이번 논문은 2017년에 나온 "Attention is all you need" 라는 제목의 트랜스포머 논문이다. 너무 유명한 논문이라 내심 읽어보고 싶은 마음이 컸지만, 생각보다 어려워서 당황했다. 내가 지금까지 읽었던 논문들과는 분야가 다른 NLP라서 그런지 사용하는 데이터셋도 다르고, 사용하는 표현들도 달랐다. 이해하는데 많은 시간이 필요했던 것 같다.
1. 저자가 이루려고 한 것
트랜스포머 이전에 sequence model과 transduction 문제들의 SOTA는 RNN, LSTM과 같은 방법들이 책임지고 있었다. 그러나 RNN에서는 training sample들의 parallelization이 불가하고, sequence의 길이가 더 길어진다면 이 문제는 더 심각해진다.
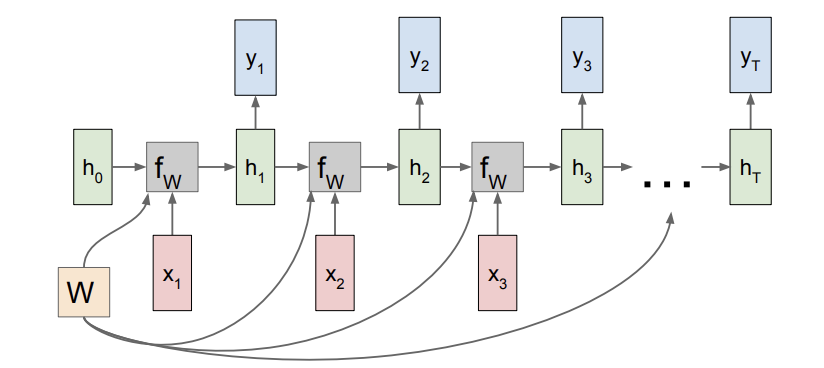
위의 RNN Architecture를 보면 parallelization이 불가하다는게 무슨 뜻이 더 와닿을 것이다. 우리는 한정된 메모리를 사용하기 때문에 이것이 더 큰 문제가 된다. 물론 LSTM을 이용해 이를 어느 정도 해결할 수 있지만, 저자들은 LSTM 성능을 뛰어넘는 다른 방법을 제안한다. 이전의 방법들과의 가장 큰 차이는 Attention만을 이용해 모델을 구성한다는 점이다. 물론 Attention이 트랜스포머에서 처음 사용된 것은 아니지만, 이전에는 Attention과 RNN을 함께 사용했었다.
이렇게 Transformer는 Attention만을 사용해 모델을 만들어 parallelization을 가능하게 만들었고, 이전보다 더 좋은 SOTA를 이루었다.
2. 주요 내용
Transformer는 기본적으로 transduction model답게 encoder-decoder 구조를 가지고 있다. 트랜스포머를 보기 전에, 기존의 전통적인 encoder-decoder 구조를 알아보자.
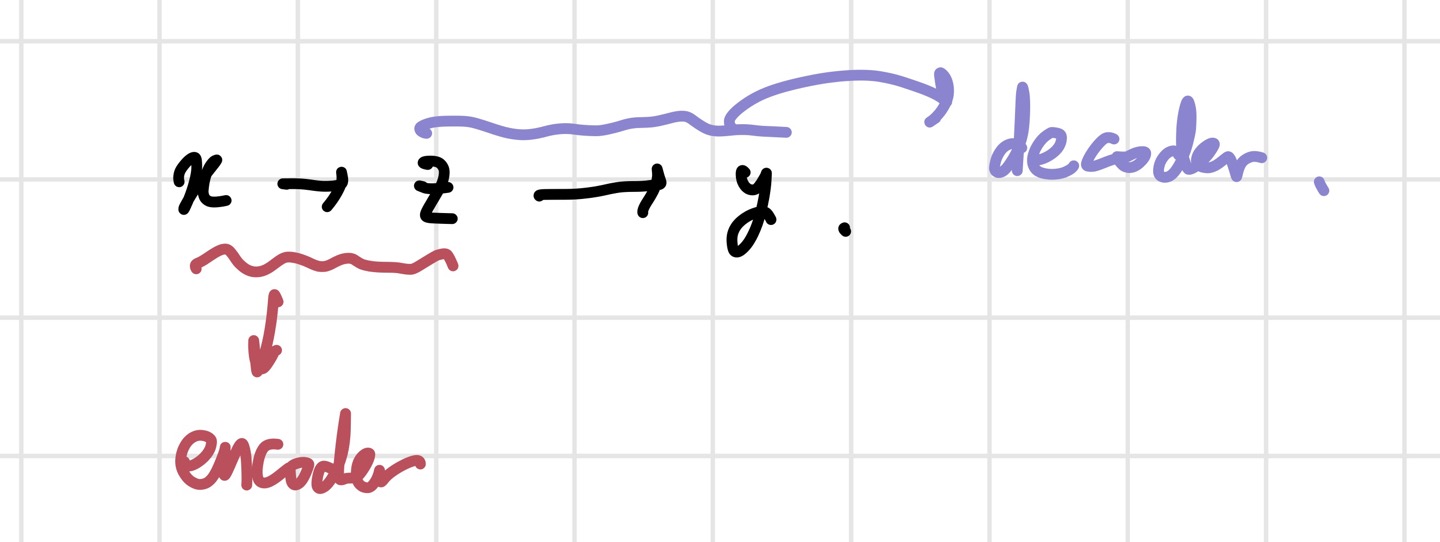
- encoder: x를 z라는 representation으로 mapping 해주는 역할을 한다. input을 잘 설명하는 z를 만드는 과정이라고 생각하면 된다.
- decoder: 생성된 z를 가지고 output을 하나씩 만들어 낸다.
모델이 이전 값들을 이용해 미래의 값들을 예측하기 때문에, auto-regressive한 특성을 가지게 된다. 트랜스포머는 이런 encoder-decoder에 self-attention, point-wise FCL을 얹은 구조이다.
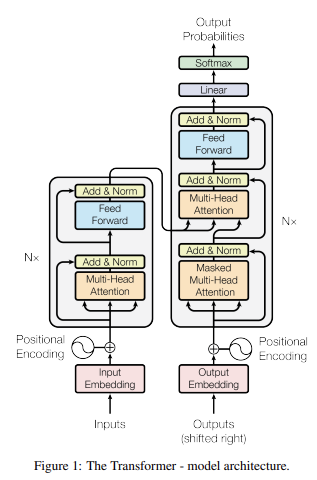
위 사진이 transformer의 architecture이다. 쭉 설명하려고 하니 워낙 복잡해서, 먼저 간단히 틀을 잡고 자세한 설명을 하려고 한다. 일단 각 sublayer가 어떤 역할을 하는지 보고, encoder/ decoder 구조로 크게 넓혀가려고 한다.
- Multi-head Attention: Self- attention을 여러 개 사용한 layer이다.
- Self-attention: K(key), V(value), Q(query)를 이용해 alignment와 attention weight들을 얻는다.
- Positional encoding: Self- attention은 input의 순서를 고려하지 않는다. 그렇기 때문에 positional encoding을 도입해 sequence data인 언어와 image feature들을 다룬다.
1) Layer Architecture
전체 모델 구조를 살펴보기에 앞서 각각의 layer가 어떻게 돌아가는지부터 알 필요가 있다.
i) self-attention layer
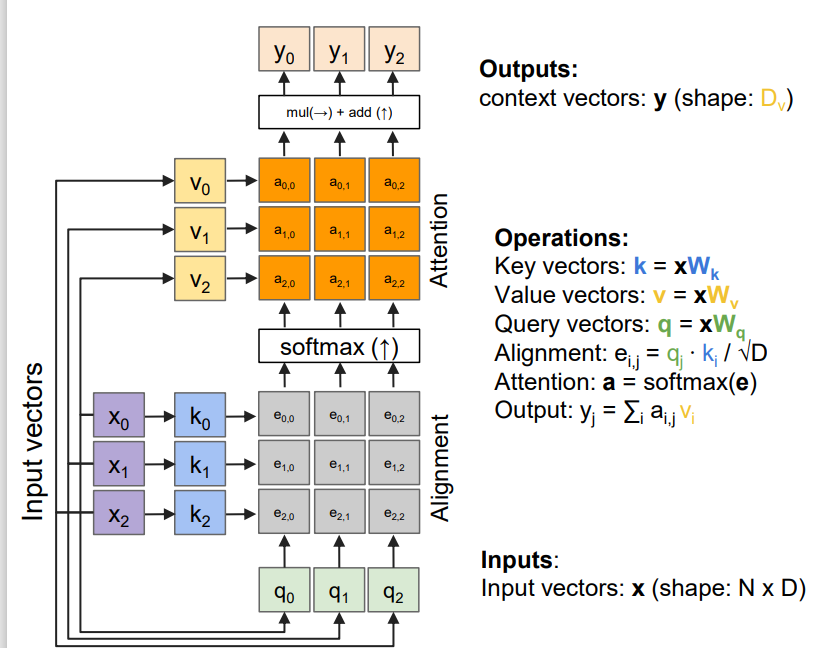
self-attention의 구조는 이렇다. input vector가 들어오면, 각 weight matrix와 dot product를 통해 key, value, query vector를 얻는다. 이때 각 key와 value는 pair를 이룬다. 그리고 k와 q의 dot product를 이용해 alignment score을 얻는다. 이때 alignment score e가 뜻하는 바는 무엇일지 생각해봐야 한다. 기본적으로 dot product는 두 벡터의 유사성에 대한 정보를 준다. 벡터의 방향이 유사하다면 값이 클 것이고, 두 벡터가 이루는 각도가 90도면 값은 0일 것이다. 따라서 k와 q의 dot product가 크다면, 우리가 주의 깊게 봐야 한다는 뜻이다. 즉, attention에 대한 정보를 주는 것이다. 그러나 우리가 다루는 데이터의 차원이 크기 때문에, dot product 값도 너무 커질 수 있다. 이를 방지하기 위해 차원값의 루트 값으로 나눠주는 것이다. 논문에서는 이 attention 과정을 scaled-dot product attention이라고 한다. 이렇게 얻은 e 값들을 softmax에 태워 attention weight들을 얻는다. 일종의 normalization으로 봐도 된다. 마지막으로 attention weight와 value 값을 곱해 최종 output을 찾는 것이다. 논문에서는 Attention 공식을 아래와 같이 표현했다. (공식 아래의 그림이 공식을 직관적으로 이해하는데 도움이 될 것이다.)
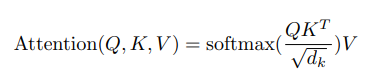
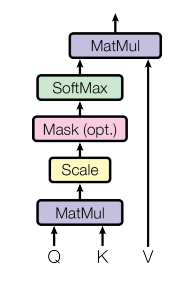
cs231n 슬라이드의 e가 위의 공식의 QK^T를 뜻한다. 참고로, 찾아보니 V는 source sentence들의 유의미한 부분들을, K는 V의 index 값들을, Q는 내가 알고 싶은 것들을 담고 있다고 한다. 수식에 담긴 직관적인 해석이라고 생각하면 될 것 같다. 따라서 Q와 K를 내적하는 것은 내가 알고 싶은 것과 source sentence의 index를 비교하고, attention 값이 높은 것들에 해당하는 value를 곱해주는 것이다.
ii) positional encoding
앞서 언급한대로, self-attention layer는 input의 순서를 신경쓰지 않는다. 그렇기 때문에 positional encoding을 도입한다.
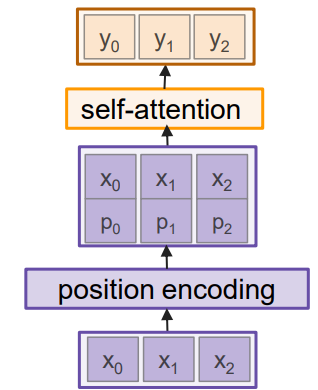
위의 구조처럼 positional encoding된 벡터를 input과 concat 시켜서 self-attention layer에 먹인다. 문제는 어떤 방식으로 positional encoding을 할 것인지인데, 논문에서는 를 이용해서 이를 구현했다.

짝수 항에는 , 홀수 항에은 를 사용한다. 위 사진의 intuition을 보면, 각 position별로 다른 값을 지정하는 것을 볼 수 있다. 이를 혹은 곡선을 이용해서 구현해내는 것이다. 이 방식은 간단하면서도 각 time step별로 unique한 encoding을 할 수 있고, 문장 간 distance를 효과적으로 표현할 수 있다.
iii) Masked self-attention layer
self-attention에서 살짝 변주를 준 layer이다.
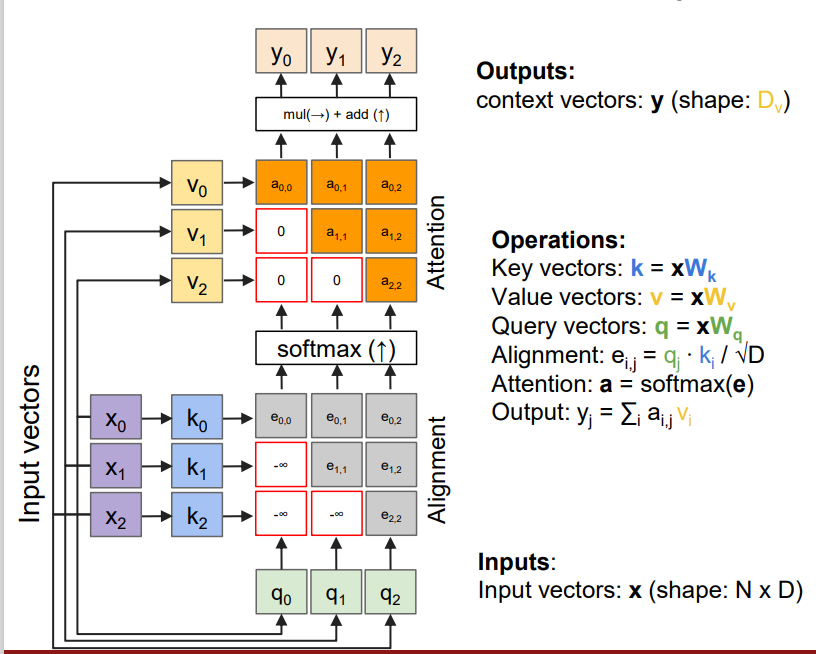
masking을 하는 목적은 현재보다 미래의 vector들은 보지 못하게 하기 위함이다. 현재 시점보다 미래의 값들의 alignment score에는 -INF를 넣어 output을 내는데 영향을 주지 못하게 한다. 이 점 외에는 앞에서 본 것과 비슷하다.
iv) Multi-head attention layer
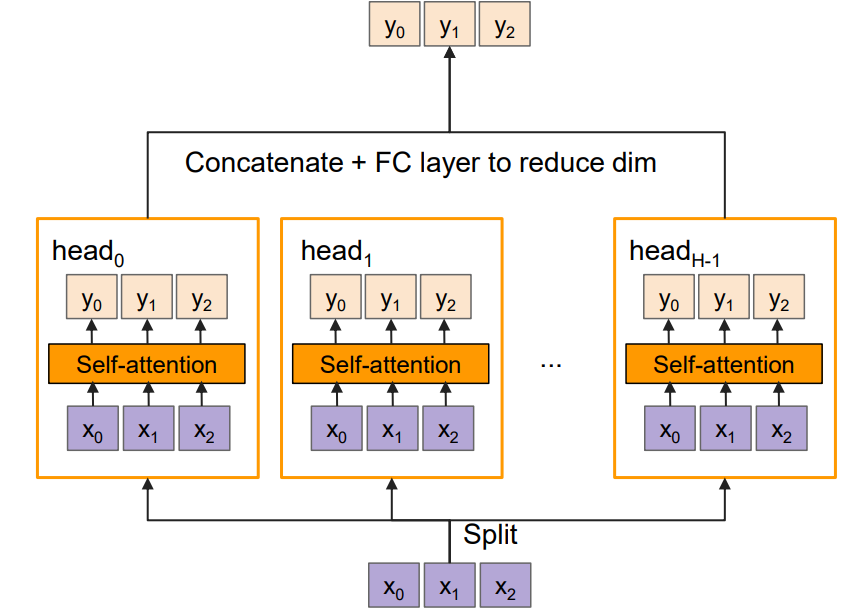
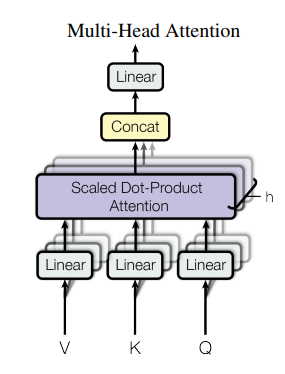
Multi-head attention은 self-attention layer가 여러 개 쌓인 형태라고 보면 된다. 이걸 도입하는 이유는 여러 개의 Q,K,V 값들을 이용하고 싶기 때문이다. CNN에서 여러 개의 filter를 사용하는 것과 같은 느낌이라고 보면 된다. 이때, 각 self-attention을 head라고 표현한다.
v) Position-wise Feed Forward Network
논문에서 보이는 FFN은 두 개의 FC layer로 구성된다. 우리가 익숙한 표기법으로 보자면, FC1-ReLU-FC2 의 구조를 가진다. 아래의 식에서도 이를 확인할 수 있다.
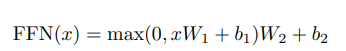
여기까지가 모델을 구성하는 layer들에 대한 설명이다. 이제 encoder/ decoder block을 살펴보자.
2) Encoder/ Decoder Architecture
이제 앞서 살펴본 layer들이 Encoder와 Decoder에서 어떻게 엮여 있는지 알아보자.
i) Encoder
논문에서는 6개의 Encoder block을 사용했다.
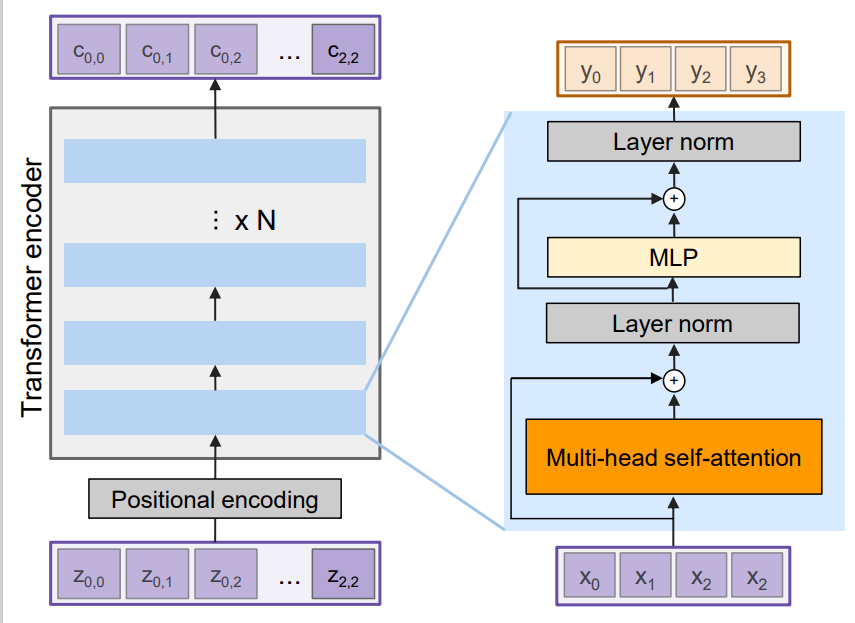
논문의 illustration과 다르지만, 난 이게 더 보기 편했다. 논문의 architecture를 반으로 나누었을때 왼쪽 부분에 해당하는 것이 위의 그림이다.
먼저, input은 positional encoding을 거쳐 Multi-head attention layer를 만나게 된다. 그 이후 layer norm을 거치고, FFN(위 그림의 MLP)과 layer norm 후 output을 얻게 되는 구조이다. 주목할 것은 residual connection이다. 각 sublayer마다 따로 진행해준다.
ii) Decoder
Decoder의 경우도 논문에서 6개의 block이 사용되었다.
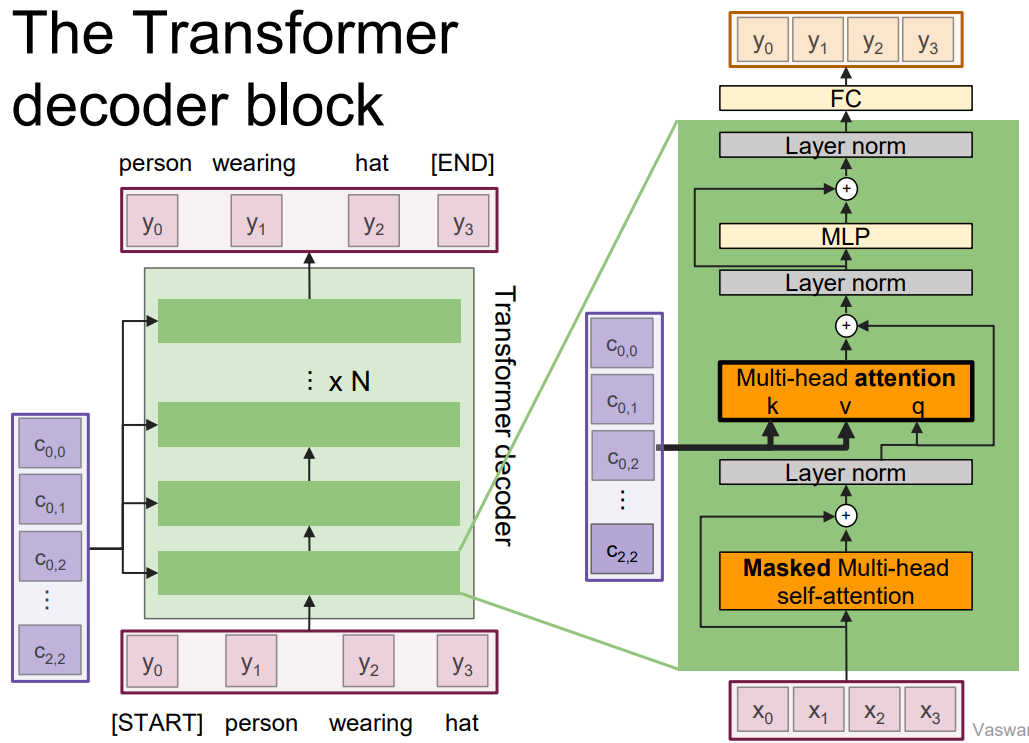
decoder는 encoder의 2개의 sublayer에 하나의 sublayer가 추가된 형태이다. encoder의 residual connection도 똑같이 사용됨을 알 수 있다. 중간의 multi-head attention을 보면, encoder output stack을 input으로 받는 것을 알 수 있다. 이것이 추가된 sublayer이다. 이 layer는 self-attention이 아니라는 것이 중요하다. encoder output을 attention에 이용하기 때문이다. 이제 전체적인 decoder 구조를 훑어보자. 먼저 decoder는 input으로 target sequence를 받아 masked multi-head self-attention layer를 통과한다. 이를 통해 현재를 기준으로 이전 token들만 보며 output을 낼 수 있게 된다. 그리고 나서 layer norm을 거치고, encoder output을 input으로 하는 multi-head attention layer를 통과한다. 이후는 encoder와 마찬가지로 layer norm-FFN을 통과한다. 그리고 마지막으로 output을 내기 전에 layer norm과 FC layer를 더 거친다.
내용이 너무 길어져 논문에서 다루는 training 결과에 대한 부분은 간단히만 정리하려고 한다.
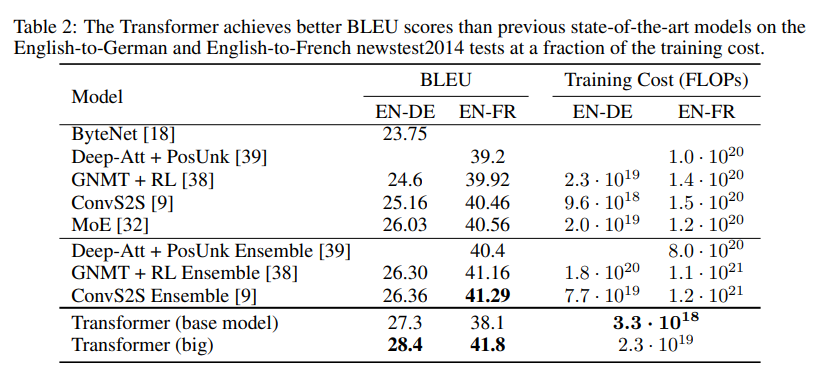
위의 표를 보면, transformer가 새로운 SOTA 결과를 냈음을 알 수 있다. BLEU는 NLP 분야의 성능을 평가하는 중요한 지표중 하나인데, BLEU가 2 이상 증가하면 엄청난 발전이라고 한다. Transformer는 이런 면에서 대단하다고 느껴진다.
3. 논문 내용의 실용성
논문을 이해하는데 중요한 요소 중 하나는 RNN과의 차이점을 아는 것이라고 생각한다. 먼저, Transformer와 RNN의 가장 큰 차이점은 Transformer는 Attention만 사용해서 모델을 구현했다는 점이다. RNN과 Attention을 함께 사용했던 이전과는 확연히 다르다. RNN의 단점은 sequence 형태로 input을 넣어야 했다는 것이고, sequence가 길어질수록 정보가 decoder에게 전달되기 힘들다는 것이었다. 또, 후속 hidden state들은 이전 hidden state들이 계산 되어야 얻을 수 있다는 점 또한 문제였다.
transformer는 이러한 단점을 어느정도 해결했다. 길이가 긴 sequence들에서도 좋은 성능을 냈고, attention을 사용할 때도 모든 input을 고려하기 때문에 더 정확하다. 또, positional encoding을 통해 input으로 ordered/unordered sequence를 모두 받을 수 있게 되었고, parallelization도 가능해졌다.( alignment score와 attention weight들을 계산할 때 사용한다.) 이런 transformer도 단점은 있다. 메모리를 많이 요구한다는 것이다. 그러나 GPU의 성능이 점점 좋아지고 있어 나름 긍정적인 면도 있다고 한다.
훈련 속도 또한 RNN/CNN based architecture를 가진 모델들보다 훨씬 빠르며, 이전에 존재하던 앙상블 모델까지 모두 능가했다는 점 또한 눈여겨 볼 만 하다.
4. 찾아볼 레퍼런스
논문을 읽다가 'beam search'라는 표현이 나왔는데, 완벽히 이해하진 못해서 이 표현이 처음 제안된 논문을 좀 읽어봐야 될 것 같다.
5. 정리
여태까지 읽은 논문 중에 구조가 가장 머리에 들어오지 않았던 것 같다. Attention이 어떻게 이루어지는지, 어떻게 해서 Attention의 식이 저렇게 나오게 되었는지, 왜 굳이 Layer Norm을 쓰는지 등 궁금한 점이 너무 많았다. 그런데 하나하나 천천히 찾아보고 논문도 여러 번 읽으니 어떻게 돌아가는지 어느정도 이해를 하게 된 것 같다. 요새 엄청나게 핫한 분야에 발이라도 담궈본 것 같아 기쁘다. 그리고 비전 분야에서도 요새 트랜스포머 기반의 모델들이 많이 나온다고 하니 그 쪽으로도 공부해 봐야겠다.
6. 참고
- https://www.youtube.com/watch?v=iDulhoQ2pro
- cs231n Transformer 강의 슬라이드
