논문 리뷰(17) - Fast, Accurate, and Lightweight Super-Resolution with Cascading Residual Network
논문 리뷰
이번에 살펴볼 논문은 CARN으로 유명한 'Fast, Accurate, and Lightweight Super-Resolution with Cascading Residual Network'라는 논문이다.
1. 저자가 이루려고 한 것
1) 기존 방법의 문제
기존의 방법들이 더 좋은 퀄리티, 높은 정확도의 SR을 가능하게 했지만, 굉장히 무거운 모델이라는 단점이 있었다. 때문에 막상 현실의 문제를 해결하기 위해 사용하기에는 적합하지 않았다. 현실에서는 모바일 기기에 모델을 올려야 하는데, 무거운 모델로는 이것이 불가능 했기 때문이다.
2) CARN을 통해 해결하고자 한 것
저자들은 모바일 기기에서 사용할 수 있을 정도로 가벼운 lightweight SR 모델을 만들고자 했다. 그래서 제안한 것이 CARN과 그의 경량화 버전인 CARN-M이다. CARN-M은 모바일 기기에 올릴 수 있도록 더욱 가볍게 만든 것이라고 한다. CARN은 multi-level representation과 multiple shortcut connection의 특성을 가지는 Cascading module을 제안했다. 또, 보통 lightweight SR이라고 하면 parameter의 수만 줄이는 것을 생각하는데, operation, 즉 연산량도 줄여야 모바일 기기에서 효과적으로 작동할 수 있다는 아이디어를 제안했다. 이를 통해 줄어든 parameter와 연산량으로 기존의 모델들과 비슷하거나 그를 능가하는 성능을 보여주었다.
2. 주요 내용
1) Notation
Notation을 살펴보기에 앞서, ResNet에서 등장하는 와 CARN에서 등장하는 는 비슷하지만, 다른 표현이다. 이를 잘 구별해야 한다.
- : convolution layer
- : activation function (ReLU)
- : i-th residual block
- : output of i-th residual block (ResNet에서만!)
- : parameter set of i-th residual block
- : j-th convolution in the i-th residual block
- : output of the final residual block = input to the upsampling block (ResNet에서만!)
- : conv layer의 parameter
- : output of j-th residual block of i-th local cascading block.
- : set of parameters of i-th local cascading block
- : i-th local cascading block
- : output of bth local cascading block
2) 1x1 Convolution
논문에 자주 등장하는 1x1 convolution이 무엇인지 복습하고 가려고 한다. 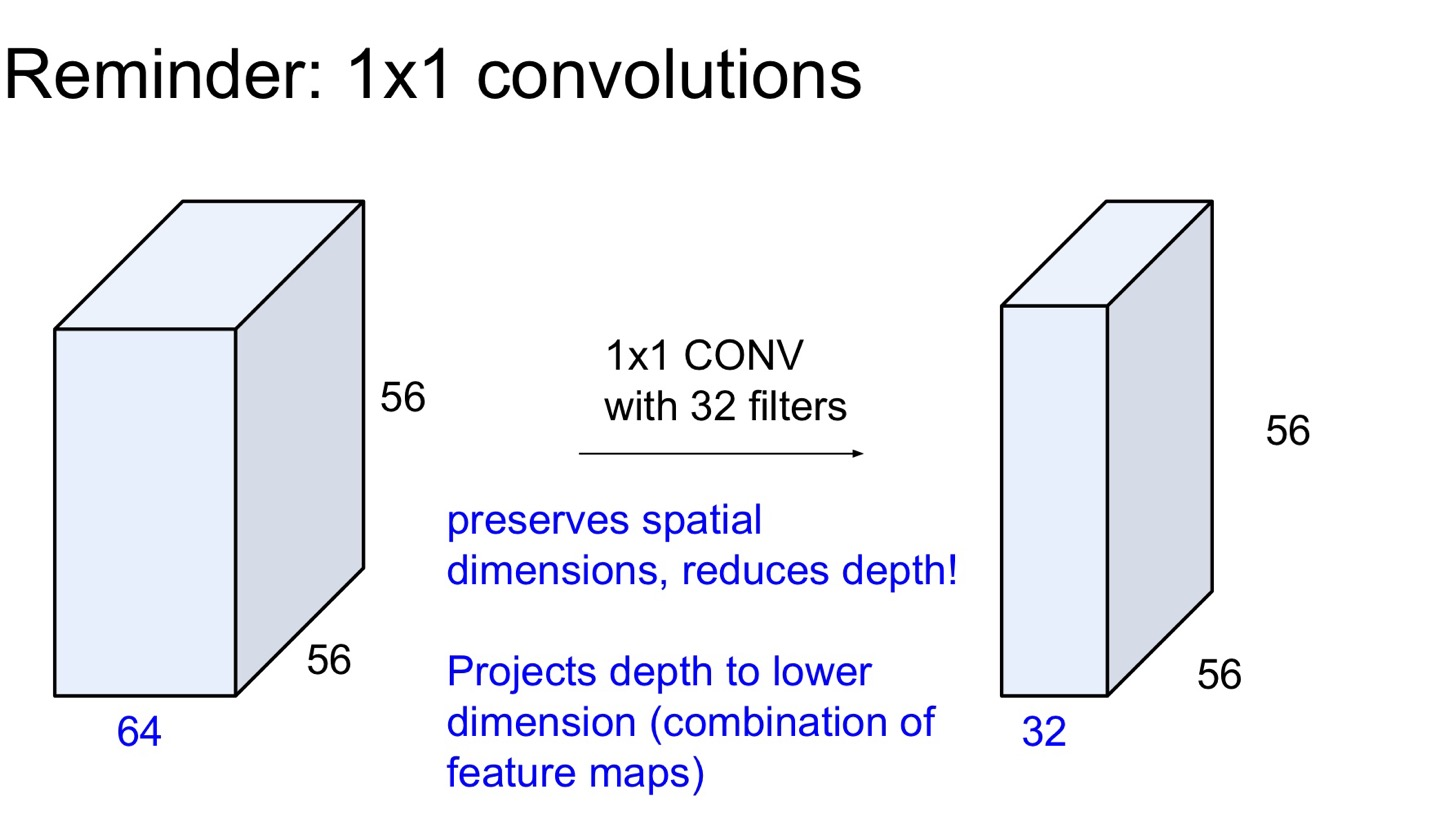
1x1 convolution은 기존의 width, height는 유지하면서 channel 수만 줄여주는 테크닉이다. 이름에서도 알 수 있듯이, kernel의 크기는 1x1이다. CARN에서도 concat이 계속되면 연산량이 많아지므로 1x1 convolution으로 이를 줄여주는 것이다.
3) CARN (Cascading Residual Network)
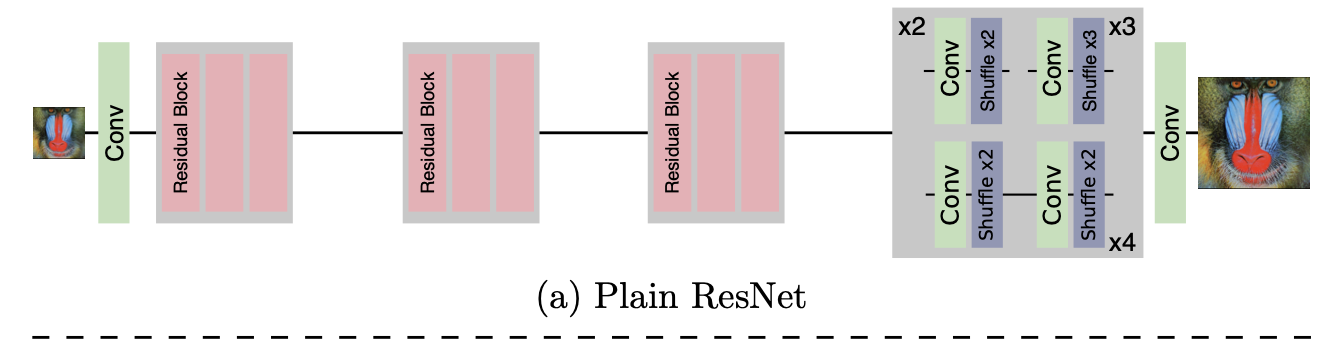
CARN = ResNet + Local/Global Cascading Modules이다. local/global cascading이 CARN의 핵심이다. 이후에 살펴보겠지만, 모델의 구조에 대해 가닥을 잡고 갈 필요가 있다. CARN은 기본적으로 ResNet 베이스의 모델이다. Residual Block을 조금 변형하여 cascading block을 만들어서 사용한다. 아래의 그림의 (b)에서 보듯이, 초기 layer의 정보들이 이후 layer로 전달된다. 그리고 나서 마지막에 upsampling module이 붙어있는데, 논문에서는 이 upsampling module에 대해서는 거의 설명하지 않는다. 코드를 찾아보니 Pixel Shuffle 기반의 방법으로 upsampling을 진행한다고 한다. 이제 CARN에 대해 자세히 알아보자.
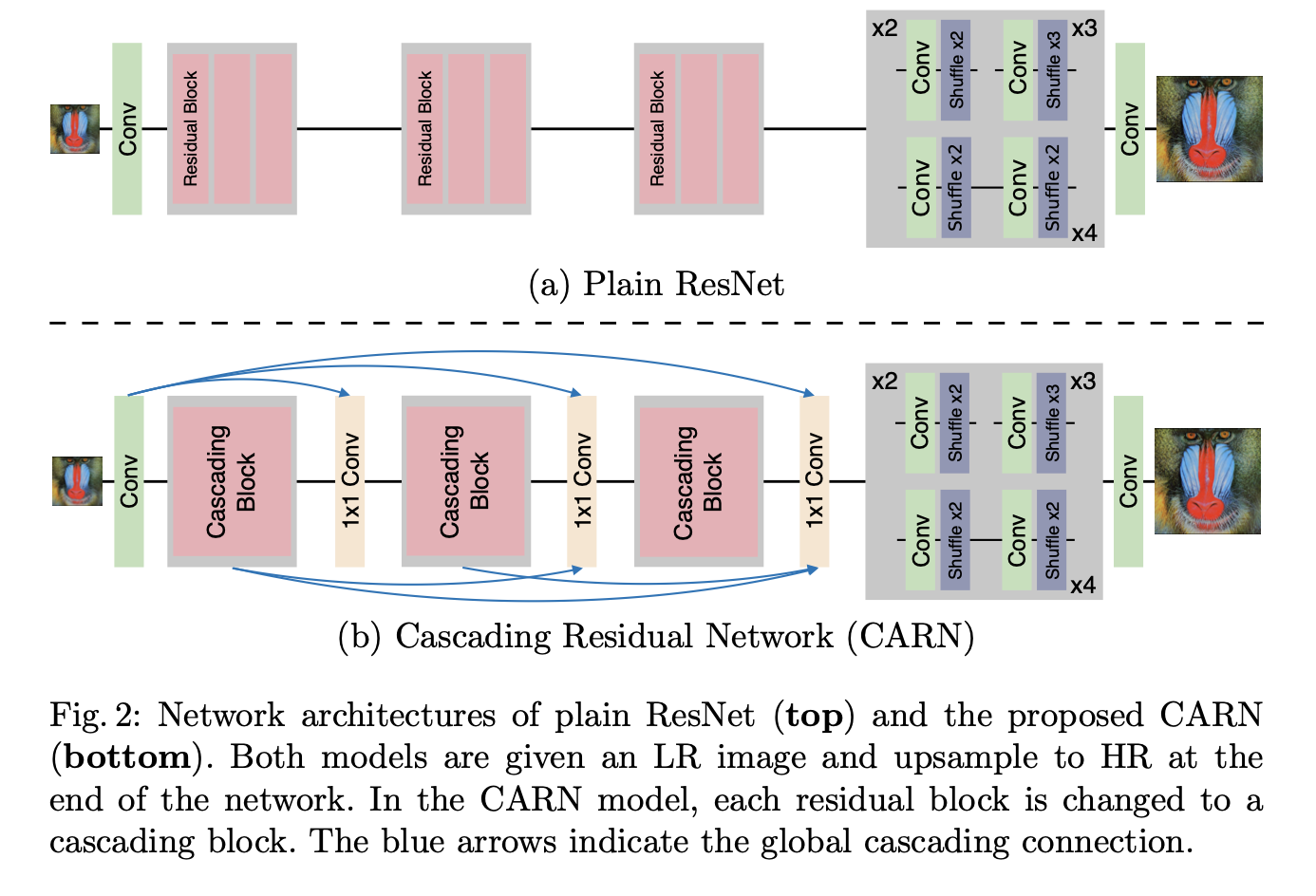
- 파란 화살표는 global cascading을 뜻함.
- Cascading Block 안에서 각각 local cascading이 일어남.
Residual Block
헷갈리면 안되는 것이, Residual Block이 CARN에 쓰이긴 하지만, 여기서 쓰이는 와 이따 나올 local cascading에서의 는 다르다. 즉, 여기서 다루는 residual block은 위의 ResNet과 CARN의 구조를 나타낸 사진에서 (a)에 해당하는 Plain ResNet에 해당하는 것이다. 일단 여기서는 이 점을 알아두기만 하고, 이따 local cascading에서 더 자세히 짚어보자.
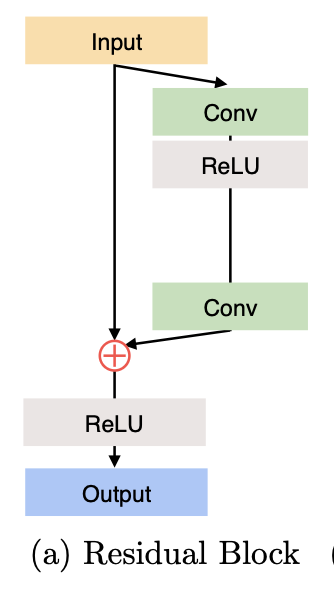
i-th Residual Block 는 위의 식과 같이 정의할 수 있다. 복잡해 보이지만 하나하나 뜯어보면 그냥 위의 그림을 식으로 나타낸 것이다. 식의 input은 , 가 i-th residual block의 output이므로, i-th residual block 의 input이 이 되는 것은 자연스러운 일이다. output은 output은 이 된다.
i)
단순한 convolution layer이다. Residual block 내의 첫 번째 convolution이기 때문에 parameter는 을 사용한다. conv layer 이후 ReLU(를 거치게 된다.
ii)
i) 에서의 식에 conv layer만 하나 추가된 것이다. block의 두 번째 conv layer이므로 parameter 를 사용한다.
iii)
ii) 식에서 ReLU만 추가된 것인데, input을 더해주어 skip connection을 반영해주었다.
위의 block들을 반복해 최종적인 output feature인 를 얻게 된다. 그 식은 아래와 같다.
여기서 는 u개의 residual block을 거쳐 나온 최종 output feature를 의미한다.
위의 식을 보면 input이 처음에 conv layer를 거쳐서 가기 때문에 를 적어줘야 한다. 는 conv layer의 parameter를 의미한다.
Local Cascading Block
이제 CARN에서 중요한 local cascading block에 대해 알아볼 차례이다.
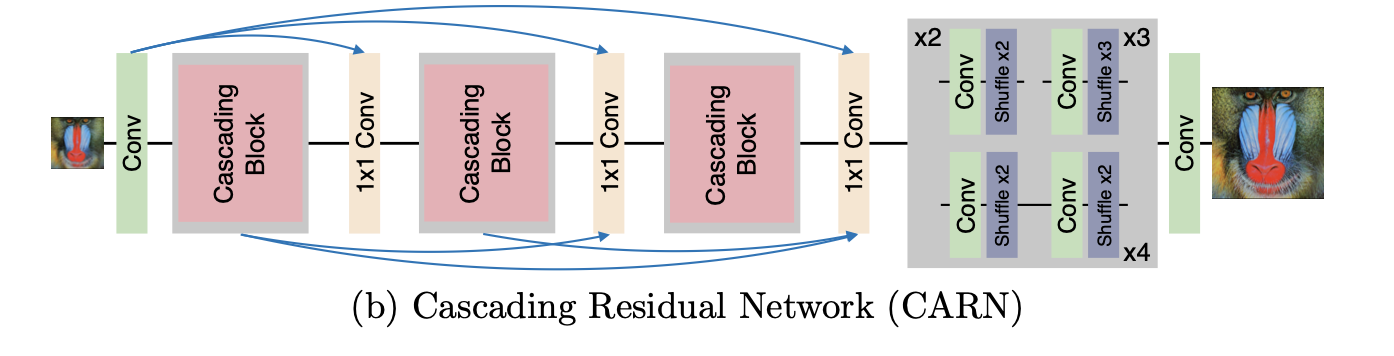
앞서 언급했듯이, CARN은 위와 같은 구조를 갖는다. 각 cascading block은 아래의 그림과 같은 구조를 가지고 있다.
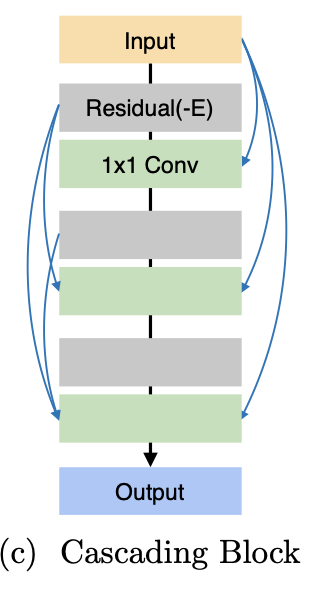
cf) residual block을 보면 'Residual(-E)' 라고 되어 있는데, 이는 Residual Block 또는 Residual-E가 올 수 있음을 의미한다. 구체적으로 CARN에서는 일반 residual이 쓰이고, CARN의 경량화 버전인 CARN-M에서는 Residual-E가 쓰인다. CARN-M에 대해서는 자세히 알아보지 않으니 지금은 CARN에만 집중하자.
이를 식으로 알아보자.
i)
기본적으로 i-th local cascading block 은 이전 block의 output인 을 input으로 사용한다. 식의 표현에 따라 의 output은 가 되는 것이다.
ii)
에 도달하기까지, 는 재귀적으로 구성되어 있다. 이때 는 하나의 cascading block 내의 residual의 개수를 의미한다. 논문에서는 실험 시 그림과 같이 의 세팅을 사용한다. 먼저 부터 살펴보자. 앞서 본 대로, 번째 residual block을 의미한다. input은 직전 layer의 output feature이다. 이렇게 residual block을 통과한 값과 지금까지 모든 intermediate layer들의 출력(), 그리고 원래의 Block의 input()을 concat한다. 그리고 나서 마지막에 1x1 conv layer를 거치는 것이다. 이러한 것을 까지 반복하는 것이다.
Global Cascading
다음은 Global Cascading이다. 여기서 는 i-th cascading block의 output feature 정도로 이해하면 될 것 같다.
Global Cascading의 식은 아래와 같다.
i)
초기값 로는 conv layer를 타고 나온 값 를 사용한다. 위의 CARN의 구조도를 보면 더 이해가 잘 될 것이다.
ii)
이후의 block들에서는 위의 식을 사용하는데, 먼저 부터 살펴보자. 앞서 이야기한 local cascading block이다.
cf) 사실 이 부분은 논문에서 로 써져 있는데, 내가 생각하기에 가 오타같다. 자리에 가 와야 논문이 의도하는 바가 수식에 전해지는 것 같다.
의 input은 로, 이전 block의 output feature이다. 이렇게 local cascading block을 계산한 후, 지금까지의 intermediate layer의 output feature들()과 concat 해준다. 그리고 나서 1x1 conv layer를 거치면 final output feature 가 나오는 것이다. 이때, 논문에서는 을 사용한다.
이것이 CARN의 구조에 대한 설명이다. 분량상 CARN-M에 대해서는 따로 다루지는 않겠다.
정리
지금까지 배운 내용들을 정리해보자. CARN에서 가장 중요한 것은 local & global cascading을 통한 multi-level representation과 multi-shortcut connection의 생성이다. 이를 통해 parameter 수와 연산량을 획기적으로 줄이는데 성공했다. CARN의 전체 구조도의 Cascading Block 안에서 local cascading이 일어나고, 그것들을 이용해 global cascading이 진행된다. 그 속에서는 concat 후 1x1 conv가 반복된다.
Experiments
이제 논문에서 실험에 어떤 세팅을 썼는지 알아보자.
- Dataset : 291 image set, DIV2K (800 training, 100 validation, 100 testing images)
- Testing : Set5, Set14, B100, Urban100
- Training
- Input: 64x64 patches random sampled from LR images.
- Data Augmentation : random horizontal flip & 90 degrees rotation.
- Adam Optimizer : steps.
- batch size =64, lr = , decay rate = 0.5 every steps.
- weight & bias initialization : , ; # of channels in input feature map
- scaling factor : x2, x3, x4 중에 하나. -> 모델이 하나의 batch 내에서는 하나의 scale만 다룰 수 있음.
- Loss : L1 loss
- Evaluation : PSNR, SSIM, number of operations with Mult-Adds.
위의 그래프를 보면 PSNR과 parameter 수, 그리고 operation 수를 나타내는 척도인 Mult-Adds까지 한 눈에 볼 수 있다. CARN은 다른 모델들보다 연산량과 parameter 수는 현저히 적으며, 그에 비해 PSNR은 밀리지 않는 모습을 보여준다. 아래는 CARN과 다른 모델들의 성능을 비교한 표이다.
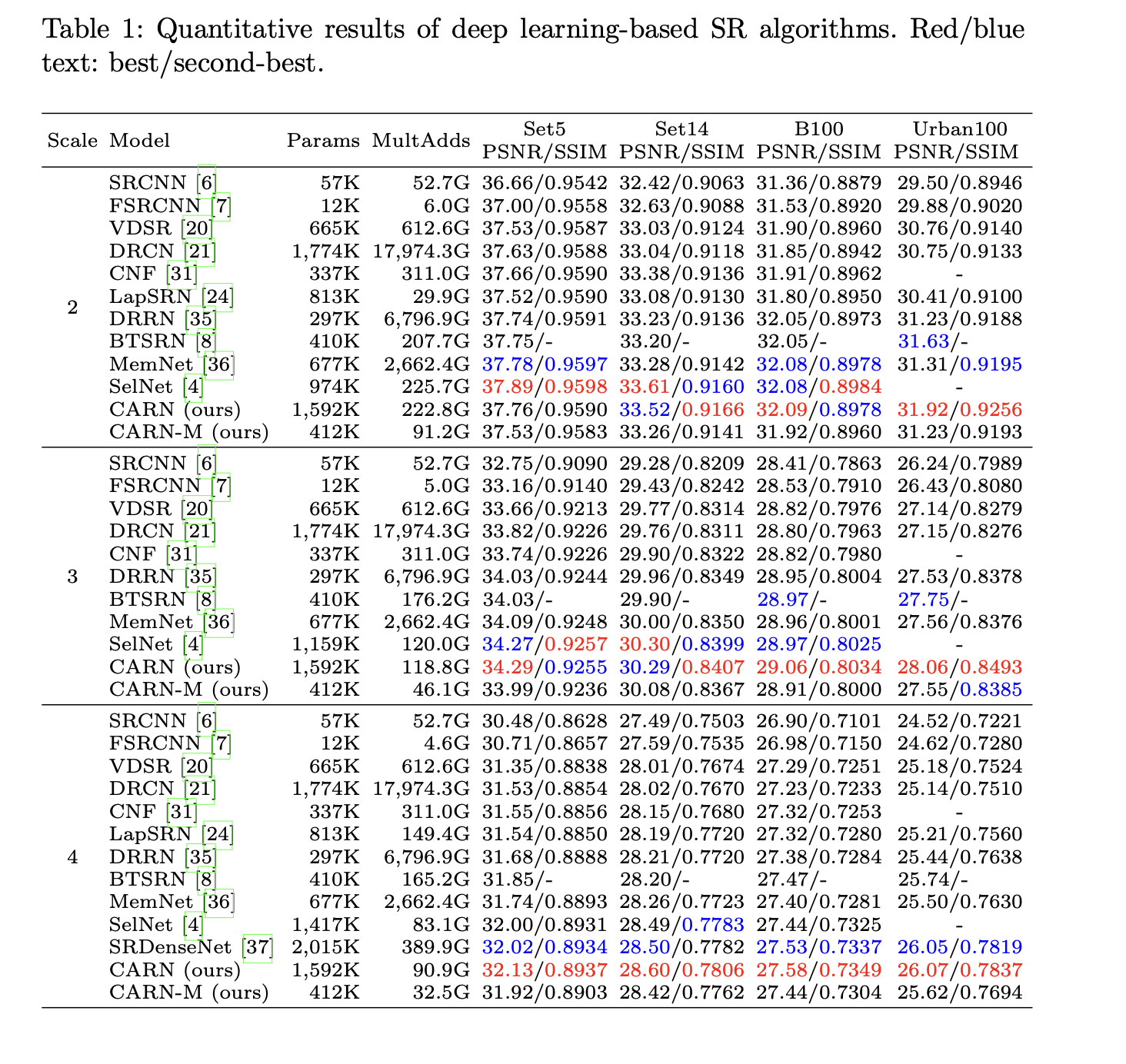
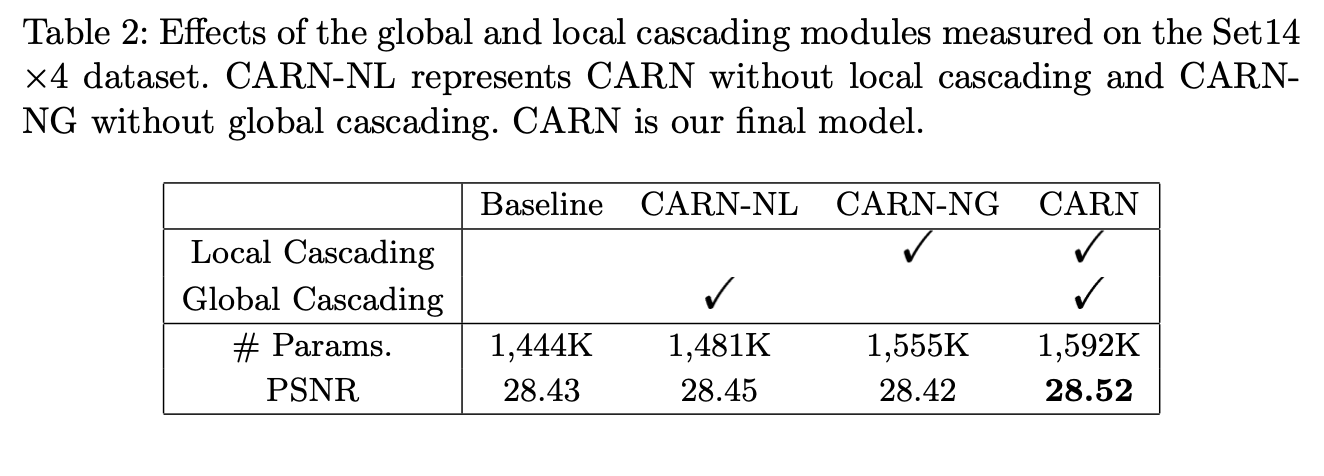
또, local cascading과 global cascading을 굳이 같이 써야 하는가? 라는 의문이 생길 수 있는데, 아래 표를 보면 둘 중에 하나만 썼을 때보다 둘 다 사용했을 때가 더 좋은 성능을 낸다는 것을 알 수 있다. 심지어 Local cascading만 사용할 때는 성능이 오히려 떨어진다. 자세한 내용은 논문을 참고하길 바란다.
3. 더 찾아볼 내용 및 질문
- Upsampling 기법인 Pixel Shuffle
- CARN 코드 리뷰 혹은 직접 구현
