R 로 만들 수 있는 그래프
- 2차원 그래프, 3차원 그래프
- 지도 그래프
- 네트워크 그래프
- 모션 차트
- 인터랙티브 그래프
ggplot2 의 레이어 구조
1단계 : 배경 설정 (축)
2단계 : 그래프 추가(점, 막대, 선...)
3단계 : 설정 (축 범위, 색, 표식)
산점도(Scatter Plot)
데이터를 x축과 y축에 점으로 표현한 그래프
-> 나이와 소득 처럼 연속 값으로 된 두 변수의 관계를 표현할 때 사용
library(ggplot2)
#패키지 로드
1. 배경 설정
x축 displ(배기량), y축 hwy(고속도로연비)로 지정해 배경 생성
ggplot(data=mpg, aes(x=displ, y=hwy))
2. 그래프 추가
배경에 산점도 추가
ggplot(data=mpg, aes(x=displ, y=hwy)) + geom_point()
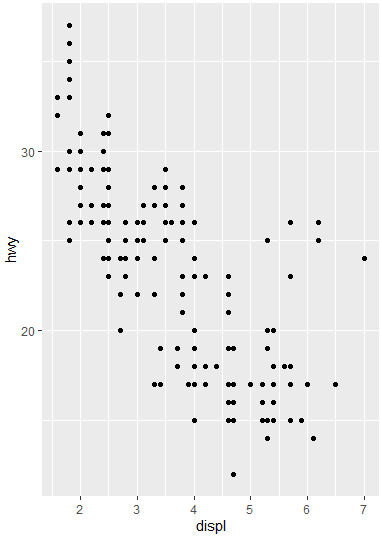
3. 축 범위를 조정하는 설정 추가하기
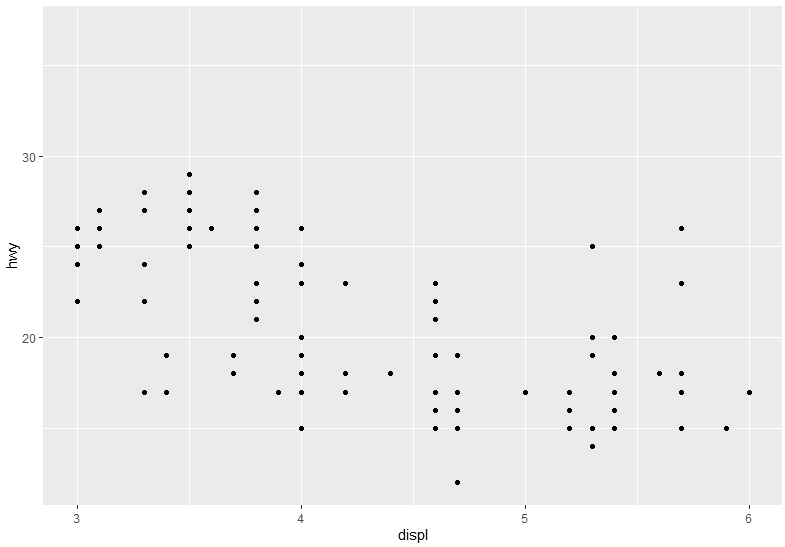
x 축 범위 3~6 으로 조정 (xlim)
ggplot(data=mpg, aes(x=displ, y=hwy)) + geom_point() + xlim(3,6)
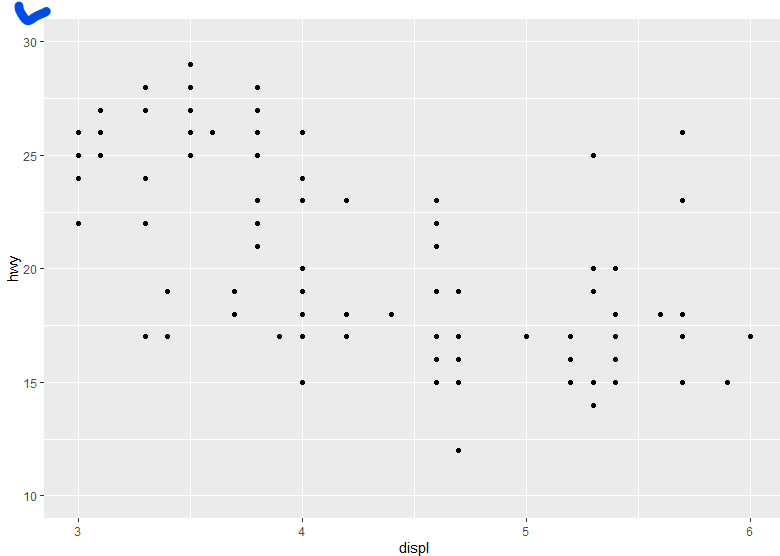
y축 범위 10~30 으로 조정 (ylim)
ggplot(data=mpg, aes(x=displ, y=hwy)) +
geom_point() +
xlim(3,6) +
ylim(10,30)
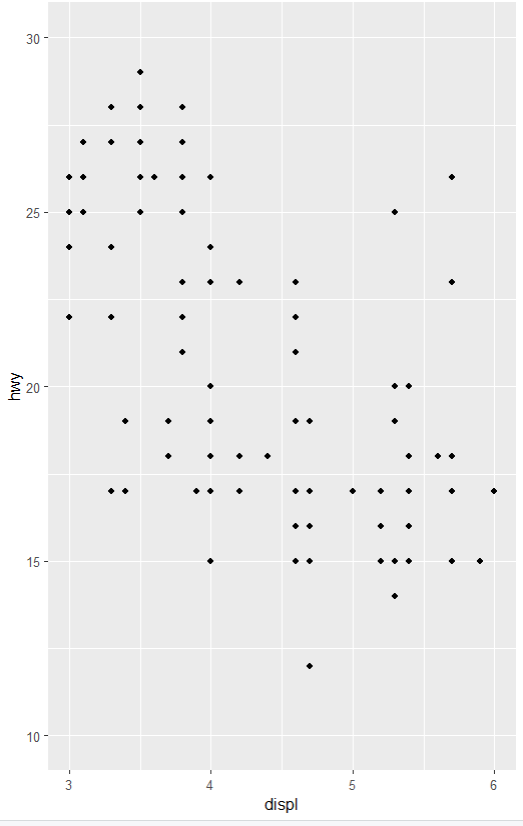
qplot() : 전처리 단계 데이터 확인용, 문법 간단, 기능 단순
ggplot() : 최종 보고용. 색, 크기, 폰트 등 세부 조작 가능
막대 그래프 - 평균 막대 그래프 : 각 집단의 평균값을 막대 길이로 표현
1. 집단별 평균표 만들기
library(dplyr)
mpg <- as.data.frame(ggplot2 :: mpg)
df_mpg <- mpg %>%
group_by(drv) %>%
summarise(mean_hwy = mean(hwy))
df_mpg
# A tibble: 3 × 2
drv mean_hwy
<chr> <dbl>
1 4 19.2
2 f NA
3 r 212. 막대 그래프 생성(geom_col())
ggplot(data=df_mpg, aes(x=drv, y=mean_hwy)) + geom_col()
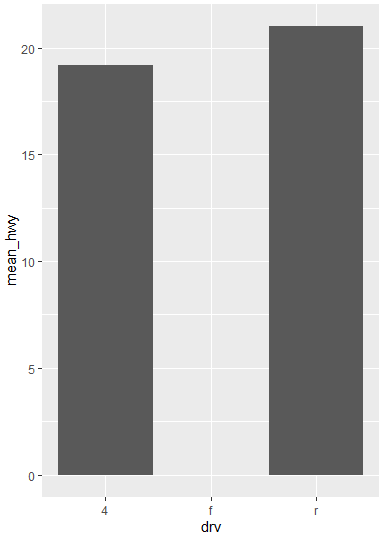
data=df_mpg:
df_mpg라는 데이터프레임을 사용한다.
자동차의 구동 방식(drv)과 고속도로 연비(hwy) 데이터를 포함한다.
aes(x=drv, y=mean_hwy):
x=drv: x축에 drv 열의 데이터를 사용한다.
drv는 구동 방식(예: 전륜구동, 후륜구동, 4륜구동)을 나타낸다.
y=mean_hwy:
y축에 mean_hwy 열의 데이터를 사용한다.
mean_hwy는 고속도로 연비(hwy)의 평균값을 나타내는 변수이다.
+ geom_col():
geom_col() 함수는 막대 그래프를 그리는 데 사용된다.
geom_col()은 x축과 y축의 값을 사용하여 막대의 높이를 지정한다.
이 함수는 x축의 범주별로 y축 값을 기반으로 막대의 높이를 설정한다.
3. 크기 순으로 정렬
ggplot(data=df_mpg, aes(x=reorder(drv, -mean_hwy), y=mean_hwy)) + geom_col()
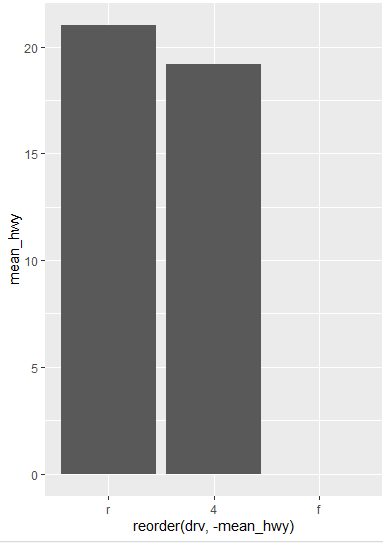
aes(x=reorder(drv, -mean_hwy), y=mean_hwy):
x=reorder(drv, -mean_hwy):
x축에 drv 변수를 사용함.
reorder() 함수를 사용하여
drv 값을 mean_hwy의 크기에 따라 내림차순으로 정렬함.
mean_hwy 값이 큰 순서대로 drv 값을 정렬하여 표시함.
y=mean_hwy:
y축에 mean_hwy 변수를 사용함. (고속도로 연비의 평균값)
reorder()를 통해 x축의 drv 값이 mean_hwy 값에 따라 정렬되어 표시되므로,
그래프에서는 mean_hwy가 큰 구동 방식부터 작은 구동 방식 순서대로 막대가 그려짐.
막대 그래프
빈도 막대 그래프 : 값의 개수(빈도)로 막대의 길이를 표현
1. x축 범주 변수, y축 빈도
ggplot(data=mpg, aes(x=drv)) + geom_bar()
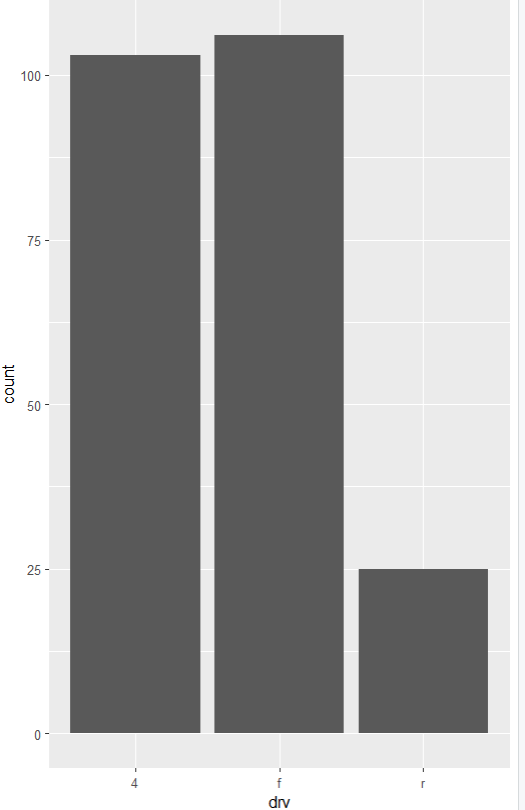
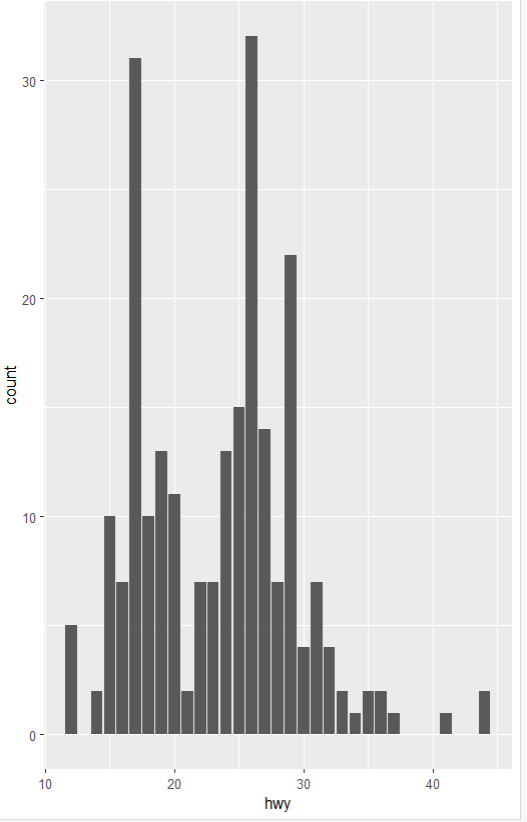
2. x축 연속 변수, y축 빈도
ggplot(data=mpg, aes(x=hwy)) + geom_bar()
막대 그래프 (Bar Chart)
데이터의 크기를 막대의 길이로 표현
-> 성별 소득 차이 처럼 집단 간 차이를 표현할 때 자주 사용
1. 집단별 평균표 만들기
library(dplyr)
mpg <- as.data.frame(ggplot2 :: mpg)
mpg <- as.data.frame(ggplot2 :: mpg)
df_mpg <- mpg %>%
group_by(drv) %>%
summarise(mean_hwy = mean(hwy))
group_by(drv):
drv 변수를 기준으로 데이터를 그룹화함.
drv는 자동차의 구동 방식을 나타내는 변수로,
전륜구동, 후륜구동, 4륜구동 등을 포함할 수 있음.
summarise(mean_hwy = mean(hwy)):
mean_hwy = mean(hwy)는
각 구동 방식별로 hwy 변수의 평균값을 계산하여
mean_hwy라는 새로운 변수로 저장함.
즉, 각 구동 방식별 평균 고속도로 연비를 계산함.
df_mpg
drv mean_hwy
<chr> <dbl>
1 4 19.2
2 f 28.2
3 r 21 2. 그래프 생성: geom_col()
ggplot(data=df_mpg, aes(x=drv, y=mean_hwy)) + geom_col()
3. 크기 순으로 정렬
ggplot(data=df_mpg, aes(x=reorder(drv, -mean_hwy), y=mean_hwy)) +
geom_col()
막대 그래프 - 빈도 막대 그래프: geom_bar()
값의 개수(빈도)로 막대의 길이를 표현
1. x축 범주 변수, y축 빈도
ggplot(data=mpg, aes(x=drv)) + geom_bar()
2. x축 연속 변수, y축 빈도
ggplot(data=mpg, aes(x=hwy)) + geom_bar()
평균 막대 그래프: geom_col()
데이터를 요약한 평균표를 먼저 만든 후 평균표를 이용해서 생성
geom_col()
빈도 막대 그래프: geom_bar()
별도로 표를 만들지 않고 원자료를 이용해 바로 그래프 생성
geom_bar()
선 그래프
데이터를 선으로 표현한 그래프
시계열 그래프
일정 시간 간격을 두고 나열된 시계열 데이터를 선으로 표현한 그래프.
환율, 주가지수 등 경제 지표가 시간에 따라 어떻게 변하는지 표현할 때 자주 사용
ggplot(data=economics, aes(x=date, y=unemploy)) +
geom_line()
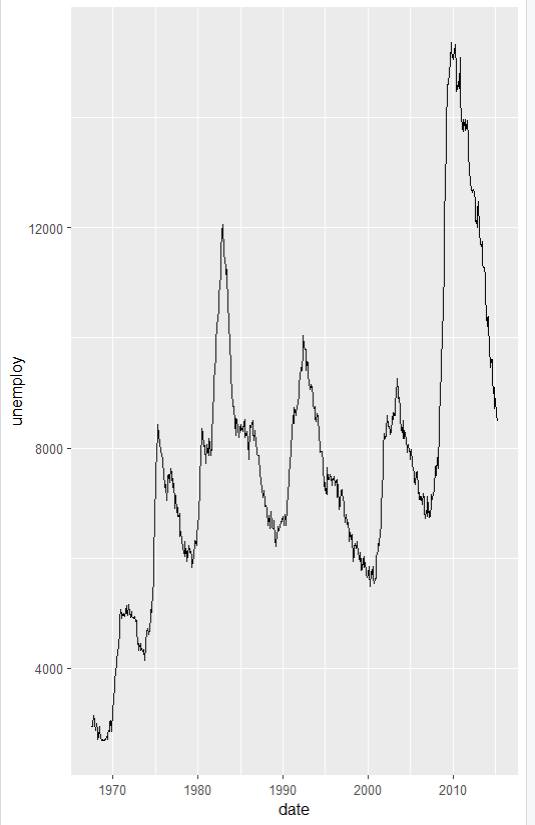
ggplot(data=economics, aes(x=date, y=unemploy))
economics 데이터셋은 미국 경제 지표를 포함한 데이터로,
날짜(date), 실업자 수(unemploy), 개인 저축률 등을 포함하고 있음.
aes(x=date, y=unemploy)
x=date: x축에 date 변수를 사용함.
date는 날짜를 나타냄.
y=unemploy
y축에 unemploy 변수를 사용함.
unemploy는 실업자 수를 나타냄.
geom_line()
geom_line() 함수는 선 그래프를 그리는 데 사용됨.
x축과 y축의 값을 사용하여 두 점을 선으로 연결하여 시계열 변화를 나타냄.
이 함수는 시간의 경과에 따라 date와 unemploy 간의 관계를 시각적으로 표현함.
상자그림(박스플롯)
- 집단 간 분포 차이
- 분포를 알 수 있기 때문에 데이터 특성을 자세히 이해할 수 있다.
ggplot(data=mpg, aes(x=drv,y=hwy)) + geom_boxplot()
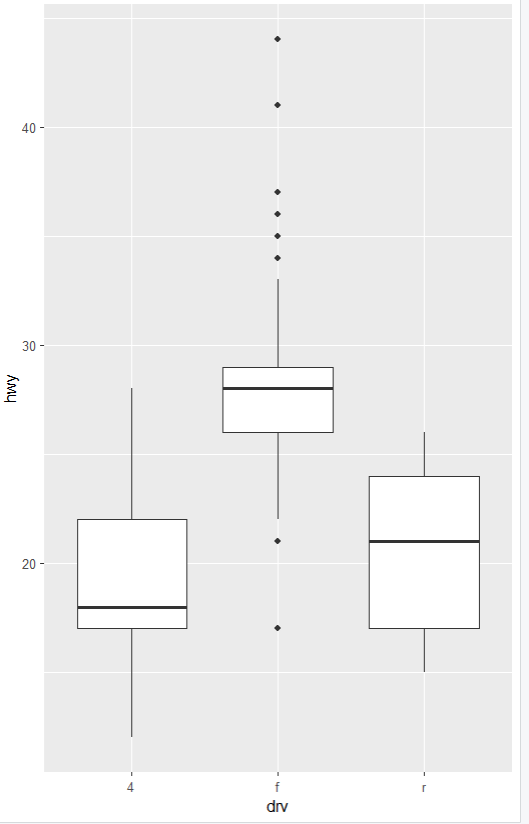
ggplot(data=mpg, aes(x=drv, y=hwy))
aes(x=drv, y=hwy)
x=drv
x축에 drv 변수를 사용함.
drv는 자동차의 구동 방식을 나타내며,
전륜구동(f), 후륜구동(r), 4륜구동(4) 등의 값을 가질 수 있음.
y=hwy
y축에 hwy 변수를 사용함.
hwy는 자동차의 고속도로 연비를 나타냄.
1.5IQR(사분위범위)
사분위 범위(Q1~Q3간 거리)의 1.5배
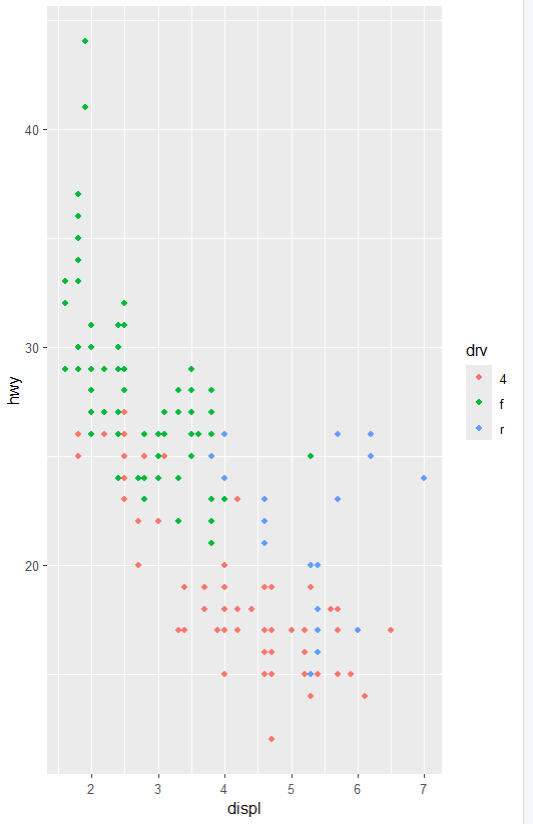
library(ggplot2)
ggplot(mpg, aes(displ, hwy, colour = drv)) +
geom_point()
사분위수
사분위수 범위는 자료 집합의 중간
50%에 포함되는 자료의 산포도를 나타냅니다.
제3사분위수 - 제1사분위수 = 사분위수 위

확률과 통계 - 사분위수 (출처: khan academy)
aes(displ, hwy, colour = drv)
displ
x축에 사용할 변수로,
자동차의 엔진 배기량(리터 단위)을 나타냄
hwy
y축에 사용할 변수로,
고속도로 연비(마일/갤런)를 나타냄
colour = drv
점의 색깔을 drv 변수에 따라 다르게 설정함.
drv는 자동차의 구동 방식을 나타내며,
전륜구동(f), 후륜구동(r), 4륜구동(4) 등의 값을 가짐.
geom_point()
산점도를 그리는 데 사용됨.
각 데이터 포인트를 그래프에 점으로 표시함.
x축의 displ(배기량)과 y축의 hwy(고속도로 연비) 값을
기반으로 각 점을 플로팅함.
각 점의 색깔은 drv(구동 방식)에 따라 다르게 표시됨.
