논문 리뷰
1.논문 리뷰 방법과 ML 커리어 조언- cs230 Lecture 8
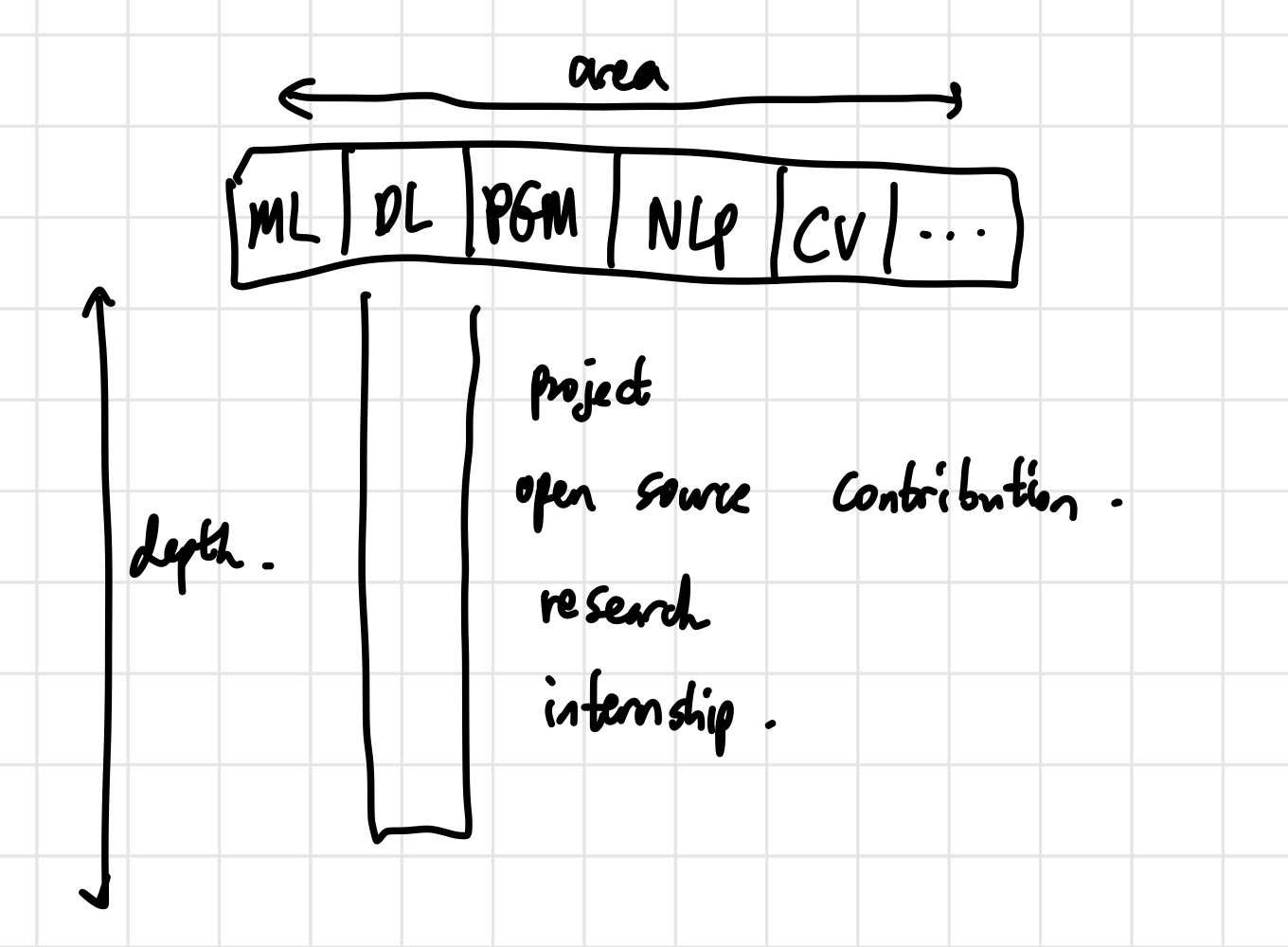
이 글은 cs230(스탠포드 강의) 8강 내용을 바탕으로 요약한 글이다. 앤드류 응 교수님의 논문을 효율적으로 읽는 방법과 ML / DL 분야에서 어떤 직장을 골라야 할지에 대한 조언을 담고 있다. 강의 원본을 보고 싶다면 유튜브에 cs230 lecture 8이
2.논문 리뷰(1)- Deep learning
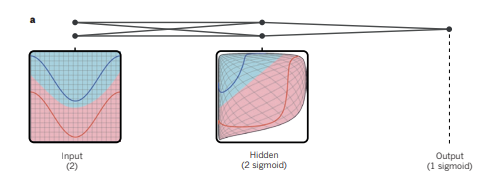
이번에 살펴볼 논문은 Nature 지에 실린 LeCun, Yann, Yoshua Bengio, and Geoffrey Hinton. "Deep learning." Nature 521.7553 (2015): 436-444이다. 딥러닝에 대한 전체적인 개요를 소개하
3.논문 리뷰(2)- Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
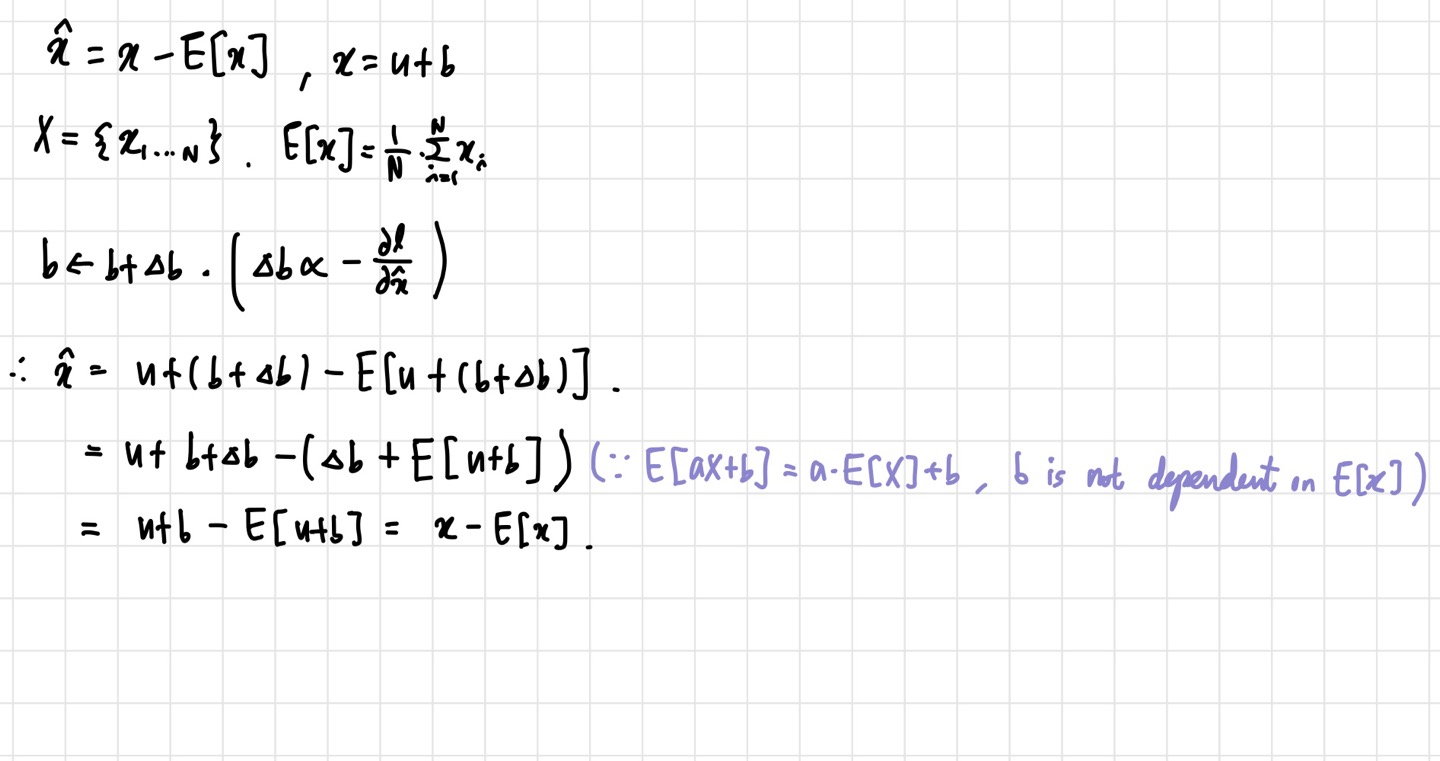
이번에 살펴볼 논문은 2015년에 제안된 'Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift' 라는 논문이다. 인공지능을 공부하다보면 자주 마주치
4.논문 리뷰(3)- ImageNet Classification with Deep Convolutional Neural Networks
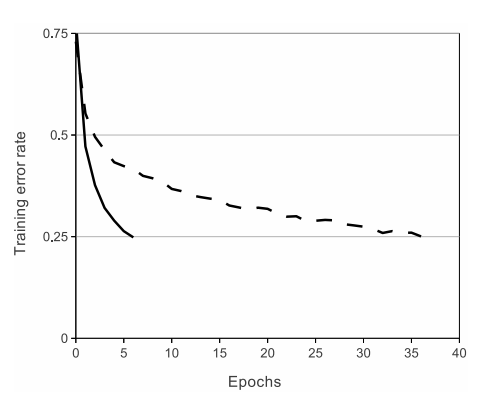
이번에 리뷰해볼 논문은 AlexNet을 다루는 'ImageNet Classification with Deep Convolutional Neural Networks, Krizhevsky et al. (2012)' 라는 논문이다. Deep Convolutional
5.논문리뷰(4) - Dropout: A Simple Way to Prevent Neural Networks from Overfitting

    이번에 살펴볼 논문은 2014년에 Dropout을 제안한 "Improving neural networks by preventing co-adaptation of feature detectors", Hinton et al. 이다. Dropout은 현
6.논문 리뷰(5)- Very Deep Convolutional Networks For Large-Scale Image Recognition
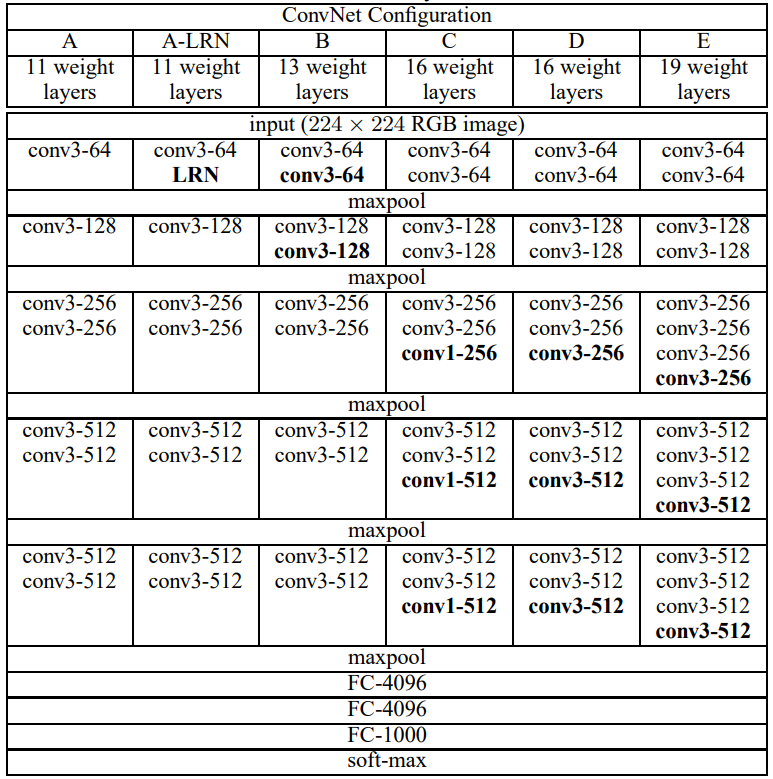
이번에 살펴볼 논문은 VGGNet 논문으로 알려진 "Very Deep Convolutional Networks For Large-Scale Image Recognition", Simonyan et al. (2014) 이다. VGGNet은 이전의 모델 archit
7.논문 리뷰(6)- Attention Is All You Need
이번 논문은 2017년에 나온 "Attention is all you need" 라는 제목의 트랜스포머 논문이다. 너무 유명한 논문이라 내심 읽어보고 싶은 마음이 컸지만, 생각보다 어려워서 당황했다. 내가 지금까지 읽었던 논문들과는 분야가 다른 NLP라서 그런지
8.논문 리뷰(7)- Going deeper with convolutions
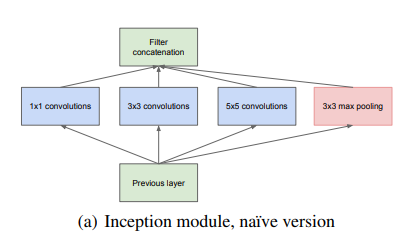
이번 논문은 2014년에 발표된 "Going deeper with convolutions" 이라는 논문이다. GoogLeNet이라는 CNN 구조를 제안한 논문으로도 유명하다. 저자가 논문을 쓴 목적은 한정적인 computational budget을 이용해
9.논문 리뷰(8)- Deep Residual Learning for Image Recognition
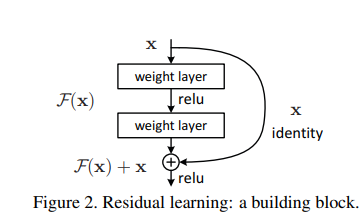
이번에 리뷰해 볼 논문은 2015년에 나온 "Deep Residual Learning for Image Recognition" 이다. 우리에게 ResNet이라고 알려진 CNN 구조를 다룬 논문이다. 논문이 나올 당시에는 ImageNet dataset에 16
10.논문 리뷰(9)- An Image Is Worth 16x16 Words: Transformers For Image Recognition At Scale
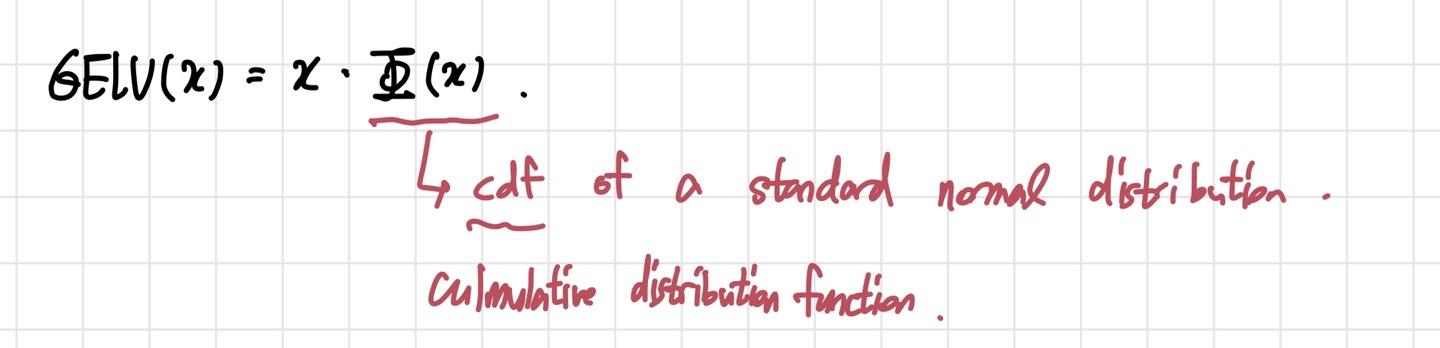
이번에 리뷰해 볼 논문은 ViT 논문으로도 유명한 2021년에 나온 "An Image Is Worth 16x16 Words: Transformers For Image Recognition At Scale" 이라는 논문이다. NLP 분야에서 사실상 Transfor
11.논문 리뷰(10)- A Simple Framework for Contrastive Learning of Visual Representations
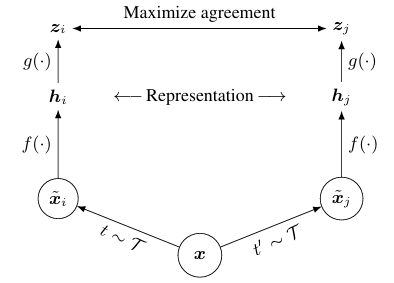
이번에 살펴볼 논문은 SimCLR 구조를 제안한 "A Simple Framework for Constrastive Learning of Visual Representations,Chen et al.(2020)" 이다. SimCLR은 간단한 contrastive
12.논문 리뷰(11) - Hitchhiker's Guide to Super-Resolution: Introduction and Recent Advances
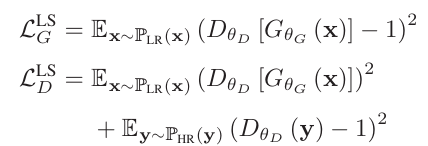
    드디어 Deep Learning의 기초 논문들을 읽고 내가 관심이 있던 Super Resolution으로 들어올 수 있게 되었다. 그러나 막상 읽으려고 하니 사용하는 metric들이 낯설어 survey 논문으로 먼저 대략적인 개념을 잡고 가야 되겠
13.논문 리뷰(12) Image Super-Resolution Using Deep Convolutional Networks
    저번 글에서 정리한 survey 논문을 읽으며 기초적인 지식은 조금 쌓았으니, 이번에는 SR 분야에서 CNN을 처음 적용해 유의미한 결과를 낸 SRCNN 논문을 살펴보려고 한다. 논문의 정확한 이름은 "Image Super-Resolution Us
14.논문 리뷰(13) - Accurate Image Super-Resolution Using Very Deep Convolutional Networks
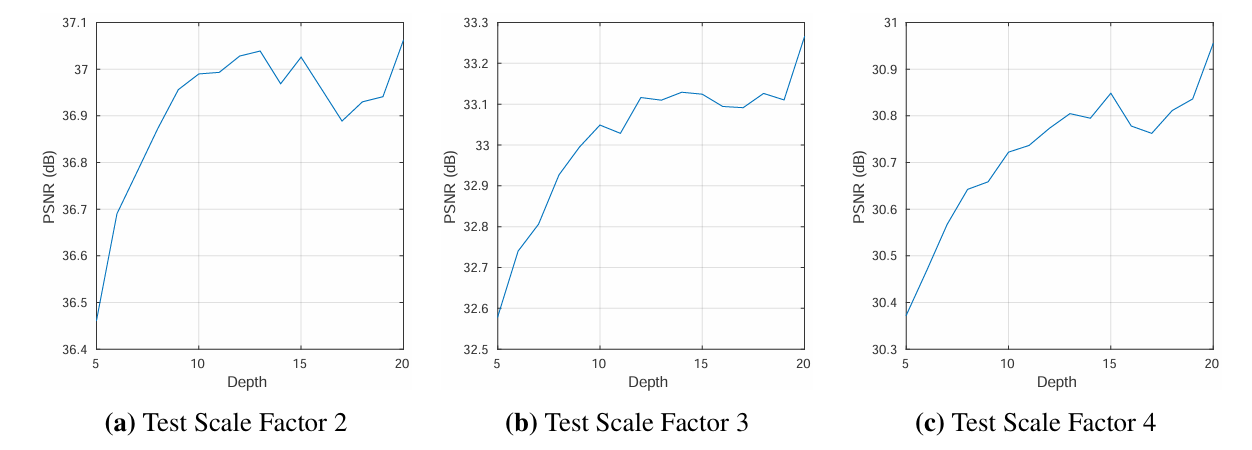
    이번에 살펴볼 논문은 VDSR이라는 모델 archiecture를 제안한 "Accurate Image Super-Resolution Using Very Deep Convolutional Networks", Kim et al., 2016 이다. 우리나
15.논문 리뷰(14)- Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
    이번에 살펴볼 논문은 SRGAN을 제안한 논문으로도 유명한 "Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network", Ledig et al.(2017
16.논문 리뷰(15) - Accelerating Image Super-Resolution Networks with Pixel-Level Classification
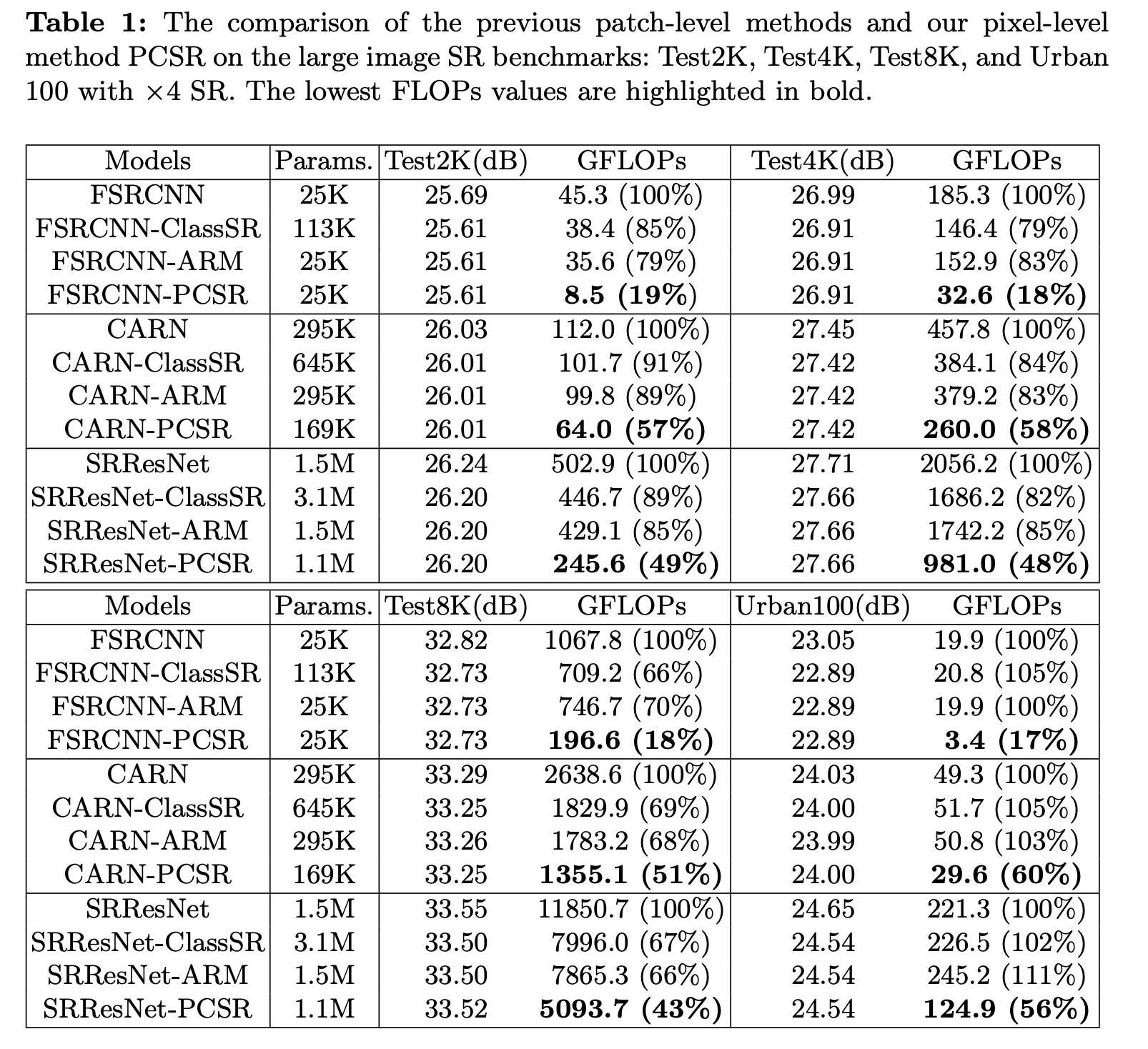
    이번 논문은 연세대학교 CIPLAB에서 ECCV 2024에 발표한 'Accelerating Image Super-Resolution Networks with Pixel-Level Classification'이라는 논문이다. 이 논문에서 다룬 모델의
17.논문 리뷰 (16) - [LIIF] Learning Continuous Image Representation with Local Implicit Image Function
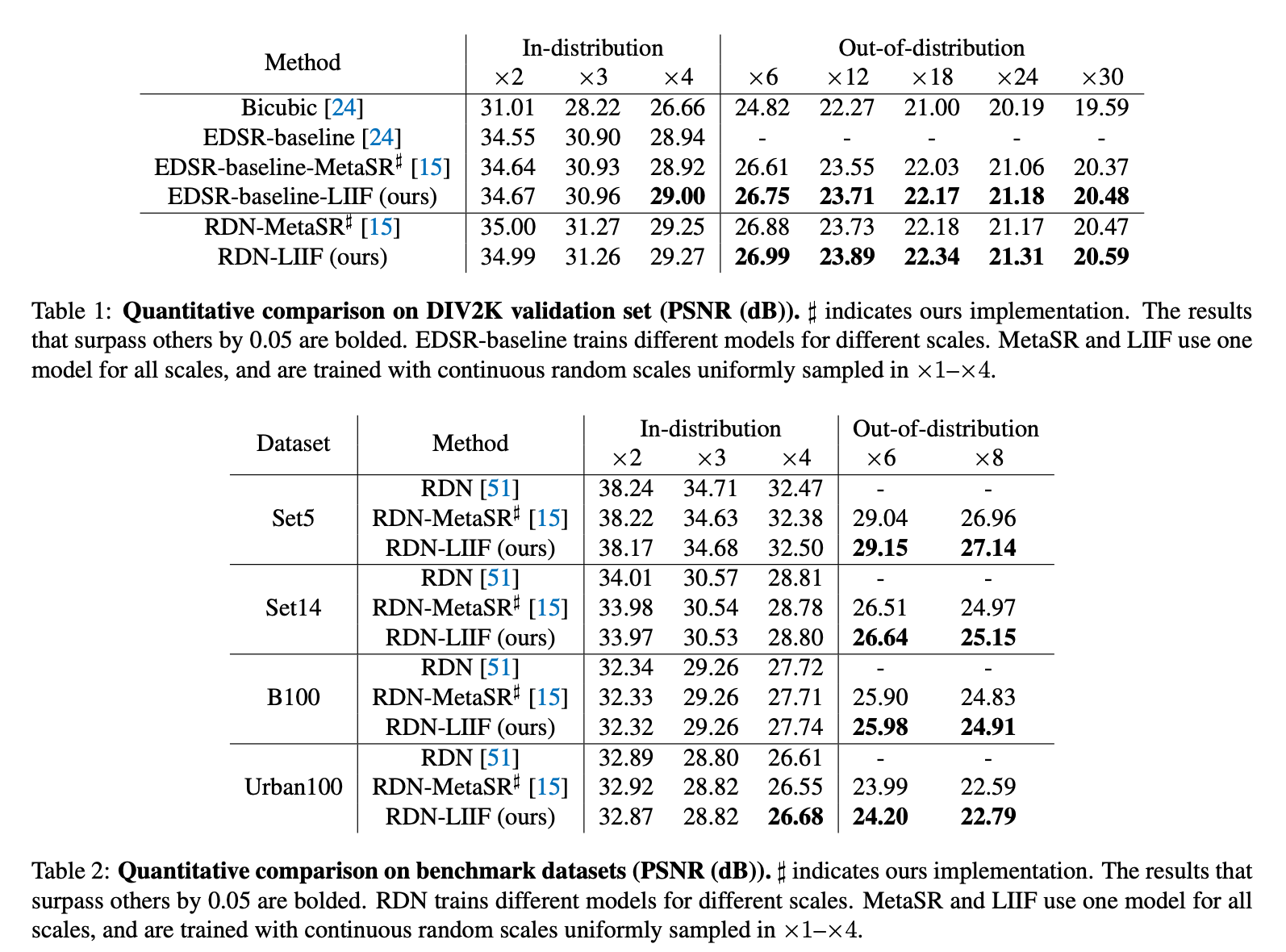
    이번에 살펴볼 논문은 LIIF로 유명한 'Learning Continuous Image Representation with Local Implicit Image Function'이라는 논문이다. 직전에 읽었던 PCSR 에서도 LIIF를 사용하는 등
18.논문 리뷰(17) - Fast, Accurate, and Lightweight Super-Resolution with Cascading Residual Network
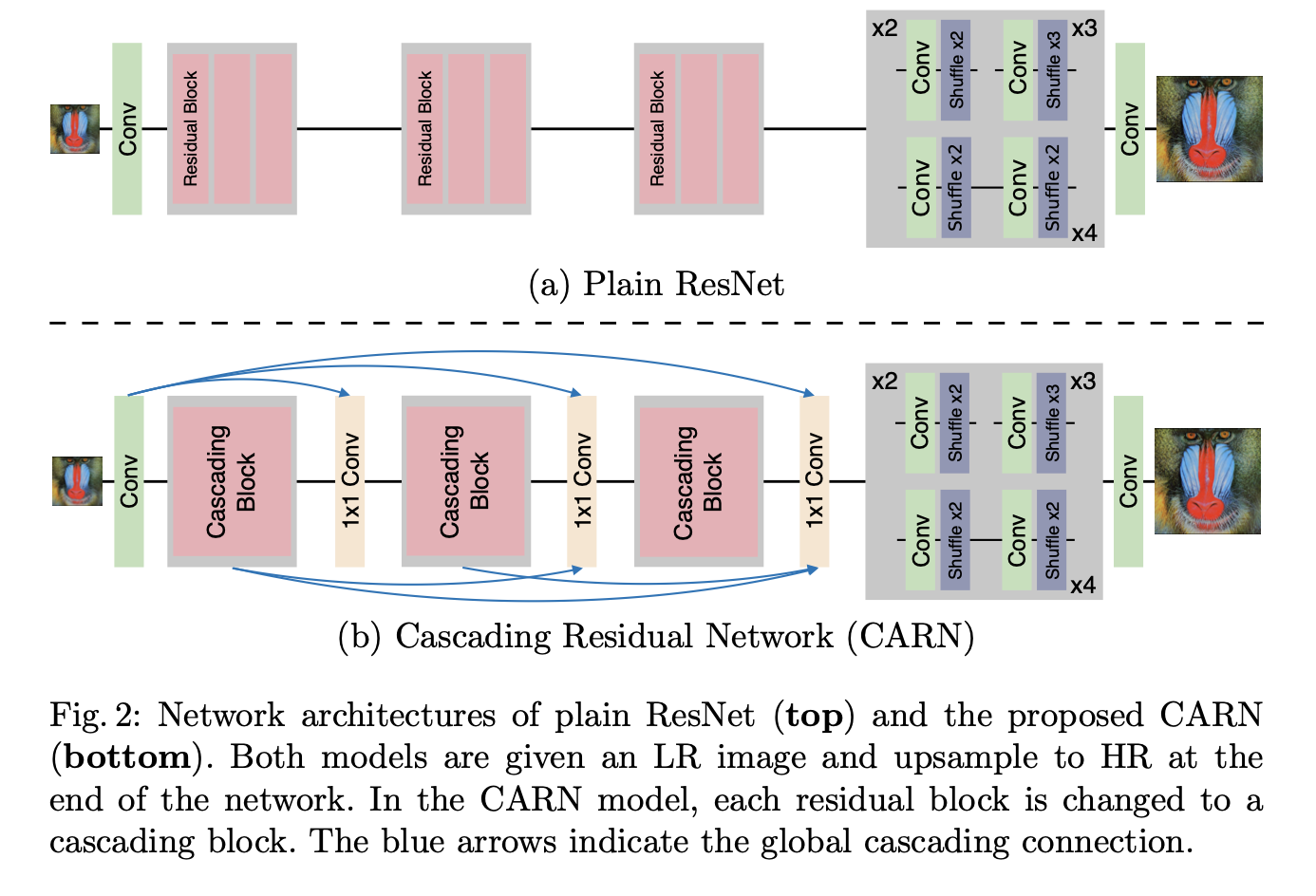
    이번에 살펴볼 논문은 CARN으로 유명한 'Fast, Accurate, and Lightweight Super-Resolution with Cascading Residual Network'라는 논문이다. 1. 저자가 이루려고 한 것 1) 기존 방법의 문제     기존의 방법들이 더 좋은 퀄리티, 높은 정확도의 SR을 가능...