1. 7강 복습
8강은 Deep Learning Software에 관한 내용이라 정리를 생략한다. 7강에서는 SGD의 문제점과, 각종 최적화 방법들에 대해서 배웠다. 그 중 가장 많이 사용하는 것은 Adam optimizer였다. 또, model ensemble을 이용해 training score와 validation score의 차이를 줄일 수 있었다. Dropout이라는 regularization 방법도 overfitting을 줄일 수 있는 테크닉 중 하나였다. 이번 강의에서는 그 동안 연구된 CNN 모델들에 대해 배운다. 등장한 순서대로 다룰 것이다.
2. LeNet
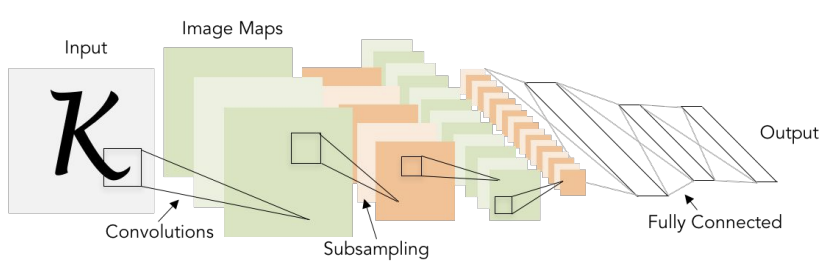
LeNet은 가장 처음에 나온 CNN 모델들 중에 하나이다. Conv Layer에서는 filter size=5x5, stride=1로 설정되었고, Pooling layer에서는 size 2x2, stride=2를 적용하였다.
3.AlexNet
AlexNet은 당시 이전의 네트워크들을 성능면에서 압도한 최초의 large scale network이었다.
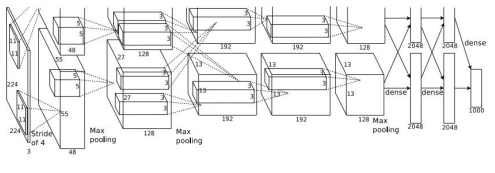
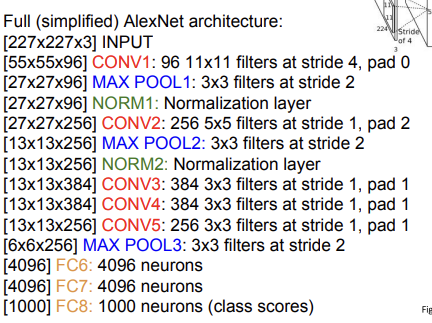
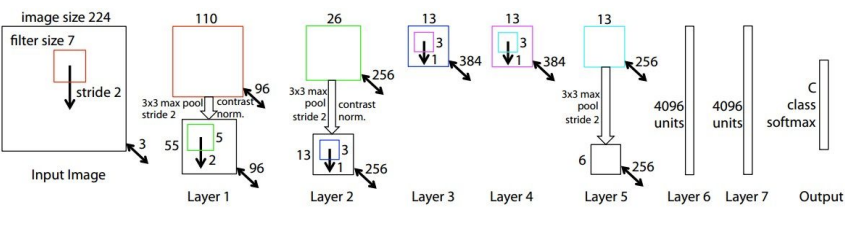
Architecture는 Conv1-Max Pool1-Norm1-Conv2-Max Pool2-Norm2-Conv3-Conv4-Conv5-Max Pool3-FC6-FC7-FC8 형태이다. 논문에서는 227x227x3 크기의 input image를 넣었다. 이 경우 각 layer에서의 output size를 몇 개만 살펴보자. 이전에 배웠던 공식 을 이용하면 편리하다.
1) Conv1-(96개의 11X11 filter, S=4)
number of params= =35K (input channel=filter channel)
위의 식을 설명하자면, 파라미터 수는 kernel 1개당 11*11이고, 각 kernel은 채널이 3개씩 있으므로 3을 곱해주어야 한다. 또, 그 kernel이 96개 있으니 96도 곱해주면 된다.
2) Pool1 (3x3 filter, S=2)
여기서 주의해야 할 것은 pooling layer는 parameter가 없다는 것이다. 또한, pooling layer는 depth를 보존해준다. 쉽게 말해 크기만 줄이지, depth는 건드리지 않는다는 소리다. 이런 식으로 output size와 parameter 계산을 할 수 있다.
Retrospective/Details
-ReLU를 처음 사용
-Norm Layer 사용(이웃 채널간의 response를 normalization 하는 layer)-> 현재는 잘 사용하지 않음.
-data augmentation 많이 사용
-dropout=0.5, batch size=128, SGD Momentum=0.9, lr=1e-2, validation accuracy plateau시 1/10으로 줄임.
-L2 weight decay 5e-4
-7 CNN ensemble-> 성능 향상 효과
※주의
-input channel= filter channel
-filter 개수= output 차원(depth) 개수
-pooling layer는 parameter가 없고, input data의 depth를 건들진 않는다.
-1개의 filter는 1개의 activation map(feature map)을 만든다.
4. ZFNet
AlexNet 이후에 나온 모델로, AlexNet의 hyperparamer에서 개선이 있었다. 구체적으로, AlexNet의 Conv1 filter가 11x11, S=4였던 것을 filter= 7x7, S=2로, Conv3,4,5에서 filter 개수를 512, 1024, 512개로 바꾸었다. 결과적으로 성능이 AlexNet보다 더 좋아졌다. 이 다음부터는 네트워크가 더 깊어지기 시작한다.
5.VGGNet
VGG는 fiter size를 줄이고, 네트워크를 더 깊게 만들었다. 8개의 Layer였던 AlexNet에 비해 VGG는 16개 혹은 19개의 layer로, 훨씬 더 많은 layer를 가진다. (layer의 개수에 따라 VGG16, VGG19이라고 부른다.)
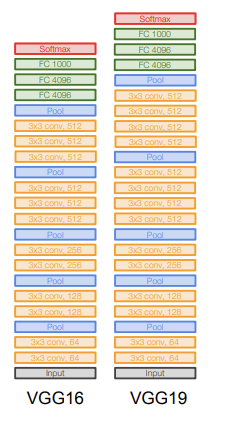
가장 크게 달라진 점이라고 하면 Conv1에서의 filter size가 작아졌다는 점이다. 11x11 filter를 쓰던 AlexNet에서와는 다르게 VGG는 3x3 filter를 사용한다. 더 작은 필터를 사용하는 것은 효율적인 receptive field를 가지도록 하기 위해서이다. Receptive field는 하나의 픽셀이 관장하는 영역을 뜻한다. 예를 들어보자. 3x3 filter 3개를 쓰면 7x7 filter 1개를 쓴 것과 같은 효과가 난다.
위의 말만 듣고는 Receptive field에 대해 명확히 개념을 이해하기 힘들기 때문에 더 자세히 설명해보겠다. 아래 사진은 맨 오른쪽부터 왼쪽으로 차례차례 봐야한다. 가장 오른쪽의 1x1이 우리가 CNN을 통해 얻은 output인 것이다. 물론 실제로는 1x1보다 당연히 크게 나올 것이지만, 우리는 지금 output에서의 하나의 픽셀이 CNN의 초반에 얼마나 영향을 미치는지가 알고 싶은 것이다. 어쨌든, 그 왼쪽에 있는 3x3을 보자. 가장 쉽게 이해하는 방법은 3x3 크기의 filter가 output layer의 1x1 픽셀을 만들었다는 것이다. 즉, 총 9개의 픽셀이 다음 layer의 픽셀 1개를 만드는데 사용되었다는 것이다. 이런 식으로 생각하면, 우리가 지금 보고 있는 3x3 영역도 그 전의 5x5 크기의 픽셀들에 필터가 씌워져서 만들어졌을 것이고, 그 다음도 마찬가지이다.
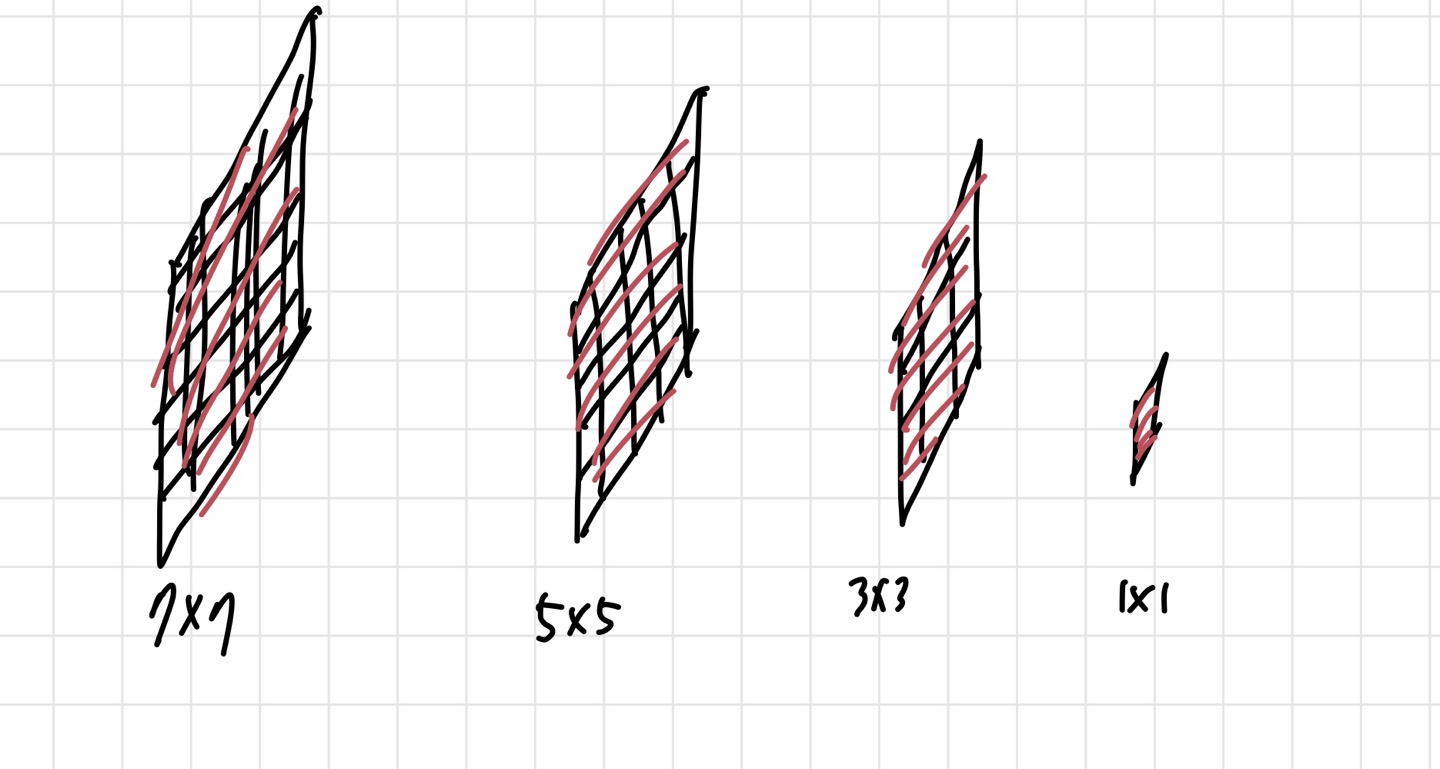
어쨌든 여기서 하고 싶은 말은 3개의 3x3 filter를 쓰는 것이 7x7 filter 1개 쓰는 것보다 효율적이라는 것이다. 더 효율적인 이유는 parameter 수가 더 적기 때문이다. 같은 receptive field를 만드는데 더 적은 parameter를 사용하였다면, 안 쓸 이유가 없다.
이제 VGG에 대해 더 자세히 살펴보자. 결론적으로 VGG는 이러한 구조로 좋은 결과를 얻을 수 있었다. VGG는 앙상블을 사용할 경우 더 좋은 결과를 낼 수 있고, 보통 VGG16과 VGG19 중에서는 16을 더 많이 사용한다. 19가 16보다 parameter 수가 더 많은 것에 비해 정확도의 차이가 그닥 없기 때문이다. 또한, FC7의 feature들은 다른 task에도 잘 사용될 수 있다고 한다.
6.GoogLeNet
GoogLeNet의 가장 큰 목적은 효율성 높이기였다. 정확히 말하자면 Computational Efficiency를 높인 것이다. 22개의 layer를 가지고, FC layer가 없는 것이 특징이다. 또, parameter 수도 AlexNet보다 12배 정도 적기 때문에 효율성이 늘어난다. 효율성을 늘릴 수 있었던 이유는 Inception module이라는 것을 사용하기 때문이다.
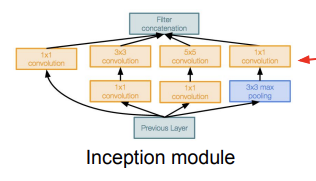
Inception Module은 네트워크 속의 네트워크를 만든 것이다. 이 Inception Module들이 쌓여서 네트워크를 구성한다.
1) Naive Inception Module
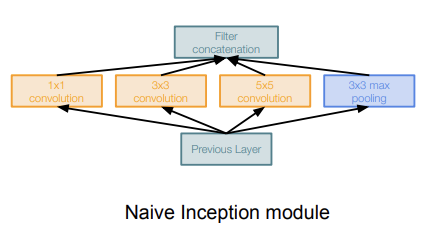
Naive Inception Module은 parallel filter를 사용하고, 여러개의 filter의 output을 depth-wise concatenation한다. 그러나 이렇게 하면 계산의 수가 엄청나게 많아진다. 아래 사진에서 보이듯이, 하나의 inception module을 계산하는데 필요한 계산 수가 854M정도이다. 그렇기 때문에 이런 방법은 비용적인 측면에서 손해이다. 또, 여러 layer를 거치며 output의 depth가 커지기 때문에 갈수록 더 힘들어질 것이다. 이것을 그나마 해결하기 위해 1x1 convolution을 사용한다.
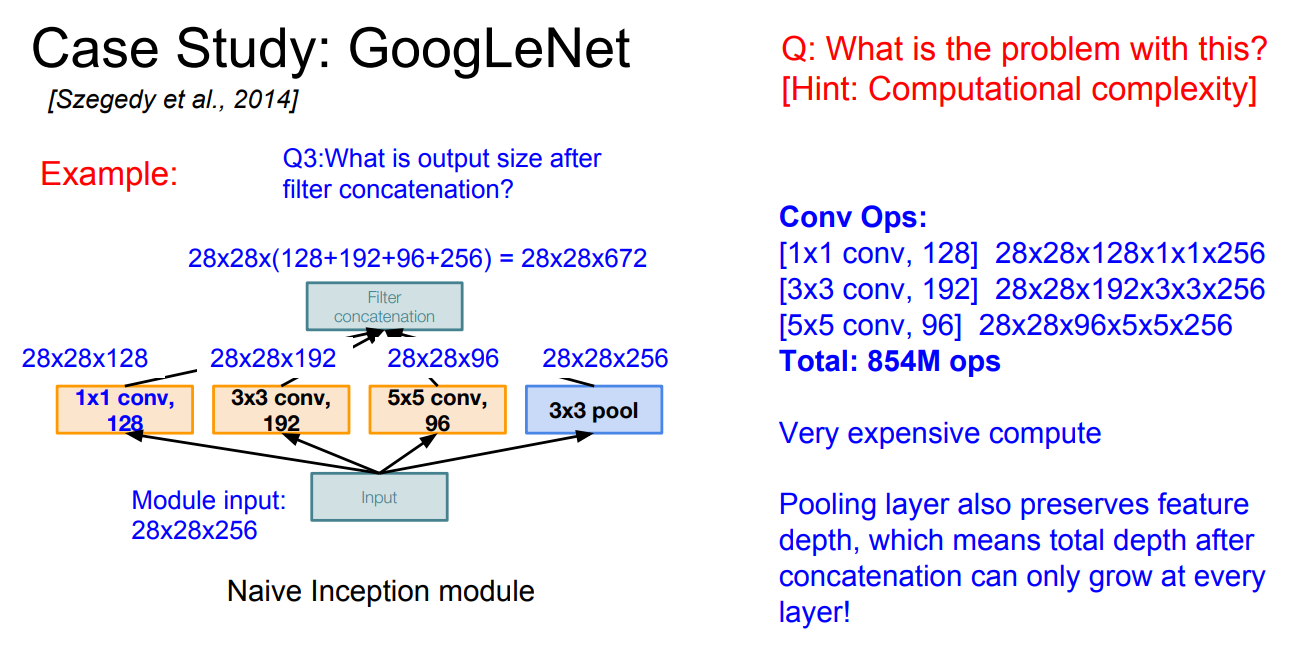
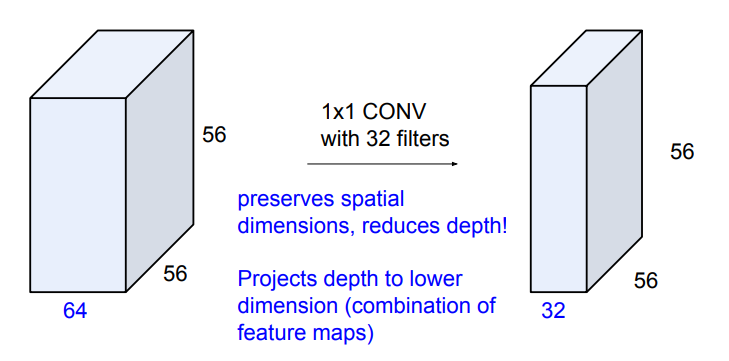
1x1 convolution은 channel 개수를 줄여주는데 효과적이다. filter 개수가 output의 depth이니, filter 개수로 channel들을 조절해주는 것이다. filter size=1x1이라서 width와 height에는 영향을 주지 않는다.
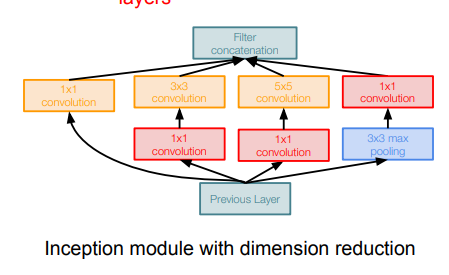
pooling layer는 depth를 보존하기 때문에, layer가 거듭될 수록 차원이 증가할 것이다. 그렇기 때문에 pooling layer에 1x1 convolution을 사용해 depth를 줄여준다. 다른 layer들에도 1x1 convolution을 적용해 Naive module보다 computational complexity가 줄어든다. 이런 layer들을 bottleneck layer라고도 하고, 사진에서는 빨간색 박스들에 해당한다.
GoogLeNet은 이렇게 만들어진 Inception Module들이 쌓여 구성된다.
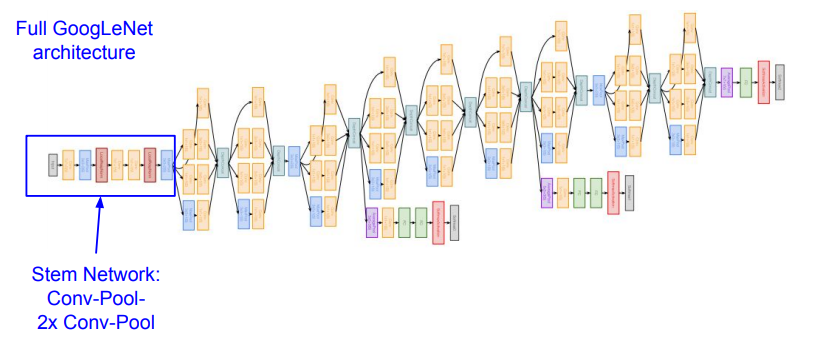
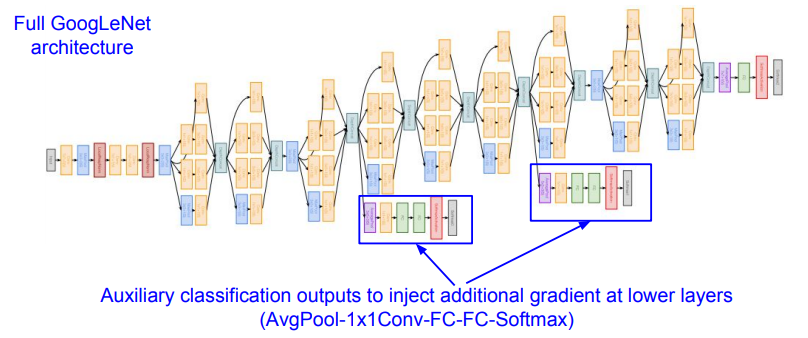
구조를 보면 Auxiliary classification output이라는 표현이 나온다. layer 수가 많다 보니 update때 backprop값을 정확히 반영되지 못할 수 있다. 이런 현상을 막기 위해 위해 보조적으로 output을 뽑는 것이다. 따라서 최종적으로 classification을 할 때는 2개의 보조 output과 1개의 output을 같이 보고 판단하게 된다.
7. ResNet
residual(잔차) connection을 이용한 deep network이다. ResNet은 ImageNet에 대한 모델로 152 layer짜리 모델을 내놓았다. ILSVRC에서 classification과 detection 부문에서 모두 엄청난 성능을 냈다. CNN layer들을 계속 쌓다보면 아래 사진과 같이 그래프에서 이상한 점이 발견된다.
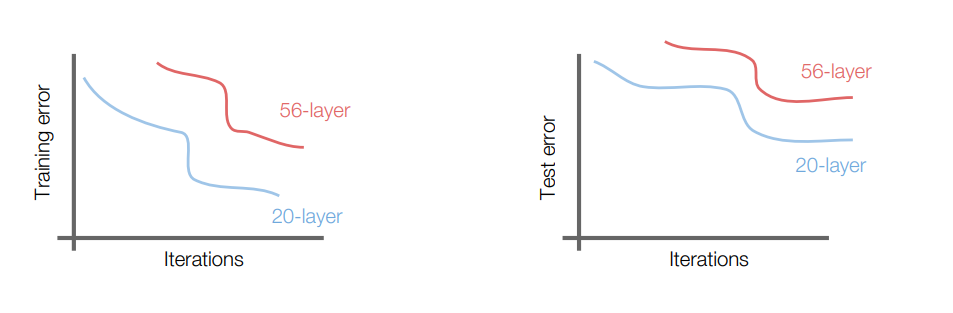
그래프를 보면, 56-layer 모델의 training error와 testing error 모두 20 -layer 모델보다 안 좋게 나왔다. Overfitting의 문제도 아니었다. 논문 저자들은 이를 optimization problem일 것이라고 가설을 세웠다. 직관적으로 생각해보면 layer가 깊어질 수록 더 성능이 좋아져야 하는데, 그렇지 못했다. 그래서 해결책으로 등장한 것이 residual block이다.
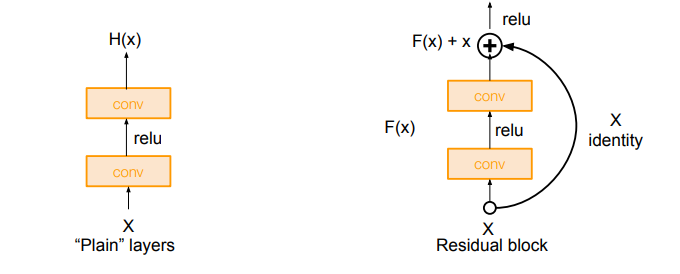
residual block은 원래 하던 것처럼 예측값을 정답값인 y에 최대한 가깝게 하는 것보다, 잔차인 에 fitting을 시키자는 아이디어에서 나오게 되었다.(는 우리가 얻고자 하는 이상적인 값이다.) residual block에서 를 더해주는 곡선의 선을 skip connection이라고 한다. skip connection은 가 들어갔을 때 가 나오게 해준다. 우리는 이걸 도입한 이유에 대해 생각해봐야 한다. 왜 하필 로 정했을까? 왜냐하면 에 가까운 값이라고 생각할 수 있기 때문이다. layer가 깊어진다면, intermediate한 값들은 서서히 바뀌는 것이 좋을 것이다. 즉, layer 28와 layer 30의 output 값의 차이는 그닥 많이 나지 않을 것이라는 소리이다. 이러한 이유에서 근처 값이라고 생각할 수 있다.
라는 가정을 하는 이유를 알았으니, 이제 다시 잔차 로 돌아가보자. 이므로, 는 0 근처의 값이 될 것이다. 를 0 근처의 값으로 만드려고 이렇게 먼 길을 돌아온 것이다. 0 근처의 값으로 만드는 것이 장점이 되는 이유는 우리가 맨날 만들던 weight matrix의 초기화 방법인 Xavier, He가 0 근처의 값으로 초기화되기 때문이다. 우리가 하던 방법이라 더 쉽다. 에 fitting시키는 것이 그래서 좋은 것이다.
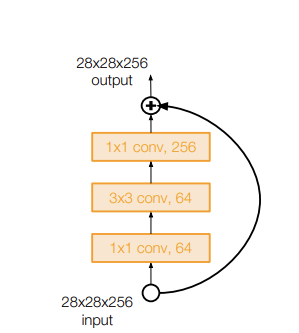
ResNet은 skip connection을 포함하고 있는 Residual Block을 겹겹이 쌓은 것이다. 아래 구조에서도 볼 수 있듯이, 하나의 residual block은 2개의 3x3 conv layer로 구성된다. 그리고, 일정 간격마다 filter 수를 2배로 늘리고, downsampling을 진행한다.(S=2)
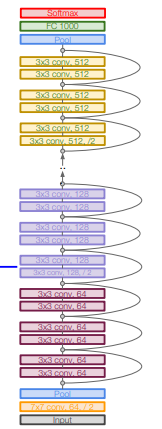
input 다음에 Conv layer를 추가한 것도 하나의 특징이다. 또, FC layer가 output 직전에 class 개수 맞춰주기 위해 하나 있는 것 빼고는 없다는 사실 또한 짚고 넘어갈 부분이다. layer가 50개 이상이 된다면, residual block 앞에 bottleneck layer(앞서 언급했던 1x1 conv layer를 이용해 채널 수를 줄여주는 것이다.)를 삽입해서 복잡도를 조금 낮출 수 있다.
실전에서 ResNet training을 할 때의 주의사항
-BN을 모든 Conv layer 뒤에 해준다.
-Xavier/2 initialization을 해준다.
-SGD+Momentum=0.9
-lr=0.1, validation error plateau할 때마다 1/10배로 줄임.
-Mini batch size=256
-Weight decay=1e-5
-Dropout은 사용 x
8. 비교
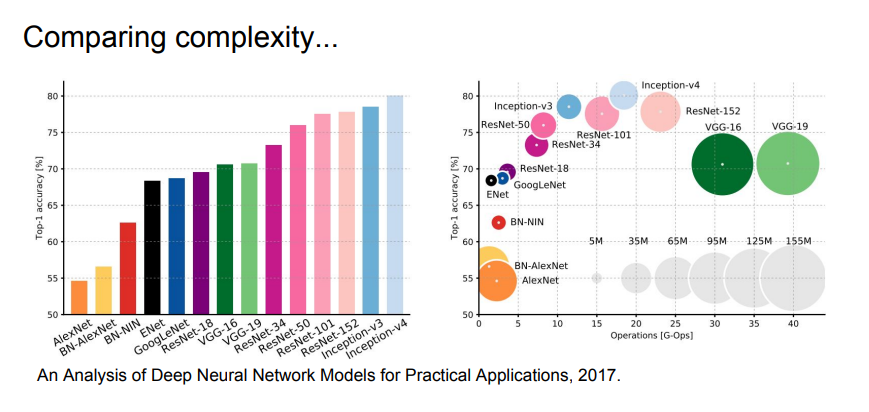
위 사진은 모델들의 정확도와 복잡도를 비교한 것이다. 왼쪽 그래프가 정확도, 오른쪽 표가 정확도와 복잡도를 비교한 것이다. 오른쪽 표를 보면, x축은 복잡도(계산량), y축은 정확도를 의미한다. x축의 경우, 왼쪽으로 갈수록 연산량이 적어 복잡도가 낮은 모델이고, 오른쪽으로 갈수록 복잡한 모델이다. GoogLeNet이 가장 효율적인 모델이고, AlexNet은 계산량은 적지만 정확도가 낮고 메모리를 많이 잡아먹는 것을 볼 수 있다. ResNet은 그 depth에 따라 효율은 달라지지만, 가장 높은 정확도를 보여준다.
