이번 글에서는 cs231n 과제 3의 Q1을 구현하며 어려웠던 부분들을 정리해보려고 한다. 이전의 CNN을 했던 방식과 유사한데, 이제 각 time step에 대해서 구현해야 한다는 것이 차이점인 것 같다.
1. rnn_backward() 함수
이 부분에서 헷갈렸던 것은 gradient 계산 방법이다.
def rnn_backward(dh, cache):
"""Compute the backward pass for a vanilla RNN over an entire sequence of data.
Inputs:
- dh: Upstream gradients of all hidden states, of shape (N, T, H)
NOTE: 'dh' contains the upstream gradients produced by the
individual loss functions at each timestep, *not* the gradients
being passed between timesteps (which you'll have to compute yourself
by calling rnn_step_backward in a loop).
Returns a tuple of:
- dx: Gradient of inputs, of shape (N, T, D)
- dh0: Gradient of initial hidden state, of shape (N, H)
- dWx: Gradient of input-to-hidden weights, of shape (D, H)
- dWh: Gradient of hidden-to-hidden weights, of shape (H, H)
- db: Gradient of biases, of shape (H,)
"""
dx, dh0, dWx, dWh, db = None, None, None, None, None
##############################################################################
# TODO: Implement the backward pass for a vanilla RNN running an entire #
# sequence of data. You should use the rnn_step_backward function that you #
# defined above. You can use a for loop to help compute the backward pass. #
##############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
N=dh.shape[0]
T=dh.shape[1]
H=dh.shape[2]
D = cache[0][0].shape[1] # cache[0][0]=x. (N,D)
dx=np.zeros((N,T,D))
dh0=np.zeros((N,H))
dWx=np.zeros((D,H))
dWh=np.zeros((H,H))
db=np.zeros((H,))
for t in reversed(range(T)):
dx_t, dh0, dWx_t, dWh_t, db_t=rnn_step_backward(dh[:,t,:]+dh0, cache[t])
dx[:,t,:]=dx_t
dWx+=dWx_t
dWh+=dWh_t
db+=db_t
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
##############################################################################
# END OF YOUR CODE #
##############################################################################
return dx, dh0, dWx, dWh, db역시 각 time step별로 계산해 주어야 한다. 그러나 처음에 나는 time step마다 계산한 값을 dx, dWx,dWh,db 등의 gradient들에 더해줄 생각을 하지 못했고, 아래와 같이 코드를 작성했다.
for t in reversed(range(T)):
dx_t, dh0, dWx_t, dWh_t, db_t=rnn_step_backward(dh[:,t,:]+dh0, cache[t])
dx[:,t,:]=dx_t
dWx=dWx_t
dWh=dWh_t
db=db_tdx의 경우 time step에 해당하는 차원이 따로 있어서 위와 같이 코드를 작성해도 문제가 없지만, weight matrix와 bias matrix의 경우는 모든 time step에서 공통으로 사용하기 때문에 문제가 될 수 있다. 결국 위의 코드가 의미하는 것은 각 time step에서 얻은 gradient값으로 초기화하는 것이고, 마지막에는 가장 처음 time step의 gradient 뿐일 것이기 때문이다. 그러나 우리는 전체 time step의 gradient를 반영해야 하기 때문에 dWx+=dWx_t 와 같은 식으로 적어주는 것이 맞다.
2. word_embedding_forward()
이 부분은 코딩이 어렵다기보다는 word embedding 방식을 이해하는게 오래 걸렸다.
def word_embedding_forward(x, W):
"""Forward pass for word embeddings.
We operate on minibatches of size N where
each sequence has length T. We assume a vocabulary of V words, assigning each
word to a vector of dimension D.
Inputs:
- x: Integer array of shape (N, T) giving indices of words. Each element idx
of x muxt be in the range 0 <= idx < V.
- W: Weight matrix of shape (V, D) giving word vectors for all words.
Returns a tuple of:
- out: Array of shape (N, T, D) giving word vectors for all input words.
- cache: Values needed for the backward pass
"""
out, cache = None, None
##############################################################################
# TODO: Implement the forward pass for word embeddings. #
# #
# HINT: This can be done in one line using NumPy's array indexing. #
##############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
out=W[x]
cache=(x,W,out)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
##############################################################################
# END OF YOUR CODE #
##############################################################################
return out, cache 코드 자체는 이렇게 두 줄로 끝난다. 그러나 어떻게 해서 저 코드가 나왔는지를 이해해야 한다. 과제는 W=(V,D) , x=(N,T), out-=(N,T,D)의 크기를 가진다고 한다. 이때 N은 mini batch의 크기, T는 각 mini batch 속 sample의 sequence 길이, V는 고려하는 전체 단어의 수를 의미한다.
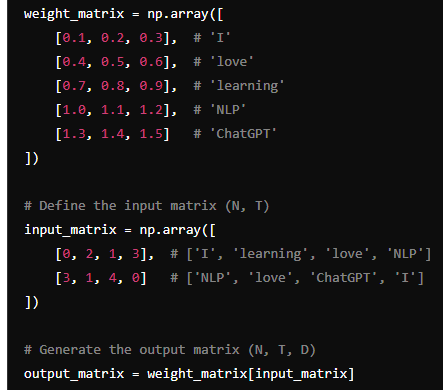
weight matrix, Input Matrix가 위의 사진과 같다고 하자. Weight matrix에서 단어 'I'는 [0.1,0.2,0.3] 벡터로 표현되고, 나머지 단어들도 마찬가지다. 이 예시에서는 W=(5,3)의 크기를 가지는 것이다. (전체 vocab는 5개, 벡터의 차원은 3인 것이다.) 그리고 input matrix를 보면, N=2, T=4를 의미함을 알 수 있다. 고려하는 mini batch 속 sample은 2개, 각 sample 당 단어의 개수는 4개이다. 때문에 첫 번째 sample인 [0,2,1,3]은 weight matrix에서 각각 0번째, 2번째, 1번째, 3번째 단어를 뜻하게 된다. 이런 식으로 word 하나당 하나의 벡터를 지정해주는 방식이다.
지금까지 설명한 바에 따르면, input matrix를 weight matrix의 index로 써서 output matrix를 뱉는 것이다. 그걸 numpy를 이용해서 쉽게 하면, out=W[x]와 같은 코드를 생각해 낼 수 있다.
3. word_embedding_backward()
def word_embedding_backward(dout, cache):
"""Backward pass for word embeddings.
We cannot back-propagate into the words
since they are integers, so we only return gradient for the word embedding
matrix.
HINT: Look up the function np.add.at
Inputs:
- dout: Upstream gradients of shape (N, T, D)
- cache: Values from the forward pass
Returns:
- dW: Gradient of word embedding matrix, of shape (V, D)
"""
dW = None
##############################################################################
# TODO: Implement the backward pass for word embeddings. #
# #
# Note that words can appear more than once in a sequence. #
# HINT: Look up the function np.add.at #
##############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
x,W=cache
V=W.shape[0]
D=W.shape[1]
dW=np.zeros((V,D))
np.add.at(dW,x,dout) # add the elements at certain indices(x) of dout to dW.
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
##############################################################################
# END OF YOUR CODE #
##############################################################################
return dWword_embedding_backward() 에서는 gradient를 계산해야 한다. 과제에서 np.add.at을 찾아보라고 조언한다. np.add.at(dW,x,dout)은, x의 index에 해당하는 원소에만 덧셈을 해준다는 뜻이다. 즉, x의 인덱스에 해당하는 dout의 원소를 dW에 더해주는 효과를 준다는 것이다.
4. class CaptioningRNN- loss()
def loss(self, features, captions):
"""
Compute training-time loss for the RNN. We input image features and
ground-truth captions for those images, and use an RNN (or LSTM) to compute
loss and gradients on all parameters.
Inputs:
- features: Input image features, of shape (N, D)
- captions: Ground-truth captions; an integer array of shape (N, T + 1) where
each element is in the range 0 <= y[i, t] < V
Returns a tuple of:
- loss: Scalar loss
- grads: Dictionary of gradients parallel to self.params
"""
# Cut captions into two pieces: captions_in has everything but the last word
# and will be input to the RNN; captions_out has everything but the first
# word and this is what we will expect the RNN to generate. These are offset
# by one relative to each other because the RNN should produce word (t+1)
# after receiving word t. The first element of captions_in will be the START
# token, and the first element of captions_out will be the first word.
captions_in = captions[:, :-1]
captions_out = captions[:, 1:]
# You'll need this
mask = captions_out != self._null
# Weight and bias for the affine transform from image features to initial
# hidden state
W_proj, b_proj = self.params["W_proj"], self.params["b_proj"]
# Word embedding matrix
W_embed = self.params["W_embed"]
# Input-to-hidden, hidden-to-hidden, and biases for the RNN
Wx, Wh, b = self.params["Wx"], self.params["Wh"], self.params["b"]
# Weight and bias for the hidden-to-vocab transformation.
W_vocab, b_vocab = self.params["W_vocab"], self.params["b_vocab"]
loss, grads = 0.0, {}
############################################################################
# TODO: Implement the forward and backward passes for the CaptioningRNN. #
# In the forward pass you will need to do the following: #
# (1) Use an affine transformation to compute the initial hidden state #
# from the image features. This should produce an array of shape (N, H)#
# (2) Use a word embedding layer to transform the words in captions_in #
# from indices to vectors, giving an array of shape (N, T, W). #
# (3) Use either a vanilla RNN or LSTM (depending on self.cell_type) to #
# process the sequence of input word vectors and produce hidden state #
# vectors for all timesteps, producing an array of shape (N, T, H). #
# (4) Use a (temporal) affine transformation to compute scores over the #
# vocabulary at every timestep using the hidden states, giving an #
# array of shape (N, T, V). #
# (5) Use (temporal) softmax to compute loss using captions_out, ignoring #
# the points where the output word is <NULL> using the mask above. #
# #
# #
# Do not worry about regularizing the weights or their gradients! #
# #
# In the backward pass you will need to compute the gradient of the loss #
# with respect to all model parameters. Use the loss and grads variables #
# defined above to store loss and gradients; grads[k] should give the #
# gradients for self.params[k]. #
# #
# Note also that you are allowed to make use of functions from layers.py #
# in your implementation, if needed. #
############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
h0,cache1=affine_forward(features,W_proj,b_proj)
x_embed,cache2=word_embedding_forward(captions_in, W_embed)
h,cache3=rnn_forward(x_embed, h0, Wx, Wh, b)
out,cache4=temporal_affine_forward(h,W_vocab ,b_vocab)
loss,dx=temporal_softmax_loss(out, captions_out, mask)
dx,dw4,db4=temporal_affine_backward(dx,cache4)
dx, dh0, dwx, dwh, db=rnn_backward(dx,cache3)
dw_embed=word_embedding_backward(dx, cache2)
dx,dw_proj,db_proj=affine_backward(dh0,cache1)
grads['W_embed']=dw_embed
grads['W_proj']=dw_proj
grads['b_proj']=db_proj
grads['Wx']=dwx
grads['Wh']=dwh
grads['b']=db
grads['W_vocab']=dw4
grads['b_vocab']=db4
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)**temporal_affine layer는 우리가 얻은 caption의 score를 계산해주는 용도이다. 또한, 마지막에 temporal_softmax_loss를 넣어서 loss 값을 얻는다. 이후 backpropagation은 이전에 구현한 layer들을 통해서 진행할 수 있다. weight matrix의 종류가 많아서 헷갈렸지만, 차근차근 하면 어렵진 않은 것 같다.
5. sample()
sample 함수는 test time 때 caption을 sampling을 하는 방식을 구현하는 것이다. 각 time step에서 다음 hidden state를 계산하고, hidden state를 이용해서 모든 단어들의 score를 얻는다. 그 중에서 가장 큰 score를 가진 단어를 다음 단어로 출력하는 것이다. 이렇게 구현을 하긴 하지만, test time 때의 성능이 그닥 좋진 않다.
def sample(self, features, max_length=30):
"""
Run a test-time forward pass for the model, sampling captions for input
feature vectors.
At each timestep, we embed the current word, pass it and the previous hidden
state to the RNN to get the next hidden state, use the hidden state to get
scores for all vocab words, and choose the word with the highest score as
the next word. The initial hidden state is computed by applying an affine
transform to the input image features, and the initial word is the <START>
token.
For LSTMs you will also have to keep track of the cell state; in that case
the initial cell state should be zero.
Inputs:
- features: Array of input image features of shape (N, D).
- max_length: Maximum length T of generated captions.
Returns:
- captions: Array of shape (N, max_length) giving sampled captions,
where each element is an integer in the range [0, V). The first element
of captions should be the first sampled word, not the <START> token.
"""
N = features.shape[0]
captions = self._null * np.ones((N, max_length), dtype=np.int32)
# Unpack parameters
W_proj, b_proj = self.params["W_proj"], self.params["b_proj"]
W_embed = self.params["W_embed"]
Wx, Wh, b = self.params["Wx"], self.params["Wh"], self.params["b"]
W_vocab, b_vocab = self.params["W_vocab"], self.params["b_vocab"]
###########################################################################
# TODO: Implement test-time sampling for the model. You will need to #
# initialize the hidden state of the RNN by applying the learned affine #
# transform to the input image features. The first word that you feed to #
# the RNN should be the <START> token; its value is stored in the #
# variable self._start. At each timestep you will need to do to: #
# (1) Embed the previous word using the learned word embeddings #
# (2) Make an RNN step using the previous hidden state and the embedded #
# current word to get the next hidden state. #
# (3) Apply the learned affine transformation to the next hidden state to #
# get scores for all words in the vocabulary #
# (4) Select the word with the highest score as the next word, writing it #
# (the word index) to the appropriate slot in the captions variable #
# #
# For simplicity, you do not need to stop generating after an <END> token #
# is sampled, but you can if you want to. #
# #
# HINT: You will not be able to use the rnn_forward or lstm_forward #
# functions; you'll need to call rnn_step_forward or lstm_step_forward in #
# a loop. #
# #
# NOTE: we are still working over minibatches in this function. Also if #
# you are using an LSTM, initialize the first cell state to zeros. #
###########################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# we want to sample the caption for each image in the mini batch.
h,cache1=affine_forward(features,W_proj,b_proj) # initializing hidden state
prev=self._start*np.ones((N,),dtype=np.int32) # feed start token to the rnn.
for i in range(max_length):
prev_embed,cache2=word_embedding_forward(prev, W_embed) #embed the input.
h, cache3=rnn_step_forward(prev_embed, h, Wx, Wh, b)
scores,cache4=affine_forward(h,W_vocab ,b_vocab) #get the scores-> use the max index to predict the next word.
prev=np.argmax(scores,axis=1) # update prev to the highest score index.
captions[:,i]=prev
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
############################################################################
# END OF YOUR CODE #
############################################################################
return captions6. 정리
구현을 하긴 했지만, 아직 RNN의 구조에 대해서 완벽히 이해한 느낌은 아니다. 이후에 RNN 논문을 좀 찾아봐야 할 것 같다.
내 과제 풀이:
