변수(Variable)
- 다양한 값을 지니고 있는 하나의 속성
- 변수는 데이터 분석의 대상
a <- 1
a
b <- 3.589
b
변수로 연산하기
a + b
a*b
4/b
여러 값으로 구성된 변수 만들기 c()
var1 <- c(1,2,5,7,8) # 숫자 다섯개로 구성된 변수 생성
var1
var2 <- c(1:100) # 1~100까지 연속값으로 생성
var2
seq() 함수 : 연속된 범위 생성할 때 사용하는 함수
var3 <- seq(1,5)
var3
var4 <- seq(1, 100, by=2) # 1~100 사이 홀수만 생성
var4
var5 <- seq(2, 100, by=2) # 1~100 사이 짝수
var5
연속값 변수로 연산하기
var1 + 2
var1
var2 <- c(1,2,3,4,5)
var2
var1 + var2
문자로 된 변수 생성
str1 <- 'a'
str1
str2 <- 'text'
str2
str3 <- 'Hello World!'
str3
연속 문자 변수 생성
str4 <- c('a','b','c')
str4
#"a" "b" "c"
str5 <- c('hello!','World','is','Good!')
str5
문자로 된 변수로는 연산을 할 수 없다.
str1 + 1
함수
값을 넣으면 특정한 기능을 수행해 처음과 다른 값을 출력하는 수
-> 입력을 받아서 출력을 내는 수
숫자를 다루는 함수 사용
변수 생성
x <- c(1,2,3)
x
함수 적용
mean(x) # 평균 함수
max(x) # 최대값 함수
min(x) # 최소값 함수
문자를 다루는 함수 사용
str5
paste(str5, collapse = ',') # 쉼표를 구분자로 단어들을 하나로 합치기
함수의 결과물을 새로운 변수로 활용
x
x_mean <- mean(x)
x_mean
변수 생성 법칙
- 스네이크 법칙 : 의미를 가진 단어 사이사이에 _ 를 넣어서 변수명을
지정하는 법칙 - 카멜 케이스 법칙 : 변수명을 대소문자를 섞어서 낙타의 등 형태로
변수명을 지정하는 법칙
ex)XmeanSum <- 123
패키지(Packages)
- 함수가 여러 개 들어있는 꾸러미
- 하나의 패키지 안에 다양한 함수가 들어있다.
- 함수를 쓰려면 패키지 설치가 선행되어야 한다.
패키지 설치 -> 패키지 로드 -> 함수 사용
ggplot2 패키지 설치, 로드
ggplot2 : R 의 대표적인 그래프 시각화 패키지
install.packages('ggplot2') # 패키지 설치 함수
library(ggplot2) # 패키지 로드 함수
함수 사용하기
1. 여러 문자로 구성된 변수 생성
x <- c('a','a','b','c')
x
2. 빈도 그래프 출력
qplot(x)
3. ggplot2의 mpg 데이터로 그래프 생성
3-1. data에 mpg, x축에 hwy 변수 지정해서 그래프 생성
qplot(data=mpg, x=hwy)
qplot(data=mpg, x=cty)
3-2 x축 drv, y축 cty
qplot(data=mpg, x=drv, y=cty)
mpg
qplot(data=mpg, x=drv, y=cty, geom='line') # 선그래프 형태로 출력
3-3 x축 drv, y축 hwy, 상자 그림 형태 출력
qplot(data=mpg, x=drv, y=hwy, geom='boxplot', colour = drv)
?qplot
데이터 프레임
- 엑셀과 비슷한 형태, 행과 열로 구성된 데이터
- 열은 속성, 행은 한 사람의 정보
- 데이터가 크다 = 행 또는 열이 많다.
english <- c(90,80,60,70) # 영어 점수 변수 생성
english
math <- c(50,60,100,20) # 수학 점수 변수 생성
math
영어와 수학 변수로 데이터 프레임 생성해서 새로운 변수에 저장
df_midterm <- data.frame(english, math) # 데이터 프레임 생성 함수
df_midterm
class <- c(1,1,2,2)
df_midterm <- data.frame(english, math, class)
df_midterm
mean(df_midtermenglish) # df_midterm 의 영어 평균 mean(df_midtermmath)
외부 데이터 사용 - 시험 성적 데이터
엑셀 파일 불러오기
install.packages('readxl')
library(readxl)
df_exam <- read_excel('excel_exam.xlsx')
df_exam
mean(df_exam$math)
직접 경로 지정
df_exam <- read_excel('C:/R_Project_bigdata/excel_exam.xlsx')
df_exam
엑셀 파일 첫 번째 행이 변수명이 아닌 경우
df_exam_novar <- read_excel('excel_exam_novar.xlsx', col_names = F)
df_exam_novar
엑셀 파일에 시트가 여러개 있는 경우
df_exam_sheet <- read_excel('excel_exam_sheet.xlsx', sheet=3)
df_exam_sheet
CSV 파일 불러오기
CSV
- 범용 데이터 형식
- 값 사이를 쉼표(,)로 구분하는 파일
- 용량 작음, 다양한 소프트웨어에서 사용 가능
df_csv_exam <- read.csv('csv_exam.csv')
df_csv_exam
데이터 프레임을 CSV 파일로 저장하기
df_midterm <- data.frame(english = c(90,87,60,70),
math = c(50,60,100,20))
df_midterm
write.csv(df_midterm, file='df_midterm_pass.csv')
데이터 파악 함수
-
head() : 데이터의 앞 부분 출력
-
tail() : 데이터의 뒷 부분 출력
-
View() : 뷰어 창에서 데이터 확인
-
dim() : 데이터 차원 출력
-
str() : 데이터의 속성 출력
6*. summary() : 요약통계량 출력
데이터 로드
exam <- read.csv('csv_exam.csv')
head() 데이터 앞 부분 확인
head(exam) # 앞에서부터 6행까지 출력
head(exam, 10) # 앞에서부터 10행까지 출력
tail() 데이터 뒷 부분 확인
tail(exam) # 뒤에서부터 6행까지 출력
tail(exam, 10) # 뒤에서부터 10행까지 출력
dim() 몇 행 몇 열로 구성되는지 파악
dim(exam)
str() 속성 파악
str(exam)
summary() 요약통계량
summary(exam)
mpg 데이터 파악(ggplot2 패키지)
ggplot2 의 mpg 데이터를 데이터 프레임 형태로 불러오기
mpg <- as.data.frame(ggplot2::mpg)
head(mpg)
tail(mpg)
str(mpg)
summary(mpg)
데이터 수정하기 - 변수명 바꾸기(dplyr)
install.packages('dplyr')
library(dplyr)
df_raw <- data.frame(var1 = c(1,2,1),
var2 = c(2,3,2))
df_raw
데이터 프레임의 변수를 변경하거나 형식을 바꾸는 경우에는
복사본을 생성한 다음 생성된 복사본을 수정한다.
데이터 프레임 복사본 생성
df_new <- df_raw # 복사본 생성
df_new
변수명 수정: 새 변수명 = 기존 변수명 순서로 입력(rename)
df_new <- rename(df_new, v2 = var2)
df_new
Q1. ggplot2 패키지의 mpg 데이터를 사용할 수 있도록 불러온 뒤에 복사본 생성
mpg <- as.data.frame(ggplot2::mpg)
mpg_new <- mpg
mpg_new
Q2. 복사본 데이터를 이용해서 cty 는 city 로, hwy는 highway로 변수명 수정
mpg_new <- rename(mpg_new, city = cty)
mpg_new <- rename(mpg_new, highway = hwy)
head(mpg_new)
파생변수 만들기
파생변수: 기존의 변수를 조합해서 새롭게 창조되는 변수
df <- data.frame(var1=c(4,3,8),
var2=c(2,6,1))
df
dfvar1 + df$var2
df
dfvar1 + df$var2) / 2
df
mpg 데이터 통합 연비 변수 생성
mpgcty + mpg$hwy) / 2
head(mpg)
mean(mpg$total)
조건문을 활용해서 파생변수 생성
1. 기준값 정하기 - 20
summary(mpg$total)
hist(mpg$total)
2. 조건문으로 합격 판정 변수 생성 - 수입할지 말지
ifelse(조건, 조건에 맞을때 부여, 조건에 맞지 않을때 부여)
통합 연비가 20 이상이면 수입, 아니면 수입X
mpgtotal >= 20,'수입','수입X')
tail(mpg, 15)
빈도표로 수입 자동차 수 살펴보기
table(mpg$test) # 수입 가능한 차량 빈도표 생성
qplot(mpg$test)
중첩 조건문 활용: 연비 등급 변수 생성
'''
A - 30 이상
B - 20 ~ 29
C - 20 미만
'''
1. total을 기준으로 A,B,C 등급 부여
mpgtotal >= 30, 'A',
ifelse(mpg$total >= 20, 'B','C'))
head(mpg,20)
table(mpg$grade)
qplot(mpg$grade)
데이터 가공
데이터 전처리(Preprocessing): dplyr 패키지
-
filter() : 행 추출
-
select() : 열 추출
-
arrange() : 정렬
-
mutate() : 변수 추가
-
summarise() : 통계치 산출
-
group_by() : 집단별로 나누기
-
left_join() : 데이터 합치기 (열 기준)
-
bind_rows() : 데이터 합치기 (행 기준)
조건에 맞는 데이터만 추출 - filter()
library(dplyr)
exam <- read.csv('csv_exam.csv')
exam
exam에서 class가 1인 경우만 추출하여 출력
exam %>% filter(class == 1)
2반인 경우만 추출
exam %>% filter(class == 2)
1반이 아닌 경우
exam %>% filter(class != 1)
!= : 같지 않다
초과, 미만, 이상, 이하 조건 걸기
수학 점수가 50점 초과인 경우
exam %>% filter(math > 50)
영어 점수가 80점 이상인 경우
exam %>% filter(english >= 80)
여러 조건을 충족하는 행 추출
1반이면서 수학점수가 50점 이상인 경우
exam %>% filter(class == 1 & math >= 50)
& (and) : 모두 부합
여러 조건 중 하나 이상 충족하는 행 추출
수학 점수가 90점 이상이거나 영어 점수가 90점 이상인 경우
exam %>% filter(math >= 90 | english >= 90)
| (버티컬 바) : 또는(or)
목록에 해당하는 행 추출
1, 3, 5반에 해당되면 추출
exam %>% filter(class==1 | class==3 | class==5)
%in% 기호 활용 - 포함 연산자
exam %>% filter(class %in% c(1,3,5))
exam
추출한 행으로 데이터 만들기
class1 <- exam %>% filter(class == 1)
mean(class1$math)
R에서 사용하는 기호들
1. 논리 연산자
< : 작다
<= : 작거나 같다
== : 같다
!= : 같지 않다
| : 또는
& : 그리고
%in% : 매칭 확인 , 포함 연산자
2. 산술 연산자
- : 더하기
- : 빼기
- : 곱하기
/ : 나누기
^, ** : 제곱
%/% : 나눗셈의 몫
%% : 나눗셈의 나머지
필요한 변수 추출(select)
exam %>% select(math)
여러 변수 추출(,)
exam %>% select(class, math, english)
해당 변수만 제외하고 추출(-변수명)
exam %>% select(-math)
exam %>% select(-math, -science)
dplyr 패키지 활용
1반이고 영어 점수만 추출(filter, select)
exam %>% filter(class == 1) %>% select(english)
- 가독성 있게 줄 바꿈을 해주는 것이 좋다.
exam %>%
filter(class==1) %>%
select(english) %>%
tail
순서대로 정렬하기(arrange)
오름차순
exam %>% arrange(math)
내림차순(desc 사용)
exam %>% arrange(desc(math))
정렬 기준 변수를 여러개 지정
exam %>% arrange(class, math)
파생변수(mutate)
a <- exam %>%
mutate(total = math + english + science) %>%
head
exam
여러 파생변수 한 번에 추가하는 방법
exam %>%
mutate(total = math + english + science,
mean = (math + english + science)/3) %>%
head
ifelse() 적용
exam %>%
mutate(test = ifelse(science >= 60, 'pass','fail')) %>%
head
exam <- read.csv('csv_exam.csv')
exam
추가한 파생변수를 코드에 바로 활용하기
exam %>%
mutate(total= math + english + science) %>%
arrange(total) %>%
head
집단별 요약(summarise)
1. 요약하기
exam %>% summarise(mean_math = mean(math))
2. 집단별로 요약하기(group_by)
exam %>%
group_by(class) %>% # class 별로 분리
summarise(mean_math = mean(math)) # 각 집단별 평균 산출
3. 여러 요약통계랑 한 번에 산출
exam %>%
group_by(class) %>%
summarise(mean_math = mean(math), # 수학 평균
sum_math = sum(math), # 수학 총점
median_math = median(math), # 수학 중앙값
student = n()) # 학생 수
요약통계량 함수
-
mean() : 평균
-
sd() : 표준편차 ( 평균에 대한 오차 )
-
sum() : 합계
-
median() : 중앙값
-
min(), max() : 최소값, 최대값
-
n() : 빈도
각 집단별로 다시 집단 나누기
a <- mpg %>%
group_by(manufacturer, model) %>%
summarise(mean_cty = mean(cty)) %>%
arrange(desc(mean_cty)) %>%
head(10)
Q1. 회사별로 "suv" 자동차의 도시 및 고속도로 통합 연비 평균을 구해서 내림차순으로 정렬하고, 1~5위까지 출력하기
mpg %>%
group_by(manufacturer) %>%
filter(class=='suv') %>%
mutate(total = (cty+hwy)/2) %>%
summarise(mean_total = mean(total)) %>%
arrange(desc(mean_total)) %>%
head(5)
가로 합치기(left_join)
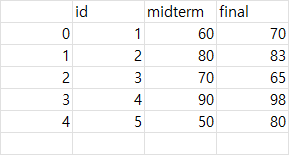
중간고사(midterm) 데이터 생성
test1 <- data.frame(id = c(1,2,3,4,5),
midterm = c(60,80,70,90,50))
기말고사(final) 데이터 생성
test2 <- data.frame(id = c(1,2,3,4,5),
final = c(70,83,65,98,80))
test1
test2
id 기준으로 합치기
total <- left_join(test1, test2, by='id') # id 기준으로 합쳐서 total 에 할당
total
다른 데이터 활용해서 변수 추가
name <- data.frame(class=c(1,2,3,4,5),
teacher=c('kim','lee','park','choi','jung'))
name
exam_new <- left_join(exam, name, by='class')
exam_new
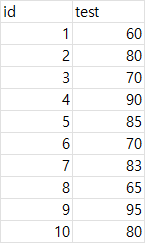
세로 합치기 (bind_rows)
group_a <- data.frame(id = c(1,2,3,4,5),
test = c(60,80,70,90,85))
group_b <- data.frame(id = c(6,7,8,9,10),
test = c(70,83,65,95,80))
group_a
group_b
group_all <- bind_rows(group_a, group_b)
group_all