데이터 병합 개요
단일 열 정렬
1 | data.sort_values(by='SALARY', ascending=False) | cs |
복합 정렬
- 인덱스 리셋
1 | 변수명.reset_index(drop = True) | cs |
- 복합 열을 별도로 저장하고, 인덱스 리셋
1 2 | temp = data.sort_values(by=['JobSatisfaction', 'MonthlyaIncome'], ascending=[True, False]) temp.reset_index(drop = True) | cs |
판다스 불러오기
1 | import pandas as pd | cs |
key를 기준으로 열과 열을 병합하기
- 데이터프레임 만들기 & 조회하기
1 2 3 | left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'], 'A': ['A0', 'A1', 'A2', 'A3'], 'B': ['B0', 'B1', 'B2', 'B3']}) | cs |
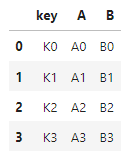
1 2 3 | right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'], 'C': ['C0', 'C1', 'C2', 'C3'], 'D': ['D0', 'D1', 'D2', 'D3']}) | cs |
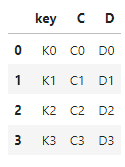
라이트 데이터 조회
1 | right | cs |
- 데이터 병합
1 | result = pd.merge(left, right, on='key') | cs |
데이터 조회
1 | result | cs |
이 케이스의 경우 완벽하게 떨어지는 경우라서 아래와 같이 보인다.

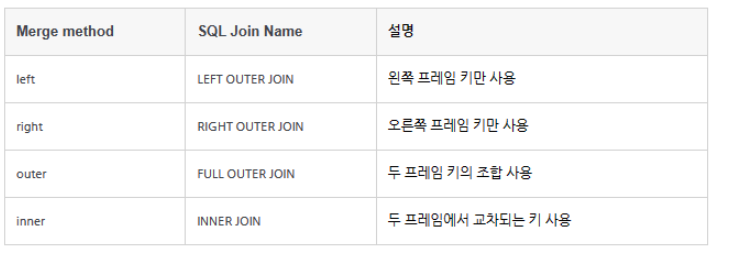
머지 메소드
다른 케이스의 데이터 정렬
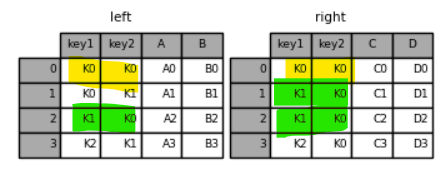
1 2 3 4 5 6 7 8 9 | left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'], 'key2': ['K0', 'K1', 'K0', 'K1'], 'A': ['A0', 'A1', 'A2', 'A3'], 'B': ['B0', 'B1', 'B2', 'B3']}) right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'], 'key2': ['K0', 'K0', 'K0', 'K0'], 'C': ['C0', 'C1', 'C2', 'C3'], 'D': ['D0', 'D1', 'D2', 'D3']}) | cs |
- 머지
1 2 | result = pd.merge(left, right, on=['key1', 'key2']) result | cs |
- 결과
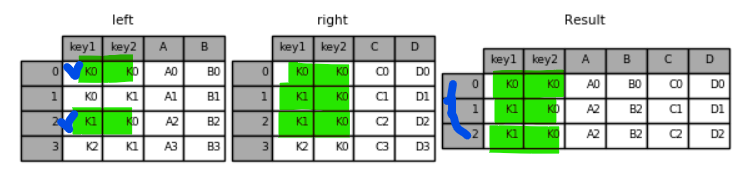
키값이 맞는 것만 보임
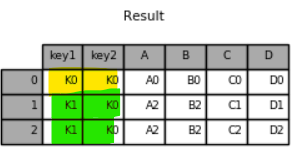
left 데이터프레임 기본 > 복수개 key 기준 열과 열 병합하기
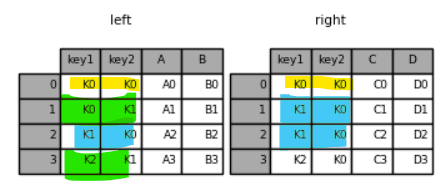
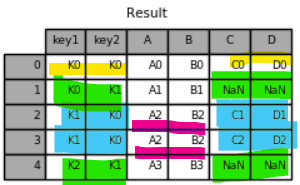
1 2 | result_left = pd.merge(left, right, how='left', on=['key1', 'key2']) result_left | cs |
핑크색 부분을 보면 left 기준으로 병합이 된 것을 알 수 있다.
right 데이터프레임 기본 > 복수개 key 기준 열과 열 병합하기
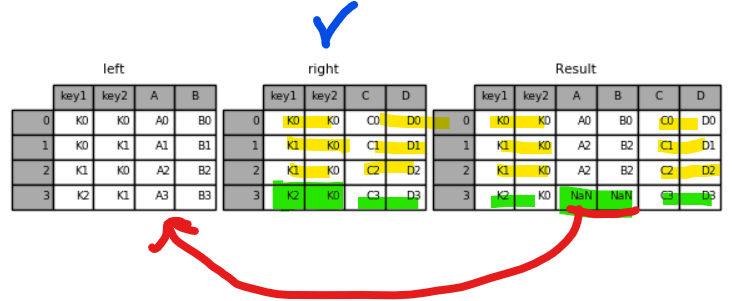
1 2 | result_right = pd.merge(left, right, how='right', on=['key1', 'key2']) result_right | cs |
right 기준으로 병합된 것을 확인 할 수 있다.
outer 방식 > 복수개 key 기준 열과 열 병합하기
1 2 | result_outer = pd.merge(left, right, how='outer', on=['key1', 'key2']) result_outer | cs |
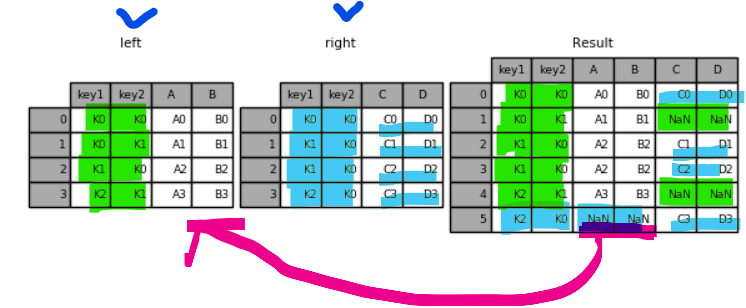
inner 방식 > 복수개 key 기준 열과 열 병합하기
1 2 | result_inner = pd.merge(left, right, how='inner', on=['key1', 'key2']) result_inner | cs |

관심분야: 추천시스템, 자연어처리, 머신러닝, 딥러닝