
1. Computer Vision의 목표
Computer Vision의 기본적인 목표는 Image Classification이다. 이미지에 라벨을 각각 달아놓고, 어떻게 하면 알고리즘이 이 라벨에 맞게 이미지를 분류할지 고민하는 것이다. 우리는 눈으로 보자마자 고양이 사진을 보고 고양이라고 인지할 수 있다. 하지만 컴퓨터는 이렇게 하지 못한다. 이를 Semantic Gap이라고 표현한다. 따라서 고양이 이미지의 각 픽셀 값을 보고 고양이라고 예측할 수 있는 알고리즘을 설계하는 작업이 필요하다. 간단한 알고리즘처럼 보이는데 설계하면 되지 왜 못하냐? 라고 할 수 있지만, 막상 하려고 보면 다양한 문제들이 생긴다.
- Viewpoint variation- 고양이를 다양한 각도에서 찍을 수 있는데, 다양한 각도에서 찍은 고양이들을 알아보기 힘들 것이다.
- Illumination- 사진별로 조명의 차이가 있을 수 있다. 어두운 곳, 밝은 곳에 따라 인지하는데 어려움이 있을 것이다.
- Deformation- 고양이가 누워있거나 앉아있는 등 다양한 형태로 찍혔을 수 있다.
- Occusion- 고양이의 형체가 전체 다 보이진 않을 수 있다. 꼬리만 보일수도, 다리만 보일수도 있다.
- Background Clutter- 배경과 비슷한 색을 띄는 고양이가 있을 수 있다.
- Interclass variation- 털 색깔, 나이, 모양 등이 다양한 고양이들이 등장할 수 있다.
위에 적은 6개의 문제들을 해결할 수 있는 메소드를 설계할 수 있을까? 다 일일이 경우를 나누어서 코딩을 하는 것은 좋은 생각이 아니다. 대신 다양한 방법으로 이러한 문제들을 해결하기 위한 시도들이 있었는데,

위 사진처럼 edge를 찾아서 고양이를 인식하는 방식이 대표적인 방법이다. 여기서 edge는 물체가 변하는 지점들이다. 갑자기 픽셀 값이 확 바뀐다면 edge로 판별하는 것이다. (여기서 픽셀값이 얼마나 차이나야 edge로 판별할 지는 정하기 나름이다.) 그러나 이 방법은 edge를 다루기가 꽤 힘들다는 문제점이 있다. 지금 소개하는 두번째 방법이 더 나은 방법이다. Data driven approach라는 방법인데, 쉽게 말해 고양이 사진을 미친듯이 많이 준비해서 머신러닝 알고리즘에 넣어 모델을 학습시키는 방법이다. 이런 방법을 사용하면 조금 더 나은 정확도를 가질 수 있을 것이다. 이제 학습시킬 때 사용하는 알고리즘들에 대해 알아보자.
2. Nearest Neighbor Classifier
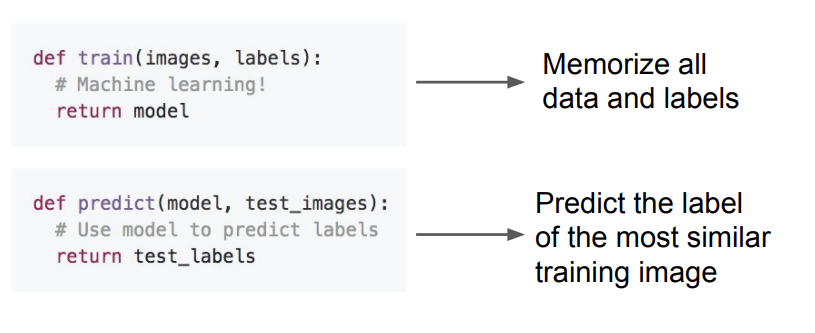
가장 간단한 classifier 중 하나이다. training data를 다 외워놓고, 새로운 test data가 들어오면, 외워놓은 training image와 가장 비슷한 것으로 출력한다.
위 사진은 CIFAR 10이라는 data set인데, 비행기, 자동차, 새, 고양이 등등 10개의 클래스가 있다. 이 data set을 가지고 훈련을 시키면, 새로운 이미지가 들어왔을 때 알고리즘이 10개의 클래스 중 가장 유사한 클래스로 판별하는 것이다. 그렇다면 당연히, 어떻게 유사성을 판별할 지에 대한 의문이 생긴다. 이는 distance metric을 통해 비교한다.

L1 distance는 일단 신경쓰지 말고(어차피 뒤에 나온다), 그냥 이렇게 유사성을 판별하는구나 하고 넘어가면 된다. test image는 새로 들어온, 우리가 어떤 사물인지 판별해야할 영상이다. training image는 우리가 이미 모델에 훈련시킨 이미지이다. 그 둘의 동일한 위치의 픽셀값들을 다 빼서 그 차이를 다 더하면, 이게 유사성을 판별하는 척도가 될 수 있다. 직관적으로 이해가 되고, 이렇게 분류하면 되겠구나 싶지만, 이건 좋은 방법이 아니다.
자료구조를 공부할 때 나오는 빅-오 표기법으로 알고리즘의 속도를 계산해보면, model training에는 O(1), prediction에는 O(N)만큼의 시간이 걸린다. (N은 가지고 있는 sample의 개수이다.) 여기서 Nearest Neighbor 알고리즘의 문제점이 생긴다. 우리는 모델을 훈련시킬 때의 시간에는 관심이 없다. 새로운 사진을 넣었을 때 그걸 판별해내는 속도가 빠른 것이 중요하다. 그런데 이 알고리즘은 훈련 속도는 빠른 반면, 예측 속도는 느리다. 우리가 원하는 목표의 반대인 것이다.
3.K-Nearest Neighbors
우리가 실제로 사용할 때는 K-Nearest Neighbors 알고리즘을 사용한다. 앞에 K가 붙은 이유는, K개의 이웃한 데이터들을 보고 과반수를 차지하는 클래스로 판별하기 때문이다. 보통 K=1이면 내 주변에 가장 가까운 이웃 하나만 보겠다는 뜻이기 때문에 정확성이 좀 떨어지고, K=3이나 K=5 정도로 사용한다. 이렇게 여러 이웃들을 이용해 클래스를 예측하면 정확도가 더 올라갈 수 있다.
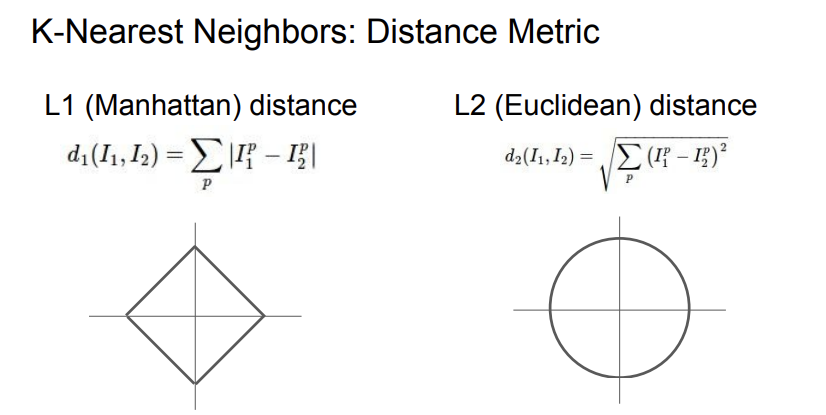
가까운 이웃을 고르는 방식이 두 개가 있는데, L1과 L2 distance이다. 둘 중에 뭐가 더 좋은게 아니라, 데이터의 특성에 따라 적절히 골라서 사용해야 한다.
1. L1: 각 차원의 차이의 절댓값들을 다 더한 것이다. 좌표계를 바꾸면 L1 distance가 바뀐다.
2. L2: 각 차원의 차이의 제곱의 합에 루트를 씌운 값이다. 좌표계를 바꿔도 별 영향이 없다.
보통 그냥 일반적인 벡터라면 L2를 이용하고, input entry에 중요한 의미들이 있다면, L1을 사용하는 것이 일반적이다.
4. Hyperparmeters
위에서 언급했듯이, K는 보통 3이나 5를 사용하고, distance는 보통 L1,L2 중에 하나를 골라서 사용한다. 그렇다면 내가 사용하고자 하는 데이터에 가장 적합한 K값과 Distance는 무엇일까? 이렇게 알고리즘에서 훈련시켜야 하는 것이 아닌, 우리가 세팅해야 하는 값들을 hyperparameter라고 한다. K, distance 종류 모두 hyperparameter에 해당한다.
결론부터 말하자면, 뭐가 제일 좋은지 알아보려면 일일이 다 해봐야 한다. 그래도 조금 체계적으로 하는 방법에 대해 알아보자.
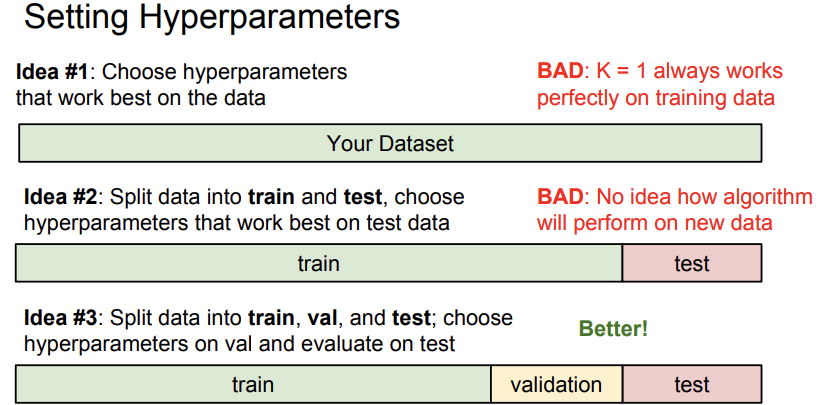
일단 data set을 얻으면, training set, validation set, test set으로 나눠야 한다. 나누는 비율은 정하기 나름인데, 보통 6:2:2 정도로 많이 한다. training data로 모델을 훈련시키고, validation set으로 모델의 최적 hyperparameter를 찾고, test set으로 최종으로 새로운 데이터를 넣어 모델의 성능을 평가한다. 중요한 것은 test set은 훈련하면서는 건들면 안되고, 마지막에 한번만 모델에 넣어봐야 한다는 것이다.
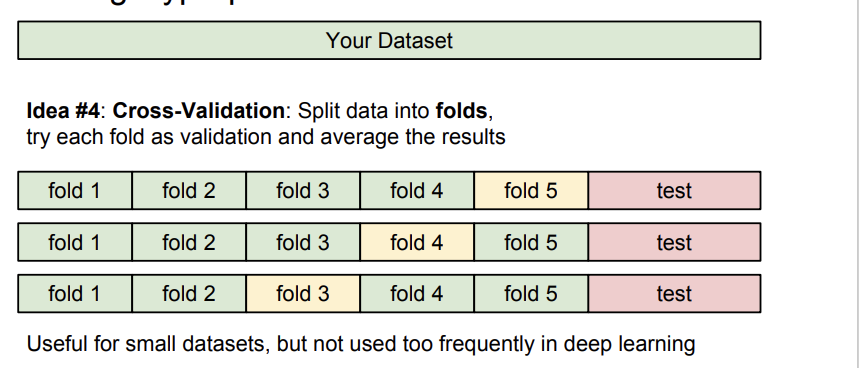
cross validation을 이용해 validation set을 바꿔가며 새로운 데이터에 더 잘 적응하게 하는 방법도 있다. 그러나 K-Nearest Neighbor는 영상처리에는 사용하지 않는다. 속도가 너무 느리고, distance metric 적용하는 것이 영상에 적합하지 않기 때문이다. (차원의 저주 문제도 있다.)
5. Linear Classification
이 수업에서 배우는 Neural Network의 기초가 되는 classifier이다.
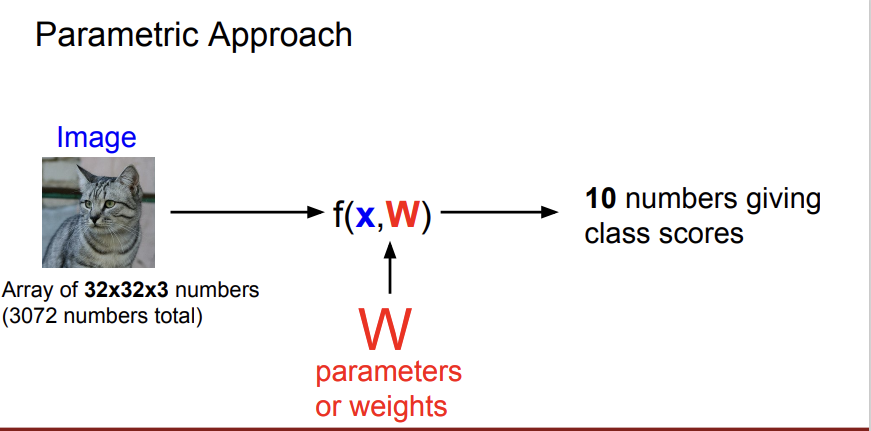
x는 input data, W는 가중치인 weight를 의미한다. 위 사진과 같이 이미지를 어떤 linear classifier f에 넣으면 각 class에 해당하는 점수 10개를 반환한다. 이 10개의 점수 중에 가장 높은 점수를 갖는 클래스가 영상 속의 사물일 가능성이 높은 것이다.
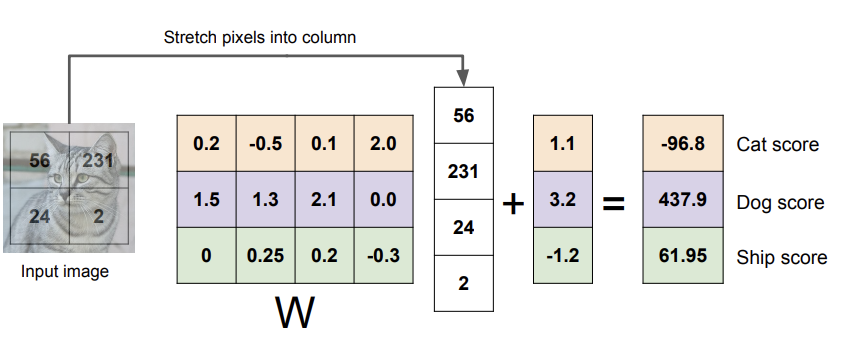
4개의 픽셀과 3개의 클래스만 이용해서 예시를 들어보자면, 픽셀값들 4개를 벡터로 쭉 늘려서 x에 넣고, 행렬 계산을 해서 각 클래스에 대한 점수를 뽑는 것이다. (결과는 신경쓰지 말자)
Wx 옆에 3*1 벡터가 하나 더 있는 이유는 bias term을 더해주기 위해서이다. (새로 들어오는 데이터를 잘 예측할 수 있게 도와주는 값 정도로만 이해하자.)

최종 Linear Classifier의 식은 f(x,W)=Wx+b와 같이 나타나고, 결국 이 알고리즘이 하는 것은 훈련을 통해 클래스별로 W값들을 얻는 것이다. 밑에 10장의 흐릿한 사진들이 W 값들을 얻어 만들어진 클래스 별 template이다. 이를 통해 새로운 데이터를 분류하는 것이다.
그러나 Linear Classifier도 분류에 사용하기 어려운 경우들이 있다.
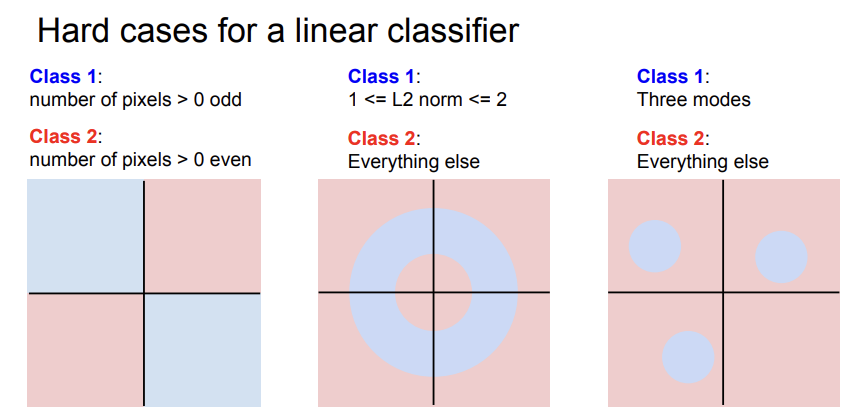
그래프 안에 파란색과 빨간색이 클래스들이라고 할때, 위에 세 예시들은 선으로 분류를 수행하기 어렵다. 빨간색과 파란색을 분류할 수 있는 선이 존재하지 않기 때문이다.
여기까지가 2강 내용이다. Linear classifier를 통해 클래스별 score를 뽑아내는 것까지 공부했다. 훈련을 통해 얻은 W가 좋은 W인지 어떻게 알까? 에 대한 내용을 3강에서 진행한다.
