👨🏻💻학습 내용
자바스크립트에서 데이터 타입은 크게 기본형(Immutable type), 참조형(Mutable type)이 있다.
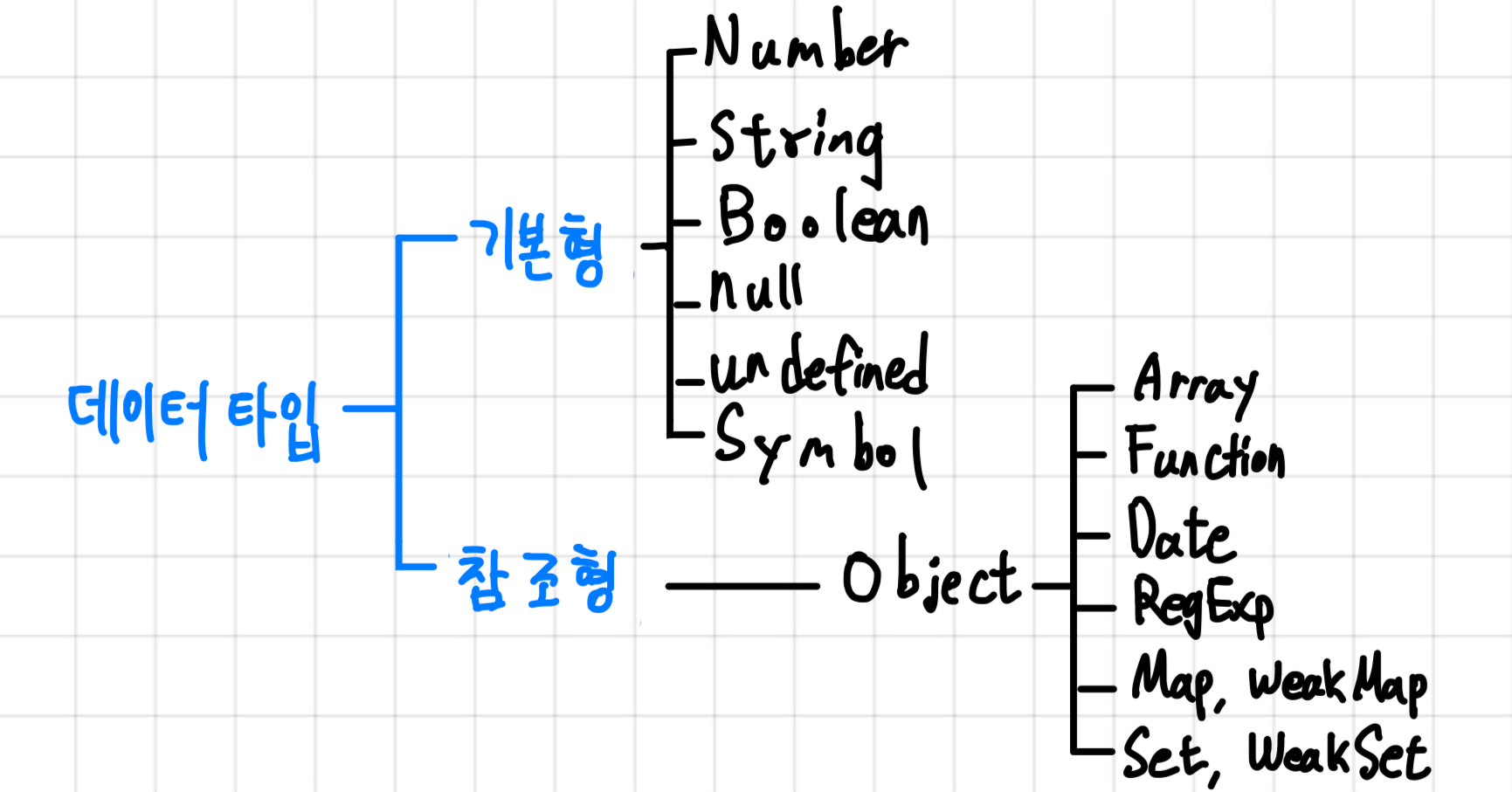
여기서 기본형과 참조형의 차이는 기본형은 값이 담긴 주솟값을 바로 복제하는데, 참조형은 주솟값 묶음을 가리키는 주솟값을 복제한다는 점이 다른다.
그리고 기본형은 불변성을 띄는데 여기서 말하는 불변성을 이해하려면, JavaScript에서 변수를 어떻게 저장하는지 이해해야 한다.
참고 - JavaScript에서는 변수 영역, 데이터 영역 두 부분으로 나눠서 변수를 저장한다.
💡 기본형 데이터 (Immutable type) 저장 방식
var a;
a = 1;
var = b;
b = 'abc';변수 영역
| 주소 | 1001 | 1002 | 1003 |
|---|---|---|---|
| 데이터 | 이름: a , 값 : @5001 | 이름:b, 값 : @5002 |
데이터 영역
| 주소 | 5001 | 5002 | 5003 |
|---|---|---|---|
| 데이터 | 1 | ‘abc’ |
예를 들어 위와 같이 코드를 작성하면, 위의 변수 영역과, 데이터 영역처럼 저장이 된다.
변수 영역에 a라는 변수가 저장되고, 값이 저장되어 있는 주소 5001을 함께 저장해 주고 그 후에 데이터 영역 5001 번에 1이라는 값을 저장해주는 것이다.
그러면 여기서 만약 내가 위의 코드에 추가로
b = 1;이라는 코드를 작성하면 어떻게 되는 걸까?
변수 영역
| 주소 | 1001 | 1002 | 1003 |
|---|---|---|---|
| 데이터 | 이름: a , 값 : @5001 | 이름:b, 값 : @5001 |
데이터 영역
| 주소 | 5001 | 5002 | 5003 |
|---|---|---|---|
| 데이터 | 1 | ‘abc’ |
바로 위와 같이 변수 영역에 b 부분의 주소만 변경되게 된다.
순서를 보면 다음과 같이 진행된다.
- 데이터 영역에 1이 있는지 확인.
- 만약 있다면, 해당 주소로 b의 주소를 변경.
- 없다면, 데이터 영역 5003에 값을 넣고 b에 5003의 주소를 저장.
따라서 위의 과정을 보면, 우리가 부여한 각각의 값 1 과 ‘abc’ 라는 데이터 영역에 저장한 값은 절대 변하지 않고, 변수 영역에 저장하는 주솟값만 변경하면서 값을 저장하는 것을 볼 수 있다. 그리고 만약 내가 3이라는 값을 저장하려고 하면, 5003의 영역에 새로 3을 저장하게 될 것이다.
이처럼 한번 저장한 값(데이터 영역)을 다른 것으로 변경할 수 없고, 변경은 새로 만드는 동작을 통해서만 이루어지는 것이 바로 앞서 말한 불변성이다.
💡 참조형 데이터(Mutable type) 저장 방식
그럼 이제 참조형 데이터 저장 방식에 대해 알아보자.
우선 참조형 데이터 저장은 기본적으로 앞서 말 했던 변수 영역과, 데이터 영역에서 객체에 대한 변수 영역이 추가로 존재한다.
이렇게 말로 하면 조금 이해가 어렵기 때문에 다시 영역을 표로 그리며 설명해보겠다.
var SanObj = {
a: 1,
b: 'abc'
};변수 영역
| 주소 | 1001 | 1002 | 1003 |
|---|---|---|---|
| 데이터 | 이름: SanObj , 값 : @5001 |
데이터 영역
| 주소 | 5001 | 5002 | 5003 |
|---|---|---|---|
| 데이터 | @7001 ~ ??? | 1 | ‘abc’ |
객체 @5001에 대한 영역
| 주소 | 7001 | 7002 | 7003 |
|---|---|---|---|
| 데이터 | 이름: a, 값 : @5002 | 이름: b, 값 : @5003 |
만약 내가 위의 코드처럼 객체를 선언하면, JavaScript에서는 객체를 다음과 같이 저장할 것이다.
그럼 여기서 객체 내부의 값을 변경 해보겠다.
SanObj.a = 2;변수 영역
| 주소 | 1001 | 1002 | 1003 |
|---|---|---|---|
| 데이터 | 이름: SanObj , 값 : @5001 |
데이터 영역
| 주소 | 5001 | 5002 | 5003 | 5004 |
|---|---|---|---|---|
| 데이터 | @7001 ~ ??? | 1 | ‘abc’ | 2 |
객체 @5001에 대한 영역
| 주소 | 7001 | 7002 | 7003 |
|---|---|---|---|
| 데이터 | 이름: a, 값 : @5004 | 이름: b, 값 : @5003 |
만약 a를 변경하면, 5004번의 자리에 새로운 값을 저장한 후에 다음과 같이 a의 값을 저장한 주솟값만 변경하면 된다.
이러면 1001번에서 SanObj 가 저장한 주소는 바뀌지 않지만, 내부의 값이 변경되게 된다.
즉, 새로운 객체가 만들어지는 것이 아니라 기존의 객체 내부의 값만 바뀐 것이다. 이러한 성질 때문에 기본형 데이터는 가변값이라고 한다.
단, 불변값으로 활용할 수도 있다. 예를 들어 객체를 이용해 새로운 객체를 반환하거나 객체를 깊은 복사를 이용하여 다른 객체로 저장하거나 JSON문법으로 문자열로 저장했다가 다시 JSON.parse로 저장하는 방법이 있다.
💡불변 객체
가변성의 문제점
let student = {
name : 'San',
age : 1
};
let updateStudent = function(student, NAME){
let newStudent = student;
newStudent.name = NAME;
return newStudent;
}
let user1 = updateStudent(student, 'Seo');
console.log(user1.name, student.name); // Seo Seo가변성 때문에 위의 예시에서 user1과 student 의 주솟값은 같은데 데이터를 변경했기 때문에 둘 다 같은 값을 가리키게 된다.
따라서 어떤 경우에는 원본 객체는 변경하지 않는 불변 객체가 필요한데, 그 방법은 크게 두가지가 있다.
- 새로운 객체를 반환하도록 만드는 방법.
- 기본의 객체를 복사하는 방법.
우선 첫번째 새로운 객체를 반환하는 방법은 아주 간단하다.
위의 updatestudent 함수를 다음과 같이 수정하면 된다.
let updateStudent = function(student, NAME){
return {
name : NAME,
age : student.age
};
};그리고 복사를 이용하는 방법은 다음과 같다.
let updateStudent = function(student, NAME){
let result = {};
for (const studentKey in student) {
result[studentKey] = student[studentKey];
}
return result;
};
let user1 = updateStudent(student);
user1.name = 'Seo';그런데 복사를 이용하는 방법의 경우 얕은 복사만 수행하고 있다.
이 말이 무슨 뜻이냐면, 바로 반복문을 1개만 사용해서 객체를 복사하고 있기 때문에 복사를 하는 객체 student가 중첩되어 있게 된다면, 예를 들어
let student = {
name : 'San',
age : 1,
parents : {
father : 'Seo',
mother : 'Jo'
}
};위와 같다면, student.parents를 복사할 때는 앞서 말했던 것과 같이 주솟값만 그대로 복사한다는 것이다.
여기서 깊은 복사를 하기 위해서는 updateStudent 안에 조건으로 재귀를 사용하는 방법과 JSON 을 사용하는 방법이 있는데, 재귀는 굳이 설명 안하고 JSON만 설명하겠다.
let student = {
name : 'San',
age : 1,
parents : {
father : 'Seo',
mother : 'Jo'
}
};
let updateStudent = function(target){
return JSON.parse(JSON.stringify(target));
};
let user1 = updateStudent(student);
user1.name = 'Seo';
user1.age = 2;
user1.parents.father = 'JO';
console.log(user1, student);
//{ name: 'Seo', age: 2, parents: { father: 'JO', mother: 'Jo' } }
//{ name: 'San', age: 1, parents: { father: 'Seo', mother: 'Jo' } }- JSON 문법으로 문자열로 변환.
- JSON 객체로 변환.
순수 함수
함수형 프로그래밍 ?
함수형 프로그래밍(函數型 프로그래밍, 영어: functional programming)은 자료 처리를 수학적 함수의 계산으로 취급하고 상태와 가변 데이터를 멀리하는 프로그래밍 패러다임의 하나이다.
출처 : https://ko.wikipedia.org/wiki/함수형_프로그래밍
순수 함수 ?
순수한 함수(pure function)란, 부작용(side-effect)이 없는 함수, 즉, 함수의 실행이 외부에 영향을 끼치지 않는 함수를 뜻한다. 따라서 순수한 함수는 스레드 안전하고, 병렬적인 계산이 가능하다.
출처 : https://ko.wikipedia.org/wiki/함수형_프로그래밍
함수형 프로그래밍에서 말하는 순수한 함수란 수학적 함수의 개념을 가져와서 생각하는 거라고 이야기한다.
그럼 수학에서의 함수는 무엇일까?
아래 사진이 명확하게 수학에서 말하는 함수를 말해준다.
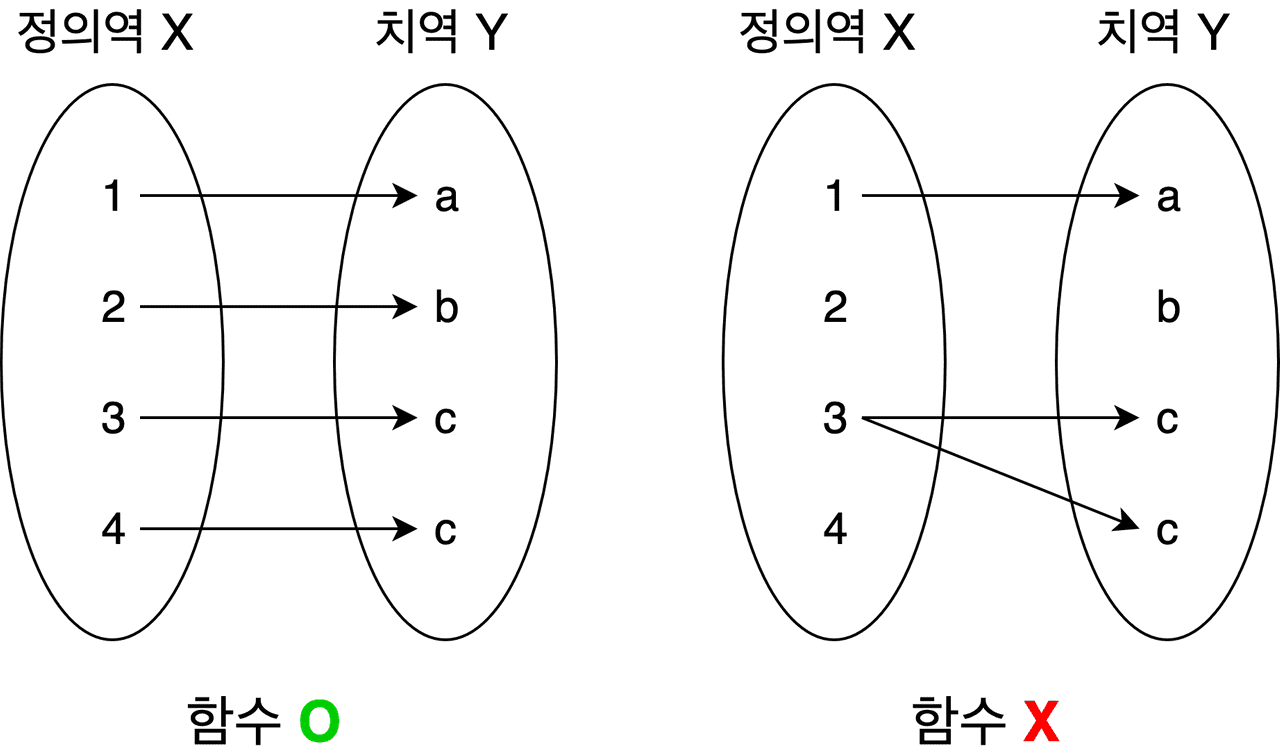
결국 순수 함수는 외부의 어떤 상태에도 의존하지 않고 오직 함수의 input만이 함수의 output에 영향을 주는 함수이다.
따라서 동일한 input 언제나 동일한 output을 줘야하고 함수의 외부 상태를 변경시키거나 외부 상태의 영향을 받으면 안된다.
그럼 왜 하필 수학에서의 함수 개념을 가져왔을까 ?
수학의 세계에서는 뭔가 값을 저장하고 할당하고 호출하는 상태라는 개념이 없다.
따라서 당연히 함수가 외부에서 영향을 주고 받는 사이드 이펙트가 없다.
즉, 수학에서의 함수를 프로그래밍에 그대로 적용하면 위에 설명되어 있는 순수한 함수의 정의에 부합하게 된다.
- 부작용 (side-effect) : 외부 상태가 없기 때문에 당연히 없다.
- 외부의 상태가 없으니 함수의 결과에 영향을 주는 것은 인자만 가능하다.
장점
그럼 왜 하필 이런 순수 함수를 사용해야 하는 걸까?
- 테스트가 쉽다
어떻게 보면 당연한 이야기이다. 유닛 테스트를 짠다고 생각해보면 개발자는 함수의 input 값만 고려하면 output 값을 예측할 수 있기 때문이다.
- 참조 투명성이 보장된다.
순수 함수를 사용하면 동일한 입력에 대해 항상 동일한 출력을 보장하기 때문에 참조 투명성을 확보할 수 있다. 이는 코드의 이해도를 높이고 예측 가능한 동작을 하도록 해준다. 또한, 참조 투명성이 보장되면 함수의 결과를 캐싱하거나, 코드의 일부를 병렬로 실행하는 최적화를 더 쉽게 적용할 수 있다.
- 코드의 재사용성과 모듈화가 증가한다.
순수 함수는 특정한 상태나 외부에 의존하지 않기 때문에 다양한 상황에서 재사용하기가 용이하다. 이는 결국 좋은 모듈화의 조건 중 하나인 "높은 응집도"에도 부합한다.
참고 자료
https://ko.wikipedia.org/wiki/함수형_프로그래밍
https://velog.io/@keum0821/FP-참조-투명성Referential-Transparency
https://velog.io/@jini9256/순수함수란-무엇인가요
https://studyingeugene.github.io/functional-programming/introduction-to-lambda-calculus/
https://evan-moon.github.io/2019/12/29/about-pure-functions/
