이번에 리뷰해 볼 논문은 ViT 논문으로도 유명한 2021년에 나온 "An Image Is Worth 16x16 Words: Transformers For Image Recognition At Scale" 이라는 논문이다. NLP 분야에서 사실상 Transformer Architecture가 standard가 되었지만, 비전 분야에서의 활용은 제한적이었다. 논문 내용을 더 자세하게 살펴보자.
1. 저자가 이루려고 한 것
앞서 언급했듯이, Tranformer 계열의 모델들을 비전에 적용시키는데에는 한계가 있었다. 저자는 이 Tranformer 구조를 Image Recognition에 효과적으로 적용하고, 좋은 성능을 내고자 했다. 비전에서는 이전까지 CNN+ attention의 구조로 attention을 활용하고 있었다. 저자는 CNN에 대한 의존성이 더 이상 필요하지 않고, transformer로만 모델을 구성했다. transformer와 거의 비슷한 형태를 취하며, 다른 점이라면 word embedding 대신에 image patch sequence를 transformer의 input으로 준다는 것이다. 이러한 모델의 구조 때문에 모델의 이름 또한 Vision Transformer(ViT)가 되었다.
2. 개념 정리
본격적인 논문 내용에 들어가기 앞서, 내가 몰랐던 개념들을 정리하고 넘어가려고 한다. GELU, Inductive Bias, translational equivariance, translational invariance 정도를 살펴보면 될 것 같다.
1) GELU( Gaussian Error Linear Unit)
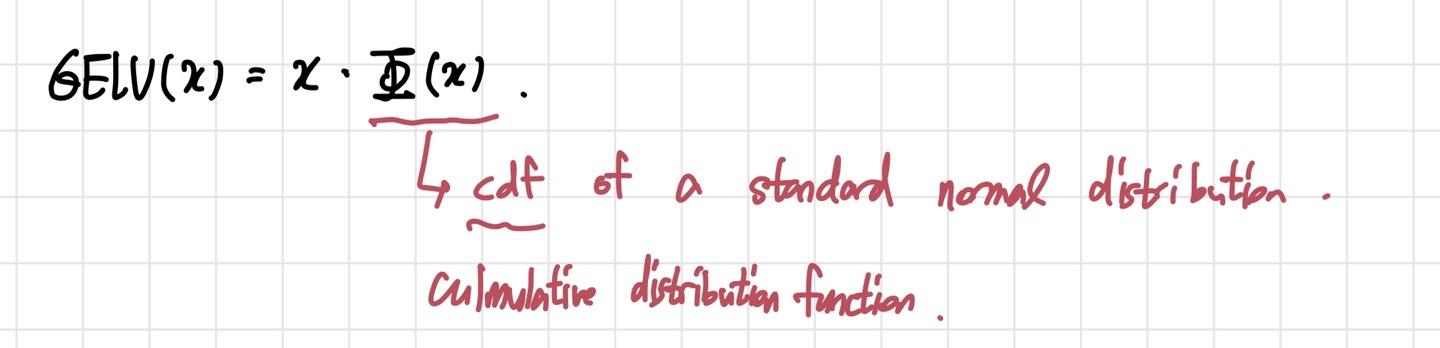
GELU는 이름에서부터 ReLU와 비슷한 느낌이다. 실제로, ReLU를 대체할 수 있는 activation function으로 사용된다. ViT 모델에서 MLP의 non-linearity로 ReLU 대신 GELU가 사용된다. 구체적인 식은 아래와 같다.

이때, 는 mean=0, variance=1인 정규분포의 cdf를 뜻한다. (mean=0, variance=1인 정규분포는 z-distribution이라고도 표현된다.) 그러나 실제로 GELU를 사용할 때는 위의 식을 아래의 식으로 근사해 사용한다고 한다.

GELU의 장점은 그래프를 그려보면 알 수 있다.
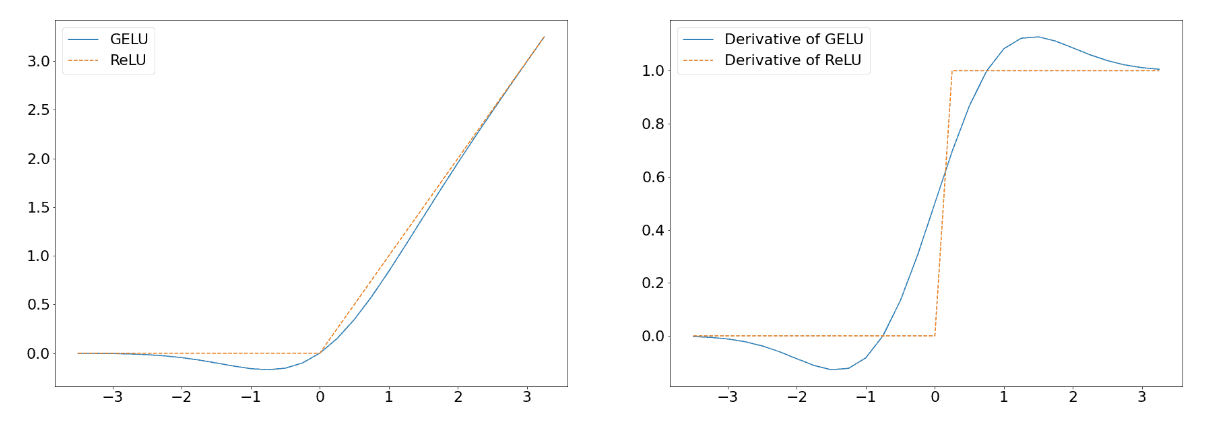
위의 그래프를 보면, GELU의 gradient 변화가 ReLU보다 훨씬 부드러운 것을 볼 수 있다. 그렇기 때문에 vanishing gradient problem을 ReLU보다 더 잘 해결할 수 있고, 모든 input value에 대해 부드러운 형태를 가지고 있기 때문에 효과적으로 데이터를 다룰 수 있다.
2) Inductive Bias
Inductive Bias라는 표현은 논문을 읽다보면 자주 만날 수 있다. 말이 되게 어려워보이지만, 개념을 알고 나면 어렵지 않다. Inductive Bias는 우리가 만드는 머신러닝 모델이 training data를 학습하고 input(data)과 output(label)의 관계를 추정하는데 사용하는 모든 방법들을 일컫는 말이다. 즉, 우리가 모델을 만들때 사용하는 대부분의 방법들은 Inductive Bias인 것이다.
Strong inductive bias를 가지고 있다면 우리가 원하는 global minimum에 수렴할 가능성이 높아진다. 반대로 weak inductive bias를 가지고 있다면 근처 local minima에 수렴될 가능성이 높아지고, initial state의 변화에 굉장히 민감하게 반응하게 된다.
3) Translation Equivariance & Translation Invariance
translation eqiuivariance는 input이 translate되는 것에 따라 output도 translate 되는 것을 말한다. 여기서 translate는 shift와 같은 의미이다. 즉, input이 바뀌면 output도 바뀌는 특성이라고 생각하면 될 것 같다. CNN은 기본적으로 translation equivariant한 특성을 가지고 있다. filter를 슬라이딩하면서 데이터를 학습하기 때문이다. 이미지 내의 object 위치가 바뀐다면, feature map 또한 위치의 영향을 받아 바뀔 것이다.
반면 translation invariance는 input이 translate되어도 output에는 지장을 주지 않는 특성을 의미한다. 모델이 translation invariant하다는 것은 큰 장점이다. input의 위치가 바뀌어도 영향을 덜 받는다는 뜻이니, input의 변화에 robust하다고 볼 수도 있다. CNN에서 이미지 내의 object들을 인식할 때 object들의 크기와 위치가 다 다르기 때문에, 이 특성을 CNN이 갖게 하는 것이 성능 개선에 큰 포인트가 된다. CNN에서는 translation invariant한 특성을 갖게 하려고 pooling과 같은 방법들을 사용한다.
3. 주요 내용
Self-Attention에 기반을 둔 Transformer architecture가 2017년에 등장한 후, NLP task에서의 가장 지배적인 접근은 큰 text corpus에서 pre-train을 시킨 후, 우리가 해결하려는 task-specific dataset에 fine tuning을 시키는 방법이었다. 쉽게 말하자면 큰 데이터셋에서 훈련을 시키고, 우리 문제를 해결하기 위한 작은 데이터셋에서 한 번 더 훈련을 시키는 것이다. tranformer의 computation 효율성 덕분에 이러한 방법이 가능해졌다. 비전 분야에서도 이러한 방법을 사용해 self-attention만으로 성능을 개선해보려는 시도가 있었으나, ResNet 계열의 Architecture를 능가하지 못했다.
저자가 논문에서 제안하는 ViT는 transformer의 장점과 성능을 모두 잡았다. 또한 ViT는 encoder-decoder 구조인 transformer와 달리, 글을 생성해낼 필요가 없고 classification만 진행하면 되기 때문에 transformer encoder만을 사용한다. encoder 구조는 transformer와 거의 유사하다. 글 후반부에 더 자세하게 다루겠지만 ViT를 mid-sized dataset(e.g. ImageNet)에서 훈련시켰을 때, 비슷한 크기의 ResNet보다 약간 낮은 성능을 보인다. 그 이유는 transformer 구조가 CNN에 내재하는 inductive bias가 부족해서이다. CNN이 가지고 있는 translation equivariance와 locality는 이미지 데이터를 다룰 때 좋은 성능을 내게 해주는 요인 중 하나이다. 그런데 transformer에는 이러한 특성이 없기 때문에 충분한 데이터가 주어지지 않으면 성능이 떨어지는 것이다. 물론, 충분히 큰 dataset에서 훈련시킬 경우, ViT는 Inductive bias를 극복하고 ResNet보다 좋은 성능을 내긴 한다.
1) Method
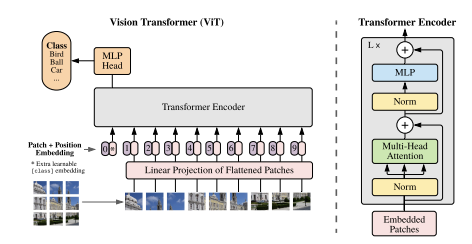
위의 사진은 ViT의 구조도이다. 기존 transformer에서 1D vector로 받았던 input이 2D 이미지에 적용되어야 하기 때문에 image를 reshape해주어야 한다. shape의 2d image를 로 reshape를 해준다. 이때 은 patch의 개수, 는 patch의 크기이고, 의 관계를 갖는다. 이렇게 되면 크기의 벡터가 sequence 형태로 개 생기는 것이다.
또한, transformer의 residual connection을 가능하게 하기 위해 latent vector들의 차원을 d_model로 동일하게 해준 것처럼 ViT도 만든 patch들을 linear layer를 통해 flatten해주어 동일한 차원을 갖게 만들어 준다. 이 과정을 통해 나온 output이 patch embedding이다. transformer의 word embedding에 해당하는 구조라고 생각하면 이해하기 좋을 것 같다.
여기에 추가로 BERT에서와 같이 class token이라는 것이 사용되는데, class token은 모든 patch들의 정보를 집약해서 나타내주는 learnable embedding이다. 이 class token은 sequence 앞쪽에 추가된다. 그리고 transformer 구조는 position에 대한 정보가 없기 때문에 image patch의 위치 정보를 알려주는 positional embedding을 patch embedding에 더해준다. 이렇게 만들어진 input이 transformer encoder로 들어가게 된다. encoder의 output은 classification head를 거쳐 classification 값을 뱉어낸다. classification head는 pre-training 때는 1 hidden layer로 구성된 MLP로, fine-tuning 때는 하나의 linear layer로 구성된다.
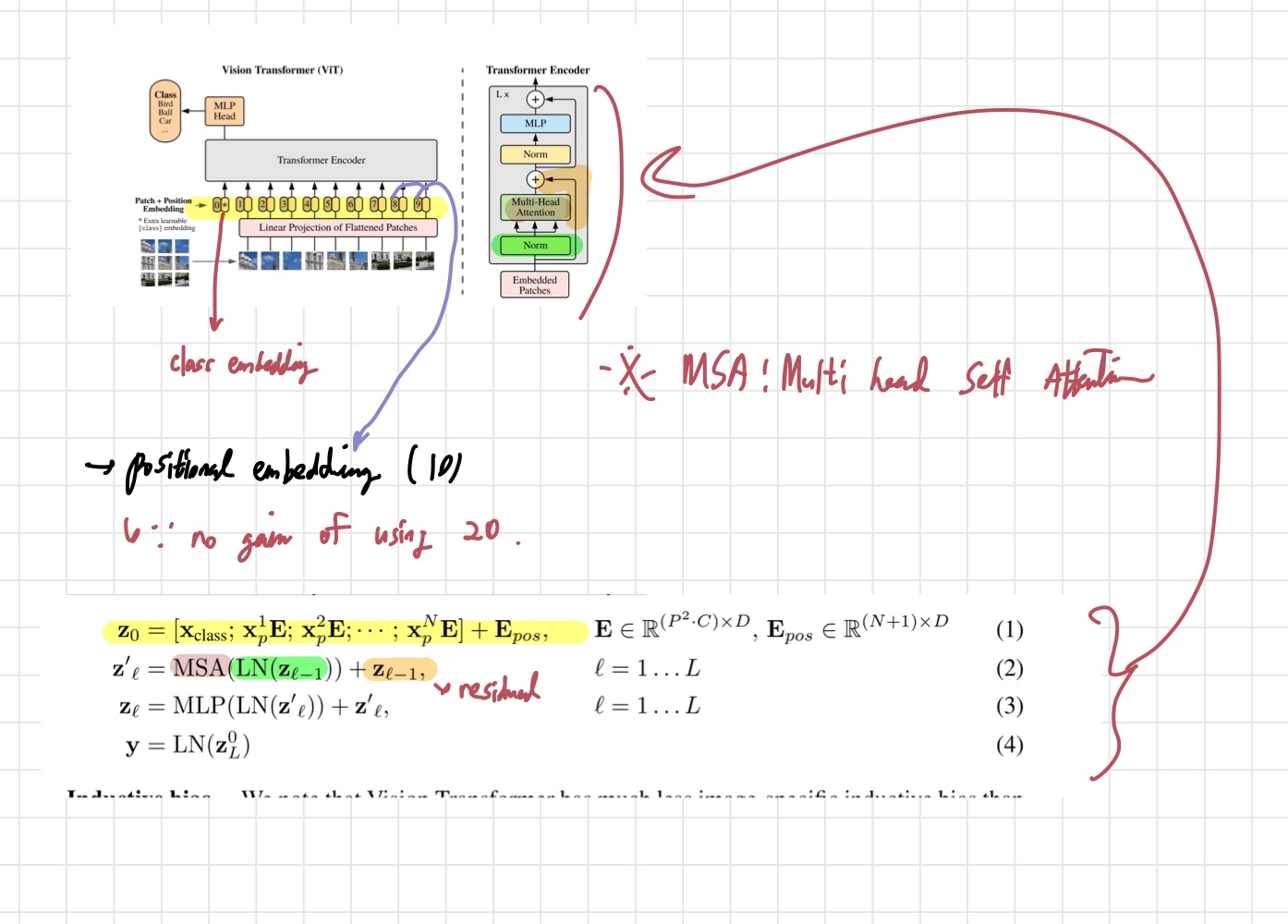
위의 사진은 논문의 식들이 구조도에서 어떤 부분을 나타내는지 표현한 사진이다. 내가 직접 그려 그렇게 깔끔하진 않지만 이해에 도움이 되긴 했다. 는 이미지 data 에 patch embedding과 positional embedding을 나타낸 식이다. 앞서 언급했던 것처럼 class token이 맨 앞에 추가된 것을 볼 수 있다. 각 patch 에 를 곱해 (N,D) 크기로 차원을 맞춰는 것도 확인할 수 있다. 그 이후에는 일반적인 transformer encoder와 같이 MSA-> MLP를 거치게 된다. 이것이 ViT가 데이터를 처리하는 기본적인 방법이다. 다음으로, ViT가 가지는 특성들에 대해 살펴보자.
i) Inductive Bias
ViT는 클래식한 CNN들에 비해 image - specific inductive bias가 부족하다. CNN의 locality, 2D neighborhood 구조, translation equivariance는 각 layer마다 만들어지고, 이것이 좋은 성능을 얻게 해주는 중요한 요인 중 하나가 된다. 그러나 ViT는 MLP 구조만 locality와 translation equivariance의 성질을 갖는다. self-attention layer들은 global 하기 때문이다.
ii) Fine tuning and higher resolution
ViT는 pre-training을 사이즈가 큰 dataset에서 마치고, 더 작은 downstream task에 대해 fine-tuning을 한다고 언급했었다. fine tuning시에는 pre-train에서 사용된 prediction head를 제거하고, 의 feedforward layer를 추가한다. 는 downstream task의 class 수를 뜻하며, 새로 추가된 layer의 weight들은 모두 0으로 초기화한다. fine tuning을 할 때에는 pre-training때 사용했던 것보다 높은 resolution의 이미지를 이용하는 것이 효과적이라고 한다. 단, patch size는 pre-training때와 같게 한다. 이렇게 하면 patch sequence가 길어질 것이다.
이렇게 resolution이 커지면 생각해야 될 것이 하나 더 있다. pre-training 때 사용했던 positional embedding은 resolution이 바뀌었기 때문에 더 이상 의미있는 정보를 주지 않는다는 것이다. 이를 해결하기 위해 positional embedding에 2D interpolation을 적용해 키워진 해상도에 맞는 positional embedding 정보를 사용한다.
2) Experiments
저자는 ResNet, ViT, hybrid(ResNet+ViT)의 학습 능력을 평가하는 실험을 진행한다. pre-training에 사용한 dataset은 ILSVRC-2012 ImageNet, ImageNet-21k, JFT이다. 그리고 나서 더 작은 dataset인 ImageNet, ReaL Labels, CIFAR-10/100, Oxford-IIIT Pets, Oxford Flowers-102, VTAB에 fine tuning을 진행한다.
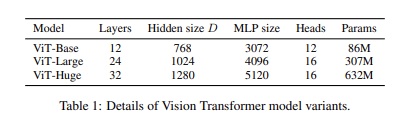
기본적으로 논문에 등장하는 ViT 모델은 BERT의 Base와 Large 모델을 따르며, 여기에 저자는 Huge 모델을 추가해서 사용한다. 논문에서 사용하는 ViT-L/16과 같은 식의 notation은 해당 모델이 ViT-L이고, input patch size=이라는 뜻을 담고 있다. 이때 (patch size의 제곱)= computation 양에 반비례한다. 따라서 patch size가 작으면, 계산량이 많아지는 것이다. 이는 직관적으로 생각해도 이해할 수 있다.
저자는 baseline CNN으로 ResNet을 사용하는데, 기존 ResNet의 BN-> Group normalization으로 바꾸고, standaradized convolution을 이용한다. 이런 방식으로 수정된 모델을 논문에서는 ResNet(BiT)라고 표현한다. hybrid 모델은 ResNet에서 얻은 intermediate feature map을 ViT에게 먹이고, patch size는 1로 설정하여 실험을 한다. 이때 다양한 길이의 sequence를 이용해 실험하기 위해 2가지 방법을 사용한다.
i) ResNet의 stage 4의 feature map을 빼온다.
ii) ResNet의 stage4를 없애고, 그 자리에 stage3 layer를 넣는다.(이를 extended stage3라고 한다) 그리고 extended stage3의 output을 빼온다.
방법 ii)가 4배 더 긴 sequence를 가지고 있으며 계산량도 더 많다. 여기서 언급되는 ResNet stage는 아래 표에서 보다시피 layer의 특정 부분들을 뜻하는 표현이다.
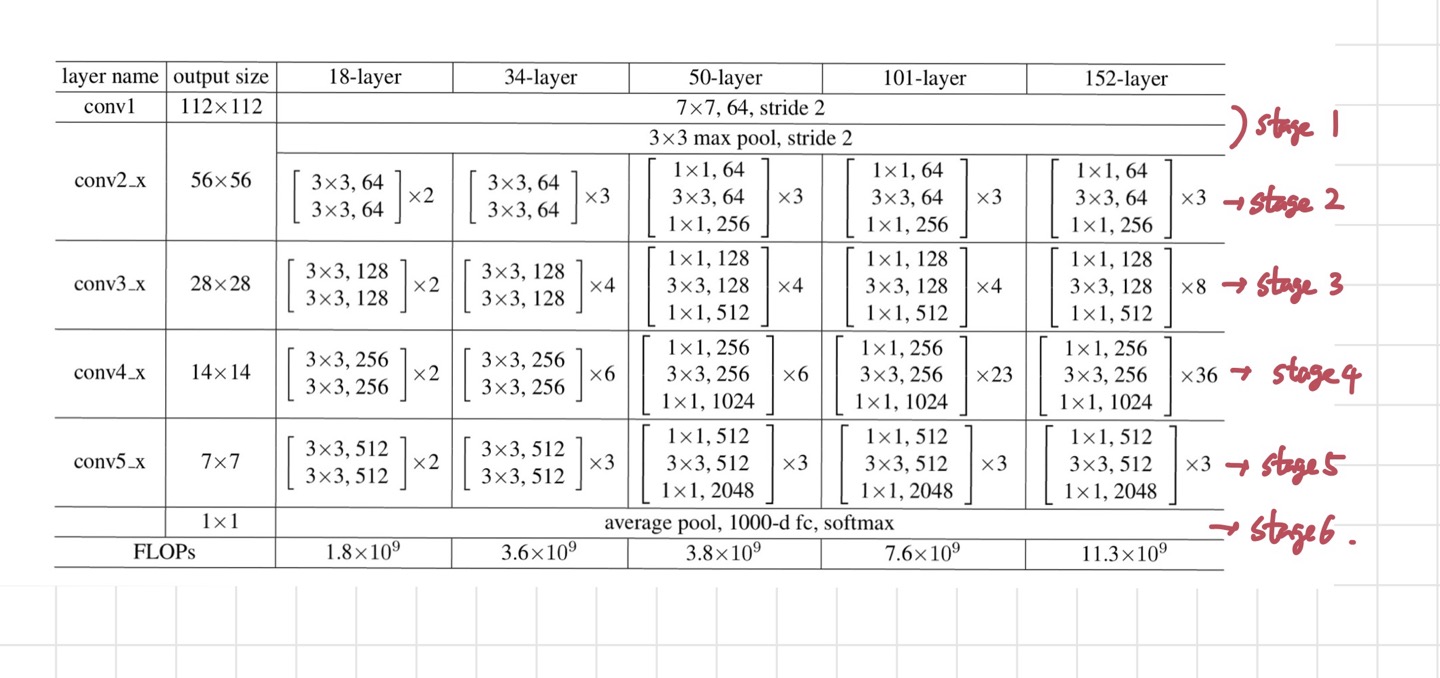
위의 사진의 빨간 글씨로 써진 stage들이 논문에서 사용하는 stage들에 해당한다. 다음으로 모델들을 training할 때 사용하는 기법들에 대해 알아보자. pre-training과 fine tuning의 방법이 살짝 다르기 때문에 나누어서 보아야 한다.
Pre-training:
- Adam optimizer(beta1=0.9, beta2=0.999)
- batch size=4096, weight decay=0.1
- linear learning rate warm up& decay
Fine tuning:
- SGD+ momentum
- batch size=512
- Polyak averaging 0.9999
이제 SOTA CNN들과 ViT-L/16, ViT-H/14의 성능을 비교해보자. JFT에 pre-train된 ViT-L/16은 모든 task에서 BiT-L 보다 좋은 성능을 내고, training할 때 훨씬 적은 computation을 필요로 한다. ViT-H/14는 ViT-L/16보다 더 좋은 성능을 낸다. ViT-H/14는 이전의 SOTA보다 pre-train하는데 필요한 계산량이 훨씬 더 적다는 점도 놀랍다.
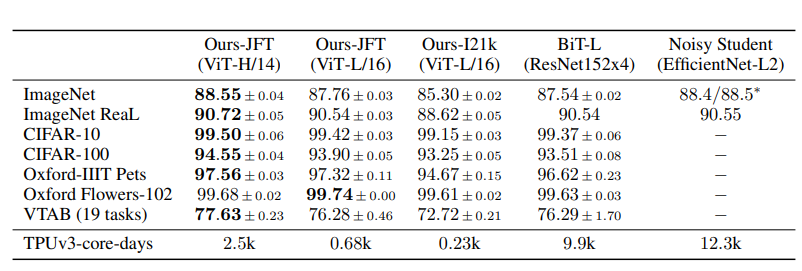
이렇게 ViT의 성능이 이전 SOTA보다 전반적으로 우수하다는 사실을 확인했다. 위의 표에서 성능이 가장 우수한 모델은 크기가 가장 큰 dataset(300M 크기를 가짐.)인 JFT에 pre-train한 모델이다. ViT가 크기가 큰 dataset에서 좋은 성능을 발휘하는 것을 관찰하고, 저자는 dataset의 크기가 성능에 얼마나 영향을 미치는지 알아보는 두 가지 실험도 진행했다. 첫 번째 실험에서는 ViT 모델들을 pre-training할 때 사용하는 dataset의 크기를 점점 늘려가는 실험이었고, 두 번째 실험은 JFT에서 subset을 9M,30M,90M,300M(원래의 JFT) 크기로 뽑아 훈련시키고 성능을 비교한다.
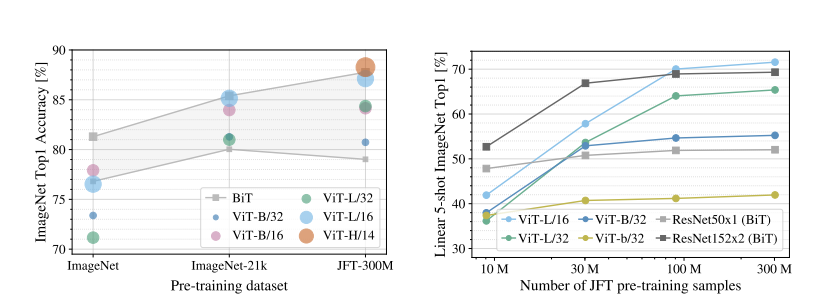
왼쪽 그래프는 첫 번째 실험의 결과, 오른쪽 그래프는 두 번째 실험의 결과를 나타낸 것이다. 첫 번째 실험은 ImageNet, ImageNet-21k, JFT-300M에서 모델들을 훈련하고 그 성능을 비교한다. regularization은 weight decay, dropout, label smoothing을 적용했다. 왼쪽의 그래프를 보면, 가장 크기가 작은 ImageNet에서 훈련했을 때에는 regularization을 했음에도 불구하고 ViT-L 계열 모델들이 ViT-Base 계열 모델들보다 성능이 낮다는 것을 알 수 있다. 심지어 CNN base의 BiT가 더 좋은 성능을 낸다. ImageNet-21k에서 훈련을 진행했을 때에도 상황은 비슷하다. JFT에서 훈련했을 때 비로소 크기가 큰 모델들의 효과를 볼 수 있는 것이다.
다음으로 두 번째 실험에 대해 살펴보자. 여기서는 regularization은 사용하지 않고(Early Stopping은 사용한다.), hyperparameter 세팅도 동일하게 한 상태에서 실험을 진행한다. 다른 요인보다는 모델 내의 요소들을 평가하겠다는 의도이다. 실험 결과, 데이터 셋의 크기가 작을 때는 ViT 모델들이 ResNet들보다 overfitting에 취약하다고 한다. 오른쪽 그래프에서 ViT의 성능이 데이터셋의 크기가 커지면 커질수록 급격하게 증가하는 것 또한 눈여겨 볼 만하다. 저자는 이 실험을 통해 convolutional inductive bias는 dataset의 크기가 작을 때는 효과적이지만, 크기가 커질수록 좋지 않다는 결론을 내렸다.
3) Scaling Study
Scaling Study는 parameter가 변함에 따라 모델의 성능이 어떻게 변하는지 살펴보는 파트이다. 저자는 performance와 pre-training cost간의 관계에 대해 탐구하는 것에 집중한다. 두 개념은 trade-off 관계를 가진다. 성능이 높아지려면 어느 정도 pre-training cost는 감수해야 한다는 뜻이다. 실험에서는 여러 모델들을 JFT-300M에 훈련시킨 후 downstream task에서의 transfer performance를 비교한다.
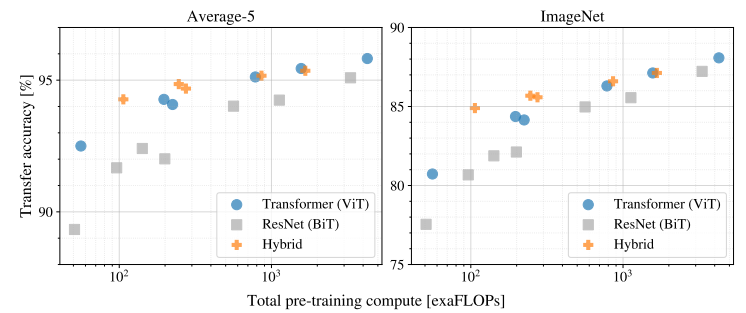
위의 왼쪽 그래프에서 average-5는 5개의 dataset에서 훈련시킨 accuracy의 평균값을 의미한다. 사용한 모델은 아래와 같다.
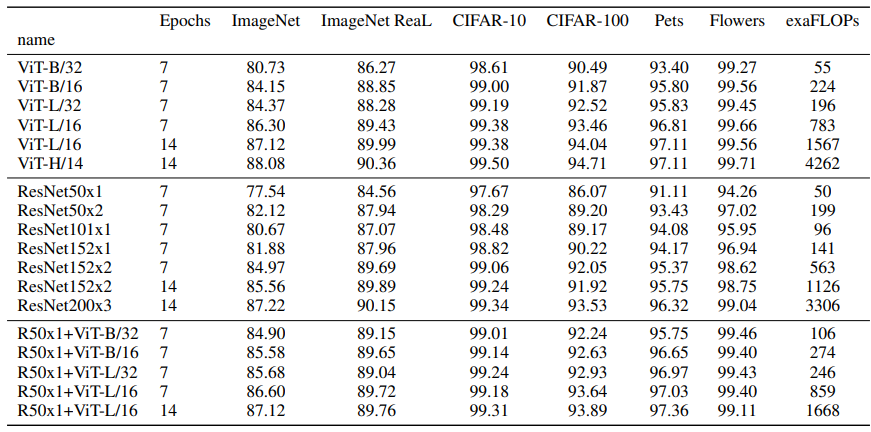
ViT 계열의 모델 7개, ResNet 계열의 모델 6개, hybrid 계열의 모델 5개를 사용했고, 위의 표는 각 모델별로 downstream dataset에 대한 성능을 보여준다. 표와 위의 그래프를 보면, performance/compute trade-off 면에서 ViT가 ResNet보다 훨씬 좋은 결과를 낸다는 것을 알 수 있다. ViT는 ResNet에서 사용하는 computation의 2-4배 적은 양을 사용하면서 똑같은 성능을 얻는다. 여기서 중요한 것은 저자가 시도해본 실험들 내에서는 ViT의 saturation이 일어나지 않았다는 것이다. 꽤 큰 dataset에 훈련을 시켰음에도 saturation이 일어나지 않은 것은 상당히 인상깊다.
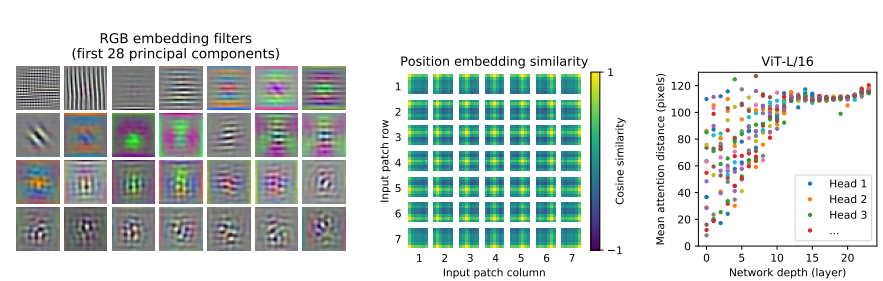
마지막으로 ViT 내부에서는 어떤 일이 일어나고 있는지에 대한 내용이다. 왼쪽 사진은 ViT의 첫 번째 layer의 linear embedding filter들을 시각화한 것이다. CNN의 초반 layer를 시각화한 것과 같이 low level feature들을 잘 잡고 있는 것 같이 보인다. 가운데 사진은 position embedding silmilarity에 기반해서 모델이 distance를 encode하는 방법을 학습한다는 것을 보여준다. 저자는 ViT에 self-supervision pre-training을 적용해 어느 정도 성과를 내기도 했지만, 여전히 supervised pre-training보다 4% 낮은 accuracy이다. 앞으로 더 연구되어야 할 주제이다.
3. 논문 내용의 실용성
ViT 계열 모델들은 현재까지 ImageNet SOTA를 지키고 있다. 그런 의미에서 이 논문이 가지는 의미는 상당한 것 같다. 이전까지 Image Classification task들에서는 ReSNet 계열의 모델들이 SOTA를 차지하고 있었다. 그러나 ViT architecture가 등장하고, Image Classification에 transformer 구조를 적용할 수 있게 되면서, CNN based architecture보다 더 좋은 성능을 내게 되었다. 또 하나 중요한 것은 computational resource를 많이 사용하지 않았다는 점이다. ViT는 같은 크기의 ResNet보다 2-4배 적은 computation을 사용하면서 같은 성능을 내기 때문이다. 다시 한 번 transformer 구조의 위대함을 느끼게 되었다. 지금까지 SOTA를 지키고 있기 때문에, 이 후에 나온 ViT 계열 논문들도 한 번 읽어봐야겠다는 생각이 들었다.
