논문 리뷰 (16) - [LIIF] Learning Continuous Image Representation with Local Implicit Image Function
논문 리뷰
이번에 살펴볼 논문은 LIIF로 유명한 'Learning Continuous Image Representation with Local Implicit Image Function'이라는 논문이다. 직전에 읽었던 PCSR 에서도 LIIF를 사용하는 등, SR에서 적지 않게 등장하는 개념이다.
1. 저자가 이루려고 한 것
1) 기존 방법의 문제
우리가 보는 visual world는 continuous 하지만, 이를 컴퓨터와 같은 기계에서 표현할 때는 discrete한 픽셀들, 즉 2D array로 나타난다. 이러한 pixel-based method는 다양한 연구들에 적용되었지만, resolution의 제한 때문에 불편함이 있다.
Ex) 만약 CNN을 훈련시킨다면, input image의 사이즈를 동일하게 맞추어서 모델에 전달해야 함. -> 이미지 퀄리티가 떨어짐.
2)LIIF가 해결하고자 한 것
이러한 상황에서 LIIF는 그 이름에서 알 수 있듯이 Continuous한 representation을 만드는 것을 목표로 한다. 이 논문의 contribution은 아래와 같다.
- 복잡한 이미지를 continuous하게 표현하는 새로운 representation.
- LIIF representation을 이용해 training 때 보지 못한, 더 큰 scale에 대한 extrapolation (데이터 범위를 벗어나는 부분에 대한 추정) -> X30(30배)까지
- size-varied image ground-truth 학습에도 효과적임.
2. 주요 내용
1) 개요
LIIF는 기본적으로 3D task에서 효과적이었던 Implicit neural representation에서 영감을 얻었다고 한다. 자세히 다루지는 않겠지만, mesh, voxel 등 기존의 3D representation들에 비해 적은 parameter수로 더 나은 성능을 보여줬다고 한다. 이러한 방법은 image representation에 적용해 본 것이 LIIF인 것이다.
2) 용어 정리
- : Continuous Image.
-> input image를 의미하지만, continuous representation에 이용되어 이름이 Continuous image인 것 같다.- : 2D feature map.
-> 의 shape을 갖는다.- : 를 shape [D,]의 벡터 HW개로 분리했을 때, 각각의 벡터를 의미한다.
- : image 도메인에서의 2D coordinate.
-> 는 특정 좌표를 나타낼 때 많이 사용함.- : decoding function.
-> 5-layer MLP와 ReLU로 구성되어 있다.- : predicted signal. (RGB 값)
- : 주어진 좌표 에서 가장 가까운 latent code.
- : 의 coordinate.
- : 가 구성하는 사각형의 면적.
-> 는 의 대각선 좌표를 의미함.- : 들을 다 합친 전체 면적. ()
3) Local Implicit Image Function
LIIF representation은 기본적으로 continuous image 를 로 표현하고, decoding function 를 이용해 predicted RGB value 인 를 만드는 과정이다. 'representation이라는 말이 어디까지 포함하는 표현인가?' 라는 의문이 있었는데, representation은 그냥 image -> feature map -> decoding function-> 를 만드는 과정 전체라고 생각하면 될 것 같다. 이제 각 과정을 자세히 살펴보자.
첫번째로 이미지에서 2D feature map을 뽑는 부분이다. 사실 이 부분은 특별할 것이 없다. CNN 기반의 encoder 를 이용해 feature map을 뽑는 것이다. 논문에서는 EDSR-baseline이나 RDN을 사용했다고 한다. feature map은 의 shape을 가지며, 이후에 이 feature map을 개의 벡터 로 분리해서 decoding function에 사용한다. 이때, 는 의 2D space image domain에 evenly distributed 되어 있다고 가정한다.
Decoding Function ()
위의 encoder를 통해 얻은 를 가지고 predicted RGB value인 를 얻는다. 추가로, 는 continuous image의 일부, 즉 local piece를 나타낸다고 해석할 수도 있다.
evenly distributed이라는 특성을 가지는 는 좌표 와 함께 decoding function의 입력으로 사용된다.
는 모든 이미지에 대해 공유하여 사용하며, 구체적인 모델은 아래와 같이 사용한다.
- 5-layer MLP + ReLU, hidden dimension = 256
이때, 특정 좌표 에서의 픽셀 예측값(RGB value) 는 아래와 같이 쓸 수 있다. (왜 갑자기 에서 로 식이 바뀌었나? 라는 질문에 대한 대답은 아래 '질문' 섹션에 정리해놓았다. 기본적으로 는 유사한 개념이다.)
- : 주어진 좌표 에서 가장 가까운 latent code.
- : 의 coordinate.
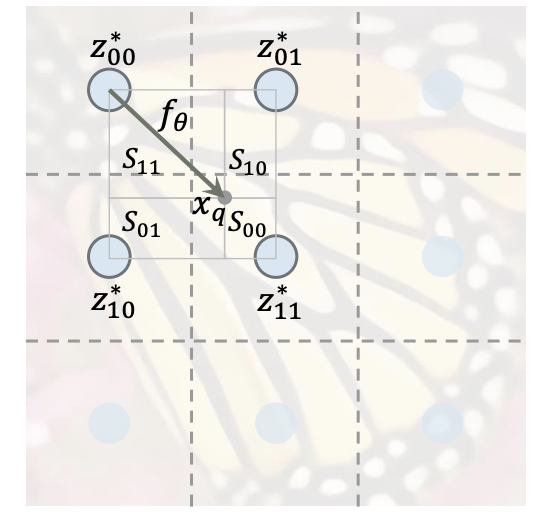
위의 그림을 통해 식을 자세히 살펴보자. 위의 그림에서 파란 점은 이전에 언급한 '2D space image domain에 evenly distributed 되어 있다고 가정한 것을 표현한 것이다. 현 상황에서 우리가 보고 있는 coordinate 에 맞는 는 이다. (에서 가장 가까운 latent code)
이것이 기본적인 decoding function의 틀이다. 이게 끝이야? 라고 생각할 수 있지만, 뒤에서 더 자세하게 살펴볼 계획이다. 지금까지 살펴 본 내용 중에 CNN 기반 Encoder의 결과물인 2D feature map 은 여전히 discrete한 상태이고, continuous함을 가능하게 하는 것은 decoding function 라는 점을 기억해야 한다.
기존의 SR은 주로 CNN 기반의 fixed resolution에 대한 해결책을 제시했다. 즉, 정해진 output image size를 가지고 각 픽셀의 위치에 맞는 예측을 하게끔 모델이 학습된 것이다. 이후에 이미지의 크기가 바뀐다면, 그것은 모두 interpolation을 이용한 것이다. 이러한 측면에서 기존 방법들이 discrete하다고 하는 것이다. 그런데 LIIF에서의 decoding function은 MLP를 이용해 continuous한 결과물을 낸다. MLP의 input이 continuous하다면, output 또한 continuous하다는 특성을 이용한 것이다. 사용하는 activation function인 ReLU도 continuous하기 때문에 우리가 원하는 continuous한 representation을 만들기 좋다.
이렇게 는 continuous한 특성을 만들어주는 LIIF의 중요한 부분이며, 뒤에 나올 feature unfolding, local ensemble, cell decoding은 decoding function이 가지는 continuous representation의 퀄리티를 더 올려주는 도구이다. 이제 위의 내용들에 대해 자세히 알아보자.
4) Feature Unfolding
Feature Unfolding은 더 rich한 feature를 통해 latent code를 더 풍부하게 만들어 주는 과정이다. 영향을 받는 부분은 2D feature map인 이다. 간단히 아래와 같이 feature unfolding을 나타낼 수 있다.
Input은 CNN 기반의 Encoder를 타고 나온 2D feature map , output은 enriched feature map 이다. 구체적인 Feature Unfolding의 식은 아래와 같다.
- zero-padding in border pixels.
식을 해석해보자. Feature Unfolding의 핵심은 특정 latent code 를 둘러싸고 있는(이웃하는) 8개의 latent code를 feature로 사용한다는 것이다. 현재 latent code 주변의 latent code들은 concat되어 이후에 enriched feature로서 사용된다. 참고로, feature unfolding을 통해 얻은 feature map은 로 표현되지만, 논문에서는 표현의 간단함을 위해 기존의 2D feature map의 표현인 로 사용한다. 라고 적혀 있어도 feature unfolding이 적용된 것이라는 점을 기억해야 한다.
Feature Unfolding을 통해 결과적으로 모델이 더 많은 feature를 보기 때문에 더 좋은 성능을 낼 수 있을 것이다.
5) Local Ensemble
다음은 Local Ensemble이다. 우리가 현재까지 살펴본 아래와 같은 식
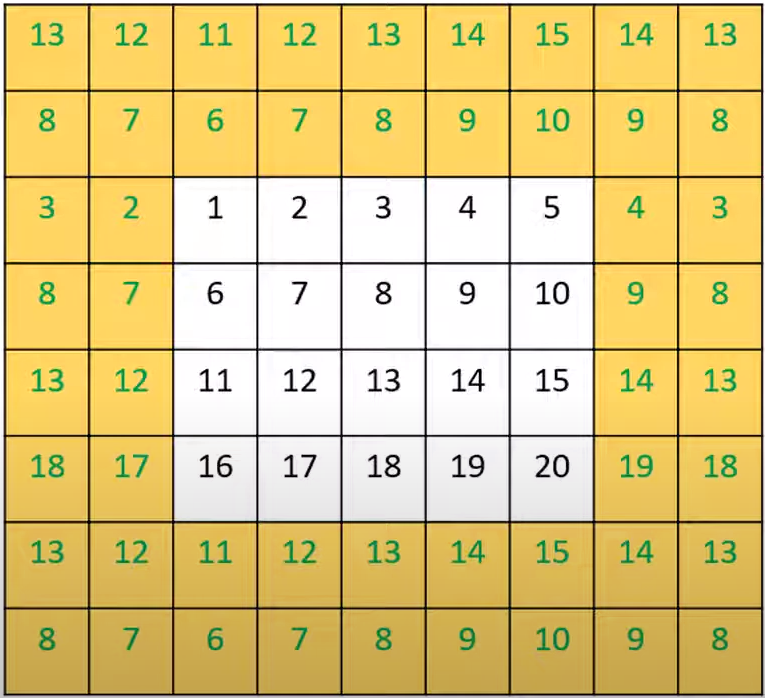
을 사용하면 Discontinuous Prediction이라는 문제점이 생긴다. 아래 사진을 보며 이해해보자.
사진과 같이 가 주어진다면, 이 될 것이다. 우리가 집중해야 할 것은 사진 내부의 점선이다. 만약 가 점선에서 아주 가까운 곳에 있다가 점선을 살짝 넘어간다면 어떻게 될까? 가 굉장히 조금 바뀌었음에도 는 바뀌게 될 것이다. 그러면 의 값에도 영향이 갈 것이다. 이런 것이 바로 discontinuous prediction이다. 실제 좌표는 굉장히 미미하게 바뀌었음에도 의 변화에 따라 값도 확 바뀌게 될 것이니 말이다. Local Ensemble은 이러한 Discontinuous Prediction을 해결하기 위한 도구이다. 그 식은 아래와 같다.
이때, 사용하는 는 border 주변의 값들이 원활히 계산될 수 있도록 mirror padding 되어 있는 상태이다. 아래와 같이 padding하는 방식이 mirror padding이다. border 바깥쪽의 padding 값들이 거울처럼 border 안쪽의 값들이 반사된 것 같은 값을 갖는 것이 특징이다.
식의 형태는 비슷하지만, 앞에 가 붙었다. 위의 용어 정리에서 살펴봤듯이,
- : 가 이루는 직사각형의 면적의 넓이
- : t에 대해 대각선에 있는 점의 좌표
ex)- : 가장 가까운 의 대각선에 있는 점의 좌표
를 의미한다. 가 어떻게 계산되는지 예시를 통해 알아보자. 만약 위 사진에서 이라고 한다면, 이 될 것이다. 그러면 이고, 우리가 구하는 면적 : 까지의 면적일 것이다.
자세히 보면, 는 confidence와 같은 역할을 한다. 우리가 살펴본 예시에서 이었는데, 에서 은 멀기 때문에 면적이 작다. 반대로 상대적으로 가까운 좌표 에서는 면적인 이 큰 것을 알 수 있다. 이와 같은 식의 설계를 정리하면 아래와 같다.
- Local Ensemble에 사용되는 주변 4개의 latent code 들은 와의 거리에 따라 다르게 weighting이 적용된다.
- 에서 latent code가 멀수록 적은 면적을 주어 최종 에 영향을 적게 주도록 하고, 에서 latent code가 가까울수록 더 많은 면적을 주어 영향을 더 많이 주도록 설계한 것이다.
- 이러한 설계가 는 confidence 혹은 weight로 작동해 더 부드러운 prediction이 가능하게 해준다.
의 변화에 영향을 많이 받았던 기존의 방법의 문제점을 해결하고자 주변 4개의 latent code를 거리에 따른 weight로 그 영향력을 조절해 조금 더 continuous한 prediction을 만들어 낸 것이 Local Ensemble의 핵심이다.
6) Cell Decoding
마지막으로 살펴볼 은 cell decoding이다. 기존의 식
은 모델이 어떤 scale로 SR이 진행되는지에 대한 정보가 없다는 문제가 있다. 이러한 문제를 해결하고자 scale에 대한 정보를 예측에 활용한 것이 Cell Decoding이다. Cell Decoding이 어떻게 작동하는지 자세히 알아보자.
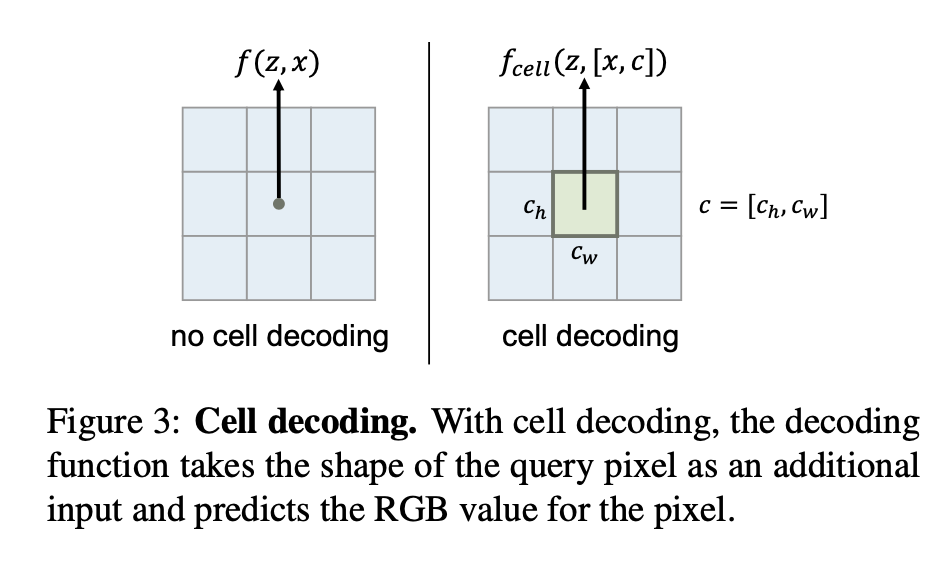
기존의 방법은 위 사진의 좌측 그림과 같이 pixel center의 좌표만 가지고 를 예측했다. 그런데, Cell decoding은 query pixel의 height()와 width()를 알려주는 를 좌표 와 함께 제공해 더 정교한 예측이 이루어질 수 있도록 한다. cell decoding에서 사용하는 는 이라고 표현하며, 식은 아래와 같다.
는 를 concat하라는 뜻임.
은 shape 로 coordinate 에서의 pixel center를 rendering 했을 때의 RGB 값을 의미하는 것이다. '지금 예측할 RGB value는 이 정도 크기의 영역을 대표해야 해' 라는 것을 알려주는 것으로도 cell decoding을 해석할 수 있을 것 같다.
7) Training
이제 training에 대해서 알아보자. 전체적인 구조도는 아래 사진과 같다.
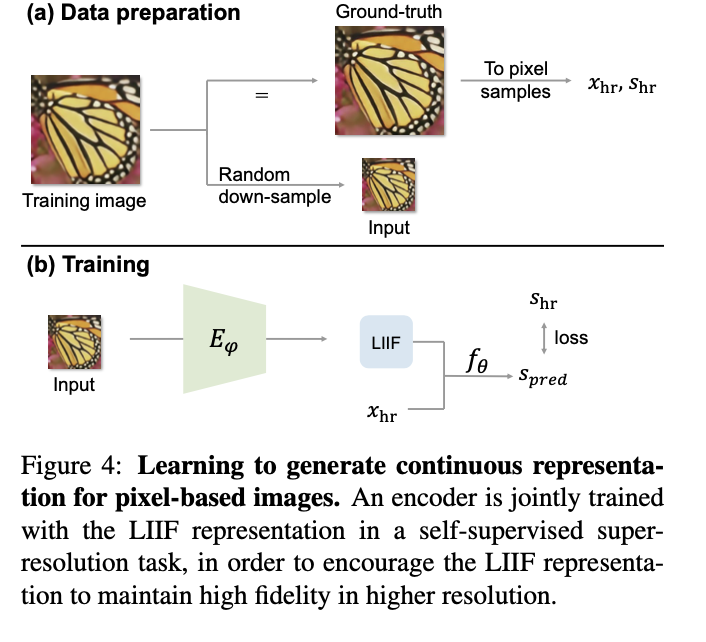
- Training image를 random scale로 down-sampling한다.
- Ground Truth: down-sample되지 않은 원본 training image를 pixel sample ( 로 나타낸다.
-> : image domain에서 pixel의 center coordinate.
: pixel에서의 RGB value.- Encoder 는 input image (1번에서 down-sample한 이미지)를 이용해 2D feature map을 만든다.
- feature unfolding, local ensemble, cell decoding, 그리고 decoding function을 통과하고 난 뒤에 predicted image인 를 얻는다.
- 를 이용해 LIIF representation에서의 해당 pixel을 query하고, ground truth인 과 의 L1 loss를 계산한다.
8) Implementation Details
Datasets
사용한 데이터셋들을 알아보자.
- Dataset : DIV 2K dataset.
-> 1000 images, 2K resolution with LR counterparts (bicubic down-sample scale: x2,x3,x4)- Training Data : 800 images from DIV 2K.
- Testing Data : 100 images from DIV 2K, Set5, Set14, B100, Urban100.
Evaluation
평가는 scale에 따라서 달라진다. LIIF가 x30 scale까지 유의미한 성능을 보여주기 때문에, x30까지의 scale에 대해 in-distribution과 out-of-distribution에 대해 나누어서 평가를 한다. 이때, in-distribution은 training때 보았던 x1~x4, out-of-distribution은 training때 보지 못했던 x6~x30 scale에 대한 평가이다. 이러한 평가 방식의 포인트는 모델이 training 때 보지 못한 임의의 scale에 대한 generalization 성능을 보겠다는 것이다.
Implementation Details
이제 구체적인 모델 세팅과 설정에 대해 알아보자.
- Encoder input : 48x48 patches
- (batch size)개의 random scale (scale을 의미)을 에서 sampling.
-> 은 uniform distribution을 의미함. (scale x1~x4 사이에서)- training image에서 개의 patch를 의 크기로 crop한다.
-> 이때, 이들의 LR counterpart는 이전에 뽑아놓은 48x48 크기의 patch들이다.- GT : training image에서 pixel sample 개, 즉 (coordinate, RGB value) pair를 뽑는다.
-> 이렇게 GT를 사용하는 이유는 하나의 batch에서 image scale이 여러 개이기 때문에, 같은 개수의 pixel들로 성능을 평가하기 위해서이다.- Encoder : EDSR-baseline or RDN (feature map size = input size가 되도록 설정)
- decoding function : 5-layer MLP with ReLU, hidden dimension=256
- Loss : L1 loss
- down-sampling : bicubic resizing with Pytorch.
- Optimizer : Adam, initial lr =
- 1000 epochs, batch size = 16, lr decay by 0.5 every 200 epochs
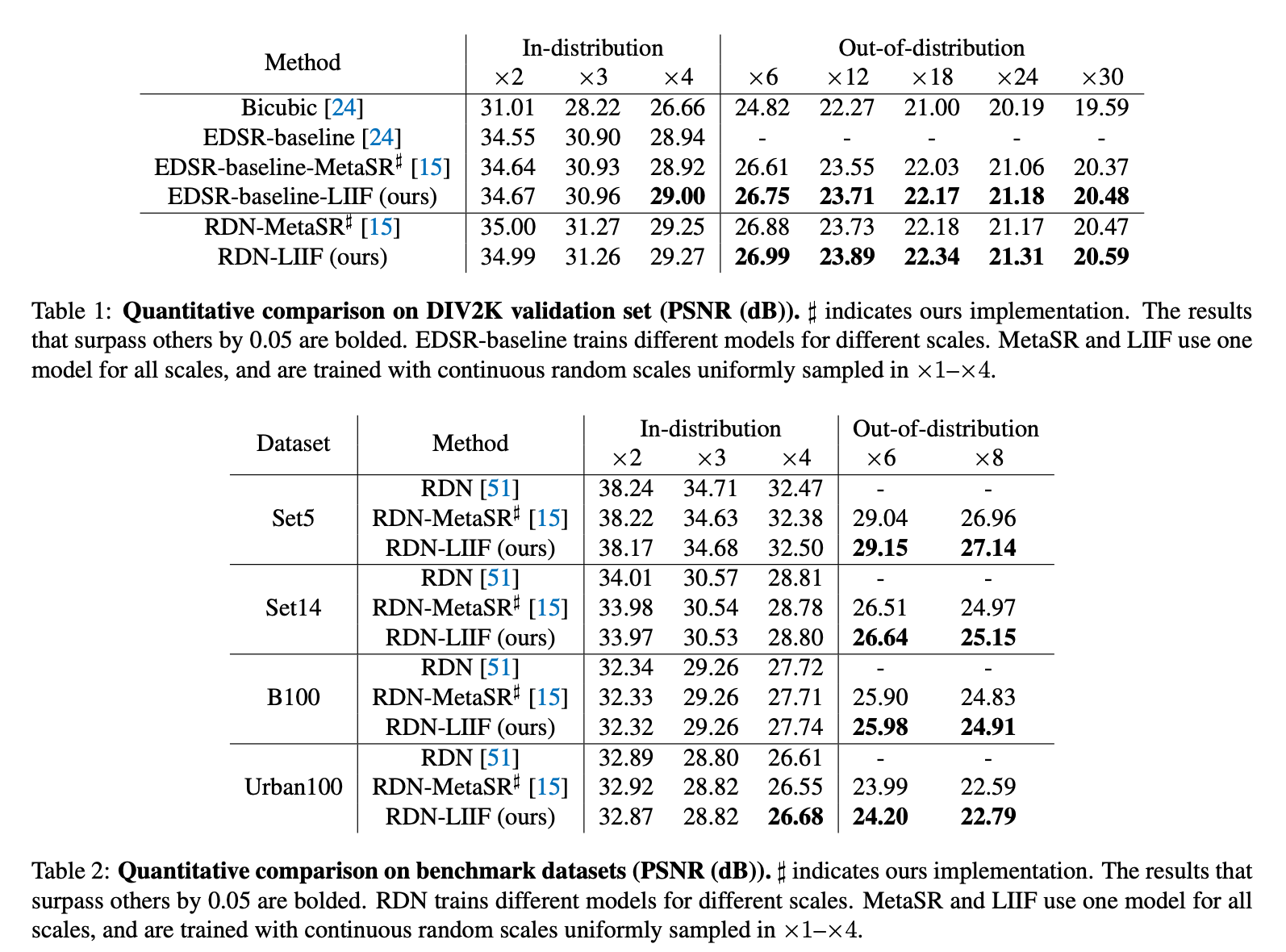
9) Results
Quantitative Results
Qualitative Results

3. 더 찾아볼 내용 및 질문
1) 질문
-
왜 에서, 를 하는 것일까?
LIIF는 기본적으로 특정 feature 주변의 local latent code를 이용해 더 자연스러운 SR output을 만드는 것이 목표이다. 때문에 decoding function으로 예측을 할 때에도 주변의 local latent code coordinate이 반영되어야 하는 것이다. 때문에 가장 가까운 의 coordinate인 를 사용해 relative coordinate을 사용한다.
-
와 의 차이는 무엇인가?
두 식을 보면 '거의 비슷한데, 무슨 차이지?' 라는 의문이 생긴다. 정확히 알지는 못하지만, 는 개념적인 내용을 나타내는 식이고, 는 실제 구현한 식을 의미하는 것 같다. 또, 논문에서는 는 전체 이미지 예측값을 나타낼 때, 는 특정 픽셀의 예측값을 나타낼 때 사용한다. (와 의 차이에서도 이러한 점이 드러난다.)
2) 더 찾아볼 내용
- CARN
- SwinIR
