1. 9강 복습
9강에서는 다양한 CNN Architecture들을 배웠다. 이번 강의에서 배울 RNN과 비슷한 효과를 가지는 ResNet도 배웠는데, ResNet은 skip connection이라는 것을 통해 gradient flow control을 가능하게 했다. 결과 값으로 F(x)+x가 나오기 떄문에, 만약 필요 없는 layer들의 weight를 다 0으로 초기화 한다면 identity의 효과를 내게 된다. (Residual block에서는 잔차인 F(x)만 학습하기 때문이다.) 이렇게 하면 skip connection에 의해 backward pass 시에 graident super highway의 효과도 얻을 수 있다. DenseNet과 FractalNet도 마찬가지로 identity path를 만들어 gradient flow가 원활하게 된다는 것에 이점이 있다.
2. RNN(Recurrent Neural Network)
오늘 배울 것은 RNN이다. 이전에 배운 CNN은 fixed input-> fixed output의 구조였다. 정해져 있는 크기의 input/output이라는 뜻에서 fixed를 사용하였다. 그중에서 CNN은 특히 이미지를 입력받아 classification에 이용하는 것에 특화되어 있었다. 말하자면 fixed input-> 1 output( label) 의 구조였던 것이다. RNN은 이것을 확장해서 one to one, one to many, many to one, many to many 들에 대해 다룬다. (input/output의 사이즈가 정해져 있지 않은 경우를 다루는 것이다.)
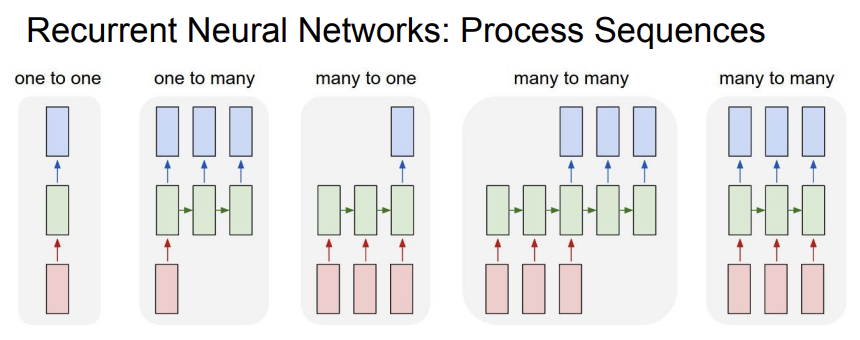
위의 사진의 가장 왼쪽은 vanilla neural network의 구조이다. 그리고 순서대로
1) one to many: ex) image captioning (image->sequence of words)
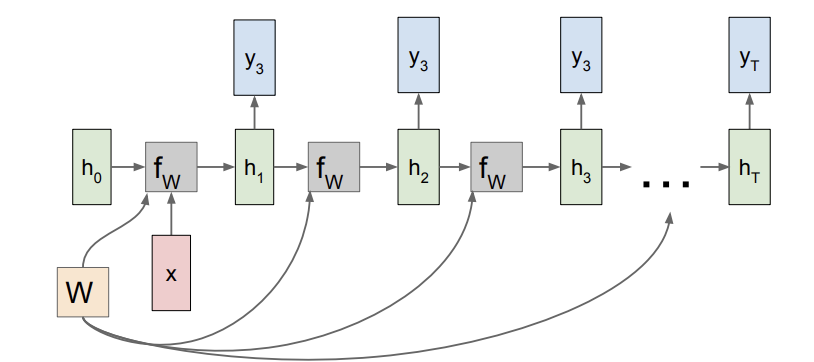
2) many to one: ex) sentiment classification(seqeunce of words-> sentiment) 행위,동작 분류
3)many to many: ex) machine translation(seq of words-> seq of words), video classification on frame level
을 나타낸다.
이렇게 RNN은 input과 output이 유동적일때 사용하면 유용하다.
3. RNN Architecture

RNN은 기본적으로 input을 읽고, hidden state를 update 시켜, output을 낸다. 이때 hidden state는 네트워크 내부에 존재하는 것으로(사진에서는 초록색 박스에 해당한다), outuput을 예측하는데 사용된다. 이를 식으로 표현한 것이 위 사진의 공식인 Recurrence formula다. h_t-1은 이전의 hidden state, x_t는 현재의 input이다. 이 두개를 f_w, 즉 weight parameter들을 이용한 식에 넣어 현재의 hidden state h_t로 update하는 것이다. 이러한 과정이 매 time step마다 일어난다. 이때 중요한 것은 매 time step마다 이용하는 weight parameter들은 전체 시간동안 공유된다는 것이다. 참고로 f_w는 tanh가 될수도 있고, 다른 식을 이용해도 된다.
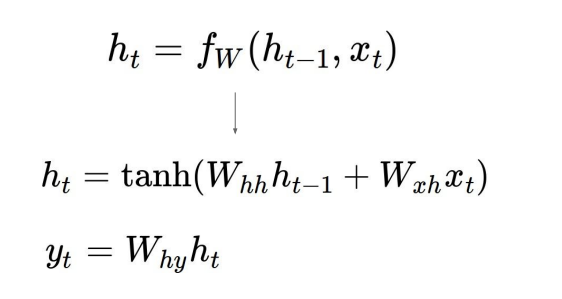
vanilla RNN의 경우, 위의 식을 이용해서 y를 예측한다. W_hh와 W_xh가 따로 정의되어 있는데, 각각 hidden state에 곱해줄 weight matrix, 그리고 input에 곱해줄 weight matrix라고 생각하면 된다. 마지막 단계에서 nonlinearity를 만들어준다.
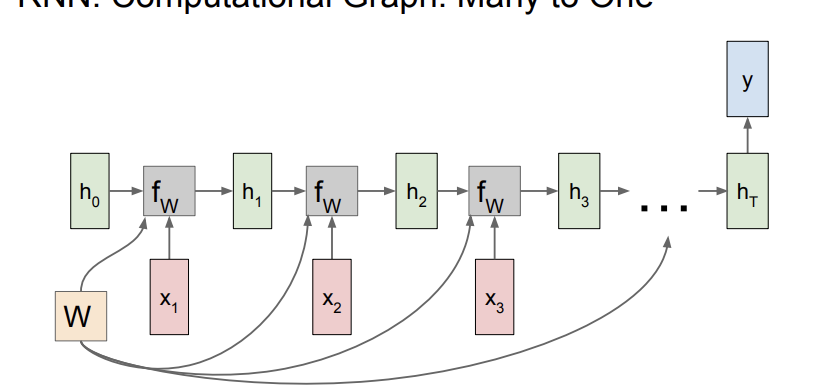
4. RNN Computational Graph
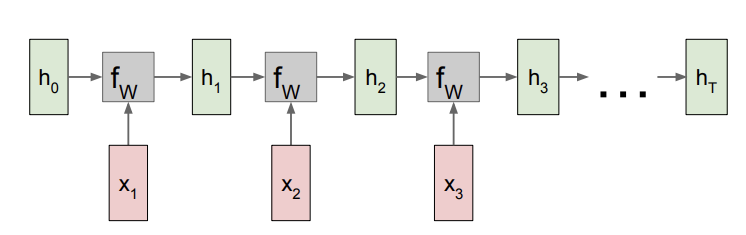
이러한 구조로 RNN이 작동한다. 가장 처음의 hidden state h0는 0으로 초기화하는 것이 일반적이다. 이때 f_w에서는 위에서 언급한 것과 같이 모든 time step에서 하나의 weight matrix를 이용한다.
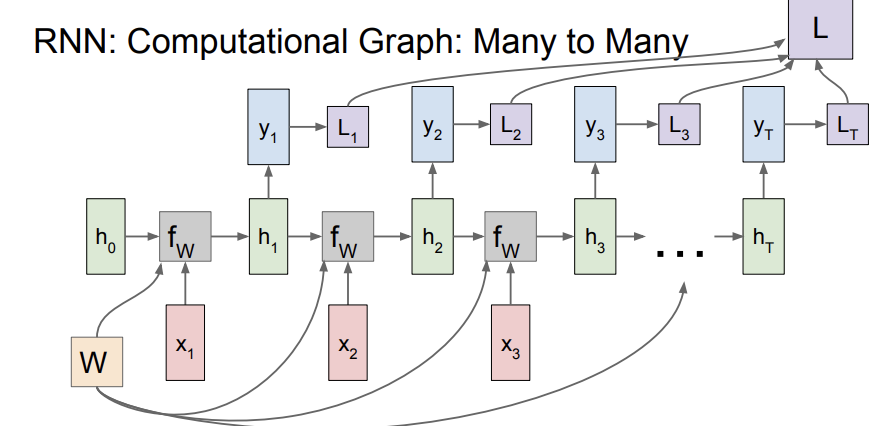
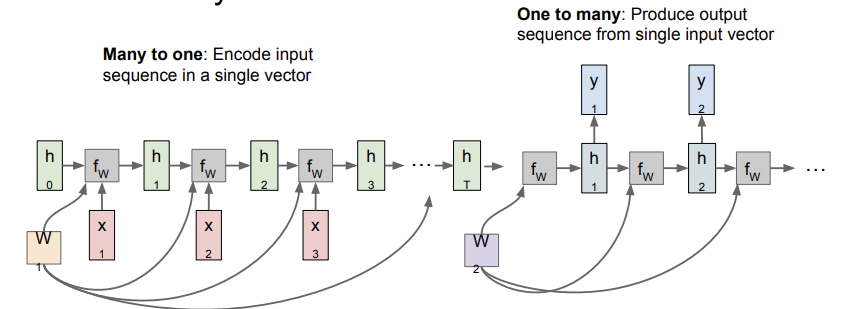
이 모델은 앞서 언급한 machine translation에 쓰인다고 한다. 이 모델은 many to one 후 one to many 를 적용한다. 따라서 결과적으로는 many to many의 효과를 얻는 것이다. many to one은 encoder의 역할, one to many는 decoder의 역할을 한다. encoder에서 하나의 벡터가 나오고, 이 벡터가 decoder로 가서 여러 개의 output을 생성하게 되는 것이다. 즉, machine translation의 예시로 살펴보면, 한글 문장이 들어가 하나의 벡터로 요약되고, 그 벡터를 이용해 다른 언어의 번역된 문장이 나오는 것이다. 이때 각 output에서 하나의 문장이 아닌 하나의 단어가 나오고, 이들이 합쳐져 문장이 되는 것이다.
5.Charcter Level Language Model
앞에서 본 개념들이 실제로 어떻게 사용되는지에 대한 하나의 예시가 Character Level Language Model이다. 살펴보자. 세부적인 사항들을 보기 전에 모델이 무엇을 이루려고 하는지부터 알아야 한다. 이 모델은 training 시에 input의 다음 글자가 무엇인지 예측하는 알고리즘을 학습한다. 그리고 나서 testing 때는 training 시에 만들어놓은 어휘들에서 sampling을 통해 output을 낸다. 조금 쉬운 말을 하자면, 훈련시에 우리가 원하는 단어들을 학습시켰으니, sampling을 해도 말이 되는 문장들이 나오지 않을까 싶은 것이다.
이제 구체적인 예시를 살펴보자. 이 모델에서 예시로 준 단어는 hello이다. hello라는 단어를 모델이 훈련할 때 어떤 식으로 배우는지부터 정리해야 한다. 가장 먼저, 단어를 구성하고 있는 알파벳 4(h,e,l,o)개를 one hot encoding (하나의 원소만 1이고 나머지는 모두 0으로 벡터를 만드는 방식)으로 나타내는 것이다.
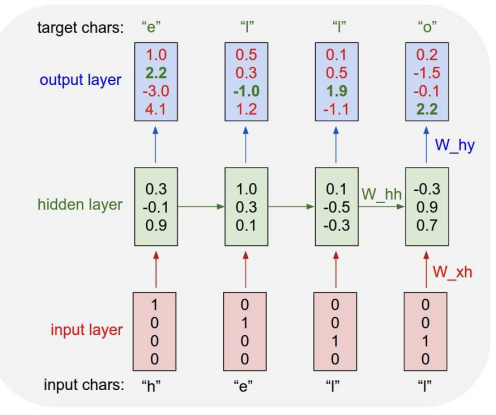
training 시에는, 단어의 각 글자들을 하나씩 input에 넣어준다. 첫 글자인 h를 넣으면 hidden layer를 통해 다음 글자인 e를 나오게 하는 것이 목적이다. e 다음에는 l, 그 다음에도 l.. 이런 식으로 나오게 하는 방식인 것이다. 이렇게 우리가 원하는 어휘들을 학습시킨다. 이 과정을 통해 모델은 '특정 글자 뒤엔 이 글자가 나올 가능성이 높구나' 에 대한 intuition을 얻는다. 이 intuition이 test time 때 sampling시에 도움을 주는 것이다.
위의 사진에서 첫 번째 input을 살펴보자. h를 넣었을 때 우리는 다음 글자로 e를 원한다. 그러나 output layer에서 보면, e의 자리는 2.2인데, o 자리에 score가 4.1이다. 정답값이 오답값보다 작기 떄문에, softmax loss를 통해 이 숫자들은 업데이트 되어 결과적으로 e 자리의 숫자가 가장 크게 될 것이다.
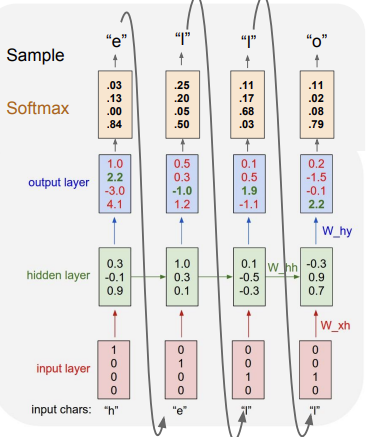
우리가 살펴본 예시만 보면, RNN이 간단한 모델이라고 생각할 수 있다. 우리는 이해를 위해 vocabulary도 h,e,l,o 밖에 안 썼고, 단어도 하나만 만들었다. 그러나 실제로는 한 단어만 만들지 않고, layer 또한 엄청 많아진다. 그렇기 때문에 이러한 방식은 back prop시에 시간이 너무 많이 걸리고, 복잡도 또한 높다는 문제가 있다. 이전에 SGD 알고리즘에서 있던 문제점과 유사하다. 그래서 실전에서는 mini batch learning과 같은 느낌으로 training을 진행한다.
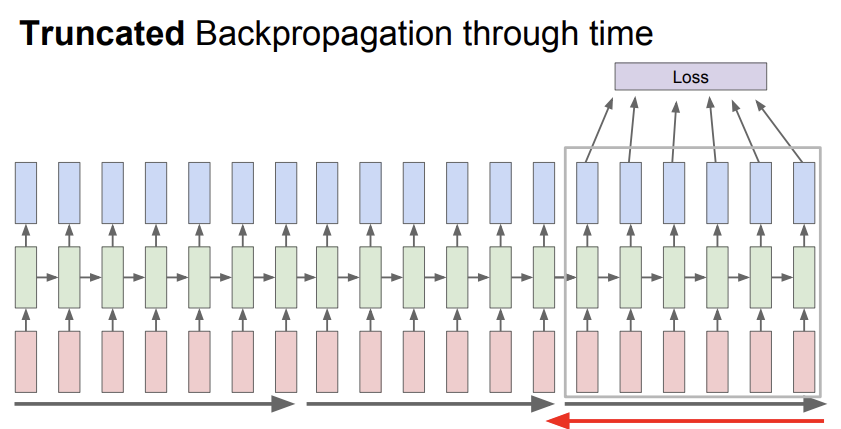
이를 Truncated backpropagation이라고 하는데, 일종의 gradient approximation이다. forward pass 시에 일정 단위(일반적으로 100개)의 time step씩 묶어서 loss를 계산한다. backprop 또한 batch 내에서만 진행하고, 다음 batch로 넘어가는 것이다. 강의에서는 subsequence라고 표현했는데, mini batch와 같은 느낌이라고 보면 될 것 같다. 다음 subsequence를 계산할 때는 이전의 subsequence에서 얻은 hidden state를 이용한다.
이 방법은 그냥 backprop하는 것보다는 시간을 많이 절약할 수 있다.
지금까지 배운 것들을 통해 셰익스피어 작품과 비슷한 글들을 만들 수도 있다.

위 사진처럼 처음에는 무슨 뜻인지 전혀 알 수 없다가, 훈련을 거듭할수록 얼추 글 같은 형식을 갖추어 출력되는 것을 볼 수 있다.

결과적으로 이 정도 수준의 글은 얻을 수 있었다고 한다. 이와 마찬가지로 수학 교과서를 훈련할 때 학습시켜 모델이 알아서 수식을 증명하고 결론까지 내는 것도 볼 수 있었다.(물론 정확하진 않지만 얼추 구색은 갖춘 형태였다.) C언어를 학습시켜 코드를 뱉어내는 것도 RNN으로 가능하다고 한다.
늘 그렇듯이, 이렇게 모델이 성능을 어느정도 낸다면, 어떤 cell들이 어떤 부분에 영향을 미치는지에 대한 intutition을 얻고 싶어진다. CNN 때 '특정 feature들은 oriented edge를 탐색하는구나'와 같은 intution을 말하는 것이다. RNN의 경우에는 hidden state들이 어떤 역할을 하고 있는지 살펴보아야 한다.


이렇게 따옴표를 인식하는 cell, 코딩에서 indent를 다루는 cell, if문을 다루는 cell 등 hidden state가 하고 있는 역할들을 볼 수 있다.
6. Image Captioning
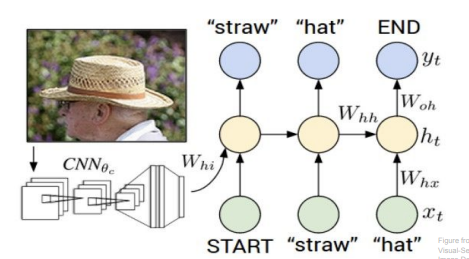
Image Captioning의 경우, input으로 영상이 들어오고, output으로는 문장이 나가는 형태의 문제이다. 문장의 길이가 상황별로 달라질테니, RNN을 쓰는 것이 유리하다. 일단 사진에 CNN을 태워서 feature들을 담은 summary vector를 얻는다. 그리고 나서 RNN의 input으로 주는 것이다. 단, classification을 하려는 목적으로CNN을 사용하는 것은 아니기 때문에 FC-4096으로 끝낸다. RNN은 받은 summart vector를 이용해 각 time step의 output에 단어들을 출력해 낸다.
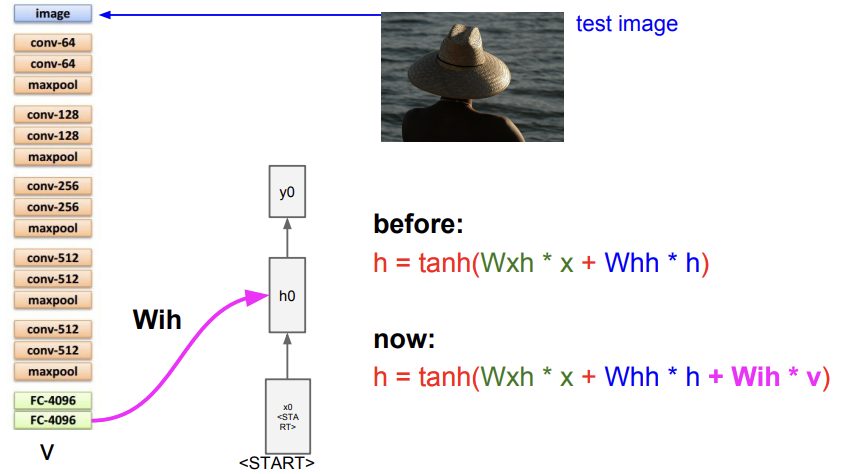
훈련이 끝나고 Test time 때도 image를 CNN에 태운 후에 얻은 정보를 RNN에게 전달해준다. CNN에서 얻은 정보를 v라고 하면 Wih를 곱하고,이를 더해줘 h의 update에 반영하는 것이다.
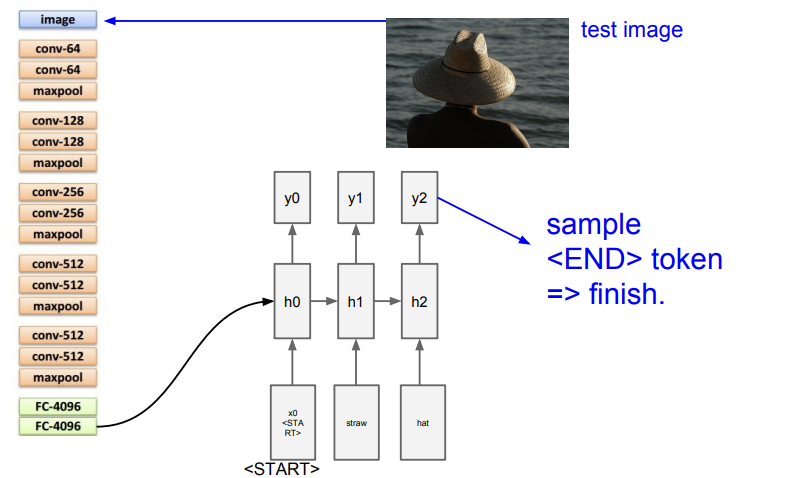
이후에는 앞에서와 같은 방식으로 sampling을 통해 다음에 나올 단어들을 예측하고, 언제 caption 생성이 끝날지 모르니 END 토큰을 통해 caption 생성이 끝났음을 알려준다. 그러나 Image Captioning이 항상 제대로 작동하는 것은 아니다. 사진에서 사물을 잘 인식하지 못하는 경우도 발생한다.이런 문제를 해결하고 조금 더 발전된 모델이 Image Captioning with Attention이다.
7. Image Captioning with Attention
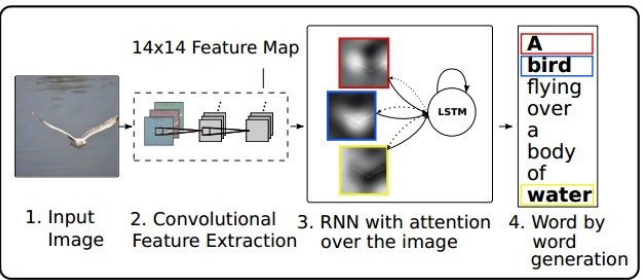
여기서 Attention은 image의 특정 부분을 더 자세히 보겠다는 의미이다. Spacial location이 고려되는 것이다.
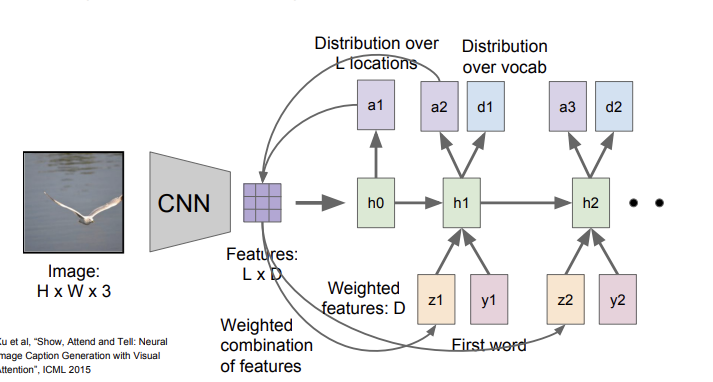
원래의 Image Captioning 모델의 CNN에서는 feature를 설명해주는 벡터가 하나만 얻었다면, 이제는 spacial information을 포함하는 벡터들의 grid를(행렬)을 얻는다. 그리고 output에서도 원래 y만 뽑았다면, 이제는 spacial information의 분포를 담고 있는 a와 단어에 대한 분포를 담고 있는 d를 함께 뽑는다. 그리고 input을 넣을 때도 이전의 output y와 feature 정보인 z를 함께 넣어준다.

training 이후 모델은 caption을 생성하기 위해 이미지의 특정 부분을 돌면서 탐색하는 것을 볼 수 있다. soft attention은 모든 영역을 골고루 보는 것이고, hard attention은 특정 영역에 집중해서 보는 방법이다. 이러한 방법은 Visual Question Answering에도 쓰인다.

이렇게 모델의 caption 생성을 할 때 나름 중요한 부분에 집중하는 것을 확인할 수 있다.
8. RNN Gradient Flow
실전에서는 RNN layer를 여러 개를 사용한다. 보통 2~4개의 layer를 많이 사용한다. 이 경우, 이전 hidden state의 output이 다음 hidden state의 input이 된다. 아래는 3 layer RNN의 구조이다.
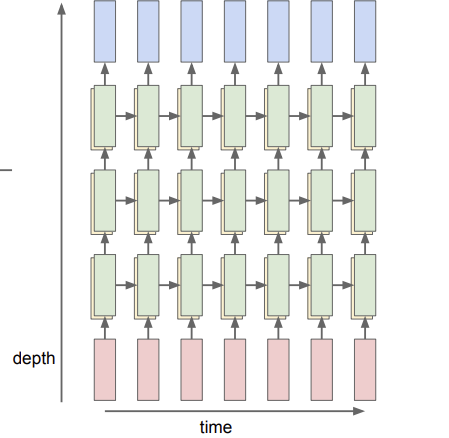
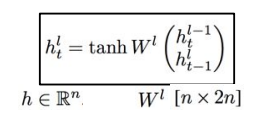
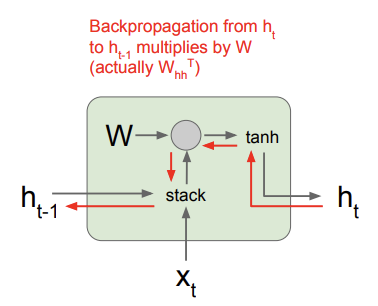
위 사진은 일반적인 vanilla RNN gradient flow를 표현한 것이다. 이 모델의 backprop은 빨간색 경로를 따라갈 것이다. backprop 과정을 살펴보면, cell로 들어오는 gradient 값은 이고, cell에서 나가는 gradient는 이라는 것을 알 수 있다. 그리고 그 중간에 matrix multiplication gate가 있는데, matmul gate의backprop은 weight matrix의 transpose를 곱해준 값이라고 한다. 과제를 하면 알 수 있다는데, 아직 안해봐서 왜 그런지는 정확히 모르겠다. 어쨌든 여러 cell들을 지나 아래 사진과 같이 빨간 선을 따라 backprop이 이루어지는 것이다. 그때마다 W를 계속 곱하다 보면, 와 같은 gradient를 구할 때의 계산적인 복잡도도 높아진다.
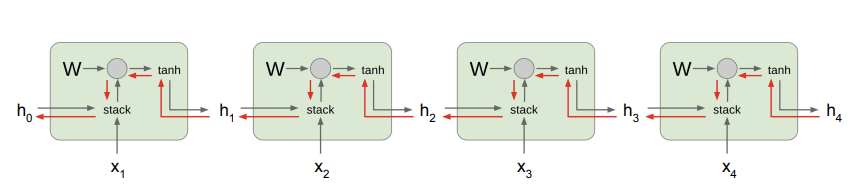
그리고 vanishing/expolding gradient problem 이 일어날 수도 있다. hidden state가 많아져 100개정도 된다고 가정해보자. 만약 W의 singular value가 1 이상이라면, 100개의 layer를 지나면서 expolding gradient problem이 일어날 수도 있다. 반대로 W의 singular value가 1 미만이라면, layer들을 지나며 vanishing gradient problem이 생길 것이다. 두 케이스 모두 제대로 된 update에는 좋지 않다. exploding gradient 같은 경우는 Thresholding을 통해 방지할 수 있다. gradient clipping이라고도 하는데, 만약 gradient가 너무 크다면(threshold 값 이상이라면) 그냥 gradient를 threshold 값으로 하고, gradient가 threshold값 미만이라면 원래의 gradient를 쓰는 방법이다. 반대로 vanishing gradient problem은 RNN의 구조를 살짝 바꿔서 해결할 수 있다. 이렇게 도입된 것이 LSTM(Long Short Term Memory) 이다.
9. LSTM
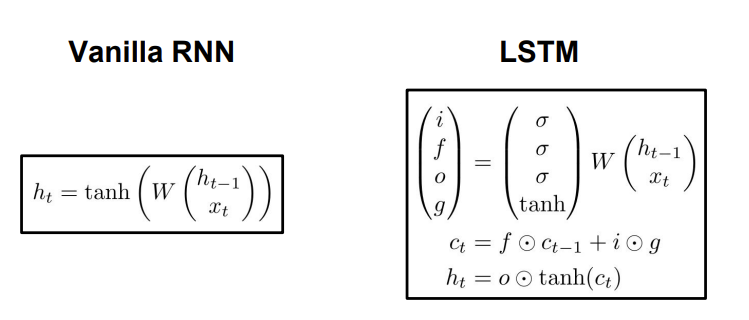
LSTM은 원래 배웠던 Activation function인 sigmoid와 tanh, 그리고 를 이용해 4개의 gate를 계산한다. 4개의 게이트는 gate인데, 각각의 gate가 무엇인지 살펴보자.
1) (input gate): cell에 쓸지 말지를 결정하는 gate
2)(forget gate): cell을 지울지 말지를 결정하는 gate
3)(output gate): cell을 얼마나 공개할지(reveal) 결정하는 cell
4)(gate gate): cell에 얼마나 쓸지 결정하는 cell
gate는 범위가 sigmoid 함수가 곱해지기 때문에 0부터 1이고, gate는 함수가 곱해지기 때문에 범위가 -1부터 1이다.
그렇다면 이 4개의 gate들이 어떤 구조로 이용되는지 위의 사진 속 식을 통해 알아보자.(c는 cell state를 뜻한다.) 현재의 cell state를 결정하기 위해 이전의 cell state에 지울건지 말건지 결정하는 를 곱해준다. 그리고 input과 input에 대한 가중치를 나타내는 를 곱해주고, 이 두 식을 더해 현재 cell state인 를 결정하는 것이다. 는 cell state를 에 태운 후 hidden state를 얼마나 공개할 것인지 결정하는 가중치 o를 곱해줘서 구한다. 확 와닿지는 않지만 얼추 이해가 가기는 하는 것 같다. 이런 구조를 만든 것은 backprop할 때 matrix multiplication을 피하기 위해서이다. 이걸 피하고 elementwise multiplication으로 만들면 계산하기가 훨씬 수월하기 때문이다.
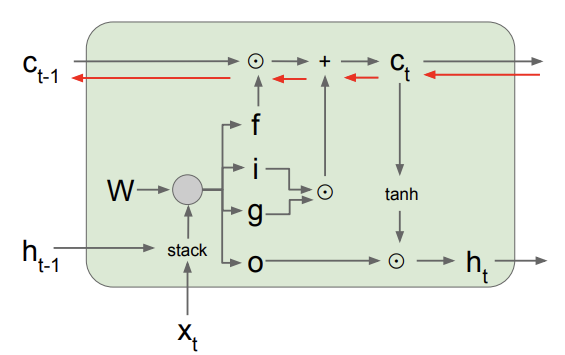
위의 사진처럼, 이제는 backprop을 할 때 add gate와 element multiplication 밖에 없다. backprop 과정이 더욱 간단해진 것이다. 따라서 여러 hidden state들이 있을 때도 gradient flow control에 용이하다. 약간 ResNet의 skip connection과 비슷한 면이 없잖아 있는 것 같기도 하다.
10. 결론
이번 강의에선 AI를 하면서 한번씩 들어봤던 LSTM이나 RNN 등을 알아볼 수 있었다. 솔직히 이것만으로는 이해가 완벽히 되지는 않아서 논문을 찾아서 읽어봐야 될 것 같다.
