이번 논문은 2014년에 발표된 "Going deeper with convolutions" 이라는 논문이다. GoogLeNet이라는 CNN 구조를 제안한 논문으로도 유명하다.
1. 저자가 이루려고 한 것
저자가 논문을 쓴 목적은 한정적인 computational budget을 이용해 효율적인 Deep Neural Network를 만드는 것이다. 이전까지의 architecture들은 layer가 많아질수록 parameter 수가 기하급수적으로 많아졌고, 이는 overfitting을 야기했다. 물론 데이터셋을 더 많이 취합해도 되지만, 이 취합하는 과정을 사람이 해야 하기 때문에 쉽지 않다. 때문에 저자는 Inception module이라는 구조를 통해 이 문제를 해결하고자 했고, 결과적으로 22 layer 모델을 만들어 ILSVRC14에서 우수한 성적을 거두었다. 이 대회에서 GoogLeNet 이 사용한 parameter 수는 AlexNet보다 12배 적은 숫자였다. 저자는 모델이 효율적으로 메모리를 이용하기 때문에 in practice에서도 사용할 수 있을 것이라고 예측한다.
2. 주요 내용
논문이 쓰여지던 시기에 성능 개선 트렌드는 network의 size를 키워 모델의 성능을 끌어올리는 식이었다. 여기서의 size는 layer 수, layer 당 neuron 수(논문에서는 width라고 표현)를 모두 의미한다. 이 방법은 training data가 충분히 많을 경우 가장 이상적인 해결책이다. 그러나 training data의 양을 늘리는데는 한계가 있다. 초기에 data를 만들 때 사람이 라벨링을 해야 하기 때문에, dataset을 만드는 것은 좋은 방법이 아닌 것이다. training data가 충분치 않은 상황이라면, 무작정 network size를 늘리는 것은 두 가지 문제점을 야기할 수 있다.
i) 사이즈를 키우며 parameter 수도 많아지기 때문에, overfitting 가능성이 굉장히 커진다.
ii) computation에 필요한 자원이 크게 증가한다.
저자들은 computation에 사용되는 자원이 늘어나는데, 만약 결과로 나온 weight matrix의 값들이 0에 가깝다면 resource가 낭비된 것이라고 표현한다. 때문에 computational resource의 효율적인 배분이 필요하다.
위에서 언급된 두 가지 문제를 해결하는 방법은 기존의 Fully connected architecture에서 sparsely connected architecture로 바꾸는 것이다. sparse한 network 구성이라면 computation을 적게 사용해도 되니까 좋은 방법처럼 보인다. 그러나 sparse한 자료구조는 계산하기에 용이하지 않다. 우리가 원래 사용하던 dense matrix에서의 계산보다 훨씬 더 정교한 엔지니어링이 필요한 것이다. 만약 sparse한 특성을 잘 활용하면서도 dense matrix를 계산할 때의 용이함을 얻을 수 있는 구조가 있다면 좋을 것이다. 이 두가지를 어느정도 만족하도록 설계된 것이 Inception Module이다.
※ Architectural Details
앞서 언급했듯이, Inception Module은 computer vision network에서 local sparse 구조를 근사해 이를 dense하게 계산하는 방법을 고안하기 위해 만들어졌다. Inception은 기본적으로 patch size(filter size)로 1x1, 3x3, 5x5만을 사용한다. 이렇게 정한 특별한 이유는 없고, ailgnment issue(filter size가 짝수일 때 어디를 가운데로 두어야 할지에 대한 문제)를 피하기 위해서이다. 홀수로 filter size를 정하면 이런 문제가 사라진다. 결과적으로 하나의 layer에서 나온 여러 output들이 concat 되어 하나의 output이 되고, 이것이 다음 layer의 input이 되는 구조를 갖게 된다. 이전의 연구를 통해 pooling도 좋은 효과를 얻는다는 사실을이 밝혀졌기 때문에 pooling도 함께 사용된다.
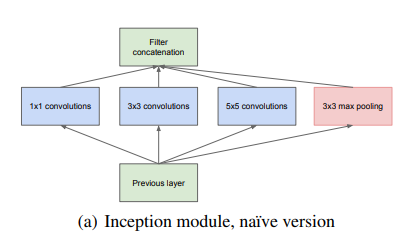
위의 사진이 지금껏 이야기한 Inception module 한 개의 구조이다. module들이 쌓이고 쌓여 전체 네트워크를 만들어 낸다. 그러나 naive한 inception module은 문제가 있다. 5x5 convolution은 전체 네트워크에서 많이 사용하지 않는다고 하더라도 filter수가 많은 경우 computation 양이 크게 증가한다. 여기에 pooling도 추가된다면, 마지막에 concat되는 각 output들의 차원도 굉장히 커지게 된다. 이런 식으로 layer가 몇 번 반복되면 요구되는 computation 숫자는 급속도로 커지게 된다는 뜻이다. 논문에서는 이 현상을 computational blow up이라고 표현한다. 이러한 문제를 해결하기 위해 저자는 1x1 convolution을 도입한다. 나는 이것이 논문의 key idea라고 생각한다. 1x1 convolution은 두 가지 목적으로 사용된다.
i) dimensional reduction
ii) ReLU
dimesional reduction은 1x1 convolution은 width, height는 유지하면서 filter의 개수를 통해 차원을 축소 할 수 있다는 뜻이다. 또, 각 convolution layer가 ReLU를 갖고 있기 때문에, projection의 효과도 있다. 이렇게 module의 구조를 살짝 바꾸면, 아래와 같은 구조가 나온다.
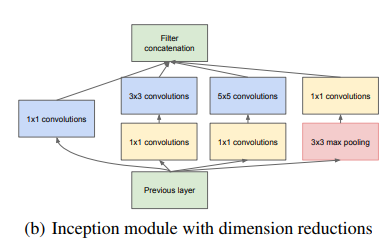
언급했던 것과 같이 computational blow up을 일으킬만한 3x3, 5x5 convolution 앞, 그리고 max pooling(Stride=2) 후에 1x1 convolution을 넣어주는 것이다. 이러한 방법을 사용하면 computational blow up의 걱정을 하지 않고 network의 size를 늘릴 수 있다.
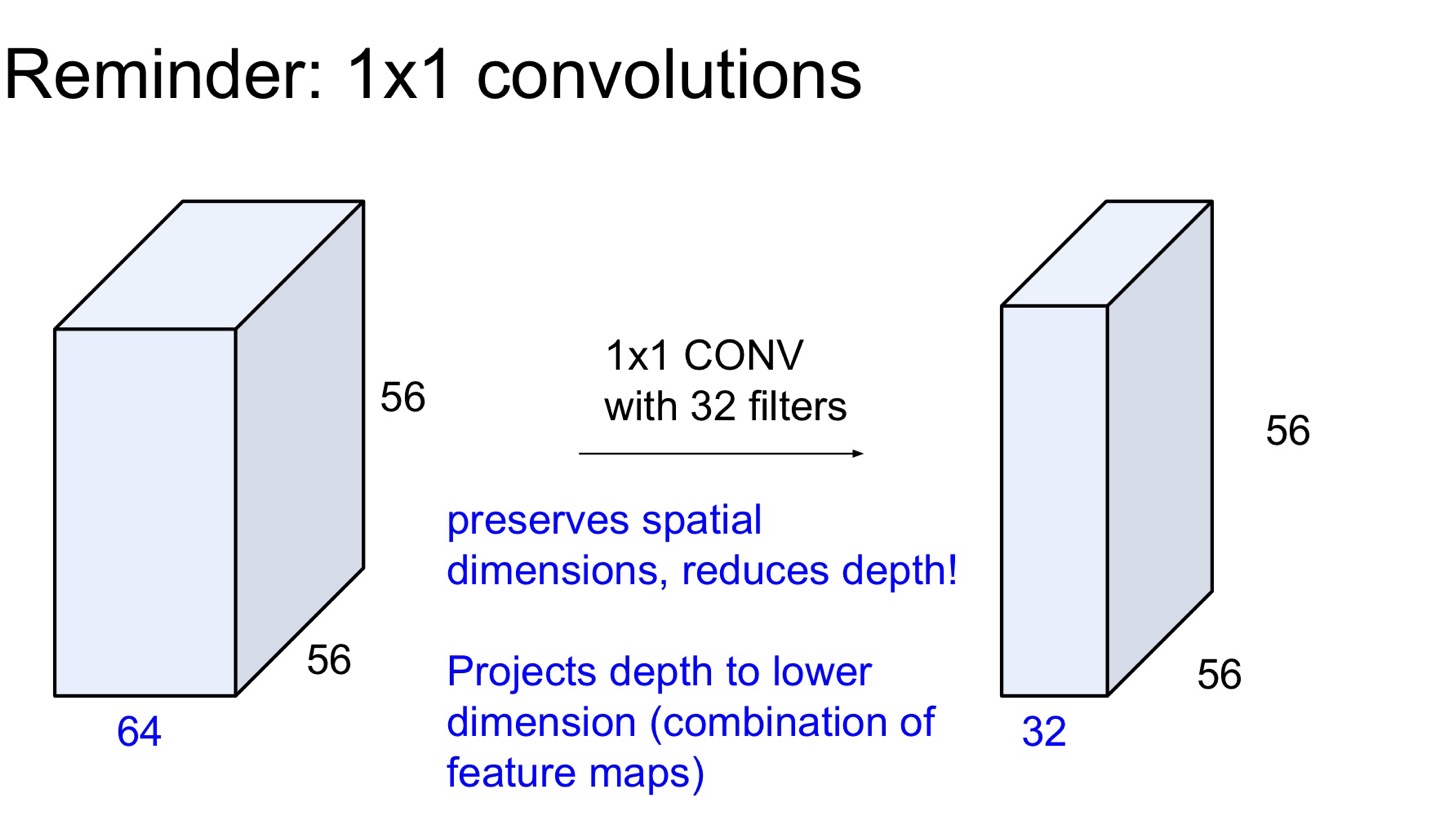
위의 사진이 1x1의 차원 축소 원리를 설명해준다. 원래 차원이 64였던 input을 1x1 filter 32개를 적용해 차원을 32로 줄인 것을 볼 수 있다.
※ GoogLeNet
GoogLeNet의 전반적인 특성을 알아보자. GoogLeNet의 초기 layer에서는 전통적인 convolutional layer 구조를 따르고, higher layer에서 Inception Module을 사용한다. 또한, 모든 convolution에서는 activation function으로 ReLU를 사용한다. input은 224x224x3 (RGB image)이고, 전처리로 mean subtraction을 해준다. 네트워크는 총 22개의 layer로 구성되어 있다. 마지막 classifier 전에 FC Layer를 사용하는 것은 top1-accuracy 0.6% 증가하는 효과를 얻게 해주었다. 그러나 Dropout은 여전히 필요하다. 아래의 사진이 지금까지 설명한 GoogleNet의 전체적인 구조이다.
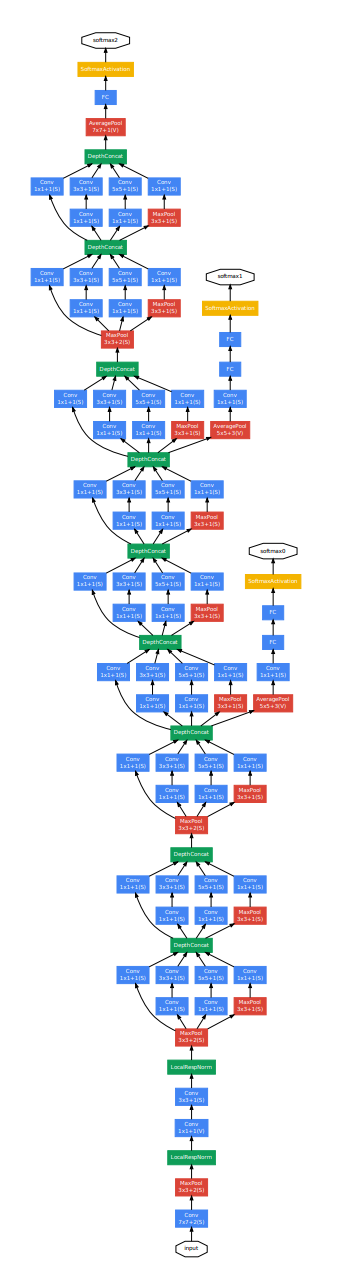
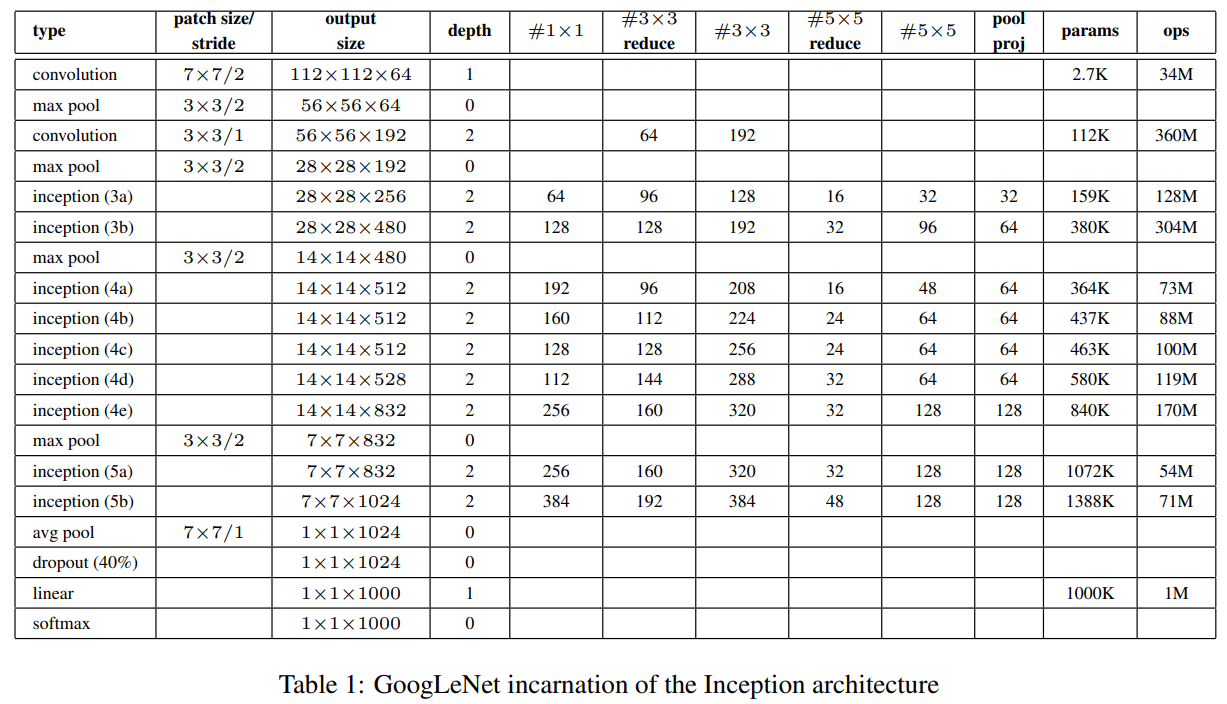
22 layer network여서 구조도도 정말 길다. 그 아래의 표는 GoogLeNet의 구조를 자세히 적어놓은 표이다. #3x3 reduce와 #5x5 reduce는 Inception module에서 3x3, 5x5 전에 적용하는 1x1 filter들의 개수를 의미한다.
이제 GoogLeNet의 backprop에 대해서 알아보자. 앞서 언급했듯이, depth가 22인 네트워크라 효과적인 backprop하는게 어려워 보인다. 초기 layer의 gradient가 계산되려면 너무 먼 길을 와야 하고, 이는 gradient update에 안 좋은 영향을 줄 수 있다. 따라서 저자는 'auxilary classifier' 라는 방법을 고안해 냈다. 직역하면 보조 classifier 정도라고 생각하면 될 것 같다. 위의 구조도 상에서는 네트워크 중간에 softmax function이 달려있는 부분 2개를 보면 된다.
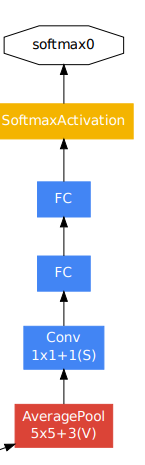
auxilary classifier는 average pool(S=3)-1x1 conv(S=1), filter 128개- FC1024- dropout 0.7- FC - softmax의 구조를 갖는다. 이전 연구를 보면 intermediate layer의 feature가 굉장히 discriminative하다는 것이 밝혀졌다. 저자는 여기서 아이디어를 얻어서 intermediate layer에 보조적인 classifier를 추가했다. 그리고 나서 Training시 전체 loss에 auxilary network들의 loss들도 (loss값 x 0.3)을 해서 더해준다. 이렇게 하면 초기 layer들의 gradient들이 update에 어느 정도 영향을 줄 수 있게 된다. Test time때는 auxilary classifier를 제거하고 모델을 돌린다.
GoogLeNet은 SGD+ momentum(0.9)를 사용해서 훈련시켰고, lr은 매 8 epoch마다 4%씩 감소하게 설정했다. SGD의 수렴을 도와주는 기법인 Polyak averaging도 사용되었다. image에서 sample하는 patch의 크기도 다양하게 할수록 좋은 성능을 낸다는 사실이 드러나 전체 사진 크기의 8%~100% 사이로 sampling을 진행했고, 가로 세로 비 또한 3/4~4/3 사이로 sampling해서 진행했다. 모델을 훈련시키는데 워낙 다양한 기법들이 사용되어 어떤 기법이 모델 성능에 크게 기여했는지에 대한 정보는 알 수 없었다고 한다.
GoogLeNet은 ILSVRC 2014 classification 부문과 detection 부문에 참가하였다. classification 부문에서는 1등(top-5 error 6.7%), detection 부문에서는 우승은 아니지만 뛰어난 성능을 보였다. 모델의 setup에 대해서는 자세히 적지 않겠다.
3. 논문 내용의 실용성
GoogLeNet은 당시 computational resource를 최대한 효율적으로 사용하려고 노력한 network이다. 실제로 저자들은 네트워크가 단순히 학술적인 용도뿐만 아니라 현실의 문제 해결에도 사용될 수 있기를 원했기 때문에 의미있다고 볼 수 있다. GoogLeNet이 제안한 Inception Module 구조를 통해 제한된 자원을 효율적으로 사용하여 이전의 모델들보다 더 좋은 성능을 낼 수 있었고, overfitting과 계산량 문제를 걱정하지 않고 네트워크의 사이즈를 늘리는 것 또한 가능하게 했다. 새로운 구조를 제안했다는 점에서 상당히 흥미로운 논문인 것 같다.
