트 노드를 초기화합니다.

public class Trie {
private final TrieNode root;
// 생성자: Trie 초기화
public Trie() {
root = new TrieNode(); // 루트 노드는 공백 노드로 시작
}
}root:Trie는 항상 루트에서 시작되며, 루트 노드는 공백 노드로 정의됩니다.
2.3 단어 삽입 메소드 구현
다음으로, 문자열을 Trie에 삽입하는 insert 메소드를 구현합니다.
- 문자열의 각 문자를 순차적으로 탐색하며, 노드가 존재하지 않으면 새 노드를 추가합니다.
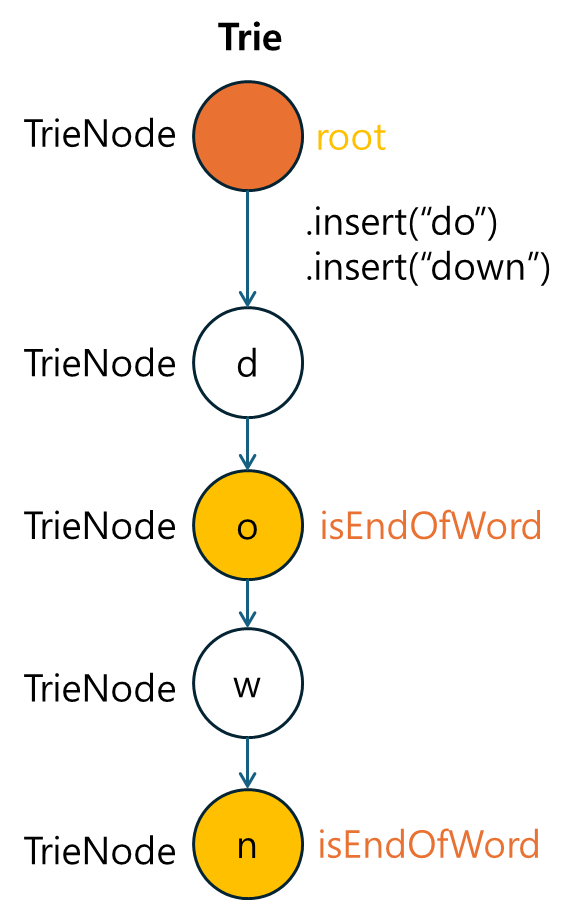
public void insert(String word) {
TrieNode node = root;
for (char c : word.toCharArray()) {
node = node.children.computeIfAbsent(c, k -> new TrieNode());
}
node.isEndOfWord = true;
}computeIfAbsent: 현재 문자가 자식 노드에 존재하지 않으면 새로운TrieNode를 추가합니다.HashMap의 메서드입니다.
- 마지막 문자에 도달하면
isEndOfWord를true로 설정하여 단어가 완성되었음을 표시합니다.
2.4 단어 검색 메소드 구현
이제 Trie에서 특정 단어가 존재하는지 확인하는 search 메소드를 구현합니다.
public boolean search(String word) {
TrieNode node = root;
for (char c : word.toCharArray()) {
node = node.children.get(c);
if (node == null) {
return false; // 문자가 존재하지 않으면 단어가 없는 것
}
}
return node.isEndOfWord;
}
- 각 문자를 순차적으로 탐색하며, 해당 문자가 없으면
false를 반환합니다. - 끝까지 탐색한 후
isEndOfWord가true여야만 단어가 존재하는 것입니다.
2.5 접두사 검색 메소드 구현
접두사(Prefix)로 시작하는 단어가 존재하는지 확인하기 위해 startsWith 메소드를 구현합니다.
public boolean startsWith(String prefix) {
TrieNode node = root;
for (char c : prefix.toCharArray()) {
node = node.children.get(c);
if (node == null) {
return false; // 접두사가 존재하지 않으면 false
}
}
return true;
}- 접두사의 각 문자를 순차적으로 탐색하며, 해당 문자가 없으면
false를 반환합니다. - 접두사에 해당하는 경로가 모두 존재하면
true를 반환합니다.
2.6 테스트
마지막으로 main 메소드를 통해 Trie 기능을 테스트합니다.
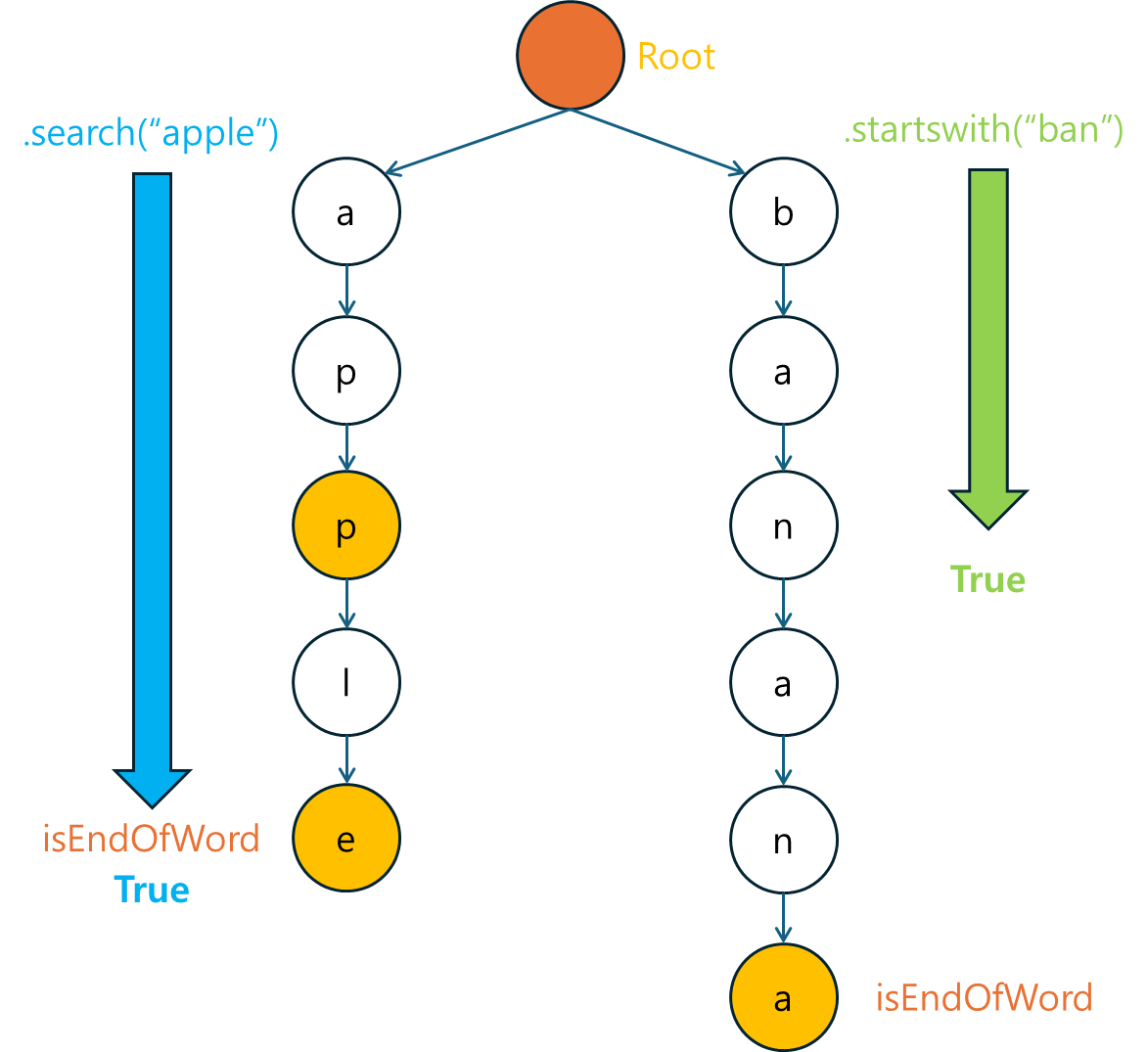
public static void main(String[] args) {
Trie trie = new Trie();
// 단어 삽입
trie.insert("apple");
trie.insert("app");
trie.insert("banana");
// 단어 검색
System.out.println(trie.search("apple")); // true
System.out.println(trie.search("app")); // true
System.out.println(trie.search("ban")); // false
// 접두사 검색
System.out.println(trie.startsWith("app")); // true
System.out.println(trie.startsWith("ban")); // true
System.out.println(trie.startsWith("can")); // false
}
- 이외에도 삭제 메서드 등도
Trie의 특성을 활용해서 구현하실 수 있습니다.
3. Trie 구현 - Python
- Python에서도
Trie자료구조만을 위한 별도의 라이브러리는 없기 때문에, 직접 구현해서 사용하셔야합니다.
구현 및 테스트 코드의 전체 코드는 다음과 같습니다.
class TrieNode:
def __init__(self):
self.children = {}
self.is_end_of_word = False
class Trie:
def __init__(self):
self.root = TrieNode()
# 단어 삽입
def insert(self, word: str) -> None:
node = self.root
for char in word:
if char not in node.children:
node.children[char] = TrieNode()
node = node.children[char]
node.is_end_of_word = True
# 단어 검색
def search(self, word: str) -> bool:
node = self.root
for char in word:
if char not in node.children:
return False
node = node.children[char]
return node.is_end_of_word
# 접두사 검색
def starts_with(self, prefix: str) -> bool:
node = self.root
for char in prefix:
if char not in node.children:
return False
node = node.children[char]
return True
# 테스트
trie = Trie()
# 단어 삽입
trie.insert("apple")
trie.insert("app")
trie.insert("banana")
# 단어 검색
print(trie.search("apple")) # True
print(trie.search("app")) # True
print(trie.search("ban")) # False
# 접두사 검색
print(trie.starts_with("app")) # True
print(trie.starts_with("ban")) # True
print(trie.starts_with("can")) # False그럼 각 단계별로 나누어서 구현 과정을 자세히 살펴보도록 하겠습니다.
3.1 TrieNode 정의
Trie 자료구조에서 각 노드는 하나의 문자를 나타내며, 자식 노드와 단어의 끝을 표시하는 플래그가 필요합니다. 이를 위해 TrieNode 클래스를 정의합니다.
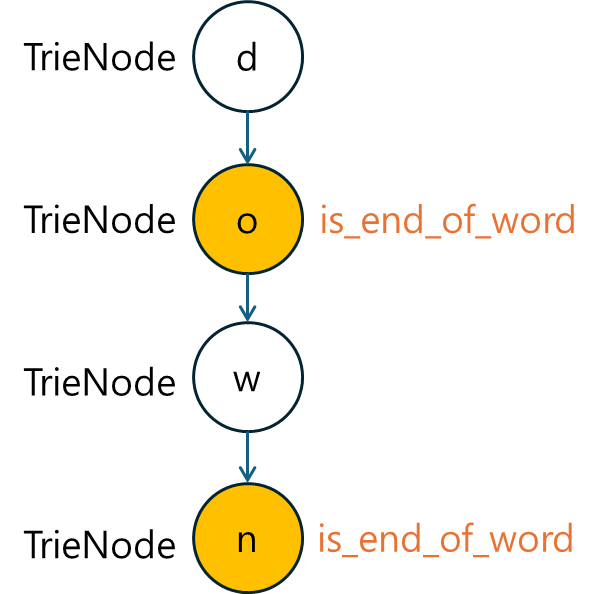
class TrieNode:
def __init__(self):
self.children = {}
self.is_end_of_word = False
children: 각 노드는 자식 노드를 가질 수 있으며, 각 자식은 현재 노드에서 이어지는 문자에 해당합니다.children은딕셔너리로 구현되어 문자를 키로, 노드를 값으로 저장합니다.
is_end_of_word: 이 플래그는 현재 노드가 하나의 단어의 끝을 나타내는지 여부를 나타냅니다.
3.2 Trie 클래스 생성
이제 Trie 클래스의 기본 구조를 정의하고, 루트 노드를 초기화합니다.

class Trie:
def __init__(self):
self.root = TrieNode() # 루트 노드는 공백 노드로 시작root:Trie는 항상 루트에서 시작되며, 루트 노드는 공백 노드로 정의됩니다.
3.3 단어 삽입 메소드 구현
다음으로, 문자열을 Trie에 삽입하는 insert 메소드를 구현합니다. 문자열의 각 문자를 순차적으로 탐색하며, 노드가 존재하지 않으면 새 노드를 추가합니다.
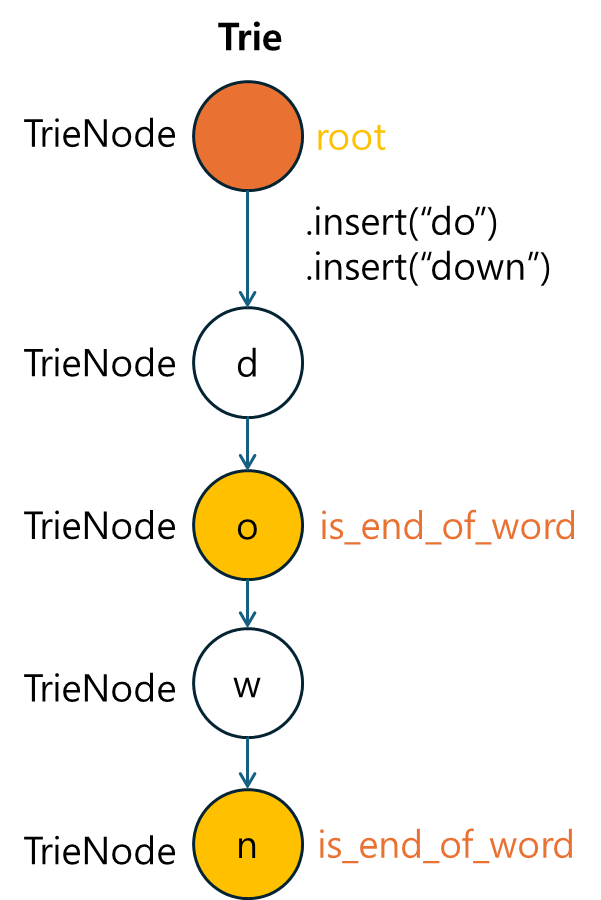
def insert(self, word: str) -> None:
node = self.root
for char in word:
if char not in node.children:
node.children[char] = TrieNode()
node = node.children[char]
node.is_end_of_word = True
children: 문자가 자식 노드에 없으면, 새로운TrieNode를 추가합니다.- 마지막 문자에 도달하면
is_end_of_word를True로 설정하여 단어가 완성되었음을 표시합니다.
3.4 단어 검색 메소드 구현
이제 Trie에서 특정 단어가 존재하는지 확인하는 search 메소드를 구현합니다.
def search(self, word: str) -> bool:
node = self.root
for char in word:
if char not in node.children:
return False # 문자가 존재하지 않으면 단어가 없는 것
node = node.children[char]
return node.is_end_of_word
- 각 문자를 순차적으로 탐색하며, 해당 문자가 없으면
False를 반환합니다. - 끝까지 탐색한 후
is_end_of_word가True여야만 단어가 존재하는 것입니다.
3.5 접두사 검색 메소드 구현
접두사(Prefix)로 시작하는 단어가 존재하는지 확인하기 위해 starts_with 메소드를 구현합니다.
def starts_with(self, prefix: str) -> bool:
node = self.root
for char in prefix:
if char not in node.children:
return False # 접두사가 존재하지 않으면 False
node = node.children[char]
return True
- 접두사의 각 문자를 순차적으로 탐색하며, 해당 문자가 없으면
False를 반환합니다. - 접두사에 해당하는 경로가 모두 존재하면
True를 반환합니다.
3.6 테스트
마지막으로 Trie의 기능을 테스트합니다.
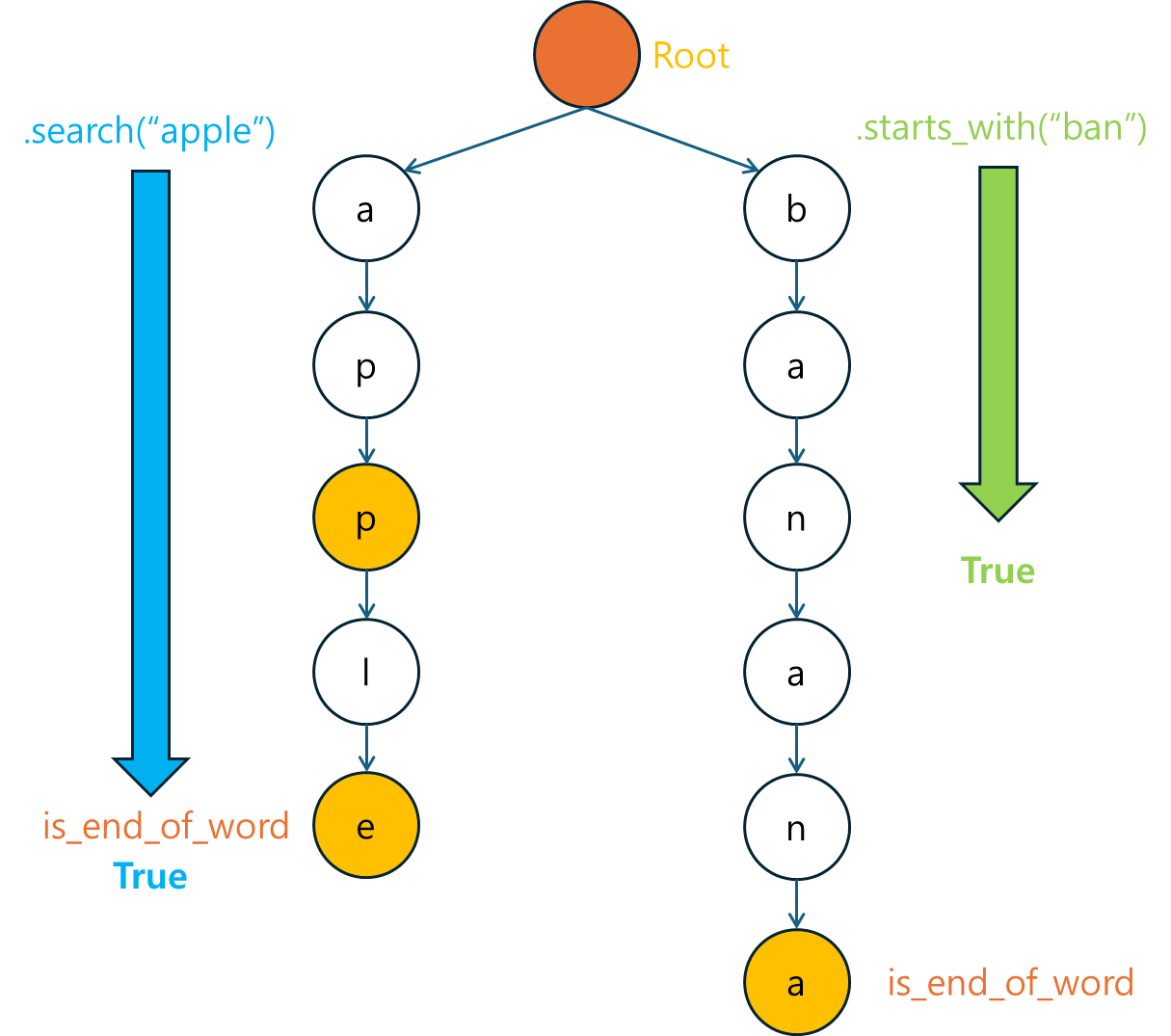
# 테스트
trie = Trie()
# 단어 삽입
trie.insert("apple")
trie.insert("app")
trie.insert("banana")
# 단어 검색
print(trie.search("apple")) # True
print(trie.search("app")) # True
print(trie.search("ban")) # False
# 접두사 검색
print(trie.starts_with("app")) # True
print(trie.starts_with("ban")) # True
print(trie.starts_with("can")) # False
4. 성능 분석 (시간 & 공간 복잡도)
Trie의 성능을 분석할 때는 주로 삽입, 검색, 접두사 검색의 시간 복잡도와 공간 복잡도를 고려합니다.
- 각 연산의 성능은 단어의 길이에 따라 달라지며, 이는 자료구조의 크기와 직접적인 연관이 있습니다.
4.1 시간 복잡도
| 연산 | 시간 복잡도 | 설명 |
|---|---|---|
| 삽입 | O(L) | 단어의 길이 L에 비례하여 각 문자를 노드에 추가합니다. |
| 검색 | O(L) | 단어의 길이 L에 비례하여 각 문자를 순차적으로 탐색합니다. |
| 접두사 검색 | O(L) | 접두사 길이 L에 비례하여 각 문자를 순차적으로 탐색합니다. |
L은 단어의 길이입니다. 일반적인 경우, 각 연산은 단어의 길이에 비례하여 시간이 걸리며, 일반적으로 상수 시간에 비해 크기가 크지 않기 때문에 효율적입니다.
4.2 공간 복잡도
Trie의 공간 복잡도는 저장되는 단어의 수와 각 단어의 문자 수에 따라 결정됩니다.
-
최악의 경우: O(N * L)
여기서N은 저장된 단어의 개수,L은 평균적인 단어의 길이를 의미합니다. 단어들이 공통 접두사를 공유하지 않으면 각 문자가 별도의 노드로 저장되어 공간 복잡도가 증가합니다. -
최선의 경우: O(N)
모든 단어가 동일한 접두사를 가질 경우,Trie는 매우 압축된 형태가 되어 공간 복잡도가 감소합니다.
Trie는 단어의 접두사를 공유하는 만큼 메모리 사용을 최적화할 수 있지만, 자식 노드가 많은 경우 공간 복잡도가 커질 수 있습니다.
5. Trie의 확장 (Variants)
Trie의 기본 구조를 바탕으로 여러 가지 변형이 존재합니다.
- 이를 통해 특정 시나리오에서 성능을 더 개선하거나 공간 사용을 줄일 수 있습니다.
5.1 압축된 Trie (Compressed Trie)
- 정의:
압축된 Trie는 단일 자식을 가진 노드들을 하나로 합쳐서 저장하는 방식입니다.- 이 방법은 공간 효율성을 극대화하며, 공통된 문자열이 많은 경우 메모리 사용량을 크게 줄일 수 있습니다.
- 특징:
- 공간 절약: 중복된 경로를 줄이기 때문에 메모리 사용이 적습니다.
- 복잡도: 검색 및 삽입의 시간 복잡도는 여전히 O(L)입니다.
- 활용:
- 대용량 데이터에서 공간 최적화가 필요할 때 유용합니다.
5.2 Ternary Search Tree (삼진 탐색 트리)
- 정의:
삼진 탐색 트리는Trie와 비슷한 구조지만, 각 노드는 3개의 자식 노드(작음, 같음, 큼)를 가집니다.- 이는 트리의 균형을 유지하면서도 메모리 사용량을 줄이기 위한 변형입니다.
- 특징:
- 메모리 사용 절감:
Trie의 공간 복잡도를 줄이기 위한 방법으로, 각 노드에 3개의 자식만 존재합니다. - 복잡도: 검색, 삽입, 삭제 모두 O(L)의 시간 복잡도를 가지지만, 메모리 사용이 더욱 효율적입니다.
- 메모리 사용 절감:
- 활용:
- 메모리 제한이 있는 환경에서 유용하며,
Trie의 대체 자료구조로 자주 사용됩니다.
- 메모리 제한이 있는 환경에서 유용하며,
5.3 Patricia Trie (Practical Algorithm to Retrieve Information Coded in Alphanumeric, PAtRICiA)
- 정의:
Patricia Trie는 압축된 Trie의 일종으로, 비트 수준에서 문자열을 처리합니다.- 공통된 비트를 합쳐서 저장함으로써 공간을 절약합니다.
- 특징:
- 고효율 공간 사용: 비트를 기준으로 공통된 부분을 합쳐 처리하기 때문에 메모리 효율이 좋습니다.
- 복잡도: 일반 Trie와 유사한 O(L)의 시간 복잡도를 유지하지만, 비트 단위로 작업을 수행합니다.
- 활용:
- 주로 네트워크 라우팅 테이블, 문자열 검색 등에 사용됩니다.
마무리
이번 포스팅에서는 Trie 자료구조의 개념과 주요 특징을 살펴보고, Java와 Python에서 각각의 구현 방식을 단계별로 살펴보았습니다.
- 또한,
Trie의 시간 및 공간 복잡도에 대해 분석하고,압축된 Trie,삼진 탐색 트리,Patricia Trie와 같은 변형들을 통해 Trie의 확장 가능성도 함께 알아보았습니다.
Trie는 특히 접두사 검색이나 자동 완성 기능에 매우 유용한 자료구조로, 효율적인 문자열 처리에 강점을 가지고 있습니다.
- 그만큼 특정 상황에 맞는 자료구조로 선택하여 활용할 수 있다는 점에서 많은 응용 가능성을 지니고 있습니다.
