데이터 정제
빠진 데이터, 이상한 데이터 제거
결측치 (Missing Value)
-> 누락된 값, 비어있는 값
-> 함수 적용 불가, 분석 결과 왜곡
-> 제거 후 분석 실시
결측치 찾기
df <- data.frame(s = c("M","F", NA, "M","F"), score = c(5,4,3,4,NA))
df
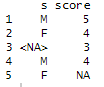
결측치 확인
is.na(df)
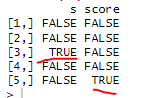
결측치 빈도 출력
table(is.na(df))
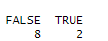
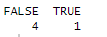
변수 별로 결측치 확인
table(is.na(df$s))
결측치 포함된 상태로 분석
mean(df$score)
sum(df$score)
각각 NA가 나온다.
결측치 제거
library(dplyr)
결측치가 있는 행 제거
df %>% filter(is.na(score)) # score 가 NA 인 데이터만 출력

df %>% filter(!is.na(score)) # score의 결측치 제거

score 열에 결측치가 없는 행들만 추출하여 새로운 데이터프레임 df_nomiss에 저장한다.
결과적으로, df_nomiss는 score 열에 결측치가 없는 데이터만 포함하게 된다.
df_nomiss <- df %>% filter(!is.na(score))
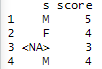
mean(df_nomiss$score)
평균은 4가 나온다.
여러 변수 동시에 결측치 없는 데이터 추출하기
score , s 동시에 결측치 제외
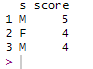
df_nomiss <- df %>% filter(!is.na(score) & !is.na(s))
df_nomiss
결측치가 하나라도 있으면 제거
df_nomiss2 <- na.omit(df) # 모든 변수에 결측치가 없는 데이터 추출
df_nomiss2

df

주의사항
na.omit()는 분석에 필요한 데이터까지 손실 될 가능성이 있다.
함수의 결측치 제외 기능: na.rm = T
mean(df$score, na.rm = T)
정답은 4가 나온다. (결측치를 제외함)
summarise() 에서 na.rm = T 사용
install.packages('readxl')
library(readxl)
exam <-read_excel('C:/R_Project_bigdata/excel_exam.xlsx')
exam
3, 8, 15 행의 math에 NA 할당
exam[c(3,8,15), 'math'] <- NA
exam 데이터프레임의 3, 8, 15번째 행의 math 열에 NA 값을 할당한다.
exam
exam %>% summarise(mean_math = mean(math))
exam 데이터프레임에서 math 열의 평균을 계산한다.
이때 결측치(NA)를 고려하지 않고 계산하기 때문에 math 열에 NA가 있으면 평균값도 NA가 된다.
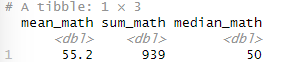
exam %>% summarise(mean_math = mean(math, na.rm = T),
sum_math = sum(math, na.rm = T),
median_math = median(math, na.rm = T))
na.rm = T 옵션을 사용하여 결측치를 제거한 후, 여러 통계량을 계산한다.
mean_math: math 열의 평균을 계산한다.
sum_math: math 열의 합계를 계산한다.
median_math: math 열의 중앙값을 계산한다.
결측치 대체
결측치가 많을 경우 모두 제외하면 데이터 손실이 크다.
대안으로 다른 값 채워넣기가 있다.
결측치 대체법
대표값(평균, 최빈값 등)으로 일괄 대체
통계분석 기법 적용하거나, 예측값 추정해서 대체하는 것이 있고
평균값으로 결측치 대체하는 것이 있다.
1. 평균 구하기
mean(exam$math, na.rm = T)
[1] 55.23529평균은 소수점 제외하여 55로 매길 것이다.
2. 구한 평균으로 대체 (ifelse 사용)
exam$math에 결측치가 있으면, 55로 대체한다.
exammath), 55, exam$math)
table(is.na())로 확인해보면 결측치가 없는 것을 확인 가능하다.
(FALSE만 있음)
table(is.na(exam$math))
FALSE
20mean(exam$math)
[1] 55.2