이번에 살펴볼 논문은 SimCLR 구조를 제안한 "A Simple Framework for Constrastive Learning of Visual Representations,Chen et al.(2020)" 이다. SimCLR은 간단한 contrastive self-supervised learning 알고리즘을 통해 당시 SOTA보다 더 좋은 성능을 낸 architecture이다. SimCLR은 특별한 구조나 메모리를 사용하지 않고도 구현이 가능하다. 더 자세히 알아보자.
1. 저자가 이루려고 한 것
SimCLR 이전의 인간의 supervision 없이 효과적인 visual representation을 배우는 것은 쉽지 않았다. 제안된 방법들은 꽤 복잡하고 pretext task를 설계하기 위해 경험에 의존하는 경향이 있었다. 이 당시 SOTA는 latent space에서 contrastive learning을 이용하는 방법이었다. 저자는 이러한 contrastive learning을 간단한 구조로 훈련시킬 수 있는 framework를 제안하였다. 그 결과, 당시 SOTA를 제치고 더 좋은 성능을 낼 수 있었다. 추가적인 architecture나 메모리가 필요하지 않다는 점이 아주 큰 장점이다.
2. 주요 내용
Architecture
먼저 SimCLR의 구조를 살펴보자.
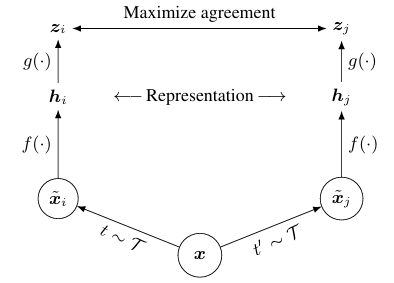
위의 사진이 SimCLR의 구조를 나타낸다. framework를 구성하는 부분은 다시 4가지(Data Augmentation, Base Encoder, Projection Head, Contrastive Loss)로 나누어 볼 수 있다. 하나하나씩 간단히 살펴보고, 각 부분을 더 파고 들어가 보려고 한다.
1) Data Augmentation
논문에서는 'Stochastic Data Augmentation'이라는 표현을 사용한다. 하나의 data sample에 랜덤하게 2개의 augmentation 테크닉을 적용한다. 랜덤한 특성 때문에 stochastic이 붙은 것이다. 이렇게 해서 각각 다른 augmentation 방법을 사용한 와 를 얻는다. 저자는 와 를 positive pair라고 표현한다. 여기까지 이해하면, 자연스럽게 어떤 augmentation 테크닉을 사용하는지 궁금해진다.
i) random cropping-> 원래 사이즈로 resize
ii) random color distortion
iii) random Gaussian blur
위의 세 가지 방법 중 하나를 랜덤하게 골라서 와 를 만드는 것이다. 실험한 결과, random cropping과 color distortion이 성능을 가장 우수하게 낸다고 한다.
2) base encoder
base encoder는 위의 구조도에서 에 해당하는 부분이다. base encoder는 augmentation을 한 sample들에서 representation vector를 뽑아내는 역할을 한다. 논문에서는 ResNet을 사용해 base encoder를 구현했다. encoder를 타고 나와서 얻은 representaiton vector는 위의 구조도의 와 이다. 수식으로 표현하면, 으로 나타낼 수 있다.
3) projection head
projection head는 위의 구조도에서 에 해당하는 부분이다. representation vector를 contrastive loss가 적용되는 공간으로 mapping해주는 역할을 한다. 논문에서는 하나의 hidden layer를 가진 MLP를 사용한다. nonlinearity로는 ReLU가 적용되었다. 실험해보면 h의 공간에서 contrastive loss를 정의하는 것보다 MLP를 태워 얻은 에서 정의하는 것이 더 좋은 결과로 이어진다고 한다.
4) contrastive loss
contrastive loss는 contrastive prediction task를 위해 정의되었다. 이 loss의 목표는 가 주어졌을 때, 를 identify하는 것이다. 일단 mini batch를 sample하고, 위에서 언급한 것과 같이 data augmentation된 와 를 얻는다. 만약 batch size가 이라면, augmentation이 끝나고 난 후의 sample 개수는 2N개가 될 것이다. 이러한 방식을 바탕으로 아래의 positive pair 에 대한 loss function이 정의된다.
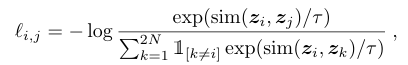
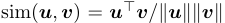
위의 식에서 는 temperature parameter이다. 이렇게 각 positive pair들의 loss들을 계산하고 final loss 값에 반영된다.

5) Batch Size와 evaluation
별도의 메모리가 사용하지 않는 대신, [256,8192] 범위 내의 여러 batch size를 적용해서 실험한다. 만약 batch size=256이면, 512개의 positive pair를 얻는다. 또한, 주로 사용하는 SGD+ momentum은 안정성이 떨어질 수 있다. 논문에서는 LARS라는 optimizer를 사용한다. 크기가 큰 모델들을 훈련시킬 때 좋으며, lr을 각 layer마다 조정하고, gradient normalization을 통해 특정 layer가 업데이트를 지배하는 것을 방지해 준다.
또한, dataset은 ILSVRC-2012 ImageNet을 label 없이 사용하고, 학습된 representation을 평가하기 위해 linear evaluation protocol을 사용한다. 이는 base encoder network 위에 linear classifier를 훈련시켜 구현한다. 논문에서 실험에 사용한 default setting을 요약하면 다음과 같다.
- data augmentation: random crop& resize, color distortion, gaussian blur
- base encoder: ResNet-50
- projection head: 2-layer MLP, 128차원의 latent space로 mapping.
- loss: NT-Xent
- optimizer: LARS, lr=4.8 and weight decay=1e-6.
- batch size= 4096, 100 epochs.
- 첫 10 epoch 동안은 linear warmup, lr decay rate with cosine decay schedule.
이제 기본적인 내용들을 다 살펴보았으니, 하나하나 더 깊게 살펴보려고 한다.
Data augmentation
architecture를 변형하여 contrastive prediction task를 정의하던 기존의 방법과 달리, 논문의 Data augmentation은 random cropping 후 resizing을 사용한다. 이를 통해 더 많은 contrastive prediction이 가능해진다고 한다. 논문에서는 data augmentation의 영향을 알아내고자 여러 실험을 진행한다. 크게 보면 아래와 같이 두 가지 종류의 기법이 있다.
i) spatial/ geometric transformation- ex) cropping & resizing, rotation, cutout
ii) appearance transformation- ex) color distortion, gaussian blur, sobel filtering
논문에서는 위에 언급된 방법들 중에 하나만 사용하거나 두 개를 사용해 framework의 성능을 분석한다. ImageNet의 사진 사이즈가 일정하지 않기 때문에, random cropping과 resize는 항상 진행하여 영상의 사이즈를 맞춰준다. 그리고 나서 SimCLR 구조도에서 하나의 branch에만 특정 method를 사용해 data augmentation을 진행하는 'asymmetric data transformation'을 적용한다. 이때, 나머지 하나의 branch는 identity로 냅둔다.
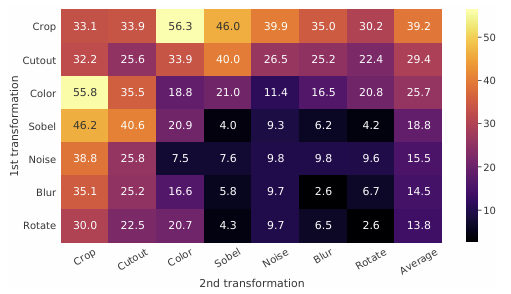
위의 그림은 실험 결과를 나타낸 그림이다. 써 있는 ImageNet top-1 accuracy를 나타내고, 대각선에 있는 원소들은 하나의 기법만 적용한 것이고, 나머지는 두 개의 기법을 사용해 실험한 것이다. 가장 정확도를 보인 방법은 56.3%의 random cropping-> color distortion이다. 또한, 대체로 하나의 방법만 사용해서는 좋은 결과를 얻기가 힘들고, 두 방법을 같이 사용했을 때 좋은 성능을 낸다는 것을 알 수 있다.
또 하나 눈여겨 볼 만한 포인트는 color distortion의 강도이다. contrastive learning은 supervised learning 보다 augmentation의 강도를 크게 했을 때의 효과가 훨씬 크다. 아래의 표로 그 결과를 확인해 볼 수 있다.
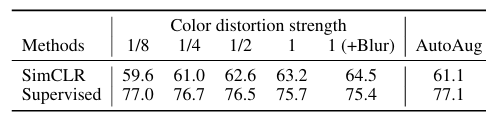
SimCLR은 unsupervised ResNet-50 에 linear evaluation을 사용해 얻은 정확도이고, supervised learning은 ResNet-50를 사용했다. SimCLR에서 augmentation 강도를 높일수록 정확도가 높아진다. 반대로 supervised learning은 augmentation 강도를 높여도 좋은 정확도를 얻기 힘들다.
Architectures for Encoder and Head
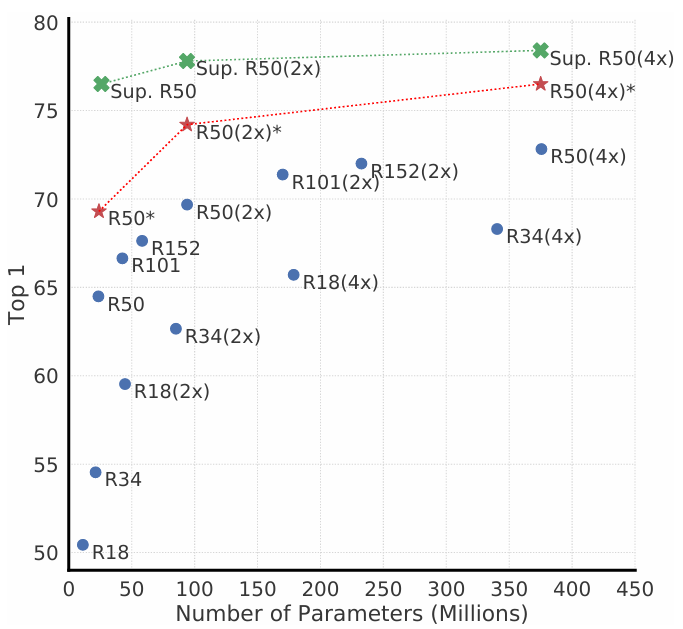
위의 그래프를 보면, 모델의 depth와 width를 늘리는 것은 성능 개선에 긍정적인 영향을 준다. 특히, 주목해야 할 것은 unsupervised 모델의 크기가 커질수록 supervised model과의 gap이 줄어든다는 것이다. 이는 unsupervised learning이 크기가 큰 모델에서 supervised learning보다 더 많은 이득을 본다고 해석할 수 있다.
이제 nonlinear projection head에 대해 살펴보자. 왜 굳이 base encoder를 통해 얻은 representation에 한 번 더 projection head를 태우는 것일까? 그 이유는 더 나은 representation을 얻기 위해서이다. 실험에서는 3가지 방법이 사용되었다.
i) identity mapping
ii) linear projection
iii) nonlinear projection with one additional hidden layer
실험 결과, nonlinear projection>linear projection> no projection 순으로 결과가 나타났다. 비록 결과는 이렇게 나왔지만, downstream task를 진행할 때는 h의 representation이 더 좋다. projection head를 거치고 나면 정보의 손실이 일어나기 때문이다. downstream task를 해결하는데 중요한 정보들을 nonlinearity를 통해 없어질 수 있다는 것이다. contrastive learning을 돕기 위해 projection head를 도입한 것을 이해해야 한다.

위와 같이, 각 representation을 가지고 추가적인 MLP를 훈련시켰을 때의 정확도는 h가 더 높은 것도 확인할 수 있다.
Loss functions and Batch size
이번에는 loss function에 대해 알아보자. 적합한 loss function을 알아보기 위해 아래의 loss function들로 모델을 훈련시켜 정확도를 확인해 보았다.
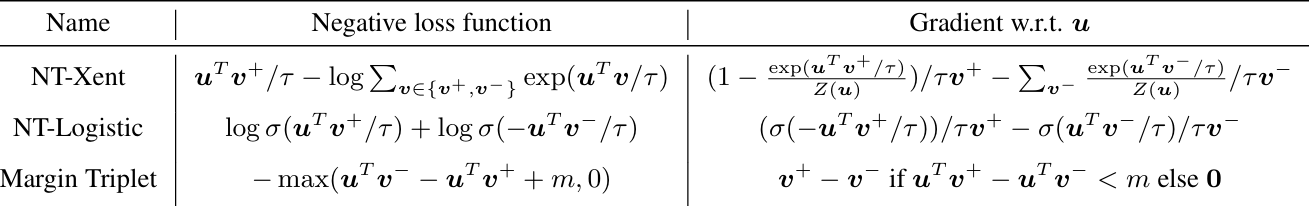

그 결과, 위와 같이 NT-Xent의 정확도가 가장 높게 나온 것을 알 수 있다. 또한, 추가적인 실험을 통해 L2 normalization과 적절한 temperature scaling이 성능에 중요한 영향을 미친다는 것, 그리고 L2 normalization이 없으면 contrastive task accuracy는 증가하지만, representation의 퀄리티는 떨어진다는 것도 확인했다. 또, batch size도 contrastive learning에 영향을 준다.
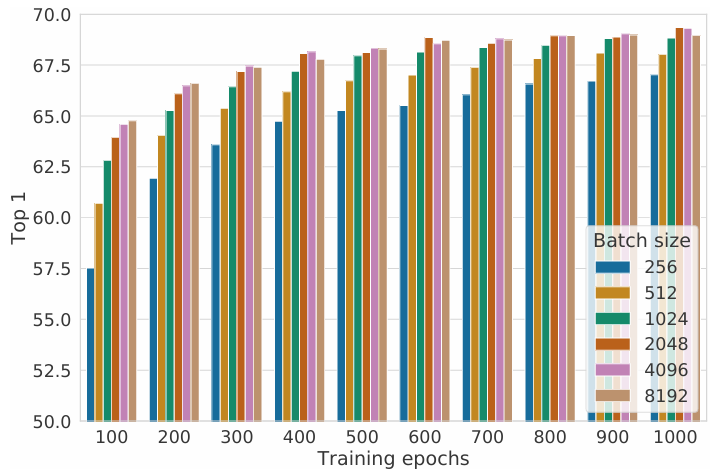
위의 그래프를 보면, epoch수가 적을 때는 batch size가 클수록 성능이 증가하며, epoch 수가 많아질수록 batch size에 따른 정확도 차이가 비교적 감소한다. supervised learning에서와는 다르게, 큰 batch size는 더 많은 negative sample을 제공하기 때문에 수렴을 하기 쉽게 만들어준다. 마찬가지의 논리로 훈련을 오래 할수록 더 좋은 성능을 얻는다. 이러한 구조를 바탕으로 SimCLR은 이전 SOTA보다 더 좋은 성능을 낸다.
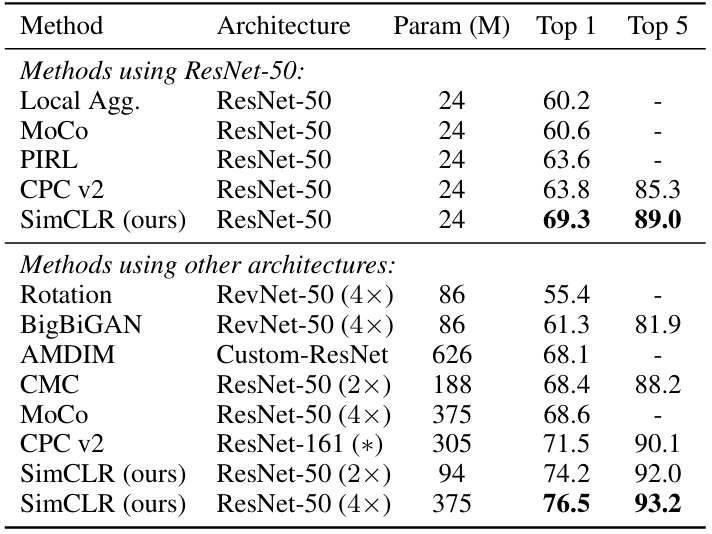
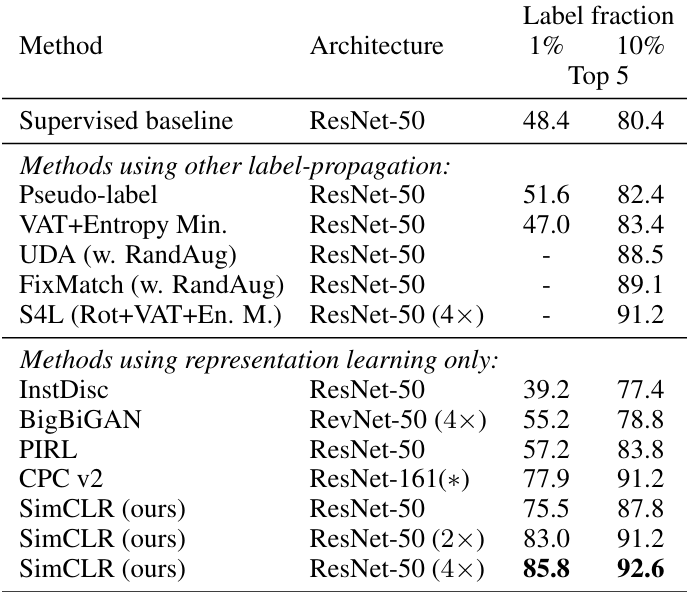
또한, unsupervised learning을 한 모델에 label을 조금씩만 주어 fine-tuning을 시켰을 때, 더 좋은 시너지가 난다.
3. 논문 내용의 실용성
SimCLR은 부가적인 메모리와 architecture 없이 성능 개선을 이루어 냈다는 점이 인상적이다. 또한, 내가 지금까지 읽어온 논문들에 비해 실험을 굉장히 많이 진행한 편에 속하며, 저자들이 제안한 framework를 하나하나 뜯어서 그 부분이 왜 좋은 성능을 내는데 기여하는지 설명하려고 많이 노력한 것 같다. 또한, self-supervised learning 관련 논문을 읽어본게 처음이라, label 없이도 훈련을 진행할 수 있다는 것이 놀라웠다.
