import pandas as pd
import numpy as np
from sklearn.datasets import load_breast_cancer
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
from sklearn.metrics import classification_report, confusion_matrix
from keras import models
from keras import layers
데이터 읽기와 분할
cancer = load_breast_cancer()
data_df = pd.DataFrame(cancer.data, columns=cancer.feature_names)
X = np.array(data_df)
y = cancer.target
len(y[y==1])/len(y[y==0])
scaler = preprocessing.MinMaxScaler()
X = scaler.fit_transform(X)
x_train, x_test, y_train, y_test = train_test_split(X, y,
test_size=0.2 , random_state= 156)
len(y[y==1])/len(y[y==0])
1.6839622641509433
데이터 읽기와 분할
cancer = load_breast_cancer()
data_df = pd.DataFrame(cancer.data, columns=cancer.feature_names)
X = np.array(data_df)
y = cancer.target
len(y[y==1])/len(y[y==0])
scaler = preprocessing.MinMaxScaler()
X = scaler.fit_transform(X)
x_train, x_test, y_train, y_test = train_test_split(X, y,
test_size=0.2 , random_state= 156)
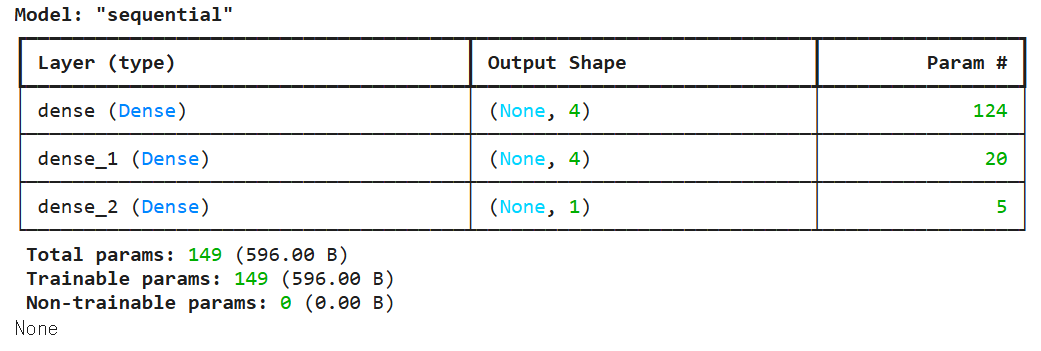
모델의 정의
model=models.Sequential()
model.add(layers.Dense(4, activation='relu',input_dim=x_train.shape[1]))
model.add(layers.Dense(4, activation='relu'))
model.add(layers.Dense(1,activation='sigmoid'))
print(model.summary())
학습 정의와 학습하기
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'])
history=model.fit(x_train, y_train, epochs=200,batch_size=128, validation_split=0.3, class_weight={0:1.68,1:1})
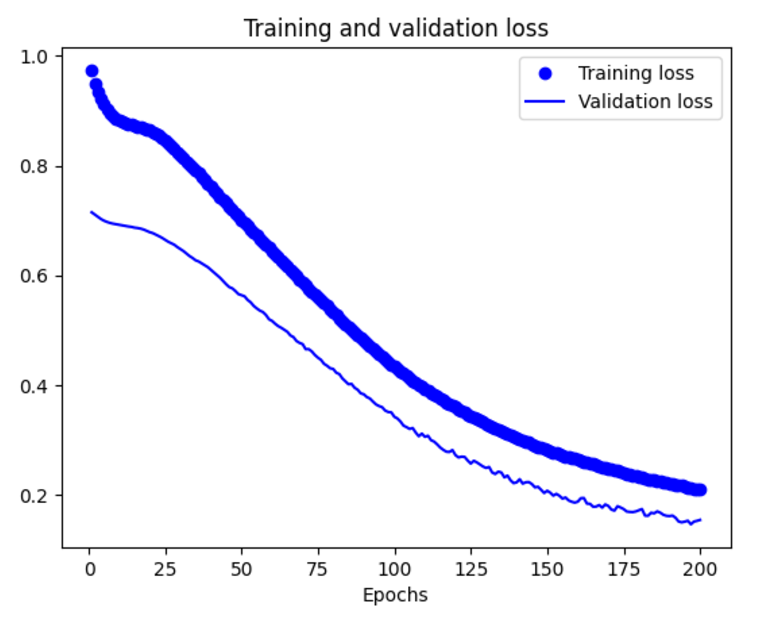
손실(Loss) 함수(Function) 그리기
plt.plot(epochs,loss,'bo',label='Training loss')
plt.plot(epochs,val_loss,'b',label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.legend()
plt.show()
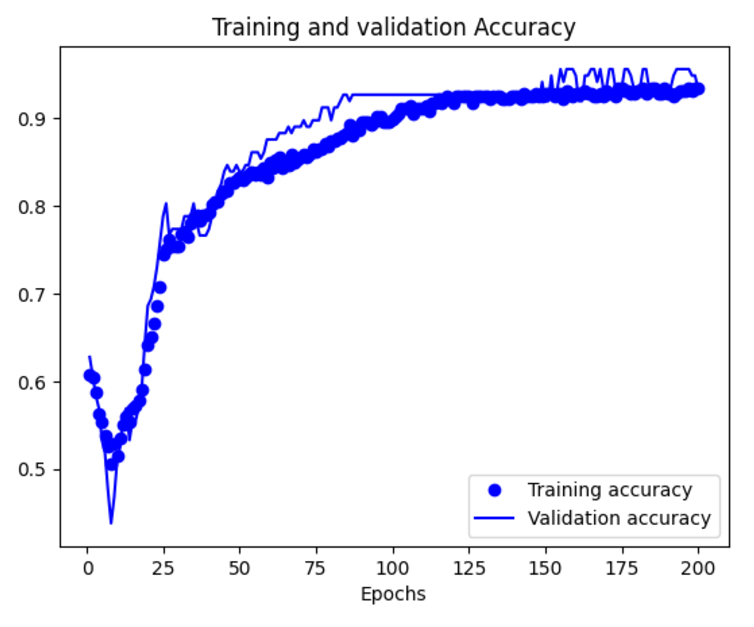
정확도 그리기
plt.plot(epochs,acc,'bo',label='Training accuracy')
plt.plot(epochs,val_acc,'b',label='Validation accuracy')
plt.title('Training and validation Accuracy')
plt.xlabel('Epochs')
plt.legend()
plt.show()
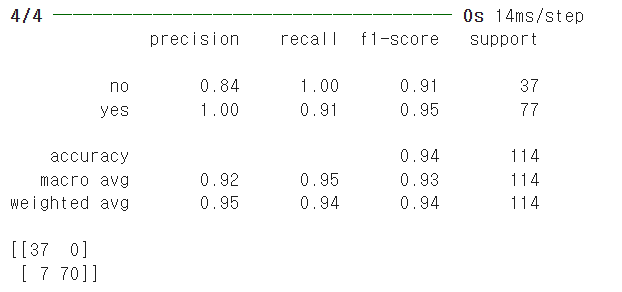
예측과 평가
predicted_result=model.predict(x_test)
predicted_result.shape
predicted_target=pd.Series([1 if predicted_result[i]> 0.5 \
else 0 for i in range(0,predicted_result.shape[0])])
print(classification_report(y_test,predicted_target,\
target_names=['no','yes']))
print(confusion_matrix(y_test,predicted_target))
손글씨인식
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten, Conv2D
from tensorflow.keras.layers import MaxPooling2D, AveragePooling2D
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.datasets import mnist
데이터 읽어오기
(X_train, y_train), (X_test, y_test) = mnist.load_data()
print(X_train.shape)
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1)
X_test = X_test.reshape(X_test.shape[0], 28, 28, 1)
print(X_train.shape)
데이터 확인
import matplotlib.pyplot as plt
plt.imshow(X_train[0], cmap = 'gray')
plt.show()
데이터 전처리
이미지 데이터 전처리
수치값이 0 ~ 255(정수) → 0 ~ 1(실수)로 변형
분산(값의 분포)이 크기 때문에 계산상의 오류가 발생할 수 있음
정수→실수로 바꿀 때 기존에 가지고 있던 의미를 그대로 가져야 함.
작은 범위의 숫자로 기존의 의미를 표현할 수 있음 → 숫자가 작아졌기 때문에 계산량 감소
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
Y_train = to_categorical(y_train, 10)
Y_test = to_categorical(y_test, 10)
모델 정의
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
print(model.output_shape)
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
모델 정의2
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
학습 정의와 학습
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
history=model.fit(X_train, Y_train, batch_size=32, epochs=10, verbose=1)
score = model.evaluate(X_test, Y_test, verbose=0)
print(model.metrics_names)
print(score)
