- 다이아몬드 데이터셋 불러오기
import seaborn as sns
df = sns.load_dataset('diamonds')
df.head()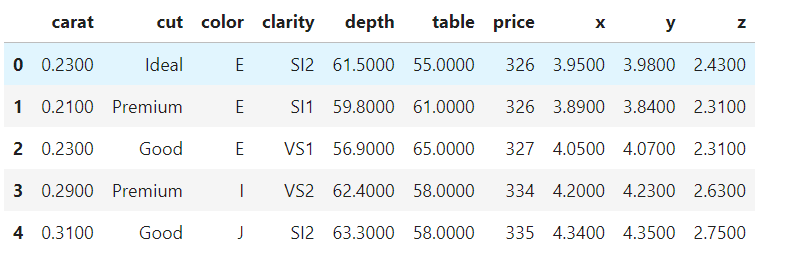
- 데이터의 각 변수
carat: 다이아몬드 무게
cut: 컷팅의 가치
color: 다이아몬드 색상
clarity: 깨끗한 정도
depth: 깊이 비율, z / mean(x, y)
table: 가장 넓은 부분의 너비 대비 다이아몬드 꼭대기의 너비
price: 가격
x: 길이
y: 너비
z: 깊이
- 캐럿과 가격 간의 관계 그래프 그리기
plt.rc('font', family='Malgun Gothic')
df.plot.scatter(x='carat', y='price', figsize=(10, 6), title='캐럿과 가격 간의 관계')
plt.show()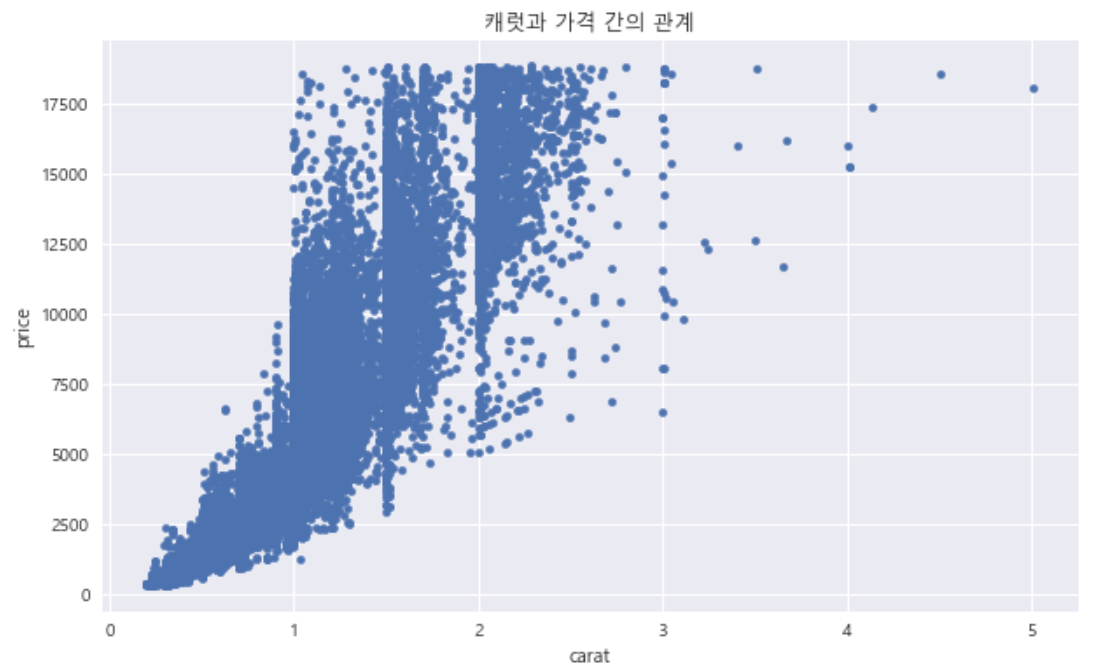
- 산점도 그리기
df.plot.scatter(x='carat', y='price', c='cut', cmap='Set2', figsize=(10, 6))
plt.show()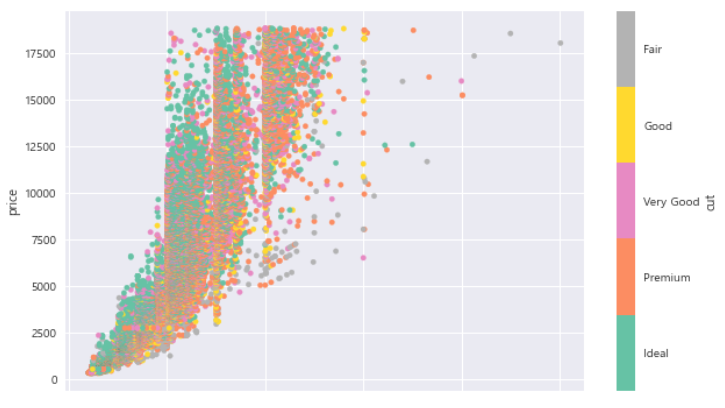
- 히스토그램 그리기
df['price'].plot.hist(figsize=(10, 6), bins=20)
plt.show()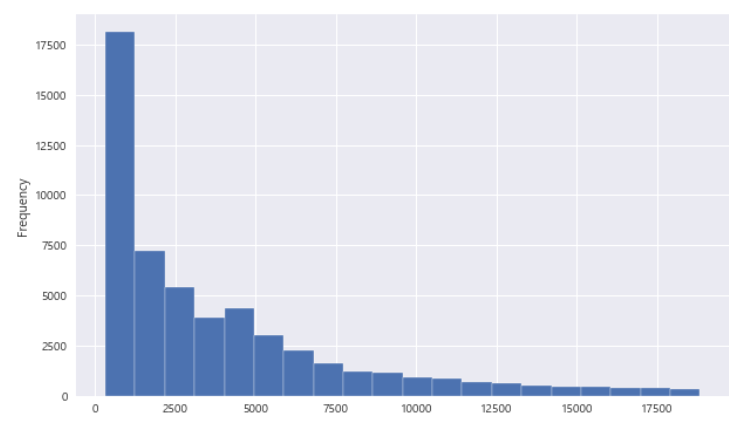
5-1. 컬러 기준으로 캐럿 평균 그래프 그리기
df.groupby('color')['carat'].mean().plot.bar(figsize=(10, 6))
plt.show()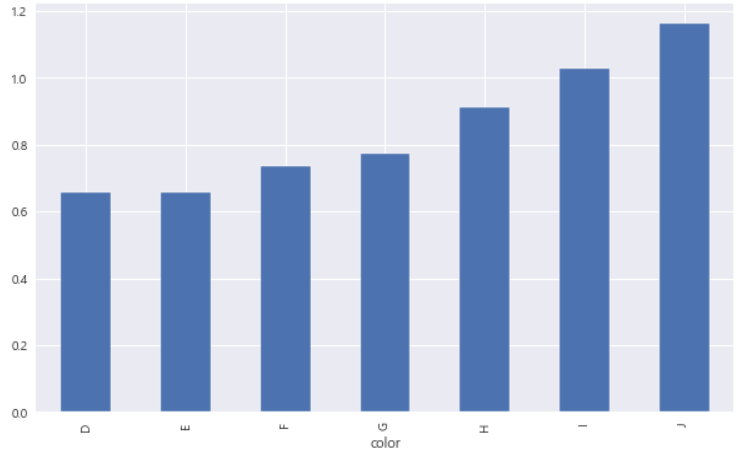
타이타닉 데이터셋
- 데이터셋 불러오기
import seaborn as sns
df = sns.load_dataset('titanic')
df.head()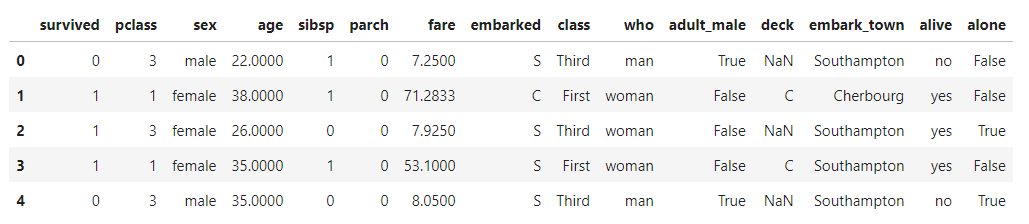
- 산점도 그리기
sns.scatterplot(data=df, x='age', y='fare')
plt.show()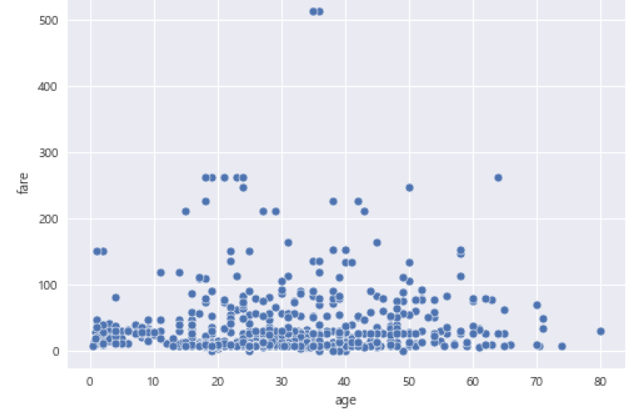
- 산점도 구체화
sns.scatterplot(data=df, x='age', y='fare', hue='class', style='class')
plt.show()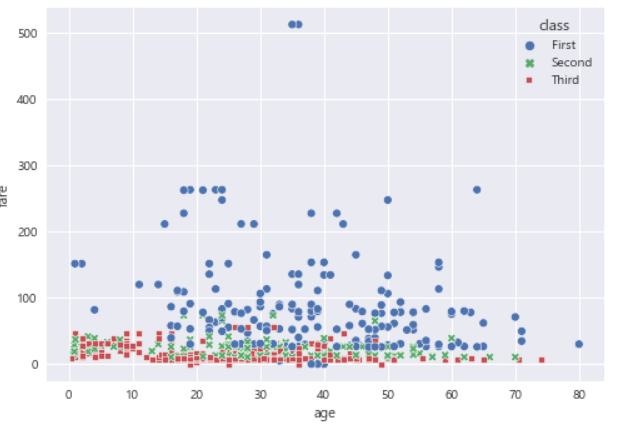
4. 피벗테이블
df_pivot = df.pivot_table(index='class',
columns='sex',
values='survived',
aggfunc='mean')
df_pivot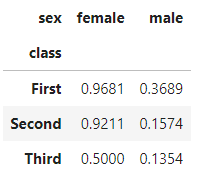
5. 히트맵
sns.heatmap(df_pivot, annot=True, cmap='coolwarm')
plt.show()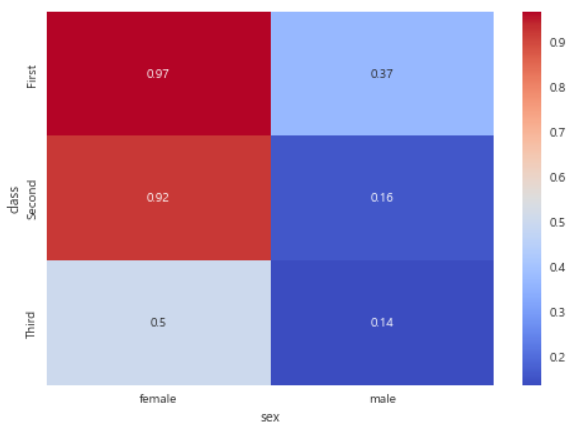
6. 히스토그램
sns.displot(data=df, x='age', hue='class', kind='hist', alpha=0.5)
plt.show()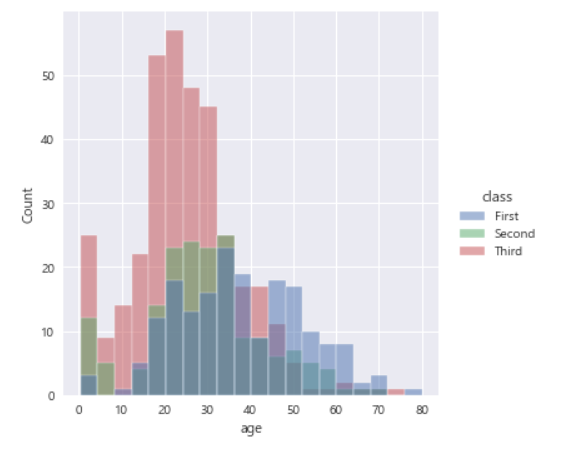
sns.displot(data=df, x='age', col='class', kind='hist')
plt.show()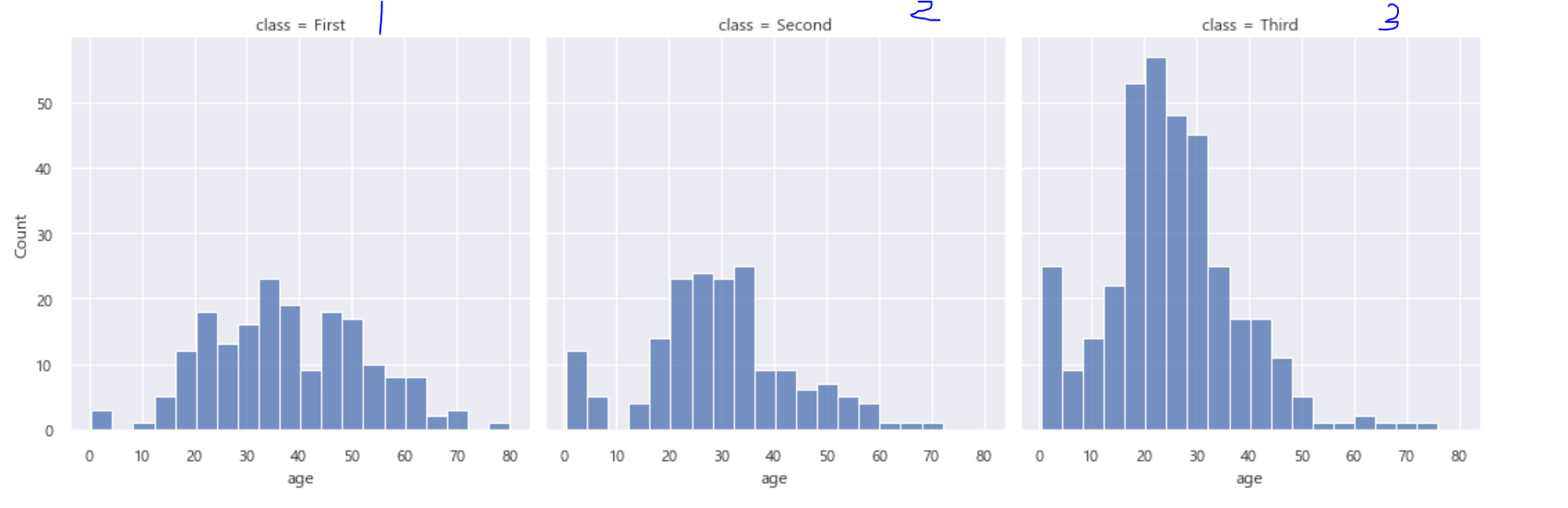
- 클래스별 나이 분포도
plt.rc('font', family='Malgun Gothic')
g, axes = plt.subplots(2, 1, figsize=(8, 6))
sns.histplot(data=df, x='age', hue='class', ax=axes[0])
sns.barplot(data=df, x='class', y='age', ax=axes[1])
axes[0].set_title('클래스 별 나이 분포도')
axes[1].set_title('클래스 별 평균 나이')
g.tight_layout()
plt.show()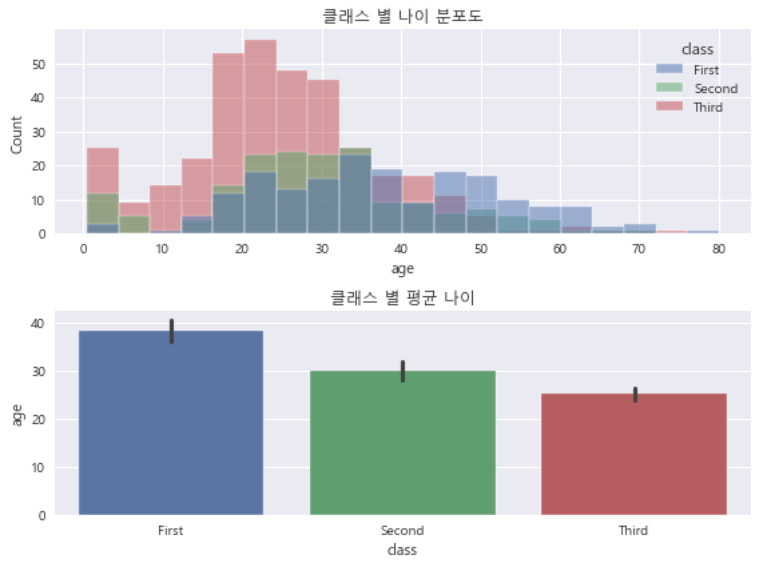

관심분야: 추천시스템, 자연어처리, 머신러닝, 딥러닝